Lucene:信息检索与全文检索
目录
- 信息检索的概念
- 信息检索技术的分类
- 全文检索与数据库查询对比
- 全文检索工具一般由三部分构成
- 全文检索中建立索引和进行检索的流程
- 索引里面究竟存什么
- 如何创建索引
- 如何对索引进行检索
- Lucene系统结构与源码组织图
- Lucene索引文件的概念组成和结构组成
1、信息检索的概念
信息检索就是从信息集合中找出与用户需求相关的信息。被检索出的信息除了文本外,还有图像、音频、视频等多媒体信息。
2、信息检索技术的分类
目前信息检索技术可分为3类:
- 全文检索:把用户的查询请求和全文中的每一个词进行比较,不考虑查询请求与文本语义上的匹配。在信息检索工具中,全文检索是最具通用性和实用性的。
- 数据检索:查询要求和信息系统中数据都遵循一定的格式,具有一定的结构,允许对特定的字段检索。其性能与使用有很多的局限性,并且支持语义匹配的能力较差。
- 知识检索:调用的是用于知识的、语义上的匹配。
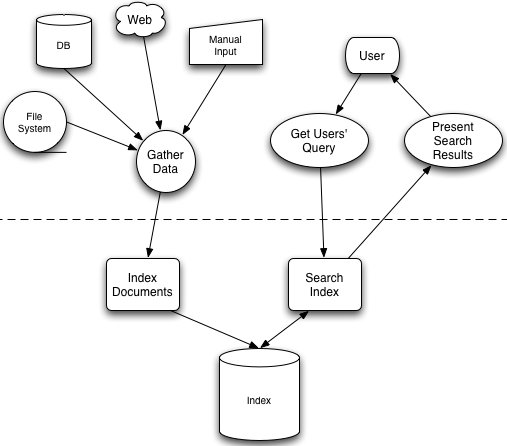
全文检索的一般过程
3、全文检索与数据库查询对比
全文检索出现的目的就是为了更快地查找信息;数据库查询效率低(例如拿一本字典来一页一页找,效率肯定很低)。全文搜索是按索引来找,效率高(从字典的索引找,再找到哪一页,效率会高)
4、全文检索工具一般由这样的三部分组成
全文检索工具一般由索引部分、分词部分和检索部分构成。
5、全文检索中建立索引与进行检索的流程
- 建立索引:就是对待检索的信息进行一定的分析,并将分析结果按照一定的组织方式存储起来,通常将这些结果存储在文件中。存储分析结果的文件的集合就是索引。在查询时,先从索引中查找,由于索引是按照一定的结构组织的,所以查询的速度非常快。
- 为提供检索的功能,信息检索系统会事先做一些准备工作:信息的采集与加工。
- 信息采集:把信息源的信息拷贝到本地,构成待检索的信息集合。(信息源可以是互联网中的网页、硬盘中的txt、doc、pdf等格式的电子文档,或是文件系统上的文件等等)。
- 信息加工:为采集到本地的信息编排索引,为查询做好准备。
流程如下:

6、索引里面究竟存什么?
假设:我的文档集合里面有100篇文档,为了方便表示,我们为文档编号从1到100,得到下面的结构
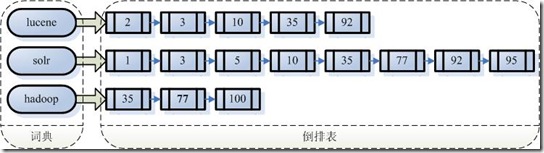
左边保存的是一系列字符串,称为词典。
每个字符串都指向包含此字符串的文档(Document)链表,此文档链表称为倒排表(Inverse List)。
有了索引,便使保存的信息和要搜索的信息一致,可以大大加快搜索的速度。
比如说,我们要寻找既包含字符串“lucene”又包含字符串“solr”的文档,我们只需要以下几步:
1. 取出包含字符串“lucene”的文档链表。
2. 取出包含字符串“solr”的文档链表。
3. 通过合并链表,找出既包含“lucene”又包含“solr”的文件。

看到这个地方,有人可能会说,全文检索的确加快了搜索的速度,但是多了索引的过程,两者加起来不一定比顺序扫描快多少。的确,加上索引的过程,全文检索不一定比顺序扫描快,尤其是在数据量小的时候更是如此。而对一个很大量的数据创建索引也是一个很慢的过程。
然而两者还是有区别的,顺序扫描是每次都要扫描,而创建索引的过程仅仅需要一次,以后便是一劳永逸的了,每次搜索,创建索引的过程不必经过,仅仅搜索创建好的索引就可以了。
这也是全文搜索相对于顺序扫描的优势之一:一次索引,多次使用。
7、如何创建索引
From:http://www.cnblogs.com/forfuture1978/archive/2009/12/14/1623594.html
全文检索的索引创建过程一般有以下几步:
第一步:一些要索引的原始文档(Document):为了方便说明索引创建过程,这里特意用两个文件为例:
- 文件一:Students should be allowed to go out with their friends, but not allowed to drink beer.
