Spark/Storm/Flink
https://www.cnblogs.com/yaohaitao/p/5703288.html
Spark Streaming与Storm的应用场景
对于Storm来说:
1、建议在那种需要纯实时,不能忍受1秒以上延迟的场景下使用,比如实时金融系统,要求纯实时进行金融交易和分析
2、此外,如果对于实时计算的功能中,要求可靠的事务机制和可靠性机制,即数据的处理完全精准,一条也不能多,一条也不能少,也可以考虑使用Storm
3、如果还需要针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源(通常是在小型公司,集群资源紧张的情况),也可以考虑用Storm
4、如果一个大数据应用系统,它就是纯粹的实时计算,不需要在中间执行SQL交互式查询、复杂的transformation算子等,那么用Storm是比较好的选择
对于Spark Streaming来说:
1、如果对上述适用于Storm的三点,一条都不满足的实时场景,即,不要求纯实时,不要求强大可靠的事务机制,不要求动态调整并行度,那么可以考虑使用Spark Streaming
2、考虑使用Spark
Streaming最主要的一个因素,应该是针对整个项目进行宏观的考虑,即,如果一个项目除了实时计算之外,还包括了离线批处理、交互式查询等业务功能,而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,那么就应该首选Spark生态,用Spark
Core开发离线批处理,用Spark SQL开发交互式查询,用Spark
Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性
Spark Streaming与Storm的优劣分析
事实上,Spark Streaming绝对谈不上比Storm优秀。这两个框架在实时计算领域中,都很优秀,只是擅长的细分场景并不相同。
Spark Streaming仅仅在吞吐量上比Storm要优秀,而吞吐量这一点,也是历来挺Spark
Streaming,贬Storm的人着重强调的。但是问题是,是不是在所有的实时计算场景下,都那么注重吞吐量?不尽然。因此,通过吞吐量说Spark
Streaming强于Storm,不靠谱。
事实上,Storm在实时延迟度上,比Spark Streaming就好多了,前者是纯实时,后者是准实时。而且,Storm的事务机制、健壮性 / 容错性、动态调整并行度等特性,都要比Spark Streaming更加优秀。
Spark Streaming,有一点是Storm绝对比不上的,就是:它位于Spark生态技术栈中,因此Spark
Streaming可以和Spark Core、Spark
SQL无缝整合,也就意味着,我们可以对实时处理出来的中间数据,立即在程序中无缝进行延迟批处理、交互式查询等操作。这个特点大大增强了Spark
Streaming的优势和功能。
|
对比点 |
Storm |
Spark Streaming |
|
实时计算模型 |
纯实时,来一条数据,处理一条数据 |
准实时,对一个时间段内的数据收集起来,作为一个RDD,再处理 |
|
实时计算延迟度 |
毫秒级 |
秒级 |
|
吞吐量 |
低 |
高 |
|
事务机制 |
支持完善 |
支持,但不够完善 |
|
健壮性 / 容错性 |
ZooKeeper,Acker,非常强 |
Checkpoint,WAL,一般 |
|
动态调整并行度 |
支持 |
不支持 |
Spark:容错
分布式数据集容错一般有两种方式:数据检查点(操作成本高,需要通过数据中心的网络连接在机器之间复制庞大的数据集,而且网络带宽往往比内存带宽低,同时还需要消耗更多的存储资源)和记录数据的更新(如果记录太细太多,成本也不低)
Spark用记录更新的方式。RDD只支持粗粒度的转换,即只记录单个块上执行的单个操作,然后将创建RDD的一些列变化序列(Lineage)记录下来,以便恢复丢失的分区
Lineage本质上类似于DB的Redo Log,只不过这个重做日志的力度很大,是对全局数据做同样的重做进而恢复数据,RDD的Lineage记录的是粗粒度的特定数据Transform操作(filter/map/join等)行为。当这个RDD的部分分区数据丢失时,它可以通过Lineage获取足够的信息来重新运算和恢复丢失的数据分区。因为这种粗粒度的数据模型,限制了Spark的运用场所。
Lineage以来分为两种,宽依赖(子RDD的分区依赖于父RDD的多个分区或所有分区),窄依赖(父RDD的每一个分区是最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区,或多个父RDD对应一个子RDD)
