用 BeautifulSoup爬取58商品信息
最近对Python爬虫比较迷恋,看了些爬虫相关的教程
于是乎跟着一起爬取了58上面的一些商品信息,并存入到xlsx文件中,并通过xlsxwirter的方法给表格设置了一些格式。好了,直接贴代码吧~
- #coding:utf-8
- from bs4 import BeautifulSoup
- import requests
- import sys
- import xlsxwriter
- import re
- reload(sys)
- sys.setdefaultencoding('utf8')
- def get_links_from(urls,who_sell=0,page=1):
- list_view = 'http://bj.58.com/haidian/pbdn/{}/pn{}/'.format(str(who_sell), str(page))
- web_data = requests.get(list_view)
- soup = BeautifulSoup(web_data.text, "lxml")
- for url in soup.select('td.t a.t'):
- url = url.get('href').split('?')[0]
- if url.find('zhuanzhuan.58.com') != -1:
- urls.append(url)
- is_next = soup.select('.next')
- if is_next: #如果存在下一页,继续获取url并保存到urls
- get_links_from(urls,who_sell,page+1)
- return urls
- def get_views_from(url):
- id = url.split('/')[-1].strip('z.shtml')
- api = 'http://jst1.58.com/counter?infoid={}'.format(id)
- js = requests.get(api)
- view = js.text.split('=')[-1]
- return view
- def get_item_info(who_sell):
- datas = []
- urls = []
- urls = get_links_from(urls,who_sell,1)
- workbook = xlsxwriter.Workbook(u'F:/Python27/magua/download/二手平板.xlsx')
- worksheet = workbook.add_worksheet('haidian')
- format = workbook.add_format({'bold':True, 'font_color': 'B452CD', 'font_size': 16, 'align':'center', 'bg_color':'FFA54F'})
- worksheet.set_row(0, 20) #设置第1行的单元格高度
- worksheet.set_column('A:A', 100) #设置第A列的单元格长度
- worksheet.set_column('C:C', 15) #设置第C列的单元格长度
- worksheet.set_column('D:D', 15) #设置第D列的单元格长度
- worksheet.set_column('E:E', 15) #设置第E列的单元格长度
- worksheet.write(0, 0, '标题', format)
- worksheet.write(0, 1, '价格', format)
- worksheet.write(0, 2, '区域', format)
- worksheet.write(0, 3, '个人/商家', format)
- worksheet.write(0, 4, '浏览量', format)
- # workbook.close()
- # return
- row_num = 1
- for url in urls:
- web_data = requests.get(url)
- soup = BeautifulSoup(web_data.text, "lxml")
- data = {
- 'title':soup.title.text.strip(), #strip 去掉字符串中的换行、制表符
- 'price':soup.select('.price_now i')[0].text, # #代表id
- 'area':soup.select('.palce_li i')[0].text,
- 'cate':u'个人' if who_sell ==0 else u'商家',
- 'view':soup.select('.look_time')[0].text.split('次')[0],
- # 'views':get_views_from(url),
- }
- # datas.append(data)
- if row_num%2:
- format_ = workbook.add_format({'bg_color': 'FFEC8B', 'font_size': 12})
- else:
- format_ = workbook.add_format({'bg_color': 'FFDAB9', 'font_size': 12})
- #write the data into .xlsx file
- worksheet.write(row_num, 0, data['title'], format_)
- worksheet.write(row_num, 1, data['price'], format_)
- worksheet.write(row_num, 2, data['area'], format_)
- worksheet.write(row_num, 3, data['cate'], format_)
- worksheet.write(row_num, 4, data['view'], format_)
- row_num = row_num + 1
- workbook.close()
- '''
- for item in datas:
- print repr(item).decode("unicode-escape")
- # print item
- print "total: %d" % len(datas)
- '''
- get_item_info(0) #参数 0为个人,1为商家
在这过程中有点不明白的地方就是xlsxwriter.Workbook 方法在创建xlsx文件的时候,必须要绝对路径才能成功,看官方文档也没找到问题的原因
最后抓取信息所生成的表格文件截图
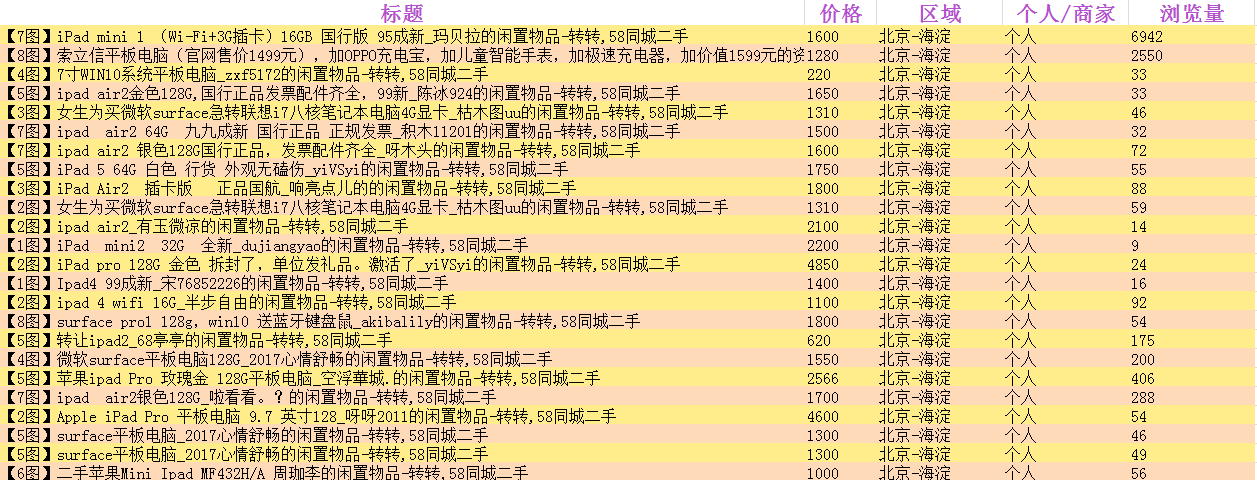
用 BeautifulSoup爬取58商品信息的更多相关文章
- selenium+phantomjs爬取京东商品信息
selenium+phantomjs爬取京东商品信息 今天自己实战写了个爬取京东商品信息,和上一篇的思路一样,附上链接:https://www.cnblogs.com/cany/p/10897618. ...
