[Bayesian] “我是bayesian我怕谁”系列 - Gaussian Process
科班出身,贝叶斯护体,正本清源,故拿”九阳神功“自比,而非邪气十足的”九阴真经“;
现在看来,此前的八层功力都为这第九层作基础;
本系列第九篇,助/祝你早日hold住神功第九重,加入血统纯正的人工智能队伍。
小喇叭:本系列文章乃自娱自乐,延缓脑细胞衰老;只“雪中送炭”,不提供”全套服务“。
九阳神功第九章《Gaussian Processes for ML》


如果,非统计机器学习是入门,统计机器学习是进阶,那么“高斯过程”就算是机器学习的高级阶段,能发paper。
国内相关的书,没发现。(有数学系的同学给推荐么?)
推荐相关的还算易懂的paper一篇: Generic Inference in Latent Gaussian Process Models
对高斯过程的了解过程中,让我深刻的明白,要发国际paper的同学都有着怎样的学习生涯套路。
菜鸡们来瞧瞧这位,Stanford cs231n 2016的lecturer,语速感人,成就经典。

血统纯正的学习路线:
2011-2015: Stanford Computer Science Ph.D. student Deep Learning, Computer Vision, Natural Language Processing. Adviser: Fei-Fei Li.
Summer 2011: Google Research Internship Large-Scale Unsupervised Deep Learning for Videos
2009-2011: University of British Columbia: MSc Learning Controllers for Physically-simulated Figures. Adviser: Michiel van de Panne
2005-2009: University of Toronto: BSc Double major in Computer Science and Physics
请注意本科时期的double major,which帮助奠定大牛潜质。
学纯数搞人工智能有点纸上谈兵;
学计科高人工智能有点后劲不足;
CS+Physics真乃绝配!
言归正传,基本上学习的路线是:GP for Regression, GP for Classification, Latent Gaussian Process Models。
百度到的东西基本都是GP for Regression,可见广大吃瓜群众基本停留在这套路线的初级阶段,后两者确实需要功力,即使一知半解也不便卖弄风骚。
此处一篇:浅谈高斯过程回归 应该是根据youtube视频课程所总结,写得挺好。在此基础上我将在此加一点补充,希望有助理解。
本来想把自己懂的这么一点东西总结于此,但最近release了一门神课,很对味,故正在重点follow中。
高斯过程回归
预测
这篇浅谈高斯过程回归已经将(预测)基本计算过程展现了一遍,这里就不再赘述。读完该链接后,抛出一个问题:
蓝色字体的协方差值是如何给出的?怎么定义会更好?
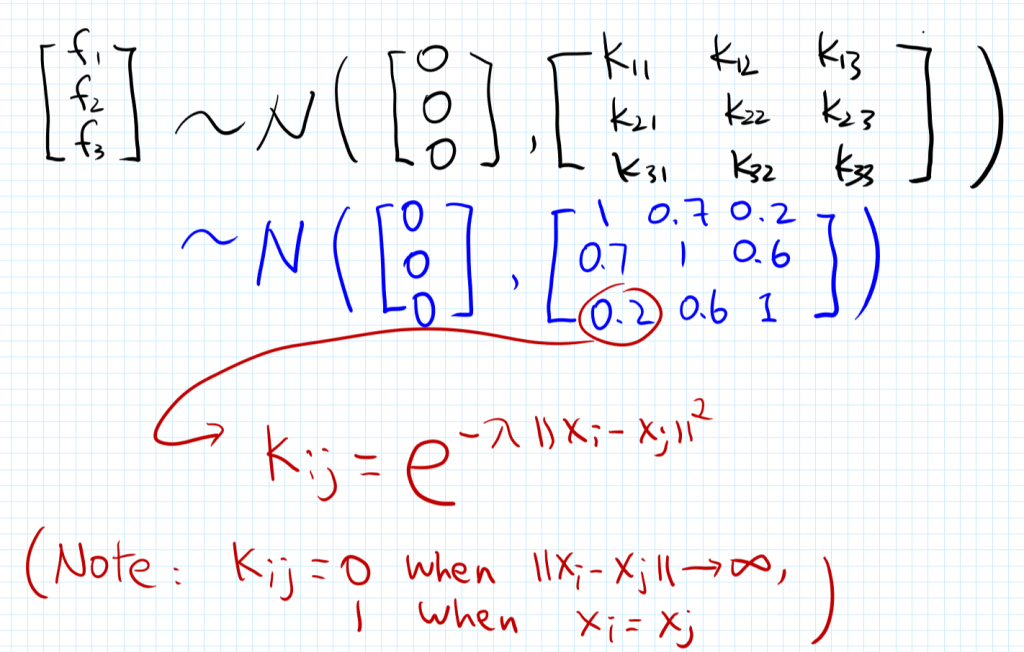
模型的选择
f是高斯,y也是高斯。根据二元高斯的条件分布计算方法:[Bayes] Why we prefer Gaussian Distribution
直接求得p(f*|y) 【等价 p(f*|X, y, x*)】的预测公式如下:

常见的结论就是:这个预测结果(期望)是个“输入的线性组合”,同时也是个“kernel的线性组合”。
以下求y的边缘分布:【过程略,较复杂】
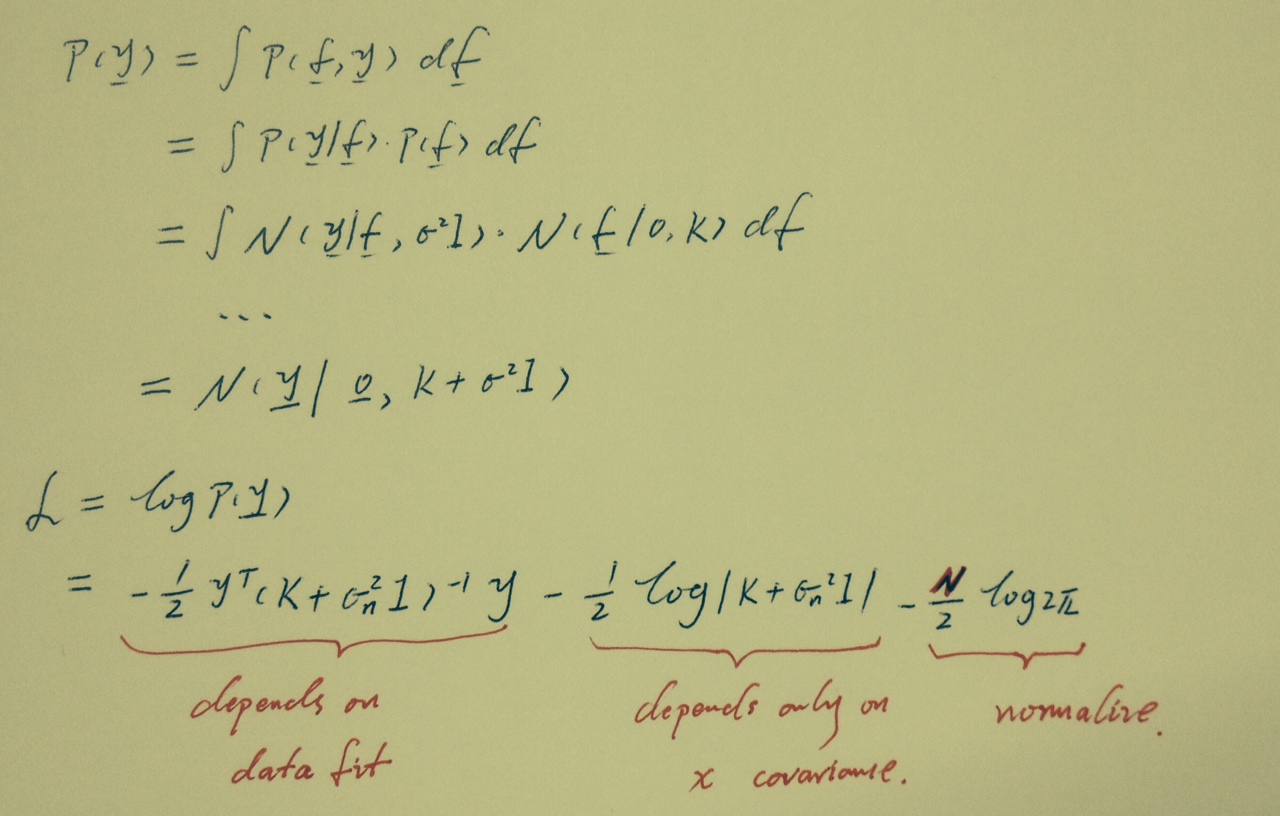
常见的结论就是:这个能用于hyperparameter learning,也就是θ = {sigma, C}的学习,如下所示。

其实就是相关性的选择问题,学习这个K内部的东西。为何要计较这三部分?
想必也是个“权衡问题”,如下图。
From: http://www.gaussianprocess.org/gpml/chapters/RW5.pdf
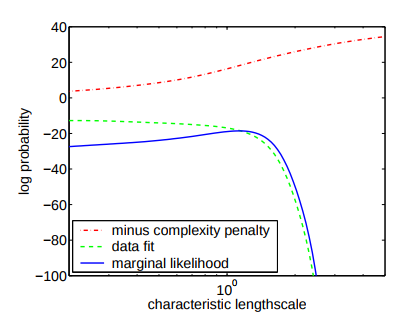
适当的选择超参,能获得一个极大的marginal likelood。
这也叫做“model selection”。
高斯过程分类
参考“回归”,学习“分类”。
没有了噪声sigma的概念,f(y|f)变为了sigmoid,故成了non-linear,p(f|X,y)成了恼人的non-gaussian。
那我们就定一个高斯q(f|X,y)来近似p(f|X,y);自然而然引出Laplace Approximation【暂略】。
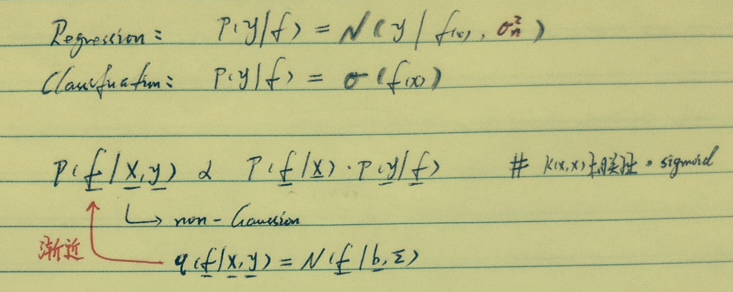
一个思考的技巧:
计算时可以暂且将f作为回归中y的角色,那么如下看去就将对应的回归结论中的噪声sigma去掉即可。
但我们终究还是要p(f*|X, y, x*),也就是需要加入一个“f given y的关系”,即是上述提及的近似高斯技巧。
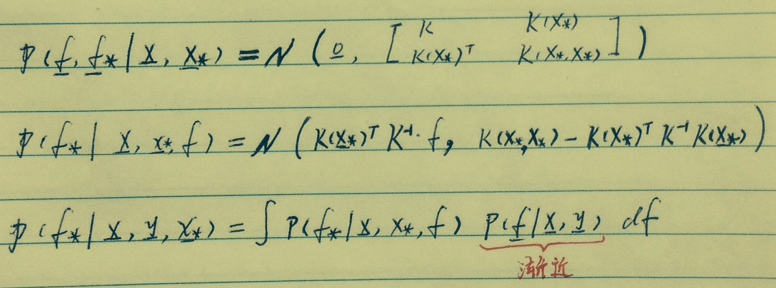
与“回归”对比,是否感觉总有点复杂?为什么搞复杂了呢?
- 同样的已知:p(y|f), p(f|x) 但前者已不是高斯。怎么办?
