memcached分布式实现原理
摘要 在高并发环境下,大量的读、写请求涌向数据库,此时磁盘IO将成为瓶颈,从而导致过高的响应延迟,因此缓存应运而生。无论是单机缓存还是分布式缓存都有其适应场景和优缺点,当今存在的缓存产品也是数不胜数,最常见的有redis和memcached等,既然是分布式,那么他们是怎么实现分布式的呢?本文主要介绍分布式缓存服务mencached的分布式实现原理。
目录[-]
摘要
在高并发环境下,大量的读、写请求涌向数据库,此时磁盘IO将成为瓶颈,从而导致过高的响应延迟,因此缓存应运而生。无论是单机缓存还是分布式缓存都有其适应场景和优缺点,当今存在的缓存产品也是数不胜数,最常见的有redis和memcached等,既然是分布式,那么他们是怎么实现分布式的呢?本文主要介绍分布式缓存服务mencached的分布式实现原理。
缓存本质
计算机体系缓存
什么是缓存,我们先看看计算机体系结构中的存储体系,根据冯·诺依曼计算机体系结构模型,计算机分为五大部分:运算器、控制器、存储器、输入设备、输出设备。结合现代计算机,CPU包含运算器和控制器两个部分,CPU负责计算,其需要的数据由存储提供,存储分为几个级别,就拿我当前的PC举个例子,我的机器存储清单如下:
356G的磁盘
4G的内存
3MB三级缓存
256KB二级缓存(pre core)
除了上述部分,还有CPU内的寄存器,当然有的计算机还有一级缓存等。CPU运算器工作的时候需要数据,数据哪里来?首先从距离CPU最近的二级缓存去拿,这块缓存速度最快,通常也是体积最小,因为价格最贵:
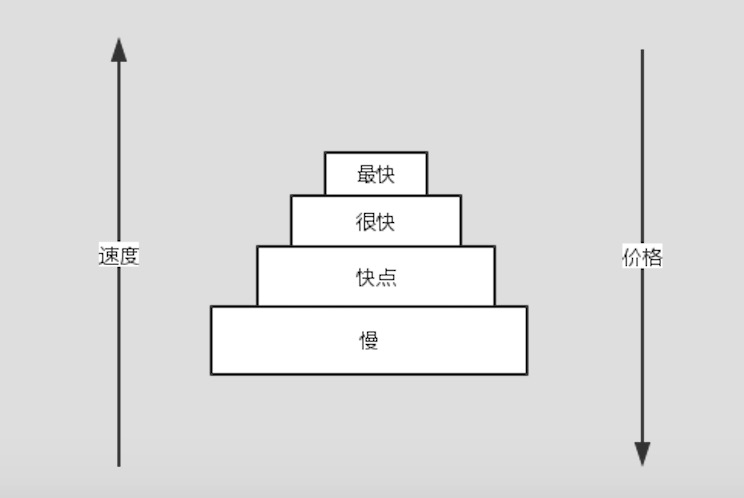
存储金字塔
如上图所示,存储体系就像个金子塔,最上层最快,价格最贵,最下层最慢,价格也最便宜,CPU的数据源优先级一层层从上到下去寻找数据。
很显然,除了最慢的那块存储,在计算机体系中,相对较快的那些存储都可以被称为缓存,他们解决的问题是让存储访问更快。
缓存应用系统
