转:HtmlCxx用户手册
1.1 简介
使用由KasperPeeters编写的强大的tree.h库文件,可以实现类似STL的DOM树遍历和导航。
打包好的Css解析器。
看似很像C++代码的C++代码(其实已不再是C++了)
Htmlcxx的解析策略其实是尝试模仿mozilla firefox(http://www.mozilla.org)的模式。因此你应当尝试去解析那些由firefox所生成的文档。然而不同于firefox浏览器,htmlcxx并不会将一些原本不存在的东西加入到所生成的文档当中去。因此,在将生成树进行序列化的时候,能够完全地还原和原始Byte大小一样的HTML文档。
1.2 快速上手
1. 安装环境
编译环境: GCC 4.4.4
2. 源代码下载
除此之外,使用Ubuntu的用户还可以直接在命令行下使用以下命令很方便地进行安装:
| sudo apt-get install htmlcxx |
3. 编写小例子
|
#include <string> #include <iostream> #include <sstream> #include <htmlcxx/html/ParserDom.h> #include <stdlib.h> #include <stdio.h> #include <unistd.h> using namespace std; using namespace htmlcxx; int main() { //解析一段Html代码 string html ="<html><body>hey</body></html>"; HTML::ParserDom parser; tree<HTML::Node> dom = parser.parseTree(html); //输出整棵DOM树 cout<< dom << endl; //输出树中所有的超链接节点 tree<HTML::Node>::iterator it = dom.begin(); tree<HTML::Node>::iterator end = dom.end(); for(; it != end; ++it) { if (strcasecmp(it->tagName().c_str(), "A") == 0) { it->parseAttributes(); cout <<it->attribute("href").second << endl; } } //输出所有的文本节点 it= dom.begin(); end= dom.end(); for(; it != end; ++it) { if ((!it->isTag()) && (!it->isComment())) { cout << it->text(); } } cout << endl; } |
将代码编写好保存后,打开控制台进入Temp.cc的目录下,输入以下的命令使用gcc将其编译:
|
gcc –o Temp Temp.cc –Iusr/include/htmlcxx-lhtmlcxx |
编译生成可执行文件Temp,直接输入./Temp运行,程序如果正常运行则应当出现如下的结果:
二.源代码分析
2.1 简介
http://tree.phi-sci.com/documentation.html上找到。在学习HtmlCxx的源代码的时候,要注意到的一点就是不仅应学习它的原理,更因为它引用了开源的树结构代码tree.h,优秀的编码风格贯穿始终,代码十分工整和简洁,广泛适用C++的template机制使其可扩展性非常强,为我们学习C++ 语言编程提供了良好的示范教材。
由于其注释代码内部较少,下面这段源代码解析主要为方便大家理解。
2.2 ParserDom.h(.cc)
我们首先来分析ParserDom.h这个文件。上面的例子中我们就用到了这个头文件来对Html文档进行解析。这里我们需要说明,一般的XML格式文档 (包括Html文档)解析有两种方式,即DOM方式和SAX方式,下面简要介绍一下这两种方式的异同。
DOM方式:
DOM(DocumentObject Model 文档对象模型)方式,从名字上来看就是将XML格式的文档读至内存,并为每个节点建立一个对象,之后我们可以通过操作对象的方式来对节点进行操作,即是将XML的节点映射到了内存中的一系列对象之上。
该方法的优点是在建立好模型后的查询和修改速度较快。
SAX方式:
该方法的优点是不用等待所有数据都被处理后再开始分析,且不需要将整个文档都装入内存中,这对大文档来说是个巨大的优点。一般来说SAX要比DOM方式快很多。
首先我们来看一下ParserDom.h中ParserDom类的几个方法和数据成员的声明。
|
class ParserDom : public ParserSax { public: ParserDom(){} //构造方法 ~ParserDom(){} //析构方法 consttree<Node> &parseTree(const std::string &html); //通过String字符串来解析树 consttree<Node> &getTree() //返回(解析好的)数据成员mHtmlTree {return mHtmlTree; } protected: //声明了一系列虚函数,用于之后的重载 virtualvoid beginParsing(); //开始解析 virtualvoid foundTag(Node node, bool isEnd); //寻找指定标签 virtualvoid foundText(Node node); //寻找文本 virtualvoid foundComment(Node node); //寻找注释文本 virtualvoid endParsing(); //结束解析 tree<Node>mHtmlTree; //数据成员,用于存放解析好的树 tree<Node>::iteratormCurrentState; //用于遍历树的迭代器,具体声明可见tree.h文件 }; |
|
std::ostream&operator<<(std::ostream &stream, const tree<HTML::Node>&tr); |
该段代码重写了<<操作符,使得可以该操作符可以直接输出tree<HTML::Node>类型的变量。
parseTree(const std::string &html)
|
const tree<HTML::Node>&ParserDom::parseTree(const std::string &html) { this->parse(html); //调用ParserSax.h中的parse方法对html字符串进行解析,并且将结果存入数据成员mHtmlTree returnthis->getTree(); //返回受保护的数据成员mHtmlTree } |
beginParsing()
|
void ParserDom::beginParsing() { mHtmlTree.clear(); //首先清空mHtmlTree tree<HTML::Node>::iteratortop = mHtmlTree.begin(); //之后申请一个top游标,指向mHtmlTree树的开始节点 HTML::Nodelambda_node; //申请一个新节点 lambda_node.offset(0); //初始化moffset值为0,具体请查阅node.h和node.cc文件 lambda_node.length(0); lambda_node.isTag(true); lambda_node.isComment(false); mCurrentState= mHtmlTree.insert(top,lambda_node); //将这个节点插入到树中去成为根节点,注意是插入到top游标节点的之前,即previous sibling,具体请查阅tree.h中的insert方法。 } |
endParsing()
|
void ParserDom::endParsing() { tree<HTML::Node>::iteratortop = mHtmlTree.begin(); //获取根节点 top->length(mCurrentOffset);//将根节点的length数据成员设置为当年已解析的距离 } |
foundComment()
|
void ParserDom::foundComment(Node node) { //Addchild content node, but do not update current state //在当前节点下添加一个新的节点node,但是不更新当前解析的进度,即不修改mCurrentState游标的位置 mHtmlTree.append_child(mCurrentState,node); } |
foundText()
|
void ParserDom::foundComment(Node node) { //Addchild content node, but do not update current state //在当前节点下添加一个新的节点node,但是不更新当前解析的进度,即不修改mCurrentState游标的位置 mHtmlTree.append_child(mCurrentState,node); } |
foundTag(Nodenode, bool isEnd)
该方法的主要作用是添加一个新的标签节点,并且需要根据isEnd变量进行判断是起始标签如<div>或<a>等,还是结束标签如</div>或</a>等。
|
void ParserDom::foundTag(Node node, boolisEnd) { if(!isEnd) { //appendto current tree node tree<HTML::Node>::iteratornext_state; next_state= mHtmlTree.append_child(mCurrentState, node); mCurrentState= next_state; } else { //Lookif there is a pending open tag with that same name upwards //IfmCurrentState tag isn't matching tag, maybe a some of its parents //matches vector<tree<HTML::Node>::iterator > path; tree<HTML::Node>::iteratori = mCurrentState; boolfound_open = false; while(i != mHtmlTree.begin()) { #ifdef DEBUG cerr<< "comparing " << node.tagName() << " with" << i->tagName()<<endl<<":"; if(!i->tagName().length()) cerr << "Tag with no name at"<<i->offset()<<";"<<i->offset()+i->length(); #endif assert(i->isTag()); assert(i->tagName().length()); boolequal; constchar *open = i->tagName().c_str(); constchar *close = node.tagName().c_str(); equal= !(strcasecmp(open,close)); if(equal) { DEBUGP("Foundmatching tag %s\n", i->tagName().c_str()); //Closingtag closes this tag //Setlength to full range between the opening tag and //closingtag i->length(node.offset()+ node.length() - i->offset()); i->closingText(node.text()); mCurrentState= mHtmlTree.parent(i); found_open= true; break; } else { path.push_back(i); } i= mHtmlTree.parent(i); } if(found_open) { //Ifmatch was upper in the tree, so we need to invalidate child //nodesthat were waiting for a close for(unsigned int j = 0; j < path.size(); ++j) { // path[j]->length(node.offset()- path[j]->offset()); mHtmlTree.flatten(path[j]); } } else { DEBUGP("Unmatchedtag %s\n", node.text().c_str()); //Treat as comment node.isTag(false); node.isComment(true); mHtmlTree.append_child(mCurrentState,node); } } } |
</div>,而可能会有<div><a>…</a><div>…</div></div>,此时第一个<div>才是其所对应的起始tag节点。为了解决这个问题,本函数里采用了一个将树路径以vetor存储的方式进行查找匹配。
1. 将所插入节点与当前节点的tagName进行比较。如果相同或者当前节点就是根节点,则前往第三步。
2. 将当前节点重置为当前节点的父节点,并将当前节点按顺序添加至path。回到第1步。
3. 检查是否找到tagName相同的节点,如果找到,我们需要调用flatten()方法调整树的结构,从而消除掉原本正在等待结束tag的起始tag节点。
4. 否则即为未找到,报错。
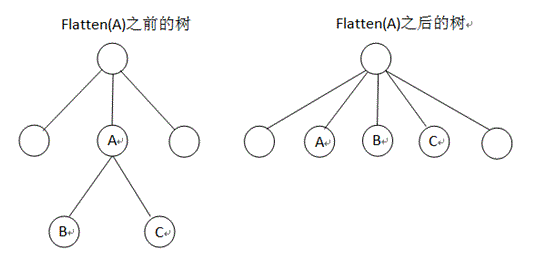
本方法主要是提供给ParseSax.tcc中的解析方法所调用。
operator<<(ostream &stream, consttree<HTML::Node> &tr)
本方法主要重写了<<操作符,使其可以直接输出tree<HTML::Node>类型的对象。
|
ostream &HTML::operator<<(ostream&stream, const tree<HTML::Node> &tr) { tree<HTML::Node>::pre_order_iteratorit = tr.begin(); tree<HTML::Node>::pre_order_iteratorend = tr.end(); introotdepth = tr.depth(it); stream<< "-----" << endl; unsignedint n = 0; while( it != end ) { intcur_depth = tr.depth(it); for(inti=0; i < cur_depth - rootdepth; ++i) stream << " "; stream<< n << "@"; stream<< "[" << it->offset() << ";"; stream<< it->offset() + it->length() << ") "; stream<< (string)(*it) << endl; ++it,++n; } stream<< "-----" << endl; returnstream; } |
2.3 ParserSax.h(.cc)
前面我们介绍过了Sax方式和DOM方式的区别,实际上在HtmlCxx中,这两种方式是结合使用的,即首先用SAX方式对流进行解析,解析出的结果采用DOM方式保存到一个树型的tree<Node>数据结构中。
首先我们还是来看一下ParserSax.h头文件中对于数据成员和函数的声明:
|
classParserSax { public: ParserSax(): mpLiteral(0), mCdata(false) {} //构造方法,初始化两个成员变量的值 virtual~ParserSax() {} //析构方法,空 /**Parse the html code */ voidparse(const std::string &html); //解析一个string格式的html文档 template<typename _Iterator> voidparse(_Iterator begin, _Iterator end); //使用两个类型相同的形参格式的解析器模板 protected: //Redefine this if you want to do some initialization before //the parsing virtualvoid beginParsing() {} //空,可进行扩展 //以下几个虚函数,都在ParseDom.cc中进行了实现 virtualvoid foundTag(Node node, bool isEnd) {} virtualvoid foundText(Node node) {} virtualvoid foundComment(Node node) {} virtualvoid endParsing() {} //以下是几个模板,大部分都在ParseSax.tcc文件中实现 template<typename _Iterator> voidparse(_Iterator &begin, _Iterator &end, std::forward_iterator_tag); template<typename _Iterator> voidparseHtmlTag(_Iterator b, _Iterator c); template<typename _Iterator> voidparseContent(_Iterator b, _Iterator c); template<typename _Iterator> voidparseComment(_Iterator b, _Iterator c); template<typename _Iterator> _IteratorskipHtmlTag(_Iterator ptr, _Iterator end); template<typename _Iterator> _IteratorskipHtmlComment(_Iterator ptr, _Iterator end); //几个数据成员 unsignedlong mCurrentOffset; //当前正在解析的偏移位置 constchar *mpLiteral; //具体作用需要到ParseSax.tcc中才显现出来 boolmCdata; //同上 }; |
打开ParserSax.cc可以看到,里面空荡荡地只有一个Parse(const std::string &html)方法
|
void htmlcxx::HTML::ParserSax::parse(conststd::string &html) { // std::cerr<< "Parsing string" << std::endl; parse(html.c_str(),html.c_str() + html.length()); } |
该方法实际上直接调用了另一个template<typename _Iterator> void parse(_Iterator begin, _Iterator end)方法,而这个方法和一些其他主要方法都是在ParseSax.tcc中进行实现。
2.4 ParseSax.tcc
注意.tcc文件和一般的.cc文件有所不同,应当是基于turboc++的,因为turbo c++是很多年没用过的东西了,具体我也不是很懂有什么区别。
ParseSax.tcc这个文件中主要实现了对html文档的文本流的解析,并将其转化为一个个的节点,并存储到Html树中去。其实现了一整套的 Html解析流程,值得我们学习。该流程主要针对的是FireFox生成的Html格式来进行的解析。并且使用 parseContent(),parseTag(),parseComment()对一段内容作为内容,标签,注释等进行不同的处理。
如果读者曾经写过类似的Html解析器,那么在看这段代码的时候会非常清晰,即使没有写过也没关系,因为这段代码的逻辑很清晰,可以借鉴其作为对Html解析器的标准来进行学习。
其基本思路就是,按序遍历整个字符串,遇到’<’则认为其是tag标签的起始处,在tag中遇到’/’则认为该标签是结束型tag标签,遇 到’>’则认为是tag标签的结束处,遇到’!’则认为其是注释字段的起始或结束处。之后运行相应的 parseContent(),parseTag(),parseComment()进行解析即可。
parse(_Iterator &begin, _Iterator&end, std::forward_iterator_tag)
|
voidhtmlcxx::HTML::ParserSax::parse(_Iterator &begin, _Iterator &end,std::forward_iterator_tag) { typedef_Iterator iterator; // std::cerr<< "Parsing forward_iterator" << std::endl; mCdata= false; mpLiteral= 0; mCurrentOffset= 0; this->beginParsing(); //调用beginParsing()进行初始化 // DEBUGP("Parsedtext\n"); |
|
while(begin != end) { *begin;// This is for the multi_pass to release the buffer |
|
while(c != end) { //For some tags, the text inside it is considered literal and is //only closed for its </TAG> counterpart |
|
while(mpLiteral) { // DEBUGP("Treatingliteral %s\n", mpLiteral); |
|
static struct literal_tag { intlen; constchar* str; intis_cdata; } literal_mode_elem[] = { {6,"script", 1}, {5,"style", 1}, {3,"xmp", 1}, {9,"plaintext", 1}, {8,"textarea", 0}, {0,0, 0} }; |
其意义就是说,当遇到这些特殊节点的时候,需要进入该循环进行一些特别的处理,即应当着手向后寻找该tagName对应的</tagName>标签,其间遇到的所有内容都应当作为普通文本进行处理。
|
// DEBUGP("Treatingliteral %s\n", mpLiteral); while(c != end && *c != '<') ++c; //向后不断查找,直到找到了文件末尾或’<’才停止,此刻说明解析完毕或者解析到了某个tag标签 if(c == end) { //如果成立说明解析完毕 if(c != begin) this->parseContent(begin, c); //此时最后一个解析的标签末尾和文档末尾之间可能还有一段内容需要解析 gotoDONE; //转到结束阶段 } iteratorend_text(c); //申请一个新游标end_text,初始值赋入c ++c; //将c游标前进一步 |
此处申请的end_text,主要是为了在后面的代码中记录下当前’<’符号的位置。
|
if(*c == '/') //判断’<’后面紧跟的是否为’/’符号 { ++c; //前进一步,指向tagName的起始位置 constchar *l = mpLiteral; while(*l && ::tolower(*c) == *l) //逐字节将mpLiteral和tagName进行比较 { ++c; ++l; } |
|
//FIXME: Mozilla stops when it sees a /plaintext. Check //other browsers and decide what to do if(!*l && strcmp(mpLiteral, "plaintext")) { //matched all and is not tag plaintext //说明不是plaintext标签,且此时l指针为空 while(isspace(*c)) ++c; //跳过空格字符 if(*c == '>') //直到找到标签结束位置 { ++c; if(begin != end_text) this->parseContent(begin,end_text); //处理这段标签之前的那段“文本” mpLiteral= 0; //更改循环进入条件 c= end_text; //修改游标值 begin= c; //修改游标值 break; //跳出循环,此时说明已经找到了对应tagName的</tagName>标签 } } |
|
elseif (*c == '!') { // we may find a comment andwe should support it iteratore(c); ++e; if(e != end && *e == '-' && ++e != end && *e == '-') { // DEBUGP("Parsingcomment\n"); ++e; c= this->skipHtmlComment(e, end); } } } |
到这里为止while(mpLiteral)循环的代码就结束了,下面的代码则是解析一般tag标签的代码。
|
if(*c == '<') //判断是否是一个标签的开始 { iteratord(c); //申请一个新游标d,初始为这个’<’的位置 ++d; //将其后移一位 if(d != end) //如果不是文档的结尾 { |
此时d所指向的应当是’<’之后的那个字符,现在要通过对这个字符进行判断来进行不同的处理,一共分四种情况进行处理:普通字符,’/’符 号,’!’符号,’?’或’%’符号。分别对应tagName,结束tag标签,注释字段,以及一些特殊字段如<?xml 或 <%VBSCRIPT。
首先是解析普通起始型标签的:
|
if(isalpha(*d)) //如果d指向的是普通字符 { //beginning of tag 说明是tag标签的起始 if(begin != c) //如果标签之前还有一段文本 this->parseContent(begin,c); //则对其进行处理 // DEBUGP("Parsingbeginning of tag\n"); d= this->skipHtmlTag(d, end); //找到Tag标签的结束位置 this->parseHtmlTag(c,d); //对Tag标签的起始位置和结束位置之间的这段标签内容适用parseHtmltag(X,X)进行处理。 //continue from the end of the tag c= d; //将游标移动到标签之后的位置 begin= c; break; //成功解析出一个节点,跳出循环 } |
|
if(*d == '/') { if(begin != c) //如果标签之前还有一段文本 this->parseContent(begin,c); //则对其进行处理 iteratore(d); //申请一个新标签e,初始化为d ++e; //将其后移一位 if(e != end && isalpha(*e)) { //说明此时e指向的是结尾型标签的起始处 d= this->skipHtmlTag(d, end); //寻找标签结束位置 this->parseHtmlTag(c,d); //对这段位置之间的标签进行处理 } else { //不是一个标准的结束型标签,和Mozilla采用一样的处理方式 d= this->skipHtmlTag(d, end); this->parseComment(c,d); } //将游标移动到tag标签之后继续 c= d; begin= c; break; //解析出一个节点,跳出循环 } |
之后是处理注释型标签的,即“<!--”型标签:
|
if(*d == '!') { //说明是注释标签 if(begin != c) //如果此标签之前还有一段文本 this->parseContent(begin,c); //则对其进行处理 iteratore(d); //申请一个游标e,初始化为d ++e;//将e后移一位 if(e != end && *e == '-' && ++e != end && *e == '-') { // DEBUGP("Parsingcomment\n"); ++e; d= this->skipHtmlComment(e, end); //查找到标签结尾 } else { d= this->skipHtmlTag(d, end); //也可能注释直到文档结束 } this->parseComment(c,d); //将这段文本作为注释进行处理 //移动游标至标签结尾处 c= d; begin= c; break; //成功解析出一个标签,跳出循环 } |
最后这段代码是处理一些诸如<?xml 或 <%VBSCRIPT之类的特殊标签的:
|
if(*d == '?' || *d == '%') { //这段代码很简单 if(begin != c) //如果标签之前还有一段文本 this->parseContent(begin,c); //则对其进行处理 d= this->skipHtmlTag(d, end); //找到标签末尾 this->parseComment(c,d); //对这段标签进行处理 //移动游标至末尾 c= d; begin= c; break;//成功解析出标签,跳出循环 } |
|
} } } c++; //每次while循环后都需要后移游标c } //在所有标签都处理完后,可能在文档末尾还有一些文本要进行处理 if(begin != c) { this->parseContent(begin,c); //处理这段文本 begin= c; } } DONE: //作为GOTO代码的位置,即为解析结束后执行的收尾工作 this->endParsing(); return; } |
parseComment(_Iteratorb, _Iterator c)
|
template <typename _Iterator> voidhtmlcxx::HTML::ParserSax::parseComment(_Iterator b, _Iterator c) { // DEBUGP("Creatingcomment node %s\n", std::string(b, c).c_str()); //申请一个新的Node节点 htmlcxx::HTML::Nodecom_node; //FIXME:set_tagname shouldn't be needed, but first I must check //legacycode //申请一个string类型,用游标b,c之间的这段文本为其初始化赋值 std::stringcomment(b, c); //以下是利用各种变量为代表该Node的一些属性的数据成员进行复制 //具体方法的细节我们在后面分析Node.h(.cc)的时候再进行解释 com_node.tagName(comment); //tag名 com_node.text(comment); //文本 com_node.offset(mCurrentOffset); //在文档中的偏移值 com_node.length((unsignedint)comment.length()); //节点长度 com_node.isTag(false); //是否是标签 com_node.isComment(true); //是否是注释 mCurrentOffset+= com_node.length(); //将当前解析位置后移,移动到该节点的结束位置 //Call callback method //回调方法,将该节点插入已有的Html树中 this->foundComment(com_node); } |
parseContent(_Iteratorb, _Iterator c)
|
template <typename _Iterator> voidhtmlcxx::HTML::ParserSax::parseContent(_Iterator b, _Iterator c) { // DEBUGP("Creatingtext node %s\n", (std::string(b, c)).c_str()); //申请一个新的Node节点 htmlcxx::HTML::Nodetxt_node; //FIXME:set_tagname shouldn't be needed, but first I must check //legacycode //申请一个string类型,用游标b,c之间的这段文本为其初始化赋值 std::stringtext(b, c); //以下是利用各种变量为代表该Node的一些属性的数据成员进行复制 //具体方法的细节我们在后面分析Node.h(.cc)的时候再进行解释 txt_node.tagName(text); //tag名 txt_node.text(text); //文本 txt_node.offset(mCurrentOffset); //在文档中的偏移值 txt_node.length((unsignedint)text.length()); //节点长度 txt_node.isTag(false); //是否是标签 txt_node.isComment(false); //是否是注释 mCurrentOffset+= txt_node.length(); //将当前解析位置后移,移动到该节点的结束位置 //Call callback method //回调方法,将该节点插入已有的Html树中 this->foundText(txt_node); } |
parseHtmlTag(_Iteratorb, _Iterator c)
我们分三段来看这段代码,首先看第一段:
|
template <typename _Iterator> voidhtmlcxx::HTML::ParserSax::parseHtmlTag(_Iterator b, _Iterator c) { _Iteratorname_begin(b); //申请一个新的游标name_begin游标,初始为b ++name_begin; //将name_begin后移一位 boolis_end_tag = (*name_begin == '/'); //判断name_begin是否是’/’,如果是则说明是结束型tag标签 if(is_end_tag) ++name_begin; //如果是结束型的tag标签,则再将name_begin前进一位,跳过’/’符号 _Iteratorname_end(name_begin); //申请一个新的name_end游标,记录一下name_begin标签。 while(name_end != c && isalnum(*name_end)) //将name_end后移,直到遇到了文档末尾或者普通字符为止。 { ++name_end; } std::stringname(name_begin, name_end); //取name_begin和name_end之间的这段文本认为是tagName并赋值给一个string型的变量name |
|
if(!is_end_tag) //当然首先得判断这不是一个结束型的标签 { std::string::size_typetag_len = name.length(); for(int i = 0; literal_mode_elem[i].len; ++i) //循环进行查找 { if(tag_len == literal_mode_elem[i].len) //进行比较 { #ifdefined(WIN32) && !defined(__MINGW32__) //这段就是根据系统采用不同的string比较函数 if(!_stricmp(name.c_str(), literal_mode_elem[i].str)) #else if(!strcasecmp(name.c_str(), literal_mode_elem[i].str)) #endif { mpLiteral= literal_mode_elem[i].str; //如果找到,则将其赋值为mpLiteral break; //并退出循环 } } } } |
|
htmlcxx::HTML::Nodetag_node; //bynow, length is just the size of the tag //注意到,目前这还只是起始节点,因此长度只是<tag>本身的长度 std::stringtext(b, c); tag_node.length(static_cast<unsignedint>(text.length())); //节点长度 tag_node.tagName(name); //tag名 tag_node.text(text); //节点文本 tag_node.offset(mCurrentOffset); //在文档中的偏移位置 tag_node.isTag(true); //是否是tag标签 tag_node.isComment(false); //是否是注释 mCurrentOffset+= tag_node.length(); //将当前的解析位置后移 this->foundTag(tag_node,is_end_tag); //调用方法将其加入到已有的Html树中 } |
find_next_quote(_Iteratorc, _Iterator end, char quote)
|
template <typename _Iterator> static inline _Iterator find_next_quote(_Iterator c,_Iterator end, char quote) { // std::cerr<< "generic find" << std::endl; while(c != end && *c != quote) ++c; returnc; } |
*find_next_quote(constchar *c, const char *end, char quote)
|
template <> inline const char *find_next_quote(const char *c,const char *end, char quote) { // std::cerr<< "fast find" << std::endl; constchar *d = reinterpret_cast<const char*>(memchr(c, quote, end - c)); if(d) return d; elsereturn end; } |
skipHtmlTag(_Iteratorc, _Iterator end)
从游标c的位置开始,直到游标end的位置之间,寻找到该标签所对应的结束’>’符号的位置,并以游标形式返回。其中要注意对tag标签内的属性做了另外的处理,即能够识别并跳过属性中的’>’符号,防止出错。
|
template <typename _Iterator> _Iteratorhtmlcxx::HTML::ParserSax::skipHtmlTag(_Iterator c, _Iterator end) { while(c != end && *c != '>') { if(*c != '=') { ++c; } else {// found an attribute ++c; while(c != end && isspace(*c)) ++c; if(c == end) break; if(*c == '\"' || *c == '\'') { _Iteratorsave(c); charquote = *c++; c= find_next_quote(c, end, quote); // while(c != end && *c != quote) ++c; // c= static_cast<char*>(memchr(c, quote, end - c)); if(c != end) { ++c; } else { c= save; ++c; } // DEBUGP("Quotes:%s\n", std::string(save, c).c_str()); } } } if(c != end) ++c; returnc; } |
2.5 Node.h(.cc)
|
protected: std::stringmText; //节点的内部文本 std::stringmClosingText; unsignedint mOffset; //节点在原文档中的偏移值 unsignedint mLength; //节点的字符长度的 std::stringmTagName; //节点的Tag名 std::map<std::string,std::string> mAttributes; //存放属性的二维数组 boolmIsHtmlTag; //节点是否是HtmlTag标签 boolmComment; //节点是否是注释 |
|
public: Node(){} //构造函数 //Node(constNode &rhs); //uses default ~Node(){} //析构函数 inlinevoid text(const std::string& text) { this->mText = text; } inlineconst std::string& text() const { return this->mText; } inlinevoid closingText(const std::string &text) { this->mClosingText = text; } inlineconst std::string& closingText() const { return mClosingText; } inlinevoid offset(unsigned int offset) { this->mOffset = offset; } inlineunsigned int offset() const { return this->mOffset; } inlinevoid length(unsigned int length) { this->mLength = length; } inlineunsigned int length() const { return this->mLength; } inlinevoid tagName(const std::string& tagname) { this->mTagName = tagname; } inlineconst std::string& tagName() const { return this->mTagName; } boolisTag() const { return this->mIsHtmlTag; } voidisTag(bool is_html_tag){ this->mIsHtmlTag = is_html_tag; } boolisComment() const { return this->mComment; } voidisComment(bool comment){ this->mComment = comment; } |
主要了解一下下面这个函数
|
std::pair<bool,std::string> attribute(const std::string &attr) const { std::map<std::string,std::string>::const_iterator i = this->mAttributes.find(attr); if(i != this->mAttributes.end()) { returnmake_pair(true, i->second); }else { returnmake_pair(false, std::string()); } } |
该函数主要功能是根据参数string &attr,查找到mAttributes[]中的某个项,并且返回该项的第二个成员值,即根据属性的名称查找该属性的值。返回的形式为一个 make_pair数据类型,如果不为最后一个属性,则为make_pair(true,属性值),而如果是最后一个属性则返回一个 make_pair(false,空字符串)。
|
operatorstd::string() const; std::ostream&operator<<(std::ostream &stream) const; conststd::map<std::string, std::string>& attributes() const { returnthis->mAttributes; } voidparseAttributes(); booloperator==(const Node &rhs) const; |
parseAttributes()
由于这段代码较长,因此我们也分段对其进行解析。这段代码默认在mText中已经存放了节点的文本数据。并且通过对该文本数据进行解析,将所有诸如<…..ID = “abc”…>之类的属性信息识别并储存起来。
|
if(!(this->isTag())) return; //判断是否是Tag标签节点,不是则返回 constchar *end; constchar *ptr = mText.c_str(); //*ptr作为mText的*char类型指针 if((ptr = strchr(ptr, '<')) == 0) return; //将ptr指向字符串中首先出现的<位置,并判断该位置是否合法,如果不合法则返回。 ++ptr; //将ptr后移一个字节 //Skip initial blankspace while(isspace(*ptr)) ++ptr; //跳过接下来所有遇到的空格字符 //Skip tagname if(!isalpha(*ptr)) return; //判断是否是普通字符,不是则返回 while(!isspace(*ptr)) ++ptr; //不断后移ptr指针,直到遇到空格字符 //Skip blankspace after tagname while(isspace(*ptr)) ++ptr; //跳过接下来所有遇到的空格字符 |
下面进入一个循环,该循环将一直不断向后解析该tag标签,直到遇到了’>’字符或者指针为空才退出。
|
while(*ptr && *ptr != '>') { stringkey, val; //跳过所有无法识别的字节 while(*ptr && !isalnum(*ptr) && !isspace(*ptr)) ++ptr; //跳过所有的空格字符 while(isspace(*ptr)) ++ptr; end= ptr; //将end指向ptr之后第一个不为普通字符或’-’字符的位置 while(isalnum(*end) || *end == '-') ++end; //将ptr至end之间的这段文本变为小写字符赋值给key key.assign(end- ptr, '\0'); transform(ptr,end, key.begin(), ::tolower); ptr= end; //此时key中应当存放的是属性名 //跳过所有的空格字符 while(isspace(*ptr)) ++ptr; |
while(*ptr && *ptr != '>')
{
stringkey, val;
//跳过所有无法识别的字节
while(*ptr && !isalnum(*ptr) && !isspace(*ptr)) ++ptr;
//跳过所有的空格字符
while(isspace(*ptr)) ++ptr;
end= ptr;
//将end指向ptr之后第一个不为普通字符或’-’字符的位置
while(isalnum(*end) || *end == '-') ++end;
//将ptr至end之间的这段文本变为小写字符赋值给key
key.assign(end- ptr, '\0'); //注意要加上’\0’
transform(ptr,end, key.begin(), ::tolower);
ptr= end;
//此时key中应当存放的是属性名
//跳过所有的空格字符
while(isspace(*ptr)) ++ptr;
if(*ptr == '=') //如果后面跟的是’=’符号,说明后面就是属性值
{
++ptr; //将ptr后移一位
while(isspace(*ptr)) ++ptr; //跳过所有的空格字符
if(*ptr == '"' || *ptr == '\'') //判断属性值是否被引号括起
{
charquote = *ptr;
// fprintf(stderr,"Trying to find quote: %c\n", quote);
constchar *end = strchr(ptr + 1, quote);
if(end == 0)
{
//b= mText.find_first_of(" >", a+1);
constchar *end1, *end2;
end1= strchr(ptr + 1, ' ');
end2= strchr(ptr + 1, '>');
if(end1 && end1 < end2) end = end1;
elseend = end2;
if(end == 0) return;
}
constchar *begin = ptr + 1;
while(isspace(*begin) && begin < end) ++begin;
constchar *trimmed_end = end - 1;
while(isspace(*trimmed_end) && trimmed_end >= begin) --trimmed_end;
val.assign(begin,trimmed_end + 1);
ptr= end + 1;
}
else //否则直接获取其值
{
end= ptr;
while(*end && !isspace(*end) && *end != '>') end++;
val.assign(ptr,end);
ptr= end;
}
// fprintf(stderr,"%s = %s\n", key.c_str(), val.c_str());
mAttributes.insert(make_pair(key,val));
}
else//否则说明格式有错误,并将该key对应的值按空字符串插入结果集
{
// fprintf(stderr,"D: %s\n", key.c_str());
mAttributes.insert(make_pair(key,string()));
}
}
}
|
bool Node::operator==(const Node &n)const //判断两个Node是否都为tag标签,且tag名是否相等 { if(!isTag() || !n.isTag()) return false; return!(strcasecmp(tagName().c_str(), n.tagName().c_str())); } Node::operator string() const { //根据是否是tag标签,返回tagName或者text if(isTag()) return this->tagName(); returnthis->text(); } ostream &Node::operator<<(ostream&stream) const { //按对象输出Node stream<< (string)(*this); returnstream; } |
三.总结
对HtmlCxx进行学习,可以很好地掌握标准Html解析的流程,以及解析器的内部结构,并掌握C++编程时的一些好习惯和系统组织方式。遗憾的是 HtmlCxx在2005年之后就不再更新,且仅仅支持Mozilla的Html标准。它对Html的良构性要求比较高,对于一些含有错误的Html文 档,在解析时可能会出现一些意想不到的错误。
目前的文档中没有包含tree.h的代码说明,因为它属于第三方代码,希望了解的可以去http://tree.phi-sci.com/documentation.html了解具体的情况。后续有机会还会专门写一篇关于这个tree.h的文档。
转:HtmlCxx用户手册的更多相关文章
- Rafy 框架-发布网页版用户手册
前段时间把 Rafy 的用户手册由 CHM 格式转换为了网页格式,而且发布到了 github.io 上,即方便文档的实时更新,也方便大家查看. Rafy 用户手册网页版地址: http://zgynh ...