- 文件二:My friend Jerry went to school to see his students but found them drunk which is not allowed.
第二步:将原始文档传给分词组件(Tokenizer):分词组件(Tokenizer)会做以下几件事情(此过程称为Tokenize):
- 将文档分成一个一个单独的单词。
- 去除标点符号。
- 去除停词(Stop word)。
对于每一种语言的分词组件(Tokenizer),都有一个停词(stop word)集合。
经过分词(Tokenizer)后得到的结果称为词元(Token)。
在我们的例子中,便得到以下词元(Token):
“Students”,“allowed”,“go”,“their”,“friends”,“allowed”,“drink”,“beer”,“My”,“friend”,“Jerry”,“went”,“school”,“see”,“his”,“students”,“found”,“them”,“drunk”,“allowed”。
第三步:将得到的词元(Token)传给语言处理组件(Linguistic Processor)。
语言处理组件(linguistic processor)主要是对得到的词元(Token)做一些同语言相关的处理。
对于英语,语言处理组件(Linguistic Processor)一般做以下几点:
- 变为小写(Lowercase)。
- 将单词缩减为词根形式,如“cars”到“car”等。这种操作称为:stemming。
- 将单词转变为词根形式,如“drove”到“drive”等。这种操作称为:lemmatization。
Stemming 和 lemmatization的异同:
相同之处:Stemming和lemmatization都要使词汇成为词根形式。
- 两者的方式不同:
- Stemming采用的是“缩减”的方式:“cars”到“car”,“driving”到“drive”。
- Lemmatization采用的是“转变”的方式:“drove”到“drove”,“driving”到“drive”。
- 两者的算法不同:
- Stemming主要是采取某种固定的算法来做这种缩减,如去除“s”,去除“ing”加“e”,将“ational”变为“ate”,将“tional”变为“tion”。
- Lemmatization主要是采用保存某种字典的方式做这种转变。比如字典中有“driving”到“drive”,“drove”到“drive”,“am, is, are”到“be”的映射,做转变时,只要查字典就可以了。
- Stemming和lemmatization不是互斥关系,是有交集的,有的词利用这两种方式都能达到相同的转换。
语言处理组件(linguistic processor)的结果称为词(Term)。
在我们的例子中,经过语言处理,得到的词(Term)如下:
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”。
也正是因为有语言处理的步骤,才能使搜索drove,而drive也能被搜索出来。
第四步:将得到的词(Term)传给索引组件(Indexer)。
索引组件(Indexer)主要做以下几件事情:
1. 利用得到的词(Term)创建一个字典。
在我们的例子中字典如下:
|
Term |
Document ID |
|
student |
1 |
|
allow |
1 |
|
go |
1 |
|
their |
1 |
|
friend |
1 |
|
allow |
1 |
|
drink |
1 |
|
beer |
1 |
|
my |
2 |
|
friend |
2 |
|
jerry |
2 |
|
go |
2 |
|
school |
2 |
|
see |
2 |
|
his |
2 |
|
student |
2 |
|
find |
2 |
|
them |
2 |
|
drink |
2 |
|
allow |
2 |
2. 对字典按字母顺序进行排序。
|
Term |
Document ID |
|
allow |
1 |
|
allow |
1 |
|
allow |
2 |
|
beer |
1 |
|
drink |
1 |
|
drink |
2 |
|
find |
2 |
|
friend |
1 |
|
friend |
2 |
|
go |
1 |
|
go |
2 |
|
his |
2 |
|
jerry |
2 |
|
my |
2 |
|
school |
2 |