计算机体系存储系统模型扩展到应用也是一样,应用需要数据,数据哪里来?缓存(更快的存储)->DB(较慢的存储),他们的工作流程大致如下图所示:
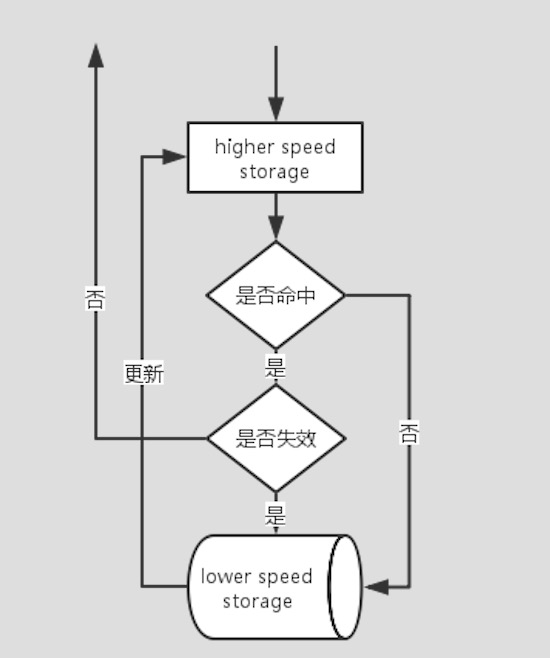
带缓存的存储访问一般模型
如上图所示,缓存应用系统一般存储访问流程:首先访问缓存较快的存储介质,如果命中且未失效则返回内容,如果未命中或失效则访问较慢的存储介质将内容返回同时更新缓存。
memcached简介
什么是memcached
memcached是LiveJournal旗下的Danga Interactive公司的Brad Fitzpatric为首开发的一款软件。现在已经成为mixi、hatena、Facebook、Vox、LiveJournal等众多服务中提高Web应用扩展性的重要因素。传统的Web应用都将数据保存到RDBMS中,应用服务器从RDBMS中读取数据、处理数据并在浏览器中显示。但是随着数据量增大、访问的集中、就会出现RDBMS的负担加重、数据库响应变慢、导致整个系统响应延迟增加。
而memcached就是为了解决这个问题而出现的,memcached是一款高性能的分布式内存缓存服务器,一般目的是为了通过缓存数据库的查询命中减少数据库压力、提高应用响应速度、提高可扩展性。
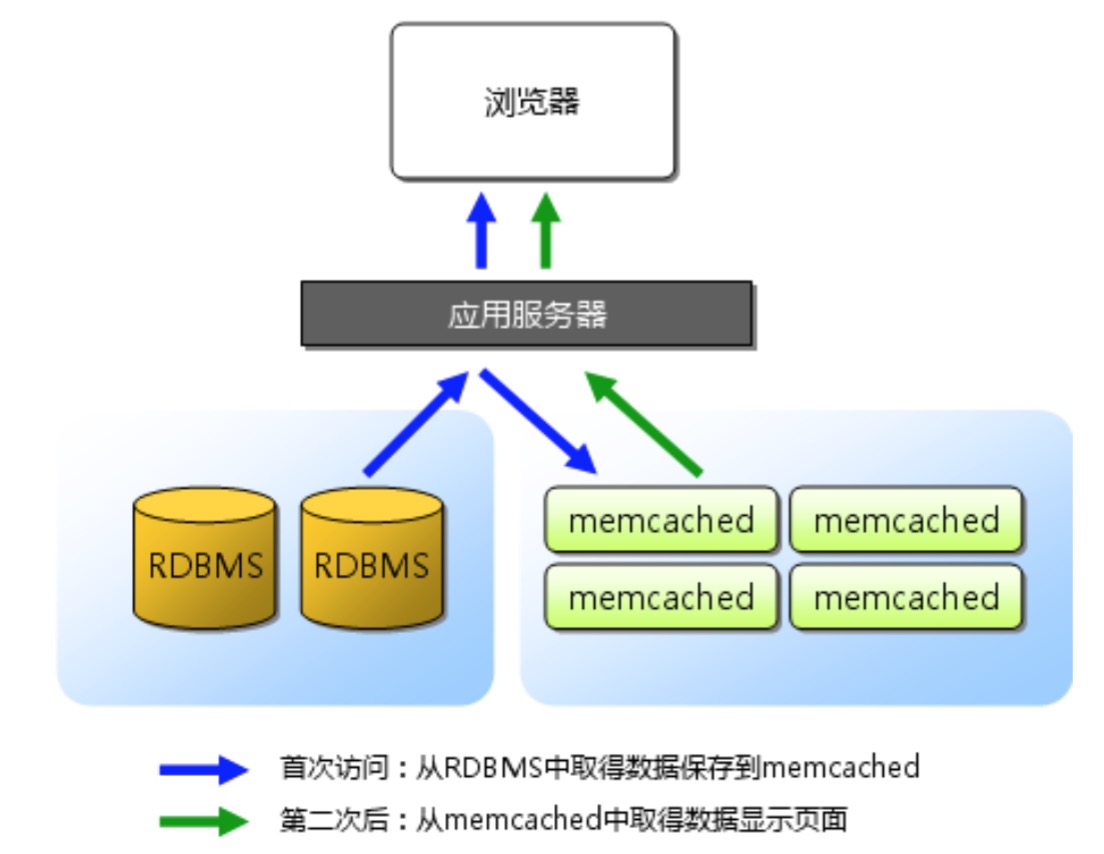
memcached缓存应用
memcached缓存特点
协议简单
基于libevent的事件处理
内置内存存储方式
memcached不相互通信的分布式
memcached分布式原理
今天的内容主要涉及memcached特点的第四条,memcached不相互通信,那么memcached是如何实现分布式的呢?memcached的分布式实现主要依赖客户端的实现:
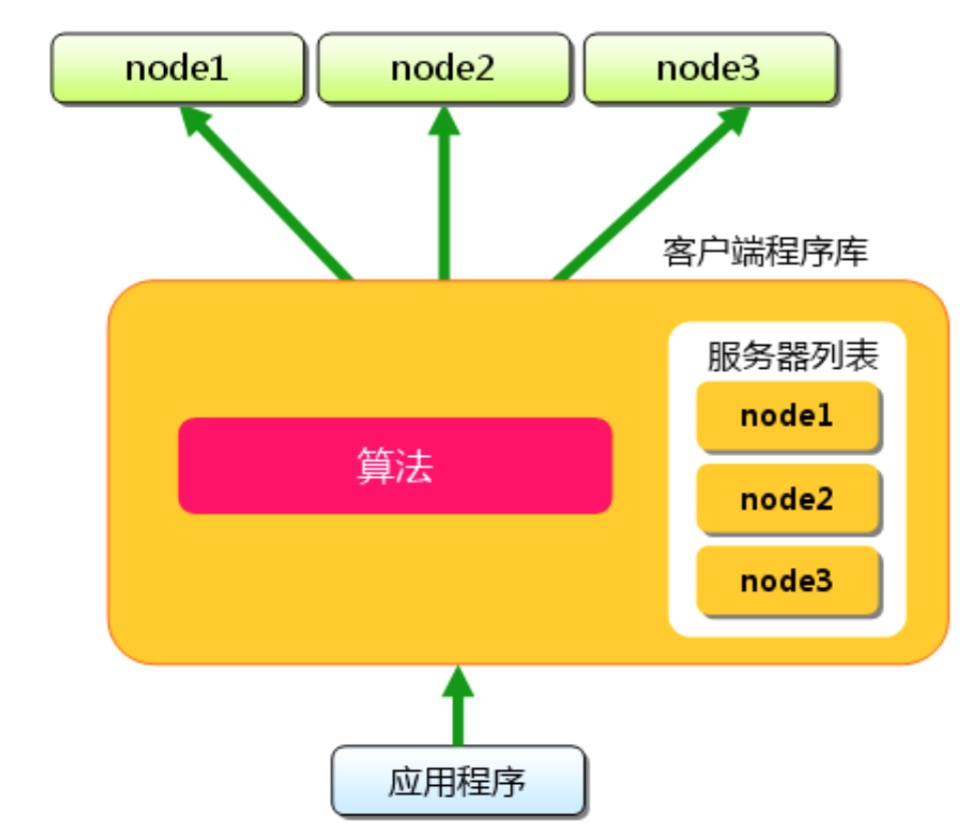
memcached分布式
如上图所示,我们看下缓存的存储的一般流程:
当数据到达客户端,客户端实现的算法就会根据“键”来决定保存的memcached服务器,服务器选定后,命令他保存数据。取的时候也一样,客户端根据“键”选择服务器,使用保存时候的相同算法就能保证选中和存的时候相同的服务器。
余数计算分散法
余数计算分散法是memcached标准的memcached分布式方法,算法如下:
|
1
|
CRC($key)%N |
该算法下,客户端首先根据key来计算CRC,然后结果对服务器数进行取模得到memcached服务器节点,对于这种方式有两个问题值得说明一下:
当选择到的服务器无法连接的时候,一种解决办法是将尝试的连接次数加到key后面,然后重新进行hash,这种做法也叫rehash。
第二个问题也是这种方法的致命的缺点,尽管余数计算分散发相当简单,数据分散也很优秀,当添加或者移除服务器的时候,缓存重组的代价相当大。
Consistent Hashing算法
Consistent Hashing算法描述如下:首先求出memcached服务器节点的哈希值,并将其分配到0~2^32的圆上,这个圆我们可以把它叫做值域,然后用同样的方法求出存储数据键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上,如果超过0~2^32仍找不到,就会保存在第一台memcached服务器上:

memcachd基本原理
再抛出上面的问题,如果新添加或移除一台机器,在consistent Hashing算法下会有什么影响。上图中假设有四个节点,我们再添加一个节点叫node5:

添加了node节点之后
node5被放在了node4与node2之间,本来映射到node2和node4之间的区域都会找到node4,当有node5的时候,node5和node4之间的还是找到node4,而node5和node2之间的此时会找到node5,因此当添加一台服务器的时候受影响的仅仅是node5和node2区间。
优化的Consistent Hashing算法
