分类模型的评价指标Fscore
分类方法常用的评估模型好坏的方法.
0.预设问题
假设我现在有一个二分类任务,是分析100封邮件是否是垃圾邮件,其中不是垃圾邮件有65封,是垃圾邮件有35封.模型最终给邮件的结论只有两个:是垃圾邮件与 不是垃圾邮件.
经过自己的努力,自己设计了模型,得到了结果,分类结果如下:
- 不是垃圾邮件70封(其中真实不是垃圾邮件60封,是垃圾邮件有10封)
- 是垃圾邮件30封(其中真实是垃圾邮件25封,不是垃圾邮件5封)
现在我们设置,不是垃圾邮件.为正样本,是垃圾邮件为负样本
我们一般使用四个符号表示预测的所有情况:
- TP(真阳性):正样本被正确预测为正样本,例子中的60
- FP(假阳性):负样本被错误预测为正样本,例子中的10
- TN(真阴性):负样本被正确预测为负样本,例子中的25
- FN(假阴性):正样本被错误预测为负样本,例子中的5
1.评价方法介绍
先看最终的计算公式:

1.Precision(精确率)
关注预测为正样本的数据(可能包含负样本)中,真实正样本的比例
计算公式

例子解释:对上前面例子,关注的部分就是预测结果的70封不是垃圾邮件中真实不是垃圾邮件占该预测结果的比率,现在Precision=60/(600+10)=85.71%
2.Recall(召回率)
关注真实正样本的数据(不包含任何负样本)中,正确预测的比例
计算公式
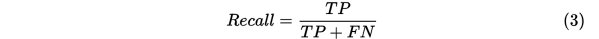
例子解释:对上前面例子,关注的部分就是真实有65封不是垃圾邮件,这其中你的预测结果中有多少预测正确了,Recall=60/(60+5)=92.31%
3.F-score中β值的介绍
β是用来平衡Precision,Recall在F-score计算中的权重,取值情况有以下三种:
- 如果取1,表示Precision与Recall一样重要
- 如果取小于1,表示Precision比Recall重要
- 如果取大于1,表示Recall比Precision重要
一般情况下,β取1,认为两个指标一样重要.此时F-score的计算公式为:
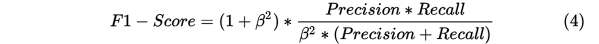
前面计算的结果,得到Fscore=(2*0.8571*0.9231)/(0.8571+0.9231)=88.89%
3.其他考虑
预测模型无非就是两个结果
- 准确预测(不管是正样子预测为正样本,还是负样本预测为负样本)
- 错误预测
那我就可以直接按照下面的公式求预测准确率,用这个值来评估模型准确率不就行了