|
see |
2 |
|
student |
1 |
|
student |
2 |
|
their |
1 |
|
them |
2 |
3. 合并相同的词(Term)成为文档倒排(Posting List)链表。

在此表中,有几个定义:
- Document Frequency 即文档频次,表示总共有多少文件包含此词(Term)。
- Frequency 即词频率,表示此文件中包含了几个此词(Term)。
所以对词(Term) “allow”来讲,总共有两篇文档包含此词(Term),从而词(Term)后面的文档链表总共有两项,第一项表示包含“allow”的第一篇文档,即 1号文档,此文档中,“allow”出现了2次,第二项表示包含“allow”的第二个文档,是2号文档,此文档中,“allow”出现了1次。
到此为止,索引已经创建好了,我们可以通过它很快的找到我们想要的文档。
而且在此过程中,我们惊喜地发现,搜索 “drive”,“driving”,“drove”,“driven”也能够被搜到。因为在我们的索引 中,“driving”,“drove”,“driven”都会经过语言处理而变成“drive”,在搜索时,如果您输入“driving”,输入的查询 语句同样经过我们这里的一到三步,从而变为查询“drive”,从而可以搜索到想要的文档。
8、如何对索引进行搜索?
到这里似乎我们可以宣布“我们找到想要的文档了”,仅仅是找到了,但是并不是“理想”的结果。
然而事情并没有结束,找到了仅仅是全文检索的一个方面。不是吗?如果仅仅只有一个或十个文档包含我们查询的字符串,我们的确找到了。然而如果结果有一千个,甚至成千上万个呢?那个又是您最想要的文件呢?
打开Google吧,比如说您想在微软找份工作,于是您输入“Microsoft job”,您却发现总共有22600000个结果返回。好大的数字呀,突然发现找不到是一个问题,找到的太多也是一个问题。在如此多的结果中,如何将最相关的放在最前面呢?

当然Google做的很不错,您一下就找到了jobs at Microsoft。想象一下,如果前几个全部是“Microsoft does a good job at software industry…”将是多么可怕的事情呀。
如何像Google一样,在成千上万的搜索结果中,找到和查询语句最相关的呢?
如何判断搜索出的文档和查询语句的相关性呢?
这要回到我们第三个问题:如何对索引进行搜索?
搜索主要分为以下几步:
第一步:用户输入查询语句。
查询语句同我们普通的语言一样,也是有一定语法的。
不同的查询语句有不同的语法,如SQL语句就有一定的语法。
查询语句的语法根据全文检索系统的实现而不同。最基本的有比如:AND, OR, NOT等。
举个例子,用户输入语句:lucene AND learned NOT hadoop。
说明用户想找一个包含lucene和learned然而不包括hadoop的文档。
第二步:对查询语句进行词法分析,语法分析,及语言处理。
由于查询语句有语法,因而也要进行语法分析,语法分析及语言处理。
1. 词法分析主要用来识别单词和关键字。
如上述例子中,经过词法分析,得到单词有lucene,learned,hadoop, 关键字有AND, NOT。
如果在词法分析中发现不合法的关键字,则会出现错误。如lucene AMD learned,其中由于AND拼错,导致AMD作为一个普通的单词参与查询。
2. 语法分析主要是根据查询语句的语法规则来形成一棵语法树。
如果发现查询语句不满足语法规则,则会报错。如lucene NOT AND learned,则会出错。
如上述例子,lucene AND learned NOT hadoop形成的语法树如下:

3. 语言处理同索引过程中的语言处理几乎相同。
如learned变成learn等。
经过第二步,我们得到一棵经过语言处理的语法树。

第三步:搜索索引,得到符合语法树的文档。
此步骤有分几小步:
- 首先,在反向索引表中,分别找出包含lucene,learn,hadoop的文档链表。
- 其次,对包含lucene,learn的链表进行合并操作,得到既包含lucene又包含learn的文档链表。
- 然后,将此链表与hadoop的文档链表进行差操作,去除包含hadoop的文档,从而得到既包含lucene又包含learn而且不包含hadoop的文档链表。
- 此文档链表就是我们要找的文档。
第四步:根据得到的文档和查询语句的相关性,对结果进行排序。
虽然在上一步,我们得到了想要的文档,然而对于查询结果应该按照与查询语句的相关性进行排序,越相关者越靠前。
如何计算文档和查询语句的相关性呢?
不如我们把查询语句看作一片短小的文档,对文档与文档之间的相关性(relevance)进行打分(scoring),分数高的相关性好,就应该排在前面。
那么又怎么对文档之间的关系进行打分呢?
这可不是一件容易的事情,首先我们看一看判断人之间的关系吧。
首先看一个人,往往有很多要素,如性格,信仰,爱好,衣着,高矮,胖瘦等等。
其次对于人与人之间的关系,不同的要素重要性不同,性格,信仰,爱好可能重要些,衣着,高矮,胖瘦可能就不那么重要了,所以具有相同或相似性格,信仰,爱好的人比较容易成为好的朋友,然而衣着,高矮,胖瘦不同的人,也可以成为好的朋友。
因而判断人与人之间的关系,首先要找出哪些要素对人与人之间的关系最重要,比如性格,信仰,爱好。其次要判断两个人的这些要素之间的关系,比如一个人性格开朗,另一个人性格外向,一个人信仰佛教,另一个信仰上帝,一个人爱好打篮球,另一个爱好踢足球。我们发现,两个人在性格方面都很积极,信仰方面都很善良,爱好方面都爱运动,因而两个人关系应该会很好。
我们再来看看公司之间的关系吧。
首先看一个公司,有很多人组成,如总经理,经理,首席技术官,普通员工,保安,门卫等。
其次对于公司与公司之间的关系,不同的人重要性不同,总经理,经理,首席技术官可能更重要一些,普通员工,保安,门卫可能较不重要一点。所以如果两个公司总经理,经理,首席技术官之间关系比较好,两个公司容易有比较好的关系。然而一位普通员工就算与另一家公司的一位普通员工有血海深仇,怕也难影响两个公司之间的关系。
因而判断公司与公司之间的关系,首先要找出哪些人对公司与公司之间的关系最重要,比如总经理,经理,首席技术官。其次要判断这些人之间的关系,不如两家公司的总经理曾经是同学,经理是老乡,首席技术官曾是创业伙伴。我们发现,两家公司无论总经理,经理,首席技术官,关系都很好,因而两家公司关系应该会很好。
分析了两种关系,下面看一下如何判断文档之间的关系了。
首先,一个文档有很多词(Term)组成,如search, lucene, full-text, this, a, what等。
其次对于文档之间的关系,不同的Term重要性不同, 比如对于本篇文档,search, Lucene, full-text就相对重要一些,this, a , what可能相对不重要一些。所以如果两篇文档都包含search, Lucene,fulltext,这两篇文档的相关性好一些,然而就算一篇文档包含this, a, what,另一篇文档不包含this, a, what,也不能影响两篇文档的相关性。
因而判断文档之间的关系,首先找出哪些词(Term)对文档之间的关系最重要,如search, Lucene, fulltext。然后判断这些词(Term)之间的关系。
找出词(Term)对文档的重要性的过程称为计算词的权重(Term weight)的过程。
计算词的权重(term weight)有两个参数,第一个是词(Term),第二个是文档(Document)。
词的权重(Term weight)表示此词(Term)在此文档中的重要程度,越重要的词(Term)有越大的权重(Term weight),因而在计算文档之间的相关性中将发挥更大的作用。
判断词(Term)之间的关系从而得到文档相关性的过程应用一种叫做向量空间模型的算法(Vector Space Model)。
下面仔细分析一下这两个过程:
1. 计算权重(Term weight)的过程。
影响一个词(Term)在一篇文档中的重要性主要有两个因素:
- Term Frequency(tf):即给定的Term在此文档中出现了多少次。tf 越大说明越重要。这个数字通常会被归一化,以防止它偏向长的文件。(注:同一个词语Term在长文件里可能会比短文件有更高的词频,而不管该词语重要与否)
- Document Frequency(df):即有多少文档包含此Term。df越大说明越不重要。
- Inverse Document Frequency(idf):是一个词语Term普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
注意:TF-IDF=TF*IDF。某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
例子:有很多不同的数学公式可以用来计算TF-IDF。这边的例子以上述的数学公式来计算。词频 (TF)
是
一词语出现的次数除以该文件的总词语数。假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是
3/100=0.03。一个计算文件频率(DF)
的方法是测定有多少份文件出现过“母牛”一词,然后除以文件集里包含的文件总数。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是
10,000,000份的话,其逆向文件频率就是log(10,000,000 / 1,000)=4。最后的TF-IDF的分数为0.03 *
4=0.12。
容易理解吗?词(Term)在文档中出现的次
数越多,说明此词(Term)对该文档越重要,如“搜索”这个词,在本文档中出现的次数很多,说明本文档主要就是讲这方面的事的。然而在一篇英语文档
中,this出现的次数更多,就说明越重要吗?不是的,这是由第二个因素进行调整,第二个因素说明,有越多的文档包含此词(Term),
说明此词(Term)太普通,不足以区分这些文档,因而重要性越低。
这也如我们程序员所学的技术,对于程序员本身来说,这项技术掌握越深越好(掌握越深说明花时间看的越多,tf越大),找工作时越有竞争力。然而对于所有程序员来说,这项技术懂得的人越少越好(懂得的人少df小),找工作越有竞争力。人的价值在于不可替代性就是这个道理。
道理明白了,我们来看看公式:


这仅仅只term weight计算公式的简单典型实现。实现全文检索系统的人会有自己的实现,Lucene就与此稍有不同。有关Lucene计算公式可以参考官方文档(V4.0)。
2. 判断Term之间的关系从而得到文档相关性的过程,也即向量空间模型的算法(VSM)。
我们把文档看作一系列词(Term),每一个词(Term)都有一个权重(Term weight),不同的词(Term)根据自己在文档中的权重来影响文档相关性的打分计算。
于是我们把所有此文档中词(term)的权重(term weight) 看作一个向量。
Document = {term1, term2, …… ,term N}
Document Vector = {weight1, weight2, …… ,weight N}
同样我们把查询语句看作一个简单的文档,也用向量来表示。
Query = {term1, term 2, …… , term N}
Query Vector = {weight1, weight2, …… , weight N}
我们把所有搜索出的文档向量及查询向量放到一个N维空间中,每个词(term)是一维。
如图:

我们认为两个向量之间的夹角越小,相关性越大。
所以我们计算夹角的余弦值作为相关性的打分,夹角越小,余弦值越大,打分越高,相关性越大。
有人可能会问,查询语句一般是很短的,包含的词(Term)是很少的,因而查询向量的维数很小,而文档很长,包含词(Term)很多,文档向量维数很大。你的图中两者维数怎么都是N呢?
在这里,既然要放到相同的向量空间,自然维数是相同的,不同时,取二者的并集,如果不含某个词(Term)时,则权重(Term Weight)为0。
相关性打分公式如下:

举个例子,查询语句和三篇文章共有11个Term。其中假定各自的权重(Term weight)如下表格。(注意:没有详细计算,只是找了一些数据作为样本数据,具体的计算过程不同的问题可以采用不同的算法,如前面的log函数可以采用不同的底数等。)
|
t1 |
t2 |
t3 |
t4 |
t5 |
t6 |
t7 |
t8 |
t9 |
t10 |
t11 |
|
|
D1 |
0 |
0 |
.477 |
0 |
.477 |
.176 |
0 |
0 |
0 |
.176 |
0 |
|
D2 |
0 |
.176 |
0 |
.477 |
0 |
0 |
0 |
0 |
.954 |
0 |
.176 |
|
D3 |
0 |
.176 |
0 |
0 |
0 |
.176 |
0 |
0 |
0 |
.176 |
.176 |
|
Q |
0 |
0 |
0 |
0 |
0 |
.176 |
0 |
0 |
.477 |
0 |
.176 |
于是计算,三篇文档同查询语句的相关性打分分别为:



于是文档二相关性最高,先返回,其次是文档三,最后是文档一。
到此为止,我们可以找到我们最想要的文档了。
说了这么多,其实还没有进入到Lucene,
而仅仅是信息检索技术(Information
retrieval)中的基本理论,然而当我们看过Lucene后我们会发现,Lucene是对这种基本理论的一种基本的的实践。所以在以后分析
Lucene的文章中,会常常看到以上理论在Lucene中的应用。
在进入Lucene之前,对上述索引创建和搜索过程所一个总结,如图:
此图参照http://www.lucene.com.cn/about.htm中文章《开放源代码的全文检索引擎Lucene》

Lucene系统结构与源码组织图
从图中我们清楚的看到,Lucene的系统由
基础结构封装、索引核心、对外接口三大部分组成。其中直接操作索引文件的索引核心又是系统的重点。Lucene的将所有源码分为了7个模块(在java语
言中以包即package来表示),各个模块所属的系统部分也如上图所示。需要说明的是org.apache.lucene.queryPaser是做为
org.apache.lucene.search的语法解析器存在,不被系统之外实际调用,因此这里没有当作对外接口看待,而是将之独立出来。
从面象对象的观点来考察,Lucene应用了
最基本的一条程序设计准则:引入额外的抽象层以降低耦合性。首先,引入对索引文件的操作org.apache.lucene.store的封装,然后将索
引部分的实现建立在(org.apache.lucene.index)其之上,完成对索引核心的抽象。在索引核心的基础上开始设计对外的接口
org.apache.lucene.search与org.apache.lucene.analysis。在每一个局部细节上,比如某些常用的数据结
构与算法上,Lucene也充分的应用了这一条准则。在高度的面向对象理论的支撑下,使得Lucene的实现容易理解,易于扩展。
Lucene在系统结构上的另一个特点表现为
其引入了传统的客户端服务器结构以外的的应用结构。Lucene可以作为一个运行库被包含进入应用本身中去,而不是做为一个单独的索引服务器存在。这自然
和Lucene开放源代码的特征分不开,但是也体现了Lucene在编写上的本来意图:提供一个全文索引引擎的架构,而不是实现。

Lucene索引文件的概念组成和结构组成
Lucene的索引文件的概念结构描述。
Lucene索引index由若干段(segment)组成,每一段由若干的文档(document)组成,每一个文档由若干的域(field)组成,每
一个域由若干的项(term)组成。项是最小的索引概念单位,它直接代表了一个字符串以及其在文件中的位置、出现次数等信息。域是一个关联的元组,由一个
域名和一个域值组成,域名是一个字串,域值是一个项,比如将“标题”和实际标题的项组成的域。文档是提取了某个文件中的所有信息之后的结果,这些组成了
段,或者称为一个子索引。子索引可以组合为索引,也可以合并为一个新的包含了所有合并项内部元素的子索引。我们可以清楚的看出,Lucene的索引结构在
概念上即为传统的倒排索引(倒排文件或倒排索引是指索引对象是文档或者文档集合中的单词等,用来存储这些单词在一个文档或者一组文档中的存储位置,是对文
档或者文档集合的一种最常用的索引机制。)结构。
1. 索引过程:
- 有一系列被索引文件
- 被索引文件经过语法分析和语言处理形成一系列词(Term)。
- 经过索引创建形成词典和反向索引表。
- 通过索引存储将索引写入硬盘。
2. 搜索过程:
- 用户输入查询语句。
- 对查询语句经过语法分析和语言分析得到一系列词(Term)。
- 通过语法分析得到一个查询树。
- 通过索引存储将索引读入到内存。
- 利用查询树搜索索引,从而得到每个词(Term)的文档链表,对文档链表进行交,差,并得到结果文档。
- 将搜索到的结果文档对查询的相关性进行排序。
- 返回查询结果给用户。
转载自 http://www.cnblogs.com/bluepoint2009/archive/2012/09/25/lucene-information-retrieval-and-fulltext-retrieval.html
Lucene:信息检索与全文检索的更多相关文章
- 使用Lucene.Net实现全文检索
使用Lucene.Net实现全文检索 目录 一 Lucene.Net概述 二 分词 三 索引 四 搜索 五 实践中的问题 一 Lucene.Net概述 Lucene.Net是一个C#开发的开源全文索引 ...
