游程编码(Run Length Code)
一、什么是游程编码
游程编码是一种比较简单的压缩算法,其基本思想是将重复且连续出现多次的字符使用(连续出现次数,某个字符)来描述。
比如一个字符串:
AAAAABBBBCCC
使用游程编码可以将其描述为:
5A4B3C
5A表示这个地方有5个连续的A,同理4B表示有4个连续的B,3C表示有3个连续的C,其它情况以此类推。
原字符串需要12个字符才能描述,而使用游程编码压缩之后只需要6个字符就可以表示,还原回去的时候只需要将字符重复n次即可,这是个原理非常简单的算法。
再来分析一下这个编码的适用场景,前面说过了这个算法的基本思想是将重复且连续出现的字符进行压缩,使用更简短的方式来描述,这种方式是基于柯氏复杂度的,那么什么是柯氏复杂度呢,比如有这么三个字符串,它们的长度都是100,其中第一个是100个A,第二个是99个A和一个B,第三个是100个完全随机的字符,我们想办法用尽可能短的语言来描述原字符串,描述第一个字符串时可以说“这是100个A”,描述第二个字符串可以说“这是99个A,然后是一个B”,但是描述第三个字符串时应该怎么说呢?比较容易想到的是“这是100个随机字符”,看上去似乎没有问题,但是这里一个比较重要的点是描述信息需要符合这么一个条件,当单独给出对字符串的描述时能够根据描述恢复出原字符串的内容,100个A和先99个A然后是一个B可以,但是100个随机字符太笼统了显然不行,这个描述信息的长度就称之为柯氏复杂度,在这个例子中第一个柯氏复杂度最小,第二第三依次次之。
那么在不同情况下这个编码的效果如何呢,假如采用定长1个字节来描述连续出现次数,并且一个字符占用1个字节,那么描述(连续出现次数,某个字符)需要的空间是2个字节,只要这个连续出现次数大于2就能够节省空间,比如AAA占用3个字节,编码为(3,A)占用两个字节,能够节省一个字节的空间,可以看出连续出现的次数越多压缩效果越好,节省的空间越大,对一个字符编码能够节省的空间等于=连续出现次数-2,于是就很容易推出连续出现次数等于2时占用空间不变,比如AA占用两个字节,编码为(2,A)仍然占用两个字节,白白浪费了对其编码的资源却没有达到节省空间的效果,还有更惨的情况,就是连续出现次数总是为1,这个时候会越压越大,比如A占用一个字节,编码为(1,A)占用两个字节,比原来多了一个字节,这种情况就很悲剧,一个1M的文件可能一下给压缩成了2M(真是效果奇佳啊),这是能够出现的最糟糕的情况,相当于在文件的每一个字节前面都插入了一个多余的字节0X01(这个字节表示连续出现次数为1),这种情况说明不适合使用游程编码,事实上,绝大多数数据的特征都属于第三种情况,不适合使用游程编码。
二、 压缩文本
本节将尝试使用游程编码对文本进行压缩。
先来写一种最简单的实现,只能压缩英文字母,读取一个字符串,然后一直数出现了多少个连续字符,当重复被打断时就将上一个的重复字符和重复次数记一下,恢复时反之:
#! /usr/bin/python3
# -*- coding: utf-8 -*- import random
import string def rle_compress(s):
"""
对字符串使用RLE算法压缩,s中不能出现数字
:param s:
:return:
"""
result = ''
last = s[0]
count = 1
for _ in s[1:]:
if last == _:
count += 1
else:
result += str(count) + last
last = _
count = 1
result += str(count) + last
return result def rle_decompress(s):
result = ''
count = ''
for _ in s:
if _.isdigit():
count += _
else:
result += _ * int(count)
count = ''
return result def random_rle_friendly_string(length):
"""
生成对RLE算法友好的字符串以演示压缩效果
:param length:
:return:
"""
result = ''
while length > 0:
current_length = random.randint(1, length)
current_char = random.choice(string.ascii_letters)
result += (current_char * current_length)
length -= current_length
return result if __name__ == '__main__':
raw_string = random_rle_friendly_string(128)
rle_compