大数据架构(PB级)
1.随着互联网快速发展,数据量的快速膨胀,我们日增3000多亿数据量,因此需要针对PB级存储、几百TB的增量数据处理架构设计
2.系统逻辑划分总图:
暂不便透露
3.系统架构图:
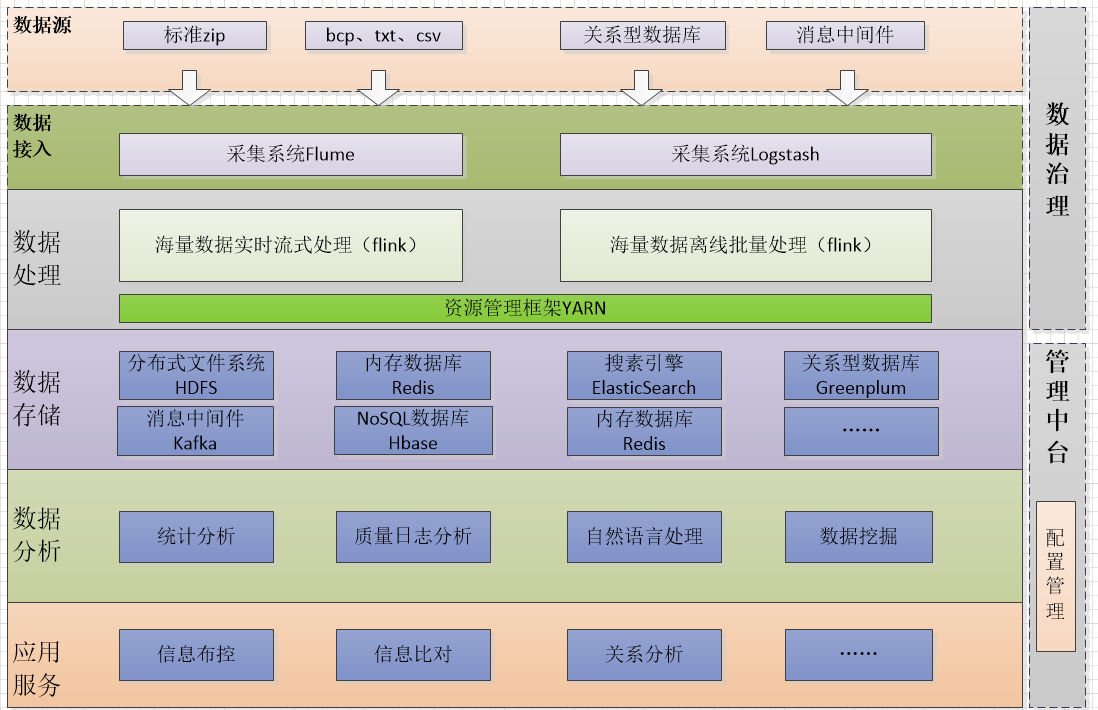
4.大数据计算引擎我们是采用Apache Flink流式计算框架,并对其进行了一些优化,目前在生产环境,已经基本稳定运行!
欢迎大家评论!!!
大数据架构(PB级)的更多相关文章
- 后Hadoop时代的大数据架构(转)
原文:http://zhuanlan.zhihu.com/donglaoshi/19962491 作者: 董飞 提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年 ...
- 后Hadoop时代的大数据架构
提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年的历史了,很多东西发生了变化,版本也从0.x进化到目前的2.6版本.我把2012年后定义成后Hadoop平台时代,这不是说不 ...
- 一篇了解大数据架构及Hadoop生态圈
一篇了解大数据架构及Hadoop生态圈 阅读建议,有一定基础的阅读顺序为1,2,3,4节,没有基础的阅读顺序为2,3,4,1节. 第一节 集群规划 大数据集群规划(以CDH集群为例),参考链接: ht ...
- 阿里巴巴飞天大数据架构体系与Hadoop生态系统
很多人问阿里的飞天大数据平台.云梯2.MaxCompute.实时计算到底是什么,和自建Hadoop平台有什么区别. 先说Hadoop 什么是Hadoop? Hadoop是一个开源.高可靠.可扩展的分布 ...
- 大数据架构师基础:hadoop家族,Cloudera产品系列等各种技术
大数据我们都知道hadoop,可是还会各种各样的技术进入我们的视野:Spark,Storm,impala,让我们都反映不过来.为了能够更好的架构大数据项目,这里整理一下,供技术人员,项目经理,架构师选 ...
- 大数据架构-使用HBase和Solr将存储与索引放在不同的机器上
大数据架构-使用HBase和Solr将存储与索引放在不同的机器上 摘要:HBase可以通过协处理器Coprocessor的方式向Solr发出请求,Solr对于接收到的数据可以做相关的同步:增.删.改索 ...
- WOT干货大放送:大数据架构发展趋势及探索实践分享
WOT大数据处理技术分会场,PingCAP CTO黄东旭.易观智库CTO郭炜.Mob开发者服务平台技术副总监林荣波.宜信技术研发中心高级架构师王东及商助科技(99Click)顾问总监郑泉五位讲师, ...
- 学习《深度学习与计算机视觉算法原理框架应用》《大数据架构详解从数据获取到深度学习》PDF代码
<深度学习与计算机视觉 算法原理.框架应用>全书共13章,分为2篇,第1篇基础知识,第2篇实例精讲.用通俗易懂的文字表达公式背后的原理,实例部分提供了一些工具,很实用. <大数据架构 ...
- 大数据架构师必读的NoSQL建模技术
大数据架构师必读的NoSQL建模技术 从数据建模的角度对NoSQL家族系统做了比较简单的比较,并简要介绍几种常见建模技术. 1.前言 为了适应大数据应用场景的要求,Hadoop以及NoSQL等与传统企 ...
- Hbase和Hive在大数据架构中处在不同位置
先放结论:Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用.一.区别:Hbase: Hadoop database ...
随机推荐
- Java springMVC前端传入字符串、后台接收Date的错误解决
今天在一个基于SSM的项目里出现以下报错 Cannot convert value of type [java.lang.String] to required type [java.util.Dat ...
- Java_jdbc 基础笔记之二 数据库连接
/** * DriverManager 类是驱动程序管理器类 * 1)可以通过重载的getConnection()方法获取数据库的连接,较为方便 * 2)可以同时管理多个驱动程序:若注册了多个数据库连 ...
- nginx高级玩法之根据来源ip分流
author :headsen chen date : 2019-08-15 16:37:05 notice :个人原创 需求:根据不同的请求的来源ip实现分流到不同的后端上去 方法一:1,在s ...
- VS Code 通过文件名查询文件并打开
On Windows press Ctrl+p or Ctrl+e On Mac press Cmd+p on the Linux press also Ctrl+p works Older Mac ...
- 国人开发的api测试工具 ApiPost
挺好用的 ApiPost https://www.apipost.cn/download.html 需要注册,免费试用.感觉比postman好用
- PDF生成类库
from:https://blog.csdn.net/plean/article/details/8097015 最近忙了两个星期的任务了 iTextSharp.dll是个开源的用于生成pdf ...
- Flutter ExpansionPanel 可展开的收缩控件
文档:https://api.flutter.dev/flutter/material/ExpansionPanel-class.html demo: import 'package:flutter/ ...
- osg编译日志3
1>------ 已启动生成: 项目: ZERO_CHECK, 配置: Debug x64 ------1> Checking Build System1> CMake does n ...
- 查看所使用的Linux系统是32位还是64 位的方法
方法一:getconf LONG_BIT # getconf LONG_BIT 1 1 我的Linux是32位!!! 方法二:arch # arch 1 1 显示 i686 就是32位,显示 x86_ ...
- NSGA,NSGA-II,Epsilon-MOEA,DE C语言Deb教授原版代码
NSGA,NSGA-II,Epsilon-MOEA,Basic Differential Evolution (DE) C语言Deb教授原版代码地址 觉得有用的话,欢迎一起讨论相互学习~[Follow ...