窄依赖和宽依赖的概念主要用在两个地方:一个是容错中相当于Redo日志的功能;另一个是在调度中构建DAG作为不同Stage的划分点。
根据父RDD分区是对应1个还是多个子RDD分区来区分窄依赖(父分区对应一个子分区)和宽依赖(父分区对应多个子分
区)。如果对应多个,则当容错重算分区时,因为父分区数据只有一部分是需要重算子分区的,其余数据重算就造成了冗余计算。
对于宽依赖,Stage计算的输入和输出在不同的节点上,对于输入节点完好,而输出节点死机的情况,通过重新计算恢复数据这种情况下,这种方法容错是有效的,否则无效,因为无法重试,需要向上追溯其祖先看是否可以重试(这就是lineage,血统的意思),窄依赖对于数据的重算开销要远小于宽依赖的数据重算开销。
checkpoint 这个概念, 就是把内存中的变化刷新到持久存储
- 数据库 checkpoint 过程中一般把内存中的变化进行持久化到物理页, 这时候就可以斩断依赖链, 就可以把 redo 日志删掉了, 然后更新下检查点,
- hdfs namenode 的元数据 editlog, Secondary namenode 会把 edit log 应用到 fsimage, 然后刷到磁盘上, 也相当于做了一次 checkpoint, 就可以把老的 edit log 删除了。
- spark streaming 中对于一些 有状态的操作, 这在某些 stateful 转换中是需要的,在这种转换中,生成 RDD 需要依赖前面的 batches,会导致依赖链随着时间而变长。为了避免这种没有尽头的变长,要定期将中间生成的 RDDs 保存到可靠存储来切断依赖链, 必须隔一段时间进行一次进行一次 checkpoint。
cache 和 checkpoint 是有显著区别的, 缓存把 RDD 计算出来然后放在内存中, 但是RDD 的依赖链(相当于数据库中的redo 日志), 也不能丢掉, 当某个点某个 executor 宕了, 上面cache 的RDD就会丢掉, 需要通过 依赖链重放计算出来, 不同的是, checkpoint 是把 RDD 保存在 HDFS中, 是多副本可靠存储,所以依赖链就可以丢掉了,就斩断了依赖链, 是通过复制实现的高容错。但是有一点要注意, 因为checkpoint是需要把 job 重新从头算一遍, 最好先cache一下, checkpoint就可以直接保存缓存中的 RDD 了, 就不需要重头计算一遍了, 对性能有极大的提升。
Storm: https://www.jianshu.com/p/7d50a6e999b8?utm_campaign=maleskine&utm_content=note&utm_medium=seo_notes&utm_source=recommendation
Storm容错机制:
记录级容错:https://www.jianshu.com/p/4229d50c7d89

Storm允许用户在spout中发射一个新的源tuple时为其指定一个message id. 这个message id可以是任意的object对象.多个源Tuple可以共用一个message id ,表示这多个源tuple对用户来说是同一个消息单元.Storm中记录级容错的意思是说,storm会告知用户每一个消息单元是否在指定的时间内被完全处理了.那么什么叫完全处理呢?就是该message id绑定的源tuple以及该源tuple后续生成的tuple经过了topolopy中的每一个应该到达的bolt的处理.举个例子举个例子。在图4-1中,在spout由message 1绑定的tuple1和tuple2经过了bolt1和bolt2的处理生成两个新的tuple,并最终都流向了bolt3。当这个过程完成处理完时,称message 1被完全处理了。
Ack机制 https://blog.csdn.net/qq_21989939/article/details/78858032 / https://www.jianshu.com/p/4229d50c7d89
在storm的topology中有一个系统级组件,叫做acker。这个acker的任务就是追踪从spout中流出来的每一个message id绑定的若干tuple的处理路径,如果在用户设置的最大超时时间内这些tuple没有被完全处理,那么acker就会告知spout该消息处理失败了,相反则会告知spout该消息处理成功了。
N XOR N = 0
N XOR 0 = N

spout中绑定message 1生成了两个源tuple,id分别是0010和1011.

