【大数据作业十一】分布式并行计算MapReduce
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
HDFS是一个hadoop平台分布式文件系统,主要是用来存储和读取数据的。
工作过程:首先工作过程可以分为分为写操作和读操作两步。
(1)写操作:假设有一个100M大小的文件a,系统使用者将文件a写入到HDFS上。HDFS按默认配置(块大小为64M)。HDFS分布在三个机架上Rack1,Rack2,Rack3。之后系统使用者将文件a按64M分块,分成两块,block1和block2。然后系统使用者向nameNode发送写数据请求。NameNode节点记录block的信息,并且返回可用的DataNode。
(2)读操作:客户端通过调用文件系统对象的open()方法来打开希望读取的文件,DistributedFileSystem通过使用RPC来调用NameNode以确定文件起始块的位置,同一block按照重复数会返回多个位置。前两步会返回一个FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流,客户端对这个输入流调用read()方法。存储着文件起始块的DataNode地址的DFSInputStream随即连接距离最近的DataNode,通过对数据流反复调用read()方法,将数据从DataNode传输到客户端。到达块的末端时,DFSInputStream会关闭与该DataNode的连接,然后寻找下一个块的最佳DataNode。一旦客户端完成读取,就对FSDataInputStream调用close()方法关闭文件读取。
工作原理:客户端通过调用DistributedFileSystem的create()方法,创建一个新的文件。DistributedFileSystem 通过远程过程调用 NameNode,去创建一个没有blocks关联的新文件。前两步结束后会返回 FSDataOutputStream 的对象,FSDataOutputStream被封装成 DFSOutputStream,DFSOutputStream 可以协调 NameNode和 DataNode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列。DataStreamer会去处理接受队列,它先问询 NameNode 这个新的 block 最适合存储的在哪几个DataNode里。客户端完成写数据后,调用close()方法关闭写入流。
MapReduce是一种并行可扩展计算的模型,主要解决海量离线数据的批处理。
工作过程:一个作业执行过程中有一个Jobtracker和多个Tasktracker,分别对应于HDFS中的namenode和datanode。Jobclient在用户端把已配置参数打包成jar文件存储在HDFS,并把存储路径提交给Jobtracker,然后Jobtracker创建每一个Task,并且分发到Tasktracker服务中去执行。
工作原理:程序会根据InputFormat将输入文件分割成splits,每个split会作为一个map task的输入,每个map task会有一个内存缓冲区,输入数据经过map阶段处理后的中间结果会写入内存缓冲区,并且决定数据写入到哪个partitioner,当写入的数据到达内存缓冲区的的阀值,会启动一个线程将内存中的数据溢写入磁盘,同时不影响map中间结果继续写入缓冲区。在溢写过程中,MapReduce框架会对key进行排序,如果中间结果比较大,会形成多个溢写文件,最后的缓冲区数据也会全部溢写入磁盘形成一个溢写文件,如果是多个溢写文件,则最后合并所有的溢写文件为一个文件。当所有的map task完成后,每个map task会形成一个最终文件,并且该文件按区划分。reduce任务启动之前,一个map task完成后,就会启动线程来拉取map结果数据到相应的reduce task,不断地合并数据,为reduce的数据输入做准备,当所有的map tesk完成后,数据也拉取合并完毕后,reduce task 启动,最终将输出输出结果存入HDFS上。
2.HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/wc


