纯手工打造简单分布式爬虫(Python)
前言
这次分享的文章是我《Python爬虫开发与项目实战》基础篇 第七章的内容,关于如何手工打造简单分布式爬虫 (如果大家对这本书感兴趣的话,可以看一下 试读样章),下面是文章的具体内容。
本章讲的依旧是实战项目,实战内容是打造分布式爬虫,这对初学者来说,是一个不小的挑战,也是一次有意义的尝试。这次打造的分布式爬虫采用比较简单的主从模式,完全手工打造,不使用成熟框架,基本上涵盖了前六章的主要知识点,其中涉及分布式的知识点是分布式进程和进程间通信的内容,算是对Python爬虫基础篇的总结。
现在大型的爬虫系统都是采取分布式爬取结构,通过此次实战项目,让大家对分布式爬虫有一个比较清晰地了解,为之后系统的讲解分布式爬虫打下基础,其实它并没有多么困难。实战目标:爬取2000个百度百科网络爬虫词条以及相关词条的标题、摘要和链接等信息,采用分布式结构改写第六章的基础爬虫,使功能更加强大。爬取页面请看图6.1。
7.1简单分布式爬虫结构
本次分布式爬虫采用主从模式。主从模式是指由一台主机作为控制节点负责所有运行网络爬虫的主机进行管理,爬虫只需要从控制节点那里接收任务,并把新生成任务提交给控制节点就可以了,在这个过程中不必与其他爬虫通信,这种方式实现简单利于管理。而控制节点则需要与所有爬虫进行通信,因此可以看到主从模式是有缺陷的,控制节点会成为整个系统的瓶颈,容易导致整个分布式网络爬虫系统性能下降。
此次使用三台主机进行分布式爬取,一台主机作为控制节点,另外两台主机作为爬虫节点。爬虫结构如图7.1所示:
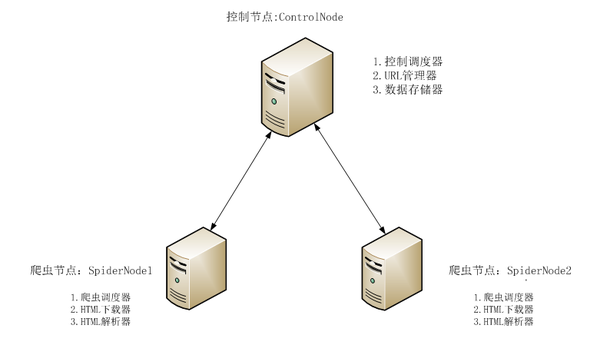
图7.1 主从爬虫结构
7.2 控制节点ControlNode
控制节点主要分为URL管理器、数据存储器和控制调度器。控制调度器通过三个进程来协调URL管理器和数据存储器的工作,一个是URL管理进程,负责URL的管理和将URL传递给爬虫节点,一个是数据提取进程,负责读取爬虫节点返回的数据,将返回数据中的URL交给URL管理进程,将标题和摘要等数据交给数据存储进程,最后一个是数据存储进程,负责将数据提取进程中提交的数据进行本地存储。执行流程如图7.2所示:
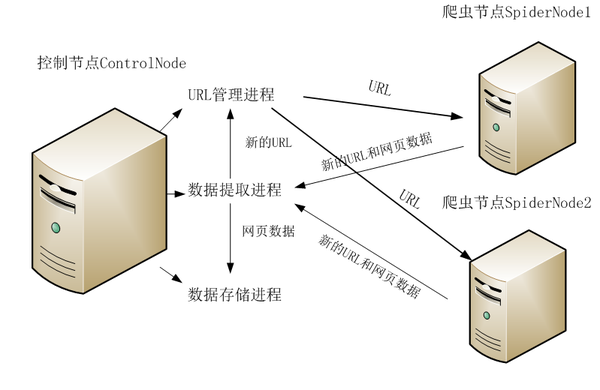
图7.2 控制节点执行流程
7.2.1 URL管理器
URL管理器查考第六章的代码,做了一些优化修改。由于我们采用set内存去重的方式,如果直接存储大量的URL链接,尤其是URL链接很长的时候,很容易造成内存溢出,所以我们采用将爬取过的URL进行MD5处理,由于字符串经过MD5处理后的信息摘要长度可以128bit,将生成的MD5摘要存储到set后,可以减少好几倍的内存消耗,Python中的MD5算法生成的是32位的字符串,由于我们爬取的url较少,md5冲突不大,完全可以取中间的16位字符串,即16位MD5加密。同时添加了save_progress和load_progress方法进行序列化的操作,将未爬取URL集合和已爬取的URL集合序列化到本地,保存当前的进度,以便下次恢复状态。URL管理器URLManager.py代码如下:
#coding:utf-8
import cPickle
import hashlib
class UrlManager(object):
def __init__(self):
self.new_urls = self.load_progress('new_urls.txt')#未爬取URL集合
self.old_urls = self.load_progress('old_urls.txt')#已爬取URL集合
def has_new_url(self):
'''
判断是否有未爬取的URL
:return:
'''
return self.new_url_size()!=0 def get_new_url(self):
'''
获取一个未爬取的URL
:return:
'''
new_url = self.new_urls.pop()
m = hashlib.md5()
m.update(new_url)
self.old_urls.add(m.hexdigest()[8:-8])
return new_url def add_new_url(self,url):
'''
将新的URL添加到未爬取的URL集合中
:param url:单个URL
:return:
'''
if url is None:
return
m = hashlib.md5()
m.update(url)
url_md5 = m.hexdigest()[8:-8]
if url not in self.new_urls and url_md5 not in self.old_urls:
self.new_urls.add(url) def add_new_urls(self,urls):
'''
将新的URLS添加到未爬取的URL集合中
:param urls:url集合
:return:
'''
if urls is None or len(urls)==0:
return
for url in urls:
self.add_new_url(url) def new_url_size(self):
'''
获取未爬取URL集合的s大小
:return:
'''
return len(self.new_urls) def old_url_size(self):
'''
获取已经爬取URL集合的大小
:return:
'''
return len(self.old_urls) def save_progress(self,path,data):
'''
保存进度
:param path:文件路径
:param data:数据
:return:
'''
with open(path, 'wb') as f:
cPickle.dump(data, f) def load_progress(self,path):
'''
从本地文件加载进度
:param path:文件路径
:return:返回set集合
'''
print '[+] 从文件加载进度: %s' % path
try:
with open(path, 'rb') as f:
tmp = cPickle.load(f)
return tmp
except:
print '[!] 无进度文件, 创建: %s' % path
return set()
7.2.2数据存储器
数据存储器的内容基本上和第六章的一样,不过生成文件按照当前时间进行命名避免重复,同时对文件进行缓存写入。代码如下:
#coding:utf-8
import codecs
import time
class DataOutput(object):
def __init__(self):
self.filepath='baike_%s.html'%(time.strftime("%Y_%m_%d_%H_%M_%S", time.localtime()) )
self.output_head(self.filepath)
self.datas=[]
def store_data(self,data):
if data is None:
return
self.datas.append(data)
if len(self.datas)>10:
self.output_html(self.filepath) def output_head(self,path):
'''
将HTML头写进去
:return:
'''
fout=codecs.open(path,'w',encoding='utf-8')
fout.write("<html>")
fout.write("<body>")
fout.write("<table>")
fout.close() def output_html(self,path):
'''
将数据写入HTML文件中
:param path: 文件路径
:return:
'''
fout=codecs.open(path,'a',encoding='utf-8')
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s</td>"%data['url'])
fout.write("<td>%s</td>"%data['title'])
fout.write("<td>%s</td>"%data['summary'])
fout.write("</tr>")
self.datas.remove(data)
fout.close() def ouput_end(self,path):
'''
输出HTML结束
:param path: 文件存储路径
:return:
'''
fout=codecs.open(path,'a',encoding='utf-8')
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
fout.close()
7.2.3控制调度器
控制调度器主要是产生并启动URL管理进程、数据提取进程和数据存储进程,同时维护4个队列保持进程间的通信,分别为url_queue,result_queue, conn_q,store_q。4个队列说明如下:
- url_q队列是URL管理进程将URL传递给爬虫节点的通道
- result_q队列是爬虫节点将数据返回给数据提取进程的通道
