关于InnoDB存储引擎text和blob类型的优化
我们在数据库优化的时候,看到一些表在设计上使用了text或者blob的字段,如果单表的存储空间达到了近上百G或者大几十G,这种情况再去改变和优化就非常难了
一、简介
为了清楚大字段对性能的影响,我们有必要知道innodb存储引擎的处理方式:
1、一些知识点
1.1 在InnoDB 1.0.x版本之前,InnoDB 存储引擎提供了 Compact 和 Redundant(Redundant 格式是为兼容之前版本而保留的) 两种格式来存放行记录数据,compact 和 redundant 合称为Antelope (羚羊)
对于blob,text,varchar(5120)这样的大字段,innodb只会存放前768字节在数据页中,而剩余的数据则会存储在溢出段中(发生溢出情况的时候适用),最大768字节的作用是便于创建前缀索引/prefix index,其余更多的内容存储在额外的page里,哪怕只是多了一个字节。因此,所有列长度越短越好
- 大字段在InnoDB里可能浪费大量空间。例如,若存储字段值只是比行的要求多了一个字节,也会使用整个页面来存储剩下的字节,浪费了页面的大部分空间。如果有一个值只是稍微超过了32个页的大小,实际上就需要使用96个页面
- 扩展存储禁用了自适应哈希,因为需要完整的比较列的整个长度,才能发现是不是正确的数据(哈希帮助InnoDB非常快速的找到“猜测的位置”,但是必须检查“猜测的位置”是不是正确)。因为自适应哈希是完全的内存结构,并且直接指向Buffer Pool中访问“最”频繁的页面,但对于扩展存储空间却无法使用Adaptive Hash
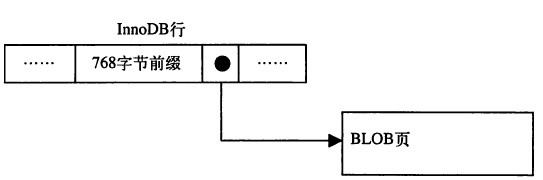
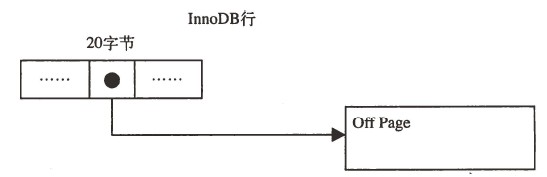
1.2 MySQL 5.1 中的 innodb_plugin 引入了新的文件格式:Barracuda (梭子鱼),该文件格式拥有新的两种行格式:compressed和dynamic,两种格式对blob字段采用完全溢出的方式,数据页中只存放20字节,其余的都存放在溢出段中,因此,强烈不建议使用BLOB、TEXT、超过255长度的VARCHAR列类型;
1.3 innodb的page大小默认为16kb,innodb存储引擎表为索引组织表,树底层的叶子节点为一双向链表,因此每个页中至少应该有两行记录,这就决定了innodb在存储一行数据的时候不能够超过8k,但事实上应该更小,因为还有一些InnoDB内部数据结构要存储,5.6版本以后,新增选项 innodb_page_size 可以修改,在5.6以前的版本,只能修改源码重新编译,但并不推荐修改这个配置
1.4 InnoDB的data page在有新数据写入时,会预留1/16的空间,预留出来的空间可用于后续的新纪录写入,减少频繁的新增data page的开销,受限于InnoDB存储方式,数据如果是顺序写入的话,最理想的情况下,data page的填充率是15/16,但一般没办法保证完全的顺序写入,因此data page的填充率一般是1/2到15/16。因此每个InnoDB表都最好要有一个自增列作为主键,使得新纪录写入尽可能是顺序的;当data page填充率不足1/2时,InnoDB会进行收缩,释放空闲空间
1.5 COMPACT行格式相比REDUNDANT,大概能节省20%的存储空间,COMPRESSED相比COMPACT大概能节省50%的存储空间,但会导致TPS下降了90%。因此强烈不推荐使用COMPRESSED行格式
1.6 使用了blob数据类型,是不是一定就会存放在溢出段中?通常我们认为blob这类的大对象的存储会把数据存放在数据页之外,其实不然,关键点还是要看一个page中到底能否存放两行数据,blob可以完全存放在数据页中(单行长度没有超过8096字节),而varchar类型的也有可能存放在溢出页中(单行长度超过8096字节,前768字节存放在数据页中)
1.7 mysql在操作数据的时候,以page为单位,不管是更新,插入,删除一行数据,都需要将那行数据所在的page读到内存中,然后在进行操作,这样就存在一个命中率的问题,如果一个page中能够相对的存放足够多的行,那么命中率就会相对高一些,性能就会有提升
1.8 在off-page中存储的BLOB、TEXT或者长VARCHAR列的page是独享的,不能共享。因此强烈不建议在一个表中使用多个长列
1.9 MySQL 5.6 中默认还是 Compact 行格式,也是目前使用最多的一种 ROW FORMAT。用户可以通过命令 SHOW TABLE STATUS LIKE'table_name' 来查看当前表使用的行格式,其中 row_format 列表示当前所使用的行记录结构类型