上面可以看出使用consistent Hashing最大限度的抑制了键的重新分配,且有的consistent Hashing的实现方式还采用了虚拟节点的思想。问题起源于使用一般hash函数的话,服务器的映射地点的分布非常不均匀,从而导致数据库访问倾斜,大量的key被映射到同一台服务器上。为了避免这个问题,引入了虚拟节点的机制,为每台服务器计算出多个hash值,每个值对应环上的一个节点位置,这种节点叫虚拟节点。而key的映射方式不变,就是多了层从虚拟节点再映射到物理机的过程。这种优化下尽管物理机很少的情况下,只要虚拟节点足够多,也能够使用得key分布的相对均匀。
总结
本文介在理解缓存基本概念的情况下介绍了memcached的分布式算法实现原理,memcached的分布式是由客户端函数库实现的。
参考文献:
《大型分布式网站架构设计与实践》
《memcached全面解析》
注:本文由博主原创,欢迎提出宝贵意见。
memcached分布式实现原理的更多相关文章
- Memcached 分布式缓存实现原理
摘要 在高并发环境下,大量的读.写请求涌向数据库,此时磁盘IO将成为瓶颈,从而导致过高的响应延迟,因此缓存应运而生.无论是单机缓存还是分布式缓存都有其适应场景和优缺点,当今存在的缓存产品也是数不胜数, ...
- Memcached 分布式缓存实现原理简介
摘要 在高并发环境下,大量的读.写请求涌向数据库,此时磁盘IO将成为瓶颈,从而导致过高的响应延迟,因此缓存应运而生.无论是单机缓存还是分布式缓存都有其适应场景和优缺点,当今存在的缓存产品也是数不胜数, ...
- 让memcached分布式
memcached是应用最广的开源cache产品,它本身不提供分布式的解决方案,我猜想一方面它想尽量保持产品简单高效,另一方面cache的key-value的特性使得让memcached分布式起来比较 ...
- memcached 分布式
memcached定义 memcached 是一套分布式的高速缓存系统,被广泛应用于应用系统的缓存层来提升应用程序的访问速度:memcache缺乏认证以及安全管制,这表明应将memcached服务器放 ...