- conn_q队列是数据提取进程将新的URL数据提交给URL管理进程的通道
- store_q队列是数据提取进程将获取到的数据交给数据存储进程的通道
因为要和工作节点进行通信,所以分布式进程必不可少。参考1.4.4小节分布式进程中服务进程中的代码(linux版),创建一个分布式管理器,定义为start_manager方法。方法代码如下:
def start_Manager(self,url_q,result_q):
'''
创建一个分布式管理器
:param url_q: url队列
:param result_q: 结果队列
:return:
'''
#把创建的两个队列注册在网络上,利用register方法,callable参数关联了Queue对象,
# 将Queue对象在网络中暴露
BaseManager.register('get_task_queue',callable=lambda:url_q)
BaseManager.register('get_result_queue',callable=lambda:result_q)
#绑定端口8001,设置验证口令‘baike’。这个相当于对象的初始化
manager=BaseManager(address=('',8001),authkey='baike')
#返回manager对象
return manager
URL管理进程将从conn_q队列获取到的新URL提交给URL管理器,经过去重之后,取出URL放入url_queue队列中传递给爬虫节点,代码如下:
def url_manager_proc(self,url_q,conn_q,root_url):
url_manager = UrlManager()
url_manager.add_new_url(root_url)
while True:
while(url_manager.has_new_url()): #从URL管理器获取新的url
new_url = url_manager.get_new_url()
#将新的URL发给工作节点
url_q.put(new_url)
print 'old_url=',url_manager.old_url_size()
#加一个判断条件,当爬去2000个链接后就关闭,并保存进度
if(url_manager.old_url_size()>2000):
#通知爬行节点工作结束
url_q.put('end')
print '控制节点发起结束通知!'
#关闭管理节点,同时存储set状态
url_manager.save_progress('new_urls.txt',url_manager.new_urls)
url_manager.save_progress('old_urls.txt',url_manager.old_urls)
return
#将从result_solve_proc获取到的urls添加到URL管理器之间
try:
if not conn_q.empty():
urls = conn_q.get()
url_manager.add_new_urls(urls)
except BaseException,e:
time.sleep(0.1)#延时休息
数据提取进程从result_queue队列读取返回的数据,并将数据中的URL添加到conn_q队列交给URL管理进程,将数据中的文章标题和摘要添加到store_q队列交给数据存储进程。代码如下:
def result_solve_proc(self,result_q,conn_q,store_q):
while(True):
try:
if not result_q.empty():
content = result_q.get(True)
if content['new_urls']=='end':
#结果分析进程接受通知然后结束
print '结果分析进程接受通知然后结束!'
store_q.put('end')
return
conn_q.put(content['new_urls'])#url为set类型
store_q.put(content['data'])#解析出来的数据为dict类型
else:
time.sleep(0.1)#延时休息
except BaseException,e:
time.sleep(0.1)#延时休息
数据存储进程从store_q队列中读取数据,并调用数据存储器进行数据存储。代码如下:
def store_proc(self,store_q):
output = DataOutput()
while True:
if not store_q.empty():
data = store_q.get()
if data=='end':
print '存储进程接受通知然后结束!'
output.ouput_end(output.filepath) return
output.store_data(data)
else:
time.sleep(0.1)
最后将分布式管理器、URL管理进程、 数据提取进程和数据存储进程进行启动,并初始化4个队列。代码如下:
if __name__=='__main__':
#初始化4个队列
url_q = Queue()
result_q = Queue()
store_q = Queue()
conn_q = Queue()
#创建分布式管理器
node = NodeManager()
manager = node.start_Manager(url_q,result_q)
#创建URL管理进程、 数据提取进程和数据存储进程
url_manager_proc = Process(target=node.url_manager_proc, args=(url_q,conn_q,'http://baike.baidu.com/view/284853.htm',))
result_solve_proc = Process(target=node.result_solve_proc, args=(result_q,conn_q,store_q,))
store_proc = Process(target=node.store_proc, args=(store_q,))
#启动3个进程和分布式管理器
url_manager_proc.start()
result_solve_proc.start()
store_proc.start()
manager.get_server().serve_forever()
7.3 爬虫节点SpiderNode
爬虫节点相对简单,主要包含HTML下载器、HTML解析器和爬虫调度器。执行流程如下:
- 爬虫调度器从控制节点中的url_q队列读取URL
- 爬虫调度器调用HTML下载器、HTML解析器获取网页中新的URL和标题摘要
- 最后爬虫调度器将新的URL和标题摘要传入result_q队列交给控制节点
7.3.1 HTML下载器
HTML下载器的代码和第六章的一致,只要注意网页编码即可。代码如下:
#coding:utf-8
import requests
class HtmlDownloader(object): def download(self,url):
if url is None:
return None
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers={'User-Agent':user_agent}
r = requests.get(url,headers=headers)
if r.status_code==200:
r.encoding='utf-8'
return r.text
return None
7.3.2 HTML解析器
HTML解析器的代码和第六章的一致,详细的网页分析过程可以回顾第六章。代码如下:
#coding:utf-8
import re
import urlparse
from bs4 import BeautifulSoup class HtmlParser(object): def parser(self,page_url,html_cont):
'''
用于解析网页内容抽取URL和数据
:param page_url: 下载页面的URL
:param html_cont: 下载的网页内容
:return:返回URL和数据
'''
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont,'html.parser',from_encoding='utf-8')
new_urls = self._get_new_urls(page_url,soup)
new_data = self._get_new_data(page_url,soup)
return new_urls,new_data def _get_new_urls(self,page_url,soup):
'''
抽取新的URL集合
:param page_url: 下载页面的URL
:param soup:soup
:return: 返回新的URL集合
'''
new_urls = set()
#抽取符合要求的a标签
links = soup.find_all('a',href=re.compile(r'/view/\d+\.htm'))
for link in links:
#提取href属性
new_url = link['href']
#拼接成完整网址
new_full_url = urlparse.urljoin(page_url,new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self,page_url,soup):
'''
抽取有效数据
:param page_url:下载页面的URL
:param soup:
:return:返回有效数据
'''
data={}
data['url']=page_url
title = soup.find('dd',class_='lemmaWgt-lemmaTitle-title').find('h1')
data['title']=title.get_text()
summary = soup.find('div',class_='lemma-summary')
#获取tag中包含的所有文版内容包括子孙tag中的内容,并将结果作为Unicode字符串返回
data['summary']=summary.get_text()
return data
7.3.3 爬虫调度器
爬虫调度器需要用到分布式进程中工作进程的代码,具体内容可以参考第一章的分布式进程章节。爬虫调度器需要先连接上控制节点,然后依次完成从url_q队列中获取URL,下载并解析网页,将获取的数据交给result_q队列,返回给控制节点等各项任务,代码如下:
class SpiderWork(object):
def __init__(self):
#初始化分布式进程中的工作节点的连接工作
# 实现第一步:使用BaseManager注册获取Queue的方法名称
BaseManager.register('get_task_queue')
BaseManager.register('get_result_queue')
# 实现第二步:连接到服务器:
server_addr = '127.0.0.1'
print('Connect to server %s...' % server_addr)
# 端口和验证口令注意保持与服务进程设置的完全一致:
self.m = BaseManager(address=(server_addr, 8001), authkey='baike')
# 从网络连接:
self.m.connect()
# 实现第三步:获取Queue的对象:
self.task = self.m.get_task_queue()
self.result = self.m.get_result_queue()
#初始化网页下载器和解析器
self.downloader = HtmlDownloader()
self.parser = HtmlParser()
print 'init finish' def crawl(self):
while(True):
try:
if not self.task.empty():
url = self.task.get() if url =='end':
print '控制节点通知爬虫节点停止工作...'
#接着通知其它节点停止工作
self.result.put({'new_urls':'end','data':'end'})
return
print '爬虫节点正在解析:%s'%url.encode('utf-8')
content = self.downloader.download(url)
new_urls,data = self.parser.parser(url,content)
self.result.put({"new_urls":new_urls,"data":data})
except EOFError,e:
print "连接工作节点失败"
return
except Exception,e:
print e
print 'Crawl fali ' if __name__=="__main__":
spider = SpiderWork()
spider.crawl()
在爬虫调度器设置了一个本地IP:127.0.0.1,大家可以将在一台机器上测试代码的正确性。当然也可以使用三台VPS服务器,两台运行爬虫节点程序,将IP改为控制节点主机的公网IP,一台运行控制节点程序,进行分布式爬取,这样更贴近真实的爬取环境。下面图7.3为最终爬取的数据,图7.4为new_urls.txt内容,图7.5为old_urls.txt内容,大家可以进行对比测试,这个简单的分布式爬虫还有很大发挥的空间,希望大家发挥自己的聪明才智进一步完善。

图7.3 最终爬取的数据
图7.4 new_urls.txt
图7.5 old_urls.txt
7.4小结
本章讲解了一个简单的分布式爬虫结构,主要目的是帮助大家将Python爬虫基础篇的知识进行总结和强化,开拓大家的思维,同时也让大家知道分布式爬虫并不是这么高不可攀。不过当你亲手打造一个分布式爬虫后,就会知道分布式爬虫的难点在于节点的调度,什么样的结构能让各个节点稳定高效的运作才是分布式爬虫要考虑的核心内容。到本章为止,Python爬虫基础篇已经结束,这个时候大家基本上可以编写简单的爬虫,爬取一些静态网站的内容,但是Python爬虫开发不仅如此,大家接着往下学习吧。
最后
打个广告,如果大家对这本书感兴趣的话,可以看一下 试读样章 或者直接购买。

欢迎大家支持我公众号:

纯手工打造简单分布式爬虫(Python)的更多相关文章
- 纯手工打造漂亮的瀑布流,五大插件一个都不少Bootstrap+jQuery+Masonry+imagesLoaded+Lightbox!
前两天写的文章<纯手工打造漂亮的垂直时间轴,使用最简单的HTML+CSS+JQUERY完成100个版本更新记录的华丽转身!>受到很多网友的喜爱,今天特别推出姊妹篇<纯手工打造漂亮的瀑 ...
- [置顶] 纯手工打造漂亮的瀑布流,五大插件一个都不少Bootstrap+jQuery+Masonry+imagesLoaded+Lightbox!
前两天写的文章<纯手工打造漂亮的垂直时间轴,使用最简单的HTML+CSS+JQUERY完成100个版本更新记录的华丽转身!>受到很多网友的喜爱,今天特别推出姊妹篇<纯手工打造漂亮的瀑 ...
- 纯手工打造漂亮的垂直时间轴,使用最简单的HTML+CSS+JQUERY完成100个版本更新记录的华丽转身!
前言 FineUI控件库发展至今已经有 5 个年头,目前论坛注册的QQ会员 5000 多人,捐赠用户 500 多人(捐赠用户转化率达到10%以上,在国内开源领域相信这是一个梦幻数字!也足以证明Fine ...
- [置顶] 纯手工打造漂亮的垂直时间轴,使用最简单的HTML+CSS+JQUERY完成100个版本更新记录的华丽转身!
前言 FineUI控件库发展至今已经有 5 个年头,目前论坛注册的QQ会员 5000 多人,捐赠用户 500 多人(捐赠用户转化率达到10%以上,在国内开源领域相信这是一个梦幻数字!也足以证明Fine ...
- Python简单分布式爬虫
分布式爬虫采用主从模式.主从模式是指由一台主机作为控制节点,负责管理所有运行网络爬虫的主机(url管理器,数据存储器,控制调度器),爬虫只需要从控制节点哪里接收任务,并把新生成任务提交给控制节点.此次 ...