那为什么还要那么复杂算各种值.理由是一般而言:负样本远大于正样本。
可以想象,两个模型的TN变化不大的情况下,但是TP在两个模型上有不同的值,TN>>TP是不是可以推断出:两个模型的(TN+TP)近似相等.这不就意味着两个模型按照以上公式计算的Accuracy近似相等了.那用这个指标有什么用!!!
所以说,对于这种情况的二分类问题,一般使用Fscore去评估模型.
需要注意的是:Fscore只用来评估二分类的模型,Accuracy没有这限制
参考
1.机器学习中的 precision、recall、accuracy、F1 Score
2.分类模型的评估方法-F分数(F-Score)
分类模型的评价指标Fscore的更多相关文章
- 【AUC】二分类模型的评价指标ROC Curve
AUC是指:从一堆样本中随机抽一个,抽到正样本的概率比抽到负样本的概率大的可能性! AUC是一个模型评价指标,只能用于二分类模型的评价,对于二分类模型,还有很多其他评价指标,比如logloss,acc ...
- 分类模型的性能评价指标(Classification Model Performance Evaluation Metric)
二分类模型的预测结果分为四种情况(正类为1,反类为0): TP(True Positive):预测为正类,且预测正确(真实为1,预测也为1) FP(False Positive):预测为正类,但预测错 ...
- NLP学习(2)----文本分类模型
实战:https://github.com/jiangxinyang227/NLP-Project 一.简介: 1.传统的文本分类方法:[人工特征工程+浅层分类模型] (1)文本预处理: ①(中文) ...
- 笔记︱风控分类模型种类(决策、排序)比较与模型评估体系(ROC/gini/KS/lift)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 本笔记源于CDA-DSC课程,由常国珍老师主讲 ...
- MXNET:分类模型
线性回归模型适用于输出为连续值的情景,例如输出为房价.在其他情景中,模型输出还可以是一个离散值,例如图片类别.对于这样的分类问题,我们可以使用分类模型,例如softmax回归. 为了便于讨论,让我们假 ...
- Spark学习笔记——构建分类模型
Spark中常见的三种分类模型:线性模型.决策树和朴素贝叶斯模型. 线性模型,简单而且相对容易扩展到非常大的数据集:线性模型又可以分成:1.逻辑回归:2.线性支持向量机 决策树是一个强大的非线性技术, ...
- 利用libsvm-mat建立分类模型model参数解密[zz from faruto]
本帖子主要就是讲解利用libsvm-mat工具箱建立分类(回归模型)后,得到的模型model里面参数的意义都是神马?以及如果通过model得到相应模型的表达式,这里主要以分类问题为例子. 测试数据使用 ...
- Spark机器学习4·分类模型(spark-shell)
线性模型 逻辑回归--逻辑损失(logistic loss) 线性支持向量机(Support Vector Machine, SVM)--合页损失(hinge loss) 朴素贝叶斯(Naive Ba ...
- sklearn特征选择和分类模型
sklearn特征选择和分类模型 数据格式: 这里.原始特征的输入文件的格式使用libsvm的格式,即每行是label index1:value1 index2:value2这样的稀疏矩阵的格式. s ...
随机推荐
- ML学习笔记之XGBoost实现对鸢尾花数据集分类预测
import xgboost as xgb import numpy as np import pandas as pd from sklearn.model_selection import tra ...
- winform实现Session功能(保存用户信息)
问题描述:在winform中想实现像BS中类似Session的功能,放上需要的信息,在程序中都可以访问到. 解决方案:由于自己很长时间没有做过winform的程序,一时间竟然手足无措起来.后来发现wi ...
- 微信小程序和asp.net core基于docker和nginx的交互
这个文章的题目起的比较长,我想实现这样一个产品: 前端是微信小程序,后端是基于docker运行的asp.net core webapi.webapi通过nginx实现的反向代理接入,nginx同样基于 ...
- 指针 vs 引用 (2)
这波要针对上篇分析里 标红的问题(成员变量用 T,T&啥情况)继续思考, 要学习以下材料: 1. 知乎上:用指针还是引用 2. StackOverflow上的相关问题 https://stac ...
- 如何在Linux中复制文档
在办公室里复印文档过去需要专门的员工与机器.如今,复制是电脑用户无需多加思考的任务.在电脑里复制数据是如此微不足道的事,以致于你还没有意识到复制就发生了,例如当拖动文档到外部硬盘的时候. 数字实体复制 ...
- 剑指前端(前端入门笔记系列)——DOM(元素节点)
DOM(元素节点) 本文介绍了元素节点的基本操作:增删改查 增 新增一个元素节点分为两步(二者缺一不可),第一步:创建元素节点,第二步:将创建的元素节点插入到指定元素节点中(也就是插入指定元素节点 ...
- VMware网络连接三种模式bridged、host-only、NAT
1. bridged(桥接模式) 在桥接模式下,虚拟机和主机处于同一网段,这样虚拟机才能和主机进行通信 使用桥接模式,就像连接在同一个Hub上的两台电脑 //简单配置ip # ifconfig eth ...
- java并发值多线程同步业务场景以及解决方案
1.20个人排队同时访问2个购票窗口,同时能购票的只有两个人,当其中一个人买票完成后,18个人中的其中一个在占用窗口进行购买. 20个人相当于20个线程,2相当于资源,当18个人等待的时候,相当于线程 ...
- 转摘Python安装与环境变量的配置
Python安装与环境变量的配置 python下载: Python安装包下载地址:http://www.python.org/ 根据实际的操作系统,安装合适的安装版本. Python安装: 本文以 ...
- Linux下源码编译php7
1.安装依赖包 yum install -y gcc gcc-c++ make zlib zlib-devel pcre pcre-devel libjpeg libjpeg-devel libpng ...