爬虫--Scrapy框架课程介绍
Scrapy框架课程介绍:
- 框架的简介和基础使用
- 持久化存储
- 代理和cookie
- 日志等级和请求传参
- CrawlSpider
- 基于redis的分布式爬虫
一scrapy框架的简介和基础使用
a) 概念:为了爬取网站数据而编写的一款应用框架,出名,强大。所谓的框架其实就是一个集成了相应的功能且具有很强通用性的项目模板。(高性能的异步下载,解析,持久化……)
b) 安装:
i. linux mac os:pip install scrapy
ii. win:
- pip install wheel
- 下载twisted:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
pip install 下载好的框架.whl
- pip install pywin32
- pip install scrapy
c) 基础使用: 使用流程
i. 创建一个工程:scrapy startproject 工程名称
- 目录结构:
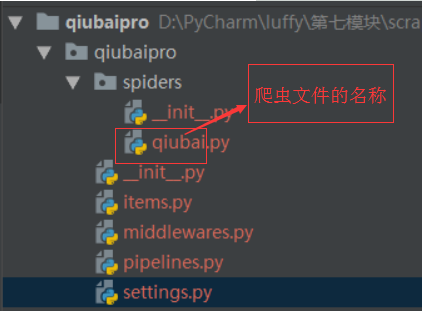
ii. 在工程目录下创建一个爬虫文件:
- cd 工程
- scrapy genspider 爬虫文件的名称 起始url
iii. 对应的文件中编写爬虫程序来完成爬虫的相关操作
iv. 配置文件的编写(settings)
v. 执行
vi. 在工程目录下创建一个爬虫文件
- cd 工程
- scrapy genspider 爬虫文件的名称 起始的url
vii. 对应的文件中编写爬虫程序来完成爬虫的相关操作
viii. 配置文件的编写(settings)
- 19行:对请求载体的身份进行伪装
- 22行:不遵从robots协议
ix. 执行 :scrapy crawl 爬虫文件的名称 --nolog(阻止日志信息的输出)

cp后面的数字代表python的版本,35代表3.5版本;

创建项目:
目前还没有IDE 能够创建scrapy的项目,我们必须手动初始化项目
1、找一个目录
输入命令
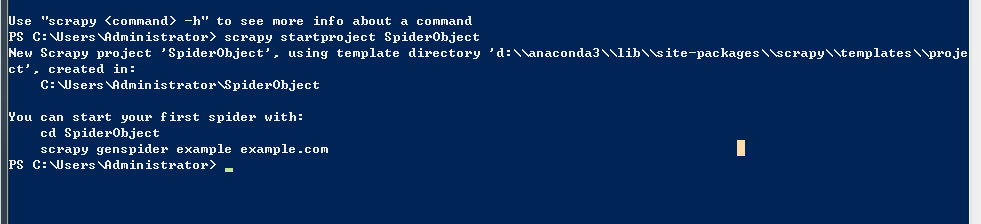
命令行出现这样的结果说明创建成果 You can start your first spider with:
cd SpiderObject
scrapy genspider example example.com
------------------------------------------
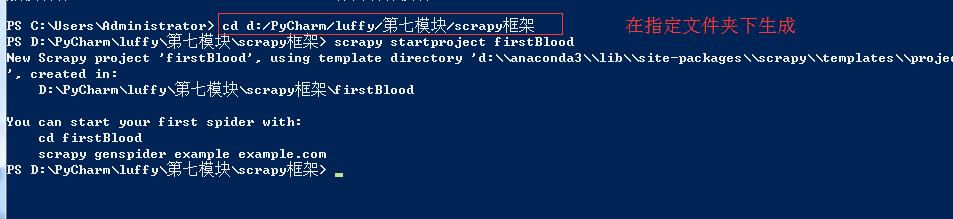
基础使用: 使用流程
1、创建一个工程:scrapy startproject 工程名称
在命令行下:
scrapy startproject 项目名称
在pycharm中打开:

目录结构:
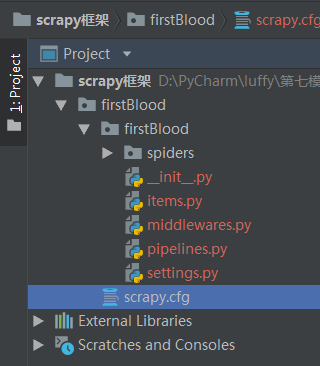
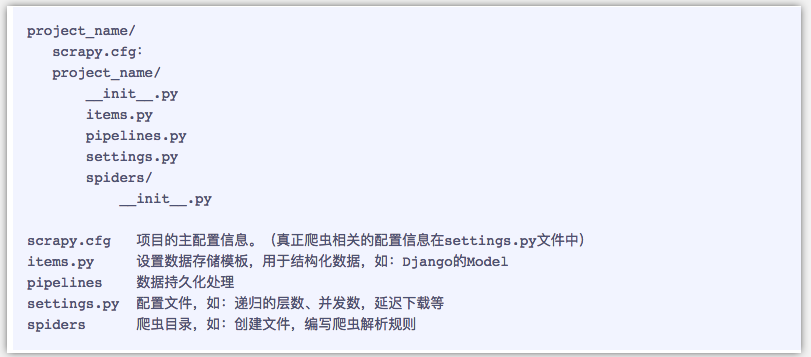
pipelines管道
2.在工程目录下创建一个爬虫文件:
1. 在命令行下 cd 进入工程所在文件夹
2.scrapy genspider 爬虫文件的名称 起始url


class FirstSpider(scrapy.Spider):
# 爬虫文件的名称:通过爬虫文件的名称可以指定的定位到某一个具体的爬虫文件
name = 'first'
# 允许的域名:只可以爬取指定域名下的页面数据
allowed_domains = ['www.baidu.com']
# 起始url
start_urls = ['http://www.baidu.com/']
# 解析方法:对获取的页面数据进行指定内容的解析
# response:根据起始url列表发起请求,请求成功后返回的响应对象
# parse方法返回值:必须为迭代器或者空
def parse(self, response):
print(response.text)#获取响应对象中的页面数据
print('执行over')
3.对应的文件中编写爬虫程序来完成爬虫的相关操作
初始阶段settings.py配置
修改内容及其结果如下:
19行:USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' #伪装请求载体身份 22行:ROBOTSTXT_OBEY = False #可以忽略或者不遵守robots协议
进入到项目文件下再执行命令
执行 :scrapy crawl 爬虫文件的名称 --nolog(阻止日志信息的输出)

如果后面加上 --nolog就是阻止日志信息输出
小试牛刀:将糗百首页中段子的内容和标题进行爬取
vi. 在工程目录下创建一个爬虫文件
1. cd 工程
2. scrapy genspider 爬虫文件的名称 起始的url
vii. 对应的文件中编写爬虫程序来完成爬虫的相关操作
viii. 配置文件的编写(settings)
1. 19行:对请求载体的身份进行伪装
2. 22行:不遵从robots协议
ix. 执行 :scrapy crawl 爬虫文件的名称 --nolog(阻止日志信息的输出)
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
#allowed_domains = ['www.qiushibaike.com/text']
start_urls = ['https://www.qiushibaike.com/text/'] def parse(self, response):
# 建议大家使用xpath进行解析(框架集成了xpath解析的接口)
div_list = response.xpath("//div[@id='content-left']/div")
for div in div_list:
author = div.xpath('./div/a[2]/h2/text()')
content = div.xpath(".//div[@class='content']/span/text()")
print(author)
-------------------------------------

# xpath解析到的指定内容被存储到了Selector对象
# extract()改方法可以将Selector对象数据值拿到
#author = div.xpath('./div/a[2]/h2/text()').extract()[0]
author = div.xpath('./div/a[2]/h2/text()').extract_first()