bolt1处理tuple 0010时生成了一个新的tuple,id为0110.

bolt2处理tuple 1011时生成了一个新的tuple,id为0111.

bolt3中接收到tuple 0110和tuple 0111,没有生成新的tuple.
spout 发出一条数据后需要知道数据处理成功和失败的状态,如失败的消息重新发送。
1. 自定义spoout实现BeseRichSpout,重写ack、fai方法。
2. 在自定义的spout 发送数据的时候,需要制定messageid,messageid 是一个Object.
3. 当消息处理成功或者失败之后,Storm框架会将messageid传回来。如果消息要重发,直接通过messageid找到或直接转化成数据内容进行重发。
4. 自定义Bolt实现BaseRichBolt
5. 在bolt的execute中进行两个操作: 发送数据时,需要制定血缘关系,锚点collector.emit(父tupe,new 子Tupe);当execute处理完成业务逻辑的时候,需要告诉storm框架当前阶段的处理状态collector.ack(tupe)
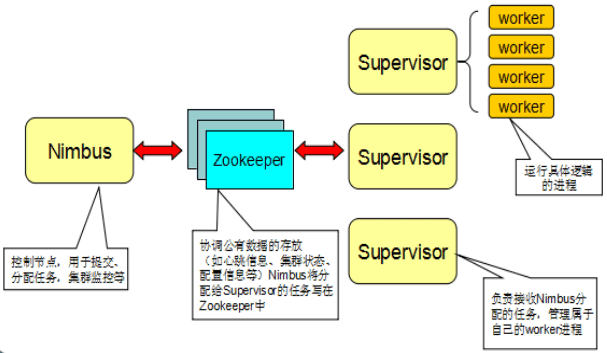
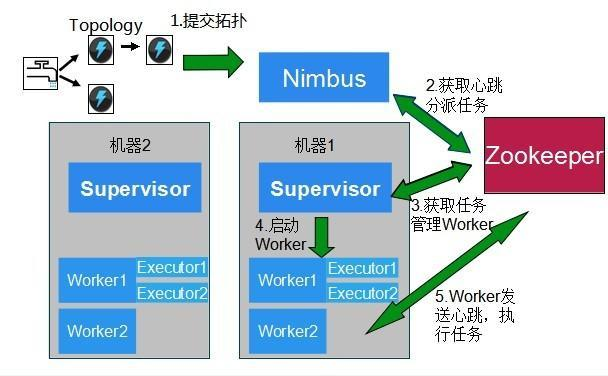
Nimbus和Supervisor被设计成是快速失败且无状态的,他们的状态都保存在ZooKeeper,如果其中某一个或者两个进程都挂掉,都不会影响其它的Supervisor已经在运行worker进程,但Nimbus和Supervisor本身不会自动重启。任务级失败:
- Bolt任务crash引起的消息未应答,此时acker中所有的与此Bolt任务关联的消息都会因为超时而失败,对应的spout的fail方法将被调用
- acker任务失败,如果acker任务本身失败了,它在失败之前持有的所有消息都将超时而失败。spout的fail方法将被调用
- spout任务失败,这种情况下,与spout任务对接的外部设备(MQ)负责消息的完整性,例如,当客户端异常时,kestrel队列会将处于Pending状态的所有消息重新放回队列中
任务槽故障
- Worker失败,每个worker中包含数个Bolt(或Spout)任务。Supervisor负责监控这些任务,当worker失败后会尝试在本机重启,如果它在启动时连续失败到一定的次数,无法发送心跳到Nimbus,Nimbus将在另一台主机上重新分配worker
- Supervisor失败,Supervisor是无状态(所有的状态都保存在ZK或磁盘上)和快速失败(每当遇到任何意外的情况,进程自动毁灭),因此Spuervisor的失败不会影响当前正在运行的任务,只要及时将他们重启即可
- Numbus失败,Nimbus也是无状态和快速失败的,因此Nimbus的失败不会影响当前正在进行的任务,但是当Numbus失败时,无法提交新的任务,只要及时将它重新启动即可。
集群节点故障
- Strom集群中的节点故障,此时Nimbus会将此机器上所有正在运行的任务转移到其他可用的机器上运行。
- ZK急群众的节点故障,ZK保证少于板书的机器宕机系统仍可正常访问,及时修复故障即可
Numbus是否是“单点故障”的
- 如果失去了Nimbus节点,Worker也会继续执行,另外,如果worker死亡,Supervisor也会继续重启它,但是,没有Nimbus,Worker不会在必要时被安排到其他主机,客户端也无法提交任务。
Flink
http://www.360doc.com/content/17/0526/17/21332217_657502791.shtml
流式的数据流执行引擎,针对数据流分布式计算提供了数据分布、数据通信以及容错机制等功能。
DataSet 对静态数据进行操作,将静态数据抽象成分布式数据集 / DataStream 流式 / Table结构化数据抽象成关系表
集成Hadoop生态圈其他项目,可以读取存储在HDFS或HBase中的静态数据,以Kafka作为流式数据源,直接重用MapReduce或Storm代码或通过YARN申请集群资源等
一般原则:
storm流处理任务,mapreduce、spark支持批量任务,spark streaming是在spark上支持流处理任务的子系统,其采用了一种mirco-batch的架构,把输入的数据切分为细粒度的batch,并且每个batch数据提交一个批处理的spark任务,所以spark streaming本质上还是基于spark批处理系统对流式数据的处理,而storm则完全流式,flink能够同时支持批量任务处理和流处理任务。
在执行引擎这一层,流处理系统和批处理系统最大的不同在于节点之间的数据传输方式。对于一个流处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,然后立即通过网络传输到下一个节点,由下一个节点继续处理。对于一个批处理系统,其节点间数据传输的标准模型是:当一条数据被处理完毕后,序列化到缓存中,并不会立刻通过网络传输到下一个节点,当缓存写满,就持久化到本地硬盘上,当所有数据都被处理完成后,才开始将处理后的数据通过网络传输到下一个节点。这两种充分体现了流处理对系统低延迟的要求和批处理系统对高吞吐量的要求。
Flink执行引擎采用了一种十分灵活的方式,同时支持了两种传输模型。以固定的缓存块为单位进行网络传输,用户可以通过缓存块超时值指定缓存块的传输机制,如果缓存块超时值为0,则数据传输方式类似流式系统标准模型,此时系统获得最低的处理延迟。如果缓存块的超时无限大,则数据传输方式类似批处理系统标准模型,此时系统可以获得最高的吞吐量。总之缓存块的超时阈值越小,流处理执行引擎的数据处理延迟越低,但吞吐量也会降低,反之亦然。用户通过延迟和吞吐量进行权衡
容错:批处理系统由于文件可以重复访问,当某个人物失败后,重启该人物即可,但流式系统数据源源不断,任务连续运行
flink 分布式快照、可部分重发的数据,用户可以自定义对整个JOB进行快照的时间间隔,当任务失败时,flink会将整个job恢复到最近一次快照,并从数据源重发快照之后的数据。
按照用户自定义的分布式快照间隔时间,flink会定时在所有数据源中插入一种特殊的快照标志消息,这些快照标志消息和其他消息一样在DAG中流动,但是不会被用户定义的业务逻辑所处理,每一个快照标记消息都将其所在的数据流分成两部分:本次快照数据和下次快照数据
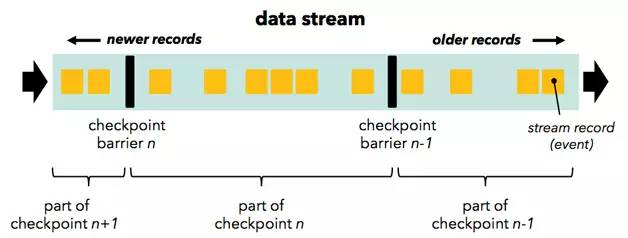
快照标记消息沿着DAG流经各个操作符,当操作符处理到快照标记消息时,会对自己的状态进行快照,并存储起来,当一个操作符有多个输入的时候,Flink会将先抵达的快照标记消息及其之后的消息缓存起来,当所有的输入中对应该次快照标记消息全部抵达后,操作符对自己的状态快照并存储,之后处理所有快照标记消息之后的已缓存消息。操作符对自己的状态快照并存储可以是异步与增量的操作,并不需要阻塞消息的处理。
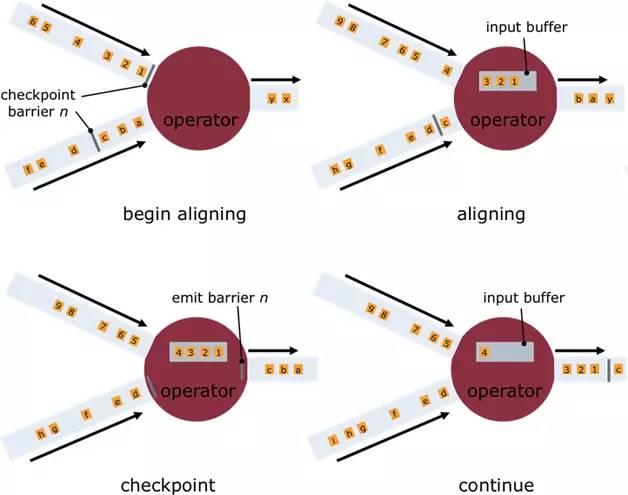
