day35_8_19 数据库
一。存储引擎
不同的数据应该有不同的处理机制
MySQL中也有不同的存储引擎:
1.InnoDB MySQL默认的存储引擎。
innoDB比myisam存储数据要安全。
innoDB支持事务。
innoDB支持行锁。就是对一行数据的操作为串行。
innoDB支持外键。
2.myisam:MySQL老版本使用的存储引擎。
myisam比InnoDB读取速度快。
3.memory:内存引擎。所有的数据都存在内存中,断电即消失。
4.blackhole:无论存什么数据都立马消失,像一个黑洞一样。
方法:
使用show engines=存储引擎。 查看MySQL的所有引擎。

MYI:索引
MYD:真实数据
二。创建表的完整语法
创建表有一个完整的语法:
create table 表名(
字段名1 类型[(宽度) 约束条件],
字段名2 类型[(宽度) 约束条件],
字段名3 类型[(宽度) 约束条件]
);
注意:
1. 在同一张表中,字段名不能相同
2. 宽度和约束条件可选,字段名和类型是必须的
3. 最后一个字段后不能加逗号!
宽度:是对存储数据的限制。
如,char(1)就是限制字符只能输出一个字符。
如果超出了这个范围就会出现两个情况:
1,在非严格模式下,会自动帮你截取数据。
2,在严格模式下,会报错。
约束条件:
在表中,如果你要限制数据时,需要约束条件的帮助。
如,如果想让一个字段中不能为空,可以修改字段为:
alter table t2 modify name char(4) not null
这样后面存储的name就不能时null,之前存储的null值将会变成空白。
中括号中的约束数基于数据类型的约束之上的。
三。数据类型之整型
在定义一个整型数据时需要对其长度进行约束,其中的数字代表的可存储的数据如下:
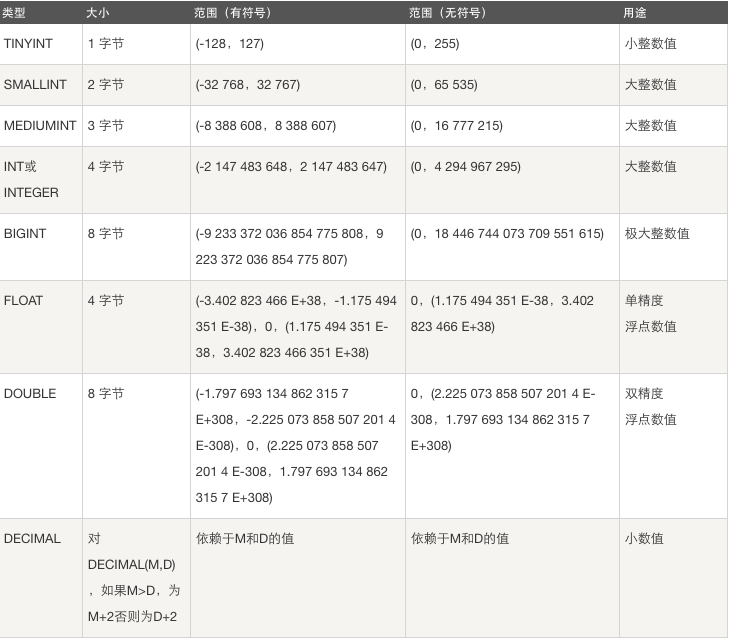
其中一个字符占8个字节,一个字节就可以存储2^8个。
整型默认的是无符号类型的,可以使用关键字unsigned使得没有正负符号。
注意:
在整型限制宽度中,其设置的宽度不代表它显示的值的位数,而是它所需要填充的位数。
如,int(8)中,如果你输入 数大于8位,那就按照定义的数据类型显示数字大小。
如果,输入的数字小于8位,则剩余的位数默认使用空格填充,
使用zerofill可以改用0填充。
只要是整型,都不需要设置宽度。
四。严格模式。
在用户输入数据的时候,表的宽度决定了你所输入数据的显示长度(除了整型),如果输出的长度超过了宽度,在非严格模式下,会自动帮助切分,但是设置了严格模式,就会报错。
为了数据的准确性,我们可以通过设置严格模式,限制用户的输入。
show variables like "%mode%"; # 查看数据库配置中变量名包含mode的配置参数
# 修改安全模式
set session # 只在当前操作界面有效
set global # 全局有效 set global sql_mode ='STRICT_TRANS_TABLES'
# 修改完之后退出当前客户端重新登陆即可
准确找到mysql的模式可以使用模糊匹配输出和mode有关的:
%匹配任意多个字符
_匹配任意一个字符
like,模糊匹配,匹配带有某个字符的名字。
所以可以通过以下语句搜寻关于mode的:
show variables like "%mode%"
输出结果如下:
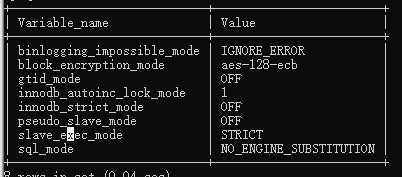
其中sql_mode就是数据库是否为严格模式。
设置分为两个方法:
1.set session 临时有效,关闭了该窗口之后就会失效。
2.set global,全局有效,设置以后就会一直有效。
设置语句:
set global sql_mode ='STRICT_TRANS_TABLES'
这样设置以后,用户再向其输入超长的字符串就会报错。
五。浮点型
浮点型的设置宽度比整型多一个小数部分的设置。
float(255.30),总共255位,小数部分占30位。
double(255.30),总共255位,小数部分占30位。
decimal(65.30),总共65位,小数部分占30位。
这些都是它们的最大位数的限制.
而它们最大的区别在于精确。
float < double < decimal 根据使用场景来选择浮点数的类型。
对于精确度和数据存储的方法,还有一个方法:
将小数点转换成字符串存入数据库,读取后再转换成浮点型数据。
六。字符类型
字符类型分为两种:
1.char(4)
最大只能存储4个字符,超出来的部分会直接报错。如果少了会用空格填充。
2.varchar(4)
最大存储4个字符,超出来的部分也会报错,少了的话,有几个就会存入几个。
在存入数据的时候,硬盘会将char中填充的空格存入,取出的时候,会自动将空格取消,所以,为了研究char与varchar的区别,需要使用set global改变模式。
set global sql_mode="strict_trans_tables,PAD_CHAR_TO_FULL_LENGTH";
注意,之前修改的严格模式也要加上,因为这个操作是替换而非累加。
设置好模式后使用char_length(字段),查看数据的长度。
select char_length(names) from t5;
可以看出char和varchar还是有不同的地方:
char定长,1.浪费空间,2.取值的时候方便,直接按长度取值。
varchar变长,1.节省空间,2.取值繁琐,需要获取数据的长度,需要加一个记录数据长度的报头。
七。日期类型
日期类型分为4个类型。
1.date 2019-05-01
2.time 11.11.11
3.datetime 2019-01-02 11.11.11
4.year 2019
例子:
create table student(
id int,
name char(16),
born_year year,
birth date,
study_time time,
reg_time datetime
);
insert into student values(1,'egon','','2019-05-09','11:11:00','2019-11-11 11:11:11');
八。枚举与集合类型
在数据输入的时候,控制用户输入数据的情况时,使用枚举类型。
如,性别,民族等,可输入类型较少,可以用枚举类型定义。
语法,关键字enum:
create table user(
id int,
name char(16),
gender enum('male','female','others')
);
insert into user values(1,'jason','xxx') # 报错
insert into user values(2,'egon','female') # 正确!
在枚举的基础上,如果数据需要输入多个数据,而这些数据又需要被规定时,可以使用集合。
集合与集合之间使用‘,’隔开。
使用场景,类似于爱好的数据。
举例:
create table teacher(
id int,
name char(16),
gender enum('male','female','others'),
hobby set('read','sleep','sanna','dbj')
);
insert into teacher values(1,'egon','male','read,sleep,dbj') # 集合也可以只存一个
set种的元素使用‘,’分隔。
九。约束条件
not null 不能为空;
default 给某个字段设置默认值。如果用户输入了值后,就写入用户传入的值,如果用户没有写入值,就写入默认值。
写入数据的第二种方式,可以在表名后指定特定值,就可以只输入该值,其他值为空。
insert into tb(id) values(1);
unique 唯一
在表中,如果想要一个字段的值只有唯一值。也就是限制某一字段唯一。
alter table t8 modify id int unique;
unique也可以设置多个值,代表这几个值共同唯一。
应用场景如同ip+post,标记一台计算机上的某个应用。
举例:
create table b9(
-> id int,
-> ip int,
-> post int,
-> name char,
-> unique(ip,post)
-> );
unique()要在字段定义 的最后使用,括号中填写你要练习的字段,这些字段构成一起不能出现重复。
primary key 主键
主键的限制的效果与not null+unique组合的效果相同,非空且唯一。
create table b2(id int primary key);
一个字段可以跟多个限制条件(MUL)
create table b2(id int primary key not null);
primary keys 也是innodb引擎查询必备的索引。
innodb引擎在创建表的时候必须要有一个主键
当没有指定主键时:
1.会将非空切唯一的字段自动升级成主键
也就是not null + unique
2.当你的表中没有任何的约束条件,innodb会采用自己的内部默认的一个主键字段,该主键字段你在查询时候是无法使用的,查询数据的速度就会很慢,类似于一页一页的翻书
例子:
create table t12(
id int,
name char(16),
age int not null unique,
addr char(16) not null unique
)engine=innodb;
desc t12;
如图: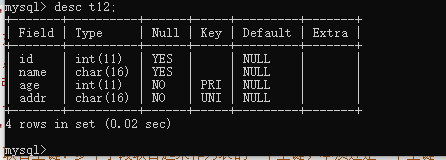
MySQL自动将第一个非空且唯一的age设置成主键(pri)。
一般的,通常把表中需要有个id字段,将id设置成主键。
联合主键:多个字段连接起来作为表的 一个主键,本质上还是一个主键。
举例:
create table t18(
ip char(16),
port int,
primary key(ip,port)
);
desc t18;
主键id作为数据的编号,每次最好能自动递增。
auto_increment 自动递增。限制条件。
设置了这个限制之后,就会自动在其数值上递增,可以不传入参数。
但是当里面的数据被删除后,继续添加数据,其自动增加的数字会接着删除的数据后面。
create table b4(
-> id int primary key auto_increment,
-> name char
-> );
结果如图:
图1:
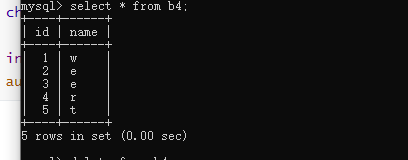
图2:

补充:
使用:truncate 表名,可以清空整个表,包括使用auto_increment 留下的记录。
day35_8_19 数据库的更多相关文章
- JSP应用开发 -------- 电纸书(未完待续)
http://www.educity.cn/jiaocheng/j9415.html JSP程序员常用的技术 第1章 JSP及其相关技术导航 [本章专家知识导学] JSP是一种编程语言,也是一种动 ...
- nodejs进阶(6)—连接MySQL数据库
1. 建库连库 连接MySQL数据库需要安装支持 npm install mysql 我们需要提前安装按mysql sever端 建一个数据库mydb1 mysql> CREATE DATABA ...
- GreenDao 数据库:使用Raw文件夹下的数据库文件以及数据库升级
一.使用Raw文件夹下的数据库文件 在使用GreenDao框架时,数据库和数据表都是根据生成的框架代码来自动创建的,从生成的DaoMaster中的OpenHelper类可以看出: public sta ...
- ASP.NET MVC with Entity Framework and CSS一书翻译系列文章之第二章:利用模型类创建视图、控制器和数据库
在这一章中,我们将直接进入项目,并且为产品和分类添加一些基本的模型类.我们将在Entity Framework的代码优先模式下,利用这些模型类创建一个数据库.我们还将学习如何在代码中创建数据库上下文类 ...