- scrapy简单分布式爬虫
经过一段时间的折腾,终于整明白scrapy分布式是怎么个搞法了,特记录一点心得. 虽然scrapy能做的事情很多,但是要做到大规模的分布式应用则捉襟见肘.有能人改变了scrapy的队列调度,将起始的网 ...
- 用PHP纯手工打造会动的多帧GIF图片验证码
效果演示: http://pcik.7di.net/pcik_reg 百度的效果演示: https://passport.baidu.com/cgi-bin/genimage?captchaservi ...
- 纯手工打造(不使用IDE)java web 项目
必备环境 1.编译器:jdk 2.web服务器:tomcat 3.文本编辑器:sublime,编写java文件和jsp文件,没有的话用记事本也行. 一.建立工程目录结构,如下图 在操作系统下完成即可, ...
- 纯手工打造dropdownlist控件
先上图吧,看看效果. JS代码: ; (function ($) { var DropdownList = function (oDataSouce, oControlsContainer, oLis ...
随机推荐
- bootstrap快速入门笔记(六)-代码
一,内联代码<code>:For example, <code><section></code> should be wrapped as inline ...
- sublime text3在指定浏览器上本地服务器(localhost)运行文件(php)
昨天在使用sublime text3时,发现能在本地服务器上运行php文件,于是百度了一下有关知识, 终于成功了,今天总结一下. 首先要让sublime text3 出现侧边栏sidebar,不会的可 ...
- Failed to read artifact descriptor for xxx:jar 的Maven项目jar包依赖配置的问题解决
在开发的过程中,尤其是新手,我们经常遇到Maven下载依赖jar包的问题,也就是遇到“Failed to read artifact descriptor for xxx:jar”的错误. 对于这种非 ...
- DTCMS插件的制作实例电子资源管理(三)前台模板页编写
总目录 插件目录结构(一) Admin后台页面编写(二) 前台模板页编写(三) URL重写(四) 本实例旨在以一个实际的项目中的例子来介绍如何在dtcms中制作插件,本系列文章非入门教程,部分逻辑实现 ...
- QQ互联第三方登陆 redirect uri is illegal(100010)
想必第一次大家接触QQ第三方登陆都会遇到各种各样的问题,备受折磨,因此,今天我把自己做QQ登陆的过程描述一下,希望给大家提供参考,少走弯路. 在开发之前,我们先了解下QQ登陆的流程 第一:查看熟悉 网 ...
- MVC两种获取上传的文件数据变量的方式
第一种方式,在控制器中利用HttpPostedFileBase参数对象获取. [HttpPost] public ActionResult SaveFile(HttpPostedFileBase up ...
- 【挖洞经验】如何在一条UPDATE查询中实现SQL注入
直奔主题 跟往常一样,在喝完我最爱的果汁饮料之后,我会习惯性地登录我的Synack账号,然后选择一个应用来进行渗透测试,此时我的“黑客之夜”便正式开始了. 我与很多其他的安全研究人员的习惯一样,我会在 ...
- Java字符串连接最佳实践
一个小问题,分享给大家. + 操作和 StringBuilder 都能连接字符串,使用+来拼接字符串,使用javap命令来反编译代码,可以看出实际上编译器会自动创建StringBuilder,调用它的 ...
- 浏览器播放rtsp流媒体解决方案
老板提了一个需求,想让网页上播放景区监控的画面,估计是想让游客达到未临其地,已知其境的状态吧. 说这个之前,还是先说一下什么是rtsp协议吧. RTSP(Real Time Streaming ...
- 瀑布流布局使用详解——JQuery插件Isotope(动态实现子项目筛选)
瀑布流布局,听起来听牛逼的样子,其实就是简单的子元素筛选功能.不过这一功能在网站页面布局当中还是很常用的,特别是在电商网站中 经常会有点一个钮筛选,然后页面的子元素刷的以下变了样.接下来,我们先简单介 ...