当所有的Data Sink(终点操作符),都收到快照标记信息并对自己的状态快照和存储后,整个分布式快照就完成了,同时通知数据源释放该快照标记消息之前的所有消息,若之后发生节点崩溃等异常情况时,只需要恢复之前存储的分布式快照状态,并从数据源重发该快照以后的消息就可以了
Exactly-Once是流处理系统需要支持的一个非常重要的特性,它保证每一条消息只被流处理系统处理一次,许多流处理系统的业务逻辑都依赖于Exactly-Once。相对于至多一次和至少一次,flink基于分布式快照实现了精确一次特性
分布式快照方式的优点:
低延迟,由于操作符状态的存储可以异步,所以进行快照的过程基本上不会阻塞消息的处理,所以不会对消息延迟产生负面的影响。
高吞吐量,当操作符状态较少时,对吞吐量基本没有影响,当操作符状态较多时,相对于其他容错机制,分布式快照的时间间隔是用户自己定义的,所以用户可以权衡错误恢复时间和吞吐量要求来调整分布式快照的时间间隔
与业务逻辑的隔离,分布式快照机制与用户的业务逻辑完全隔离,用户的业务逻辑不会依赖或是对分布式快照产生任何影响
错误恢复的代价,分布式快照的事件间隔越短,错误恢复的事件越少,与吞吐量负相关
流处理的时间窗口:
对于流处理系统来说,流入的消息时不存在上限,所以对于聚合连接等操作,流处理系统需要对流入的消息进行分段,然后基于每一段数据进行聚合或者是连接,消息的分段即为窗口,流处理系统支持的窗口类型很多,比如基于时间间隔对消息进行分段的事件窗口。
事件窗口一般是根据Task所在节点的本地始终进行切分,这种实现容易,不会产生阻塞。但有的场景无法实现,比如消息本身带有时间戳,用户希望按照消息本身的时间戳来分段;由于不同节点的是种可能不同,以及消息在流经各个节点的延迟不同,在某个节点属于同一个时间窗口处理的消息,流到下一个节点时可能被切割分到不同的事件窗口中,从而产生不符合预期的结果。
flink支持3种时间窗
1. Operator Time: 根据Task所在节点的本地时钟来切分的时间窗口
2. Event Time: 消息自带的时间戳,确保时间戳在同一个时间窗口的所有消息一定会被正确处理,由于消息可能乱序流入Task,所以Task需要缓存当前时间窗口消息处理的状态,直到确认属于该时间窗口的所有消息都被处理,才可以释放,如果乱序的消息延迟很高会影响分布式系统的吞吐量
3. Ingress Time: 消息本身并不带有时间戳信息,但用户仍然希望按照消息而不是节点的时钟划分窗口时间,此时可以在消息流入flink流处理系统时自动生成增量的时间戳赋予消息,之后处理流程与event time相同。由于其在消息源处时间戳一定是有序的,所以在流处理系统中,相对于event time,其乱序的消息延迟不会很高,因此对flink分布式系统的吞吐量和延迟的影响也会更小
Event Time时间窗口实现:
通过water mark来支持 http://www.360doc.com/content/17/0526/17/21332217_657502879.shtml

flink的一些优化:通用手段
定制的序列化工具,显示内存管理的前提步骤就是序列化,将JAVA对象序列化成二进制数据存储在内存上(on heap 或 off heap),序列化反序列化,减少元数据信息冗余。比如Hadoop writable自己实现该接口等
显示的内存管理,一般通用的做法是批量申请和释放内存,每个JVM实例有一个统一的内存管理器,所有内存的申请和释放都通过该内存管理器进行,可以避免常见的内存碎片问题,同时由于数据以二进制的方式存储,可以大大减轻垃圾回收的压力