mysql>desc db_page;
+-----------------+----------------+----------------+---------------+-------------------+-----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+----------------+----------------+---------------+-------------------+-----------------+
| id | int(11) | NO | PRI | | auto_increment |
| title | varchar(100) | NO | | | |
| name | varchar(100) | YES | | | |
| content | text | YES | | | |
+-----------------+----------------+----------------+---------------+-------------------+-----------------+
mysql>show variables like "innodb_file_format";
+-------------------------+-----------------+
| Variable_name | Value |
+-------------------------+-----------------+
| innodb_file_format | Barracuda |
+-------------------------+-----------------+
mysql>show table status like "db_page" \G
*************************** 1. row ***************************
Name: db_page
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 2
Avg_row_length: 8192
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: 3
Create_time: 2017-03-07 13:30:19
Update_time:
Check_time:
Collation: utf8_general_ci
Checksum:
Create_options:
Comment:
Block_format: Original
在 msyql 5.7.9 及以后版本,默认行格式由innodb_default_row_format变量决定,它的默认值是DYNAMIC,也可以在 create table 的时候指定ROW_FORMAT=DYNAMIC。
注意,如果要修改现有表的行模式为compressed或dynamic,必须先将文件格式设置成Barracuda:set global innodb_file_format=Barracuda;,再用ALTER TABLE tablename ROW_FORMAT=COMPRESSED;去修改才能生效,否则修改无效却无提示
二、对TEXT/BLOB这类大字段类型的影响
2.1 compact
变长大字段类型包括blob,text,varchar,其中varchar列值长度大于某数N时也会存溢出页,在latin1字符集下N值可以这样计算:innodb的块大小默认为16kb,由于innodb存储引擎表为索引组织表,树底层的叶子节点为一双向链表,因此每个页中至少应该有两行记录,这就决定了innodb在存储一行数据的时候不能够超过8k,减去其它列值所占字节数,约等于N。对于InnoDB,内存是极为珍贵的,如果把768字节长度的blob都放在数据页,虽然可以节省部分IO,但是能缓存行数就变少,也就是能缓存的索引值变少了,降低了索引效率
2.2 dynamic
dynamic行格式,列存储是否放到off-page页,主要取决于行大小,它会把行中最长的那一列放到off-page,直到数据页能存放下两行。TEXT/BLOB列 <=40 bytes 时总是存放于数据页。这种方式可以避免compact那样把太多的大列值放到 B-tree Node,因为dynamic格式认为,只要大列值有部分数据放在off-page,那把整个值放入都放入off-page更有效。