- 利用多写Redis实现分布式锁原理与实现分析(转)
利用多写Redis实现分布式锁原理与实现分析 一.关于分布式锁 关于分布式锁,可能绝大部分人都会或多或少涉及到. 我举二个例子:场景一:从前端界面发起一笔支付请求,如果前端没有做防重处理,那么可能 ...
- Python分布式爬虫原理
转载 permike 原文 Python分布式爬虫原理 首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的. (1)打开浏览器,输入URL,打开源网页 (2)选取我们想要的内容,包括标题,作 ...
- memcached 分布式聚类算法
memcached 分布式集群,该决定必须书面开发商自己.和redis 由分布式server决定.上 memcached 有两个选项用于分布式.第一个是:模运算 另一种是:一致性hash 分布式算法. ...
- 深度剖析Spark分布式执行原理
让代码分布式运行是所有分布式计算框架需要解决的最基本的问题. Spark是大数据领域中相当火热的计算框架,在大数据分析领域有一统江湖的趋势,网上对于Spark源码分析的文章有很多,但是介绍Spark如 ...
- memcached分布式缓存
1.memcached分布式简介 memcached虽然称为“分布式”缓存服务器,但服务器端并没有“分布式”功能.Memcache集群主机不能够相互通信传输数据,它的“分布式”是基于客户端的程序逻辑算 ...
随机推荐
- asp.net 批量下载实现(打包压缩下载)
1.aspx <%@ Page Language="C#" AutoEventWireup="true" CodeBehind="Default ...
- oracle 10g 恢复dmp文件。
1. 在winxp下,安装10g,默认选择,一路ok.(安装前自检出现dhcp警告,可直接忽略) 2.命令行,在xp下,输入sqlplus,即可启动,登陆用 sqlplus / as sysdba 用 ...
- 【转】伟大的RAC和MVVM入门(一)
原文:http://www.sprynthesis.com/2014/12/06/reactivecocoa-mvvm-introduction/ 翻译自ReactiveCocoa and MVV ...
- 通过移位与或非运算获取整形最大值,最小值,以及获取输入的int类型整数的二进制表示
以上是最终效果 实现类: package com.corejava.chap02; public class IntBin { private int value; public IntBin(int ...
- 主成份分析PCA
Data Mining 主成分分析PCA 降维的必要性 1.多重共线性--预测变量之间相互关联.多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯. 2.高维空间本身具有稀疏性.一维正态分布有6 ...
- vs2008 下编译jrtplib-3.9.0成功
jrtplib-3.9.0的编译,终于搞通了.网上搜集了很多资料,自己也调试了很久. 首先,jrtplib-3.9.0是什么不用多说吧,它是一个很牛的老外用C++写的一个开源的RTP协议库,用它可以进 ...
- poj 1273.PIG (最大流)
网络流 关键是建图,思路在代码里 /* 最大流SAP 邻接表 思路:基本源于FF方法,给每个顶点设定层次标号,和允许弧. 优化: 1.当前弧优化(重要). 1.每找到以条增广路回退到断点(常数优化). ...
- 封装Timer
System.Timers.Timer,System.Timers.Timer在使用的过程中需要: 1.构造函数不同,构造函数可以什么事情也不做,也可以传入响应间隔时间:System.Timers.T ...
- 【实习记】2014-08-10(上)代码跟踪git的想法+归并排序的debug过程
(冒泡,选择,插入,希尔,快速,归并,堆排)周末加班学习C++,打算用C++写七大经典排序代码.发现3个月前自己写的七大经典排序代码(C Language)突然运行出错. Makefile内容 ...
- [Windows] php开发工具,zendstudio13使用方法补丁
官网原版下载 http://downloads.zend.com/studio ... win32.win32.x86.exe 破解补丁: 链接:http://pan.baidu.com/s/1gdi ...