缓存友好的数据结构和算法,对于计算密集的数据结构和算法,直接操作序列化或的二进制数据,而不是将对象反序列化后再进行操作,同时,只将操作相关的数据连续存储,可以最大化的利用L1/L2/L3缓存,减少cache miss的概率,提升CPU计算的吞吐量,以排序为例,由于排序的主要操作是对Key进行对比,如果将所有排序数据的key与value分开并对key连续存储,那么访问key时cache命中率会大大提高
分布式计算框架可以使用定制序列化工具的前提是要待处理数据流是同一类型,由于数据集对象的类型固定,从而可以只保存一份对象的schema信息,节省大量的存储空间,同时,对于固定大小的类型,也可以通过固定的便宜位置存取,在需要访问某个对象成员变量时,通过定制的序列化工具,并不需要反序列化整个对象,而是直接通过偏移量,从而只需要反序列化特定的对象成员变量,如果对象的成员变量较多时,能够大大减少JAVA对象的创建开销,以及内存数据的拷贝大小,flink数据集都支持任意的java或scala类型,通过自动生成定制序列化工具,既能够保证api接口对用户的友好,也达到了和hadoop类似的序列化效果
Flink将内存分为3个部分,每个部分都有不同用途:
Network buffers: 一些以32KB Byte数组为单位的buffer,主要被网络模块用于数据的网络传输。
Memory Manager pool大量以32KB Byte数组为单位的内存池,所有的运行时算法(例如Sort/Shuffle/Join)都从这个内存池申请内存,并将序列化后的数据存储其中,结束后释放回内存池。
Remaining (Free) Heap主要留给UDF中用户自己创建的Java对象,由JVM管理。
更高效的存储格式。Parquet,ORC等列式存储被越来越多的Hadoop项目支持,其非常高效的压缩性能大大减少了落地存储的数据量。
Spark/Storm/Flink的更多相关文章
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink
转自:https://www.cnblogs.com/reed/p/7730329.html 今天看到一篇讲得比较清晰的框架对比,这几个框架的选择对于初学分布式运算的人来说确实有点迷茫,相信看完这篇文 ...
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink——flink支持SQL,待看
简介 大数据是收集.整理.处理大容量数据集,并从中获得见解所需的非传统战略和技术的总称.虽然处理数据所需的计算能力或存储容量早已超过一台计算机的上限,但这种计算类型的普遍性.规模,以及价值在最近几年才 ...
- 论文阅读计划1(Benchmarking Streaming Computation Engines: Storm, Flink and Spark Streaming & An Enforcement of Real Time Scheduling in Spark Streaming & StyleBank: An Explicit Representation for Neural Ima)
Benchmarking Streaming Computation Engines: Storm, Flink and Spark Streaming[1] 简介:雅虎发布的一份各种流处理引擎的基准 ...
- 数据框架对比:Hadoop、Storm、Samza、Spark和Flink——flink支持SQL,待看
简介 大数据是收集.整理.处理大容量数据集,并从中获得见解所需的非传统战略和技术的总称.虽然处理数据所需的计算能力或存储容量早已超过一台计算机的上限,但这种计算类型的普遍性.规模,以及价值在最近几年才 ...
- hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析
hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析 Spark是一种快速.通用的计算集群系统,Spark提出的最主要抽象概念是弹性分布式数据集(RDD),它是一个元素集 ...
- Spark与Flink大数据处理引擎对比分析!
大数据技术正飞速地发展着,催生出一代又一代快速便捷的大数据处理引擎,无论是Hadoop.Storm,还是后来的Spark.Flink.然而,毕竟没有哪一个框架可以完全支持所有的应用场景,也就说明不可能 ...
- 怎样在Spark、Flink应用中使用Protobuf 3的包
如果在在Spark.Flink应用中使用Protobuf 3的包,因为Spark默认使用的是2.5版本的包,提交任务时,可能会报如下异常: com.google.protobuf.CodedInput ...
- 开源项目推荐 - 巨鲸任务调度平台(Spark、Flink)
Big Whale(巨鲸),为美柚大数据研发的大数据任务调度平台,提供Spark.Flink等离线任务的调度(支持任务间的依赖调度)以及实时任务的监控,并具有批次积压告警.任务异常重启.重复应用监测. ...
- Flink及主流流框架spark,storm比较
干货 | Flink及主流流框架比较 IT刊 百家号17-05-2220:16 引言 随着大数据时代的来临,大数据产品层出不穷.我们最近也对一款业内非常火的大数据产品 - Apache Flink做了 ...
随机推荐
- HDOJ 2005 第几天?
#include<iostream> using namespace std; ] = { ,,,,,,,,,,, }; ] = { ,,,,,,,,,,, }; bool isRYear ...
- vultr上 windows使用pptp拨号来实现冗余双网关的解决方案
rasdial是拨号程序,pptpvpn是网卡拨号名称,后面跟的是帐号和密码.pptpvpn见下图:就是提前创建好一个PPTP的拨号连接 上面是启动时候的计划任务,那么万一拨号中断,要继续重拨还需要做 ...
- SQLite3数据库
#SQLite可视化管理工具(SQLite Expert Pro) SQLite特点: 1. 遵守ACID(原子性.一致性.隔离性和持久性)的关系型数据库管理系统:2. 不是一个C/S结构的数据库引擎 ...
- Sebastian Ruder : NLP 领域知名博主博士论文面向自然语言处理的神经网络迁移学习
Sebastian Ruder 博士的答辩 PPT<Neural Transfer Learning for Natural Language Processing>介绍了面向自然语言的迁 ...
- 《Linux 性能及调优指南》1.4 硬盘I/O子系统
翻译:飞哥 (http://hi.baidu.com/imlidapeng) 版权所有,尊重他人劳动成果,转载时请注明作者和原始出处及本声明. 原文名称:<Linux Performance a ...
- IIS Express内存溢出错误
IIS Express只是vs自带的一个简单版开发调试用的web服务器,所以本身貌似并不能容纳太多内存,有时候内存占用超过一定程度就会出错. 这时候可以试着发布到真正的IIS上查看一下,可能就不会出错 ...
- Codeforces Round #493 (Div. 1)
A. /* 发现每次反转或者消除都会减少一段0 当0只有一段时只能消除 这样判断一下就行 */ #include<cstdio> #include<algorithm> #in ...
- JVM总结-synchronized
在 Java 程序中,我们可以利用 synchronized 关键字来对程序进行加锁.它既可以用来声明一个 synchronized 代码块,也可以直接标记静态方法或者实例方法. 当声明 synchr ...
- 《图像处理实例》 之 Voronoi 图
Voronoi 图的设计 以下的改进是http://www.imagepy.org/的作者原创,我只是对其理解之后改进和说明,欢迎大家使用这个小软件! 如有朋友需要源工程,请在评论处留邮箱! 说明:类 ...
- 20165205 实验一 java开发环境的熟悉 实验报告
20165205 实验一 Java开发环境的熟悉 一.实验报告封面 课程:Java程序设计 班级:1652班 姓名:刘喆君 学号:20165205 指导教师:娄嘉鹏 实验日期:2018年4月2日 实验 ...