最终形式:
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
#allowed_domains = ['www.qiushibaike.com/text']
start_urls = ['https://www.qiushibaike.com/text/'] def parse(self, response):
# 建议大家使用xpath进行解析(框架集成了xpath解析的接口)
div_list = response.xpath("//div[@id='content-left']/div")
for div in div_list:
# xpath解析到的指定内容被存储到了Selector对象
# extract()改方法可以将Selector对象数据值拿到
#author = div.xpath('./div/a[2]/h2/text()').extract()[0]
# extract()[0]======>extract_first()
author = div.xpath('./div/a[2]/h2/text()').extract_first()
#content = div.xpath(".//div[@class='content']/span/text()")
content = div.xpath(".//div[@class='content']/span/text()").extract_first()
print(author)
print(content)

爬虫--Scrapy框架课程介绍的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- 爬虫scrapy框架之CrawlSpider
爬虫scrapy框架之CrawlSpider 引入 提问:如果想要通过爬虫程序去爬取全站数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模 ...
- 安装爬虫 scrapy 框架前提条件
安装爬虫 scrapy 框架前提条件 (不然 会 报错) pip install pypiwin32
- 爬虫Ⅱ:scrapy框架
爬虫Ⅱ:scrapy框架 step5: Scrapy框架初识 Scrapy框架的使用 pySpider 什么是框架: 就是一个具有很强通用性且集成了很多功能的项目模板(可以被应用在各种需求中) scr ...
- 爬虫框架 ---- scrapy 框架的介绍与安装
----- 爬虫 基于B/S 模式的数据采集技术,按照一定的规则,自动的抓取万维网信息程序 以一个或多个页面为爬取起点,从页面中提取链接实现深度爬取 使用爬虫的列子 第三方抢票软件(360/猎豹/ ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- 爬虫Scrapy框架运用----房天下二手房数据采集
在许多电商和互联网金融的公司为了更好地服务用户,他们需要爬虫工程师对用户的行为数据进行搜集.分析和整合,为人们的行为选择提供更多的参考依据,去服务于人们的行为方式,甚至影响人们的生活方式.我们的scr ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
随机推荐
- Zabbix 创建监控项目
#1 #2 [root@nod01 zabbix_agentd.d]# pwd/etc/zabbix/zabbix_agentd.d 新建文件nod.conf [root@nod01 zabbix_a ...
- 1126 Eulerian Path (25 分)
1126 Eulerian Path (25 分) In graph theory, an Eulerian path is a path in a graph which visits every ...
- STL常用容器使用方法
在程序头部使用#include<stack>来引入STL的stack容器,然后使用stack<int> s语句来声明一个管理整型数据的容器s.stack常用成员函数:push( ...
- 第8章 传输层(2)_UDP协议
2. 用户数据报协议(UDP) 2.1 UDP的特点 (1)UDP是无连接的,即发送数据之前不需要建立连接,因此减少了开销和发送数据之前的时延. (2)UDP使用了尽最大努力交付,即不保证可靠交付,因 ...
- java synchronized 同步详解
记下来,很重要. Java语言的关键字,当它用来修饰一个方法或者一个代码块的时候,能够保证在同一时刻最多只有一个线程执行该段代码. 一.当两个并发线程访问同一个对象object中的这个synchron ...
- JS+Ajax+Servlet:记录页面访问时间
1.前端JS记录页面访问时间 1.1JQuery版本: <script type="text/javascript" src="js/jquery.min.js&q ...
- FastDFS+Nginx+fastdfs-nginx-module集群搭建
一.实验环境说明 操作系统: Centos 6.6 x64 FastDFS 相关版本: fastdfs-5.05 fastdfs-nginx-module-v1.16 libfastcommon-v1 ...
- angularjs路由相关知识
angular.module('app').config(['$stateProvider','$urlRouterProvider',function($stateProvider,$urlRout ...
- windows设置电脑的固定IP
当有需要的人往往想要固定自己的IP进行测试,在我通过手机代理来录制测试带宽时不想因为IP经常变更而影响到我的测试 因此,我想要固定自己的IP 1.想要固定IP说明自己的IP设置成了自动获取方式,这样连 ...
- 第十届蓝桥杯JavaB组总结
去年参加了第九届蓝桥杯C/C++B组,很捞,做了大概5道题,就好像就做对了2道结果填空题,编程题只做了一个(只通过了部分测试数据),最后拿了个省三,但是班上那些平时没有认真准备的都拿了省二 今年想好好 ...