- Java MyBatis 插入数据库返回主键
最近在搞一个电商系统中由于业务需求,需要在插入一条产品信息后返回产品Id,刚开始遇到一些坑,这里做下笔记,以防今后忘记. 类似下面这段代码一样获取插入后的主键 User user = new User ...
- 在SQL2008查找某数据库中的列是否存在某个值
在SQL2008查找某数据库中的列是否存在某个值 --SQL2008查找某数据库中的列是否存在某个值 create proc spFind_Column_In_DB ( @type int,--类型: ...
- 分享一个SQLSERVER脚本(计算数据库中各个表的数据量和每行记录所占用空间)
分享一个SQLSERVER脚本(计算数据库中各个表的数据量和每行记录所占用空间) 很多时候我们都需要计算数据库中各个表的数据量和每行记录所占用空间 这里共享一个脚本 CREATE TABLE #tab ...
- SQL Server2014 SP2新增的数据库克隆功能
SQL Server2014 SP2新增的数据库克隆功能 创建测试库 --创建测试数据库 create database testtest use testtest go --创建表 )) --插入数 ...
- 数据库优化案例——————某市中心医院HIS系统
记得在自己学习数据库知识的时候特别喜欢看案例,因为优化的手段是容易掌握的,但是整体的优化思想是很难学会的.这也是为什么自己特别喜欢看案例,今天也开始分享自己做的优化案例. 最近一直很忙,博客产出也少的 ...
随机推荐
- 如何对jmeter设置IP欺骗
由于服务器出于安全考虑会对同一IP地址做过滤,所以如果想要达到正常的压测效果,我们需要在发请求时伪造出不同的IP地址.主要步骤分为以下3步:第一步:在负载机上绑定IP地址. 第二步:在要欺骗的http ...
- zz《分布式服务架构 原理、设计与实战》综合
这书以分布式微服务系统为主线,讲解了微服务架构设计.分布式一致性.性能优化等内容,并介绍了与微服务系统紧密联系的日志系统.全局调用链.容器化等. 还是一样,每一章摘抄一些自己觉得有用的内容,归纳整理, ...
- Codeforces Round #552 (Div. 3) EFG(链表+set,dp,枚举公因数)
E https://codeforces.com/contest/1154/problem/E 题意 一个大小为n(1e6)的数组\(a[i]\)(n),两个人轮流选数,先找到当前数组中最大的数然后选 ...
- vue_05项目配置
目录 vue项目配置: 前端样式结构: settings配置: vue项目路由配置: vue全局js配置: vue全局css配置: 父传子: 父组件 子组件 二.子传父 子组件 父组件 vue项目配置 ...
- Sharding-JDBC:查询量大如何优化?
主人公小王入职了一家刚起步的创业公司,公司正在研发一款App.为了快速开发出能够投入市场进行宣传的版本,小王可是天天加班到很晚,忙了一段时间后终于把第一个版本赶出来了. 初期功能不多,表也不多,用的M ...
- Python连载32-多线程其他属性以及继承Thread类
一.线程常用属性 1.threading.currentThread:返回当前线程变量 2.threading.enumerate:返回一个包含正在运行的线程的list,正在运行的线程指的是线程启动后 ...
- 二、Spring注解之@Conditional
Spring注解之@Conditional [1]@Conditional介绍 @Conditional是Spring4新提供的注解,它的作用是按照一定的条件进行判断,满足条件给容器注册bean. ...
- SqlBulkCopy将DataTable中的数据批量插入数据库中
#region 使用SqlBulkCopy将DataTable中的数据批量插入数据库中 /// <summary> /// 注意:DataTable中的列需要与数据库表中的列完全一致.// ...
- kubernetes 之一些报错
1.kubelet与docker的Cgroup Driver不一致导致的报错 7月 :: kubeadm-master kubelet[]: W0701 :: watcher.go:] Error w ...
- jdbc:mysql:/// jdbc连接数据url简写方式
正常情况下我们写jdbc连接本地mysql数据库的时候通常是这样写 jdbc:mysql:localhost:3306/数据库名 下面就是要提到的简单的方法 jdbc:mysql:///数据库名