Spark如何解决常见的Top N问题

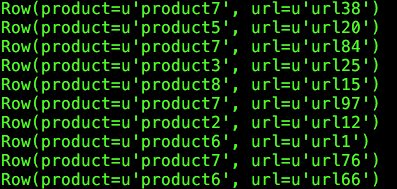

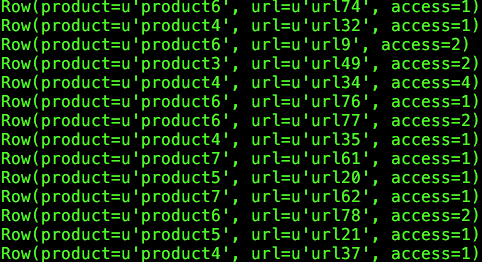



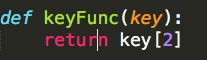




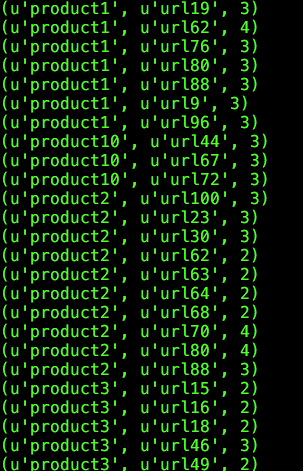
Spark如何解决常见的Top N问题的更多相关文章
- Spark程序运行常见错误解决方法以及优化
转载自:http://bigdata.51cto.com/art/201704/536499.htm Spark程序运行常见错误解决方法以及优化 task倾斜原因比较多,网络io,cpu,mem都有可 ...
- 如何解决海量数据的Top K问题
1. 问题描述 在大规模数据处理中,常遇到的一类问题是,在海量数据中找出出现频率最高的前K个数,或者从海量数据中找出最大的前K个数,这类问题通常称为“top K”问题,如:在搜索引擎中,统计搜索最热门 ...
- 【Spark篇】---Spark故障解决(troubleshooting)
一.前述 本文总结了常用的Spark的troubleshooting. 二.具体 1.shuffle file cannot find:磁盘小文件找不到. 1) connection timeout ...
- Spark 学习笔记 —— 常见API
一.RDD 的创建 1)通过 RDD 的集合数据结构,创建 RDD sc.parallelize(List(1,2,3),2) 其中第二个参数代表的是整个数据,分为 2 个 partition,默认情 ...
- 【spark】示例:求Top值
我们有这样的两个文件 第一个数字为行号,后边为三列数据.我们来求第二列数据的Top(N) (1)我们先读取数据,创建Rdd (2)过滤数据,取第二列数据. 我们用filter()来过滤数据 line. ...
- Git 项目上传至github入门实战并解决常见错误
1.Git GUI 首先,在push到github的项目必须先建立版本(即creat repository的名字一样),一般是先pull下来,再push(为了防止有其他人提交了代码,而你却不知道,造 ...
- iOS runtime实用篇解决常见Crash
程序崩溃经历 其实在很早之前就想写这篇文章了,一直拖到现在. 程序崩溃经历1 平时开发测试的时候好好的,结果上线几天发现有崩溃的问题,其实责任大部分在我身上. 我的责任: 过分信赖文档,没进行容错处理 ...
- 【spark】dataframe常见操作
spark dataframe派生于RDD类,但是提供了非常强大的数据操作功能.当然主要对类SQL的支持. 在实际工作中会遇到这样的情况,主要是会进行两个数据集的筛选.合并,重新入库. 首先加载数据集 ...
- CM5.x配置spark错误解决
通过cloudera manager 5.x添加spark服务,在创建服务过程中,发现spark服务创建失败,可以通过控制台错误输出看到如下日志信息: + perl -pi -e 's#{{CMF_C ...
随机推荐
- navicat 数据库管理工具快捷键
最近在使用navicat 管理数据库中,因为经常要写一些sql的,但是每次都要鼠标点击运行,感觉很不爽,于是找到navicat(以下) 快捷键(最常用的): ctrl + q 打开查询窗口 ctrl ...
- TransactionScope简单用法
记录TransactionScope简单用法,示例如下: void Test() { using (TransactionScope scope = new TransactionScope()) { ...
- Lucene技术杂谈
Lucene教程 1 lucene简介 1.1 什么是lucene Lucene是一个全文搜索框架,而不是应用产品.因此它并不像www.baidu.com 或者google Desktop那么 ...
- asp.net - GridView根据linkButton值不同跳转不同页面
一,当前页面中,前台界面的主要代码: <asp:TemplateField HeaderText="姓名"> <ItemTemplate> <!--根 ...
- iOS多Targets管理
序言: 个人不善于写东西,就直奔主题了. 其实今天会注意到多targets这个东西,是因为在学习一个第三方库FBMemoryProfiler的时候,用到了,所以就搜索了一些相关资料,就在这里记录一下. ...
- iOS,长按图片保存实现方法,轻松搞定!
1.添加手势识别: UITapGestureRecognizer *tap = [[UITapGestureRecognizer alloc]initWithTarget:self action:@s ...
- 请描述一下 cookies,sessionStorage 和 localStorage 的区别?
http://handyxuefeng.blog.163.com/blog/static/454521722013111714040259/ http://book.51cto.com/art/201 ...
- javascript 用函数实现“继承”
一.知识储备: 1.枚举属性名称的函数: (1)for...in:可以在循环体中遍历对象中所有可枚举的属性(包括自有属性和继承属性) (2)Object.keys():返回数组(可枚举的自有属性) ( ...
- Windowsphone 之xml序列化和反序列化的应用(WebService解析返回的数据DataSet )
关于Xml的序列化和反序列化: 可以看这篇文章,http://www.cnblogs.com/Windows-phone/p/3243575.html WebService解析返回的数据DataSet ...
- WPF RadioButton & CheckBox Style
<Style TargetType="CheckBox"> <Setter Property="Template"> <Sette ...