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- Python爬虫-爬取京东商品信息-按给定关键词
目的:按给定关键词爬取京东商品信息,并保存至mongodb. 字段:title.url.store.store_url.item_id.price.comments_count.comments 工具 ...
- 爬虫—Selenium爬取JD商品信息
一,抓取分析 本次目标是爬取京东商品信息,包括商品的图片,名称,价格,评价人数,店铺名称.抓取入口就是京东的搜索页面,这个链接可以通过直接构造参数访问https://search.jd.com/Sea ...
- Python爬虫学习之使用beautifulsoup爬取招聘网站信息
菜鸟一只,也是在尝试并学习和摸索爬虫相关知识. 1.首先分析要爬取页面结构.可以看到一列搜索的结果,现在需要得到每一个链接,然后才能爬取对应页面. 关键代码思路如下: html = getHtml(& ...
- 八个commit让你学会爬取京东商品信息
我发现现在不用标题党的套路还真不好吸引人,最近在做相关的事情,从而稍微总结出了一些文字.我一贯的想法吧,虽然才疏学浅,但是还是希望能帮助需要的人.博客园实在不适合这种章回体的文章.这里,我贴出正文的前 ...
- 利用selenium爬取京东商品信息存放到mongodb
利用selenium爬取京东商城的商品信息思路: 1.首先进入京东的搜索页面,分析搜索页面信息可以得到路由结构 2.根据页面信息可以看到京东在搜索页面使用了懒加载,所以为了解决这个问题,使用递归.等待 ...
- scrapy 爬取天猫商品信息
spider # -*- coding: utf-8 -*- from urllib.parse import urlencode import requests import scrapy impo ...
- python爬虫——用selenium爬取京东商品信息
1.先附上效果图(我偷懒只爬了4页) 2.京东的网址https://www.jd.com/ 3.我这里是不加载图片,加快爬取速度,也可以用Headless无弹窗模式 options = webdri ...
随机推荐
- pl/sql 笔记之存储过程、函数、包、触发器(下)
一.存储过程.存储函数 1.What's This? ①.ORACLE 提供可以把 PL/SQL 程序存储在数据库中,并可以在任何地方来运行它.这样就叫存储过程或函数. ②.存储过程.存储函数的唯 ...
- 函数, lambda表达式
函数 函数:简单的理解,就是一次执行很多行代码 函数的返回值 函数的参数,和变量没区别 例: def hello(): print "hello world" hello() he ...
- cannot locate symbol "atof" referenced by错误分析
ndk从r8升级到r10后, 使用eclipse编译出来的so库报错了,加载库的时候报错cannot locate symbol "atof" referenced by 原因:A ...
- 经验分享:如何用grep对PHP进行代码审计
这是一个常见的误解- 企业需要购买复杂和昂贵的软件来发现应用程序中安全漏洞:而这些专门的软件应用程序,无论是黑盒或白盒,开源或商业,都能很快的发现安全漏洞. 事实是:所有这些专业的漏洞扫描工具都有其特 ...
- macOS 中的 Rootless 机制
一.前因 苹果从 OS X El Capitan 10.11 系统开始使用了 Rootless 机制,可以将该机制理解为一个更高等级的系统的内核保护措施,系统默认将会锁定 /system./sbin. ...
- 根据优先关系矩阵使用逐次加一发构造优先函数(Java)
若已知运算符之间的优先关系,可按如下步骤构造优先函数: 1.对每个运算符a(包括#在内)令f(a)=g(a)=1 2.如果a⋗b且f(a)<=g(b)令f(a)=g(b)+1 3.如果a⋖b且f ...
- 高性能linux服务器内核调优
高性能linux服务器内核调优 首先,介绍一下两个命令1.dmesg 打印系统信息.有很多同学们服务器出现问题,看了程序日志,发现没啥有用信息,还是毫无解决头绪,这时候,你就需要查看系统内核抛出的异常 ...
- 属于自己的MES(一)概念
什么叫MES(生产制造执行系统)? 从几个方面来简单说下: 1.定位 没有MES前的工厂生产模式,公司MRP系统与生产现场之间透过人为方式沟通,使生产现场如同黑箱作业,无法掌握实时正确信息. MES的 ...
- 回锅的美食:JSP+EL+JSTL大杂烩汤
title: Servlet之JSP tags: [] notebook: javaWEB --- JSP是什么 ? JSP就是Servlet,全名是"JavaServer Pages&qu ...
- 连锁反应confirm
<script> function del(){ var flag = confirm("你真要删除么?"); if( flag ){ alert("我已被你 ...