compressed 物理结构上与dynamic类似,但是对表的数据行使用zlib算法进行了压缩存储。在long blob列类型比较多的情况下用,可以降低off-page的使用,减少存储空间(一般40%左右),但要求更高的CPU,buffer pool里面可能会同时存储数据的压缩版和非压缩版,所以也多占用部分内存。这里 MySQL 5.6 Manual innodb-compression-internals 讲的十分清楚。
另外,由于ROW_FORMAT=DYNAMIC 和 ROW_FORMAT=COMPRESSED 是从 ROW_FORMAT=COMPACT 变化来的,所以他们处理 CHAR类型存储的方式和 COMPACT 一样。
三. 对TEXT/BLOB型字段存取优化
mysql的 io 以page为单位,因此不必要的数据(大字段)也会随着需要操作的数据一同被读取到内存中来,这样带来的问题由于大字段会占用较大的内存(相比其他小字段),使得内存利用率较差,造成更多的随机读取。从上面的分析来看,我们已经看到性能的瓶颈在于由于大字段存放在数据页中,造成了内存利用较差,带来过多的随机读,那怎么来优化掉这个大字段的影响
3.1 压缩&合并
a、innodb提供了barracuda文件格式,将大字段完全存放在溢出段中,数据段中只存放20个字节,这样就大大的减小了数据页的空间占用,使得一个数据页能够存放更多的数据行,也就提高了内存的命中率(对于本实例,大多数行的长度并没有超过8k,所以优化的幅度有限);如果对溢出段的数据进行压缩,那么在空间使用上也会大大的降低,具体的的压缩比率可以设置key_blok_size来实现。
b、可以把大字段用COMPRESS()压缩后再存为BLOB,或者在发送到MySQL前在应用程序中进行压缩
c、一张表有多个类blob字段,把它们组合起来如<TEXT><f_big_col1>long..</f_big_col1> <f_content>long..</f_content></TEXT>,再压缩存储
d、如果预期长度范围varchar就满足,就避免使用TEXT
3.2 拆分
将主表拆分为一对一的两个关联表,将大字段单独放到另外一张表后,单行长度变的非常的小,page的行密度相比原来的表大很多,这样就能够缓存足够多的行,buffer pool的命中率就会提高,应用程序需要额外维护的是一张大字段的子表,还可以通过覆盖索引来优化,将索引和原表结构分开,从访问密度较小的数据页改为访问密度很大的索引页,随机io转换为顺序io
总结:还是让单个page能够存放足够多的行,不断的提示内存的命中率,从数据库底层存储的原理出发,能够更深刻的优化数据库
综上,如果在实际业务中,确实需要在InnoDB表中存储BLOB、TEXT、长VARCHAR列时,有下面几点建议:
尽可能将所有数据序列化、压缩之后,存储在同一个列里,避免发生多次off-page
如果预期长度范围varchar就满足,就避免使用TEXT
如果无法将所有列整合到一个列,可以退而求其次,根据每个列最大长度进行排列组合后拆分成多个子表,尽量是的每个子表的总行长度小于8KB,减少发生off-page的频率
关于InnoDB存储引擎text和blob类型的优化的更多相关文章
- 【mysql】关于InnoDB存储引擎 text blob 大字段的存储和优化
最近在数据库优化的时候,看到一些表在设计上使用了text或者blob的字段,单表的存储空间已经达到了近100G,这种情况再去改变和优化就非常难了 一.简介 为了清楚大字段对性能的影响,我们必须要知道i ...
- 关于InnoDB存储引擎 text blob 大字段的存储和优化
最近在数据库优化的时候,看到一些表在设计上使用了text或者blob的字段,单表的存储空间已经达到了近100G,这种情况再去改变和优化就非常难了 一.简介 为了清楚大字段对性能的影响,我们必须要知道i ...
- InnoDB 存储引擎的主要知识点介绍
本文转载自:Draveness,略有修改 原文链接:『浅入浅出』MySQL 和 InnoDB · 面向信仰编程 作为一名开发人员,在日常的工作中会难以避免地接触到数据库,无论是基于文件的 sqlite ...
- 《MySQL技术内幕:InnoDB存储引擎(第2版)》书摘
MySQL技术内幕:InnoDB存储引擎(第2版) 姜承尧 第1章 MySQL体系结构和存储引擎 >> 在上述例子中使用了mysqld_safe命令来启动数据库,当然启动MySQL实例的方 ...
- 一文带你读懂 Mysql 和 InnoDB存储引擎
作为一名开发人员,在日常的工作中会难以避免地接触到数据库,无论是基于文件的 sqlite 还是工程上使用非常广泛的 MySQL.PostgreSQL,但是一直以来也没有对数据库有一个非常清晰并且成体系 ...