- sqlmap用户手册 | WooYun知识库
sqlmap用户手册 说明:本文为转载,对原文中一些明显的拼写错误进行修正,并标注对自己有用的信息. 原文:http://drops.wooyun.org/tips/143 ============ ...
- Windows Azure Web Site (1) 用户手册
<Windows Azure Platform 系列文章目录> 下载地址: Web Apps用户手册
- Windows Azure Cloud Service (1) 用户手册
<Windows Azure Platform 系列文章目录> 下载地址 Cloud Service用户手册
- Windows Azure Virtual Machine (1) IaaS用户手册
<Windows Azure Platform 系列文章目录> Azure IaaS用户手册 - Azure IaaS相关技术- Azure虚拟机成本分析- 创建Azure虚拟机- 使用 ...
- Azure SQL Database (1) 用户手册
<Windows Azure Platform 系列文章目录> 最新更新2016年6月17日 下载地址:Azure SQL Database用户手册
- AnyCAD .Net SDK 用户手册 v2013.1
AnyCAD .Net SDK 用户手册 v2013.1 1. 简介 AnyCAD .Net SDK为.Net4.0开发者提供简单易用的三维建模和三维可视化的API.SDK主要由三维建模的API和可视 ...
- C++ 使用Htmlcxx解析Html内容(VS编译库文件)
1.下载Htmlcxx,http://sourceforge.net/projects/htmlcxx/ 2.解压htmlcxx-0.85.tar.gz 3.打开htmlcxx.vcproj,注意是h ...
- EdasStudio 开发工具用户手册
EdasStudio 开发工具用户手册 Edas 开发组2015-8-14 1. 下载安装插件 EdasStudio是EDAS的开发工具,是一个Eclipse Plugins,打开Eclipse的He ...
随机推荐
- ★房贷计算器 APP
一.目的 1. 这是一个蛮有用的小工具 2. 之前看了很多demo,第一次来完全的自己实现一个APP 3. 完成之后提交 App Store 4. 作为Good Coder的提交审核材料 二.排期 周 ...
- ios 团购信息客户端demo(二)
接上一篇,这篇我们对我们的客户端加入KissXML,MBProgressHUD,AQridView这几个库,首先我们先加入KissXML,这是XML解析库,支持Xpath,可以方便添加更改任何节点.先 ...
- NSLayoutConstraint.constraintsWithVisualFormat详解,以及AlignAllCenterY
NSLayoutConstraint.constraintsWithVisualFormat详解,以及AlignAllCenterY 转载2015-07-08 18:02:02 鉴于苹果官方文档的解释 ...
- Ubuntu美化
Ubuntu美化 觉得ubuntu18.04的界面太丑了,所以决定美化一下. 整了好长时间特别费事.所以写个随笔记录一下. 安装gnome-tweak-tool和gnome-shell-extensi ...
- 【贪心 思维题】[USACO13MAR]扑克牌型Poker Hands
看似区间数据结构的一道题 题目描述 Bessie and her friends are playing a unique version of poker involving a deck with ...
- [CODEVS] 2193 数字三角形WW
数字三角形必须经过某一个点,使之走的路程和最大 从必须经过的点,向上向下分别DP两次的和即为答案. 还有一种思路是把和必须经过点同一行的设为-INF,这样就一定(大概)不会选择它们了. //Write ...
- (41)zabbix监控api接口性能及可用性 天气预报api为例
现在各种应用都走api,例如淘宝,天气预报等手机.pad客户端都是走api的,那么平时也得对这些api做监控了.怎么做呢?zabbix的web监控是不二选择了.今天就以天气预报api作为一个例子. 天 ...
- PERL学习之模式匹配
一.简介 模式指在字符串中寻找的特定序列的字符,由反斜线包含:/def/即模式def.其用法如结合函数split将字符串用某模式分成多个单词:@array = split(/ /, $line); ...
- 【转发】【linux】【php】centos 编译php常见错误
configure: error: xml2-config not found. Please check your libxml2 installation. yum install libxml2 ...
- Day17re模块和hashlib模块
re模块 正则表达式 用一些特殊符号拼凑成的规则,去字符串中匹配到符合规则的东西 为什么有正则表达式 从字符串中取出想要的数据 怎么用正则表达式 re.findall()结果存成列表 \w 匹配一个字 ...