- Lucene作为一个全文检索引擎
Lucene作为一个全文检索引擎,其具有如下突出的优点: (1)索引文件格式独立于应用平台.Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件. ...
- 干货 |《从Lucene到Elasticsearch全文检索实战》拆解实践
1.题记 2018年3月初,萌生了一个想法:对Elasticsearch相关的技术书籍做拆解阅读,该想法源自非计算机领域红火已久的[樊登读书会].得到的每天听本书.XX拆书帮等. 目前市面上Elast ...
- 《从Lucene到Elasticsearch全文检索实战》的P184页
curl -XPOST "http://localhost:9200/_bulk?pretty" --data-binary @books.json 这句话在书中是以crul的命令 ...
- Lucene实践:全文检索的基本原理
一.总论 根据http://lucene.apache.org/java/docs/index.html 定义: "Apache Lucene(TM) is a high-performan ...
- Apache Lucene(全文检索引擎)—创建索引
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
- JAVAEE——Lucene基础:什么是全文检索、Lucene实现全文检索的流程、配置开发环境、索引库创建与管理
1. 学习计划 第一天:Lucene的基础知识 1.案例分析:什么是全文检索,如何实现全文检索 2.Lucene实现全文检索的流程 a) 创建索引 b) 查询索引 3.配置开发环境 4.创建索引库 5 ...
- Lucene的全文检索学习
Lucene的官方网站(Apache的顶级项目):http://lucene.apache.org/ 1.什么是Lucene? Lucene 是 apache 软件基金会的一个子项目,由 Doug C ...
- 全文检索引擎 Lucene.net
全文搜索引擎是目前广泛应用的主流搜索引擎.它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行 ...
随机推荐
- HTTPS通信机制
概述 使用HTTP协议进行通信时,由于传输的是明文所以很容易遭到窃听,就算是加密过的信息也容易在传输中遭受到篡改,因此需要在HTTP协议基础上添加加密处理,认证处理等,有了这些处理机制的HTTP成为H ...
- LeetCode: JumpGame 1 and 2
Title : Given an array of non-negative integers, you are initially positioned at the first index of ...
- 用C/C++开发基于VLC SDK的视频播放器
在windows系统如果开发万能播放器,一般都是基本DirectShow来开发,开发也很简单,但缺点也很多,一个文件格式是否能够播放完全取决于你 是否安装了正确的解析器和解码器,即使现在有了万能解器安 ...
- 庖丁解牛-----Live555源码彻底解密(RTP解包)
Live555 客户端解包 以testRTSPClient.cpp为例讲解: Medium<-MediaSource<-FramedSource<-RTPSource<-Mul ...
- 多线程监控文件夹,FlieSystemWatcher,并使用共享函数
发表于: 2011-01-06 09:55:47 C# code ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 2 ...
- 使用rsync同步Linux数据到Windows
windows: win7,cwrsyncserver 4.1.0 linux:ubuntu 14.04,rsync 3.1.0 networks:使用360wifi [Windows端] 是否使用管 ...
- angular+rails集成实战
http://start.jcolemorrison.com/setting-up-an-angularjs-and-rails-4-1-project/ 1. 添加gemgem 'sprockets ...
- .NET Remoting
.NET Remoting .NET Remoting是微软早期的分布式通信技术,虽然微软后来通过WCF通用基础通信框架整合掉了,但是通过回顾学习Remoting,反过来学习理解WCF也是很有帮助 ...
- C++ primer里的template用法
来源:http://c.chinaitlab.com/cc/ccjq/200806/752604_2.html -- template 的用法 在程序设计当中经常会出现使用同种数据结构的不同实 ...
- BLOCK 死循环
__weak typeof(self) weakSelf = self; myObj.myBlock = ^{ __strong typeof(self) strongSelf = weak ...