2)编写map函数和reduce函数,在本地运行测试通过
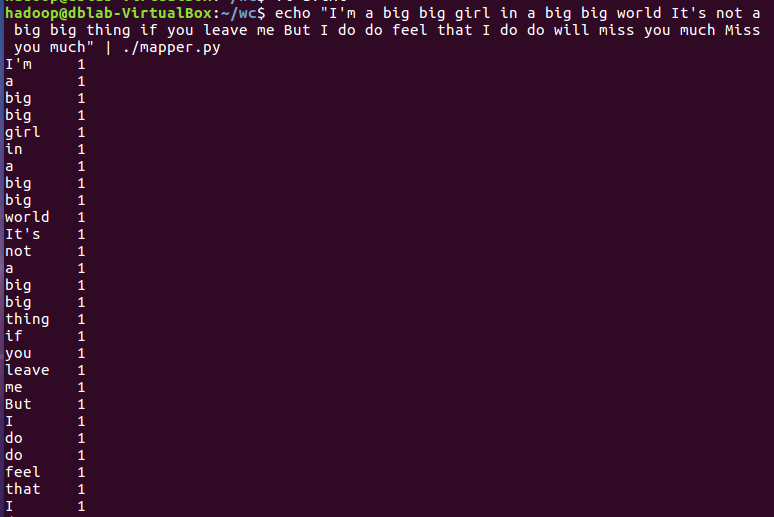

3)启动Hadoop:HDFS, JobTracker, TaskTracker

4)把文本文件上传到hdfs文件系统上 user/hadoop/input

5)streaming的jar文件的路径写入环境变量,让环境变量生效

6)建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh
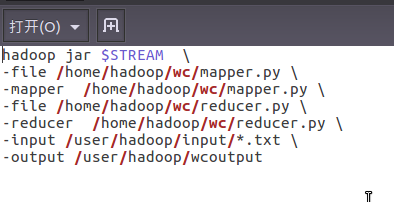
7)source run.sh来执行mapreduce
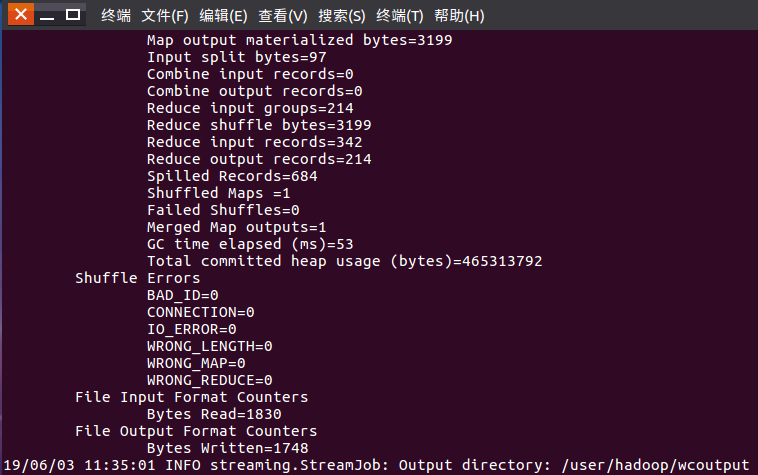
8)查看运行结果

每位同学准备不一样的大一点英文文本文件,每个步骤截图交上博客上。
上述步骤测试通过之后,可以尝试对文本做处理之后再统计次数,如标点符号、停用词等。
有能力的同学尝试对之前爬虫爬取的文本,在Hadoop上做中文词频统计。
【大数据作业十一】分布式并行计算MapReduce的更多相关文章
- 作业——11 分布式并行计算MapReduce
作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1.用自己的话阐明Hadoop平台上HDFS和MapRedu ...
- 大数据系列之分布式数据库HBase-0.9.8安装及增删改查实践
若查看HBase-1.2.4版本内容及demo代码详见 大数据系列之分布式数据库HBase-1.2.4+Zookeeper 安装及增删改查实践 1. 环境准备: 1.需要在Hadoop启动正常情况下安 ...
- 搭建大数据hadoop完全分布式环境遇到的坑
搭建大数据hadoop完全分布式环境,遇到很多问题,这里记录一部分,以备以后查看. 1.在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
- 2020/4/26 大数据的zookeeper分布式安装
大数据的zookeeper分布式安装 **** 前面的文章已经提到Hadoop的伪分布式安装.现在就在原有的基础上安装zookeeper. 首先启动Hadoop平台 [root@master ~]# ...
- 【大数据作业九】安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 4.简述Hadoop平台的起源.发展历史与应用现状. 列举发展过程中 ...
- 大数据技术之Hadoop(MapReduce)
第1章 MapReduce概述 1.1 MapReduce定义 1.2 MapReduce优缺点 1.2.1 优点 1.2.2 缺点 1.3 MapReduce核心思想 MapReduce核心编程思想 ...
- Hadoop大数据平台入门——HDFS和MapReduce
随着硬件水平的不断提高,需要处理数据的大小也越来越大.大家都知道,现在大数据有多火爆,都认为21世纪是大数据的世纪.当然我也想打上时代的便车.所以今天来学习一下大数据存储和处理. 随着数据的不断变大, ...
- 大数据作业之利用MapRedeuce实现简单的数据操作
Map/Reduce编程作业 现有student.txt和student_score.txt.将两个文件上传到hdfs上.使用Map/Reduce框架完成下面的题目 student.txt 20160 ...
- 大数据学习(05)——MapReduce/Yarn架构
Hadoop1.x中的MapReduce MapReduce作为Hadoop最核心的两个组件之一,在1.0版本中就已经存在了.它包含这么几个角色: Client 多数情况下Client的作用就是向服务 ...
随机推荐
- java基本结构
前言 Java文件的运行过程: 1,javac.exe:编译器 2,java.exe:解释器 微软shell下运行实例: C:\Users\Administrator>cd D:\文档\JAVA ...
- 英语wacche腕表
手表 (戴在手腕上的计时仪器) 手表,或称为腕表,是指戴在手腕上,用以计时/显示时间的仪器,手表在英语里watch源自中世纪wacche这一词汇. 手表通常是利用皮革.橡胶.尼龙布.不锈钢等材料,制成 ...
- 基于 k8s-搭建 Kubernetes 的 web 管理界面
查看我们的k8s环境是否正常: 使用kubectl get nodes 获取我们的节点的信息: 到此说明我们的kubernetes环境是正常的,接下来就可以实验了 第一步在master上传所需的软件包 ...
- 移动端H5长按事件 vue自定义指令
import Vue from 'vue' Vue.directive('longpress', function (el, binding){ var timer = null; var start ...
- Response响应相关
response是响应的对象 response.text # 返回的是字节,数据的原内容response.content # 返回的是字符串,默认是utf-8解码 import reques ...
- mysql的innodb数据存储结构
数据库磁盘读取与系统磁盘读取 1,系统从磁盘中读取数据到内存时是以磁盘块(block)为基本单位,位于同一个磁盘块中的数据会被一次性读取出来. 2,innodb存储引擎中有页(Page)的概念,页 ...
- 深层次揭示runBlocking与coroutineScope之间的异同点
在之前https://www.cnblogs.com/webor2006/p/11731763.html咱们写过这样的一个例子,先来回顾一下: 也就是来演示runBlocking与coroutineS ...
- SpringMVC的全局异常处理
@ControllerAdvice的使用 我们都知道做项目一般都会有全局异常统一处理的类,那么这个类在Spring中可以用@ControllerAdvice来实现. @ControllerAdvice ...
- jq function return value
所有 JS 函数 都会返回值 假如 没有 return 则返回 undefined
- C++中的常量指针和指针常量
1.概述: const Type * pointer;常量指针(const在*之前,与类型的位置无要求),所指向的地址上的数据是常量,而指向的地址可以变化. Type * const pointer: ...