- MySQL内核:InnoDB存储引擎 卷1
MySQL内核:InnoDB存储引擎卷1(MySQL领域Oracle ACE专家力作,众多MySQL Oracle ACE力捧,深入MySQL数据库内核源码分析,InnoDB内核开发与优化必备宝典) ...
- MySQL技术内幕InnoDB存储引擎(三)——文件相关
构成MySQL数据库和InnoDB存储引擎表的文件类型有: 参数文件:MySQL实例运行时需要的参数就是存储在这里. 日志文件:用来记录MySQL实例对某种条件做出响应时写入的文件. socket文件 ...
- InnoDB存储引擎的锁
InnoDB存储引擎的锁 锁的类型 锁的类型包括: 1. 共享锁(S lock),允许事务读取一行数据 2. 排他锁(X lock),允许事务删除或更新一行数据 锁的兼容性a X S ...
- MySQL InnoDB存储引擎中的锁机制
1.隔离级别 Read Uncommited(RU):这种隔离级别下,事务间完全不隔离,会产生脏读,可以读取未提交的记录,实际情况下不会使用. Read Committed (RC):仅能读取到已提交 ...
随机推荐
- Unity-奥义技能背景变黑效果
[旧博客转移 - 2016年8月29日 12:51 ] 前段时间做了一个放技能的时候,背景缓慢变黑,放完后再变回来的效果,可以很好的突出技能特效的感觉. 算是一种屏幕后期特效,这个特效说难不难,说简单 ...
- CentOS7 yum安装zabbix3.2.6
前言: 本人小白,在一个多月前通过面试进入公司,在进入公司的第一天,老板把我叫到他办公室,坐下来慢慢喝茶,吹牛,给我吹他们以前做的软件,经营的产品,还装作一副什么都告诉我的样子,其实这都是套路,我早已 ...
- zlib报“LNK2001:无法解析的外部符号”错误
这个错误一般是由使用导出dll时未加载对应的lib文件导致的,但是工程在正确配置了lib文件的情况下仍然报这个错误,经查,是由于dll导入工程和dll导出工程的函数调用约定不一致导致的. 一.函数调用 ...
- css display:box 新属性
一.display:box; 在元素上设置该属性,可使其子代排列在同一水平上,类似display:inline-block;. 二.可在其子代设置如下属性 前提:使用如下属性,必须在父代设置displ ...
- 【高斯消元】兼 【期望dp】例题
[总览] 高斯消元基本思想是将方程式的系数和常数化为矩阵,通过将矩阵通过行变换成为阶梯状(三角形),然后从小往上逐一求解. 如:$3X_1 + 2X_2 + 1X_3 = 3$ $ ...
- 处理SFTP服务器上已离职用户,设置为登录禁用状态
测试用户禁用SQL select Enabled,LoginID from suusers where LoginID = 'yangwl' update suusers set Enabled=1 ...
- .Net 调用微信公众号扫一扫
1.绑定域名 去微信公众号平台中设置js接口安全域名,要注意的是不填写http://, 只填写域名即可,如 www.baidu.com. 一个月只能修改三次,要谨慎填写. 2.引入JS文件 在页面中引 ...
- Objective-C 自定义UISlider滑杆 分段样式
效果 自定义一个功能简单的分段的滑杆 可显示分段名 为了显示效果,我们将滑块和节点都设置为不规则 这里只实现了分段的slider,未分段的没有实现,有兴趣的可以定义另一种类型做个判断修改下 需求分析 ...
- zTree新增的根结点再新增子节点reAsyncChildNodes不生效解决方案
zTree新增的根结点再新增子节点reAsyncChildNodes不生效解决方案, zTree新的根结点不能异步刷新,reAsyncChildNodes不生效解决方案, reAsyncChildNo ...
- CSS随笔1(CSS常用样式)
样式 属性 大小 font-size(x-large ; xx-small ; 可用数值单位 : PX,PD) 样式 font-style(oblique 偏斜体 : italic 斜体 : norm ...