- 那就暂且不管y,计算还是高斯的这部分,也就是截止到f的地方,这样也就自然的利用了回归时的结论如上,得到了p(f*|X,x*,f)
- 然后,再考虑f-->y已不再是高斯的问题,便自然地引入了p(f|X,y) <-- p(y|f), p(f|x)。
计算结果如下:
p(f*|X,y,x*) = N(f*| K(x*)TK-1b, K(x*,x*)-K(x*)T[K-1-K-1ΣK-1]K(x*))
预测
接下来就是“预测”问题,通常有两种策略:Average and MAP
可见虽然求出了f*,但依然无法逃避“f* --> y*”这段non-gaussian的过程。
此时,便自然而然得想到用mcmc去估计积分结果。
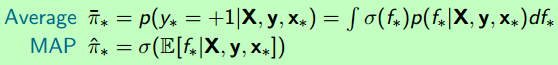
高斯过程隐变量
这一部分是超高级内容,只是简单聊一聊,仰望一下。
想想PCA,隐变量的意义是压缩,这里将要说的隐变量,也就是inducing variables也是如此。
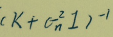
要计算这个东西,是O(N3),所以有必要想办法减小计算量。
可采用decomposition的方法,例如使用inducing variables:u。
以上便是原因之一。下图中的f之间用粗线表示“f之间是全连接”。

原理详见原论文(上图标题),如下来个例子瞧瞧。
至少我们知道有了u,z这样的概念,而且维度比N要低很多。
在Subset of Regressors (SR) approximation中,假设了covariance function:
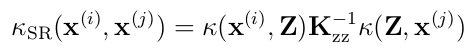
与标准GP相比,看上去精简了“相关性”的计算。将上式替代到标准GP回归时的结论即可得到如下:
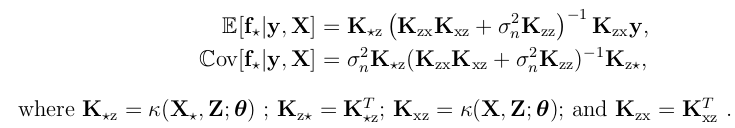
计算过程较复杂,其中会涉及到如下这个公式的运用 from Maxtrix Cookbook:
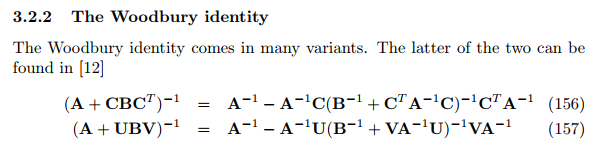
就到这里,因为inducing variables的引入,展开了一大片坑,可以阅读该链接深入了解:Generic Inference in Latent Gaussian Process Models
本篇写得相当基础, 大致写个学习进阶套路,一来确实需要相当的数学功底,二来更想花时间follow (STATS 385)。
再次强调下,本系列不提供“全套服务”,只帮助整理下个人近期的知识体系,如有兴趣,请点击文章中提及的各个亲测的高质量链接。
那么,就到这里吧。
相关链接:
Ref: http://www.cnblogs.com/hxsyl/p/5229746.html
Ref: https://zhuanlan.zhihu.com/p/24388992
Link: http://videolectures.net/gpip06_mackay_gpb/
[Bayesian] “我是bayesian我怕谁”系列 - Gaussian Process的更多相关文章
- [Bayesian] “我是bayesian我怕谁”系列 - Variational Autoencoders
本是neural network的内容,但偏偏有个variational打头,那就聊聊.涉及的内容可能比较杂,但终归会 end with VAE. 各个概念的详细解释请点击推荐的链接,本文只是重在理清 ...
- [Bayesian] “我是bayesian我怕谁”系列 - Exact Inferences
要整理这部分内容,一开始我是拒绝的.欣赏贝叶斯的人本就不多,这部分过后恐怕就要成为“从入门到放弃”系列. 但,这部分是基础,不管是Professor Daphne Koller,还是统计学习经典,都有 ...
- [Bayesian] “我是bayesian我怕谁”系列 - Variational Inference
涉及的领域可能有些生僻,骗不了大家点赞.但毕竟是人工智能的主流技术,在园子却成了非主流. 不可否认的是:乃值钱的技术,提高身价的技术,改变世界观的技术. 关于变分,通常的课本思路是: GMM --&g ...
- [Bayesian] “我是bayesian我怕谁”系列 - Exact Inference
要整理这部分内容,一开始我是拒绝的.欣赏贝叶斯的人本就不多,这部分过后恐怕就要成为“从入门到放弃”系列. 但,这部分是基础,不管是Professor Daphne Koller,还是统计学习经典,都有 ...
- [Bayesian] “我是bayesian我怕谁”系列 - Naive Bayes+prior
先明确一些潜规则: 机器学习是个collection or set of models,一切实践性强的模型都会被归纳到这个领域,没有严格的定义,’有用‘可能就是唯一的共性. 机器学习大概分为三个领域: ...
- [Bayesian] “我是bayesian我怕谁”系列 - Naive Bayes with Prior
先明确一些潜规则: 机器学习是个collection or set of models,一切实践性强的模型都会被归纳到这个领域,没有严格的定义,’有用‘可能就是唯一的共性. 机器学习大概分为三个领域: ...
- [Bayesian] “我是bayesian我怕谁”系列 - Continuous Latent Variables
打开prml and mlapp发现这部分目录编排有点小不同,但神奇的是章节序号竟然都为“十二”. prml:pca --> ppca --> fa mlapp:fa --> pca ...
- [Bayesian] “我是bayesian我怕谁”系列 - Markov and Hidden Markov Models
循序渐进的学习步骤是: Markov Chain --> Hidden Markov Chain --> Kalman Filter --> Particle Filter Mark ...
- [Bayesian] “我是bayesian我怕谁”系列 - Boltzmann Distribution
使用Boltzmann distribution还是Gibbs distribution作为题目纠结了一阵子,选择前者可能只是因为听起来“高大上”一些.本章将会聊一些关于信息.能量这方面的东西,体会“ ...
随机推荐
- poj3468(一维)(区间查询,区间修改)
A Simple Problem with Integers You have N integers, A1, A2, ... , AN. You need to deal with two kind ...
- NOIP2017SummerTraining0726
三道比较简单的题,还以为是八校考试的题目,但是并不是,无语了,第三题其实看了挺久的,一看到图,就想到了二分图,网络流之类的算法,但是尽力往这个方向想了好久都没什么思路, 最后从简单入手,然而没什么结果 ...
- swiper拖拽之后不自动滑动问题
//swiper轮播图 var mySwiper = new Swiper('.swiper-container',{ initialSlide :0, autoplay : 3000, direct ...
- ES6-模块化
ES6-模块化 在es6标准中,js原生支持modulele. ES6模块需要使用babel转码,这里简单解释一下什么是babel转码. babel就是将‘ES6模块化语法’转化为‘CommonJS模 ...
- 一个高性能、轻量级的分布式内存队列系统--beanstalk
Beanstalk是一个高性能.轻量级的.分布式的.内存型的消息队列系统.最初设计的目的是想通过后台异步执行耗时的任务来降低高容量Web应用系统的页面访问延迟.其实Beanstalkd是典型的类Mem ...
- C#中System.DateTime.Now.ToString()用法
//Asp.net中的日期处理函数 //2008年4月24日 System.DateTime.Now.ToString("D"); //2008-4-24 ...
- Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言 上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的.接下来我将给大家分享一下全分布式集群的搭建! 其实搭建最基本的全分布式集群和伪分布式集群 ...
- ASP.NET没有魔法——ASP.NET MVC 与数据库大集合
ASP.NET没有魔法——ASP.NET与数据库 ASP.NET没有魔法——ASP.NET MVC 与数据库之MySQL ASP.NET没有魔法——ASP.NET MVC 与数据库之ORM ASP.N ...
- Are We There Yet? (zoj1745)
Are We There Yet? (ZOJ Problem Set - 1745) Are We There Yet? Time Limit: 2 Seconds Memory L ...
- java web mysql 入门知识讲解
MySQL学习笔记总结 一.SQL概述: SQL:Structured Query Language的缩写(结构化查询语言) SQL工业标准:由ANSI(ISO核心成员) 按照工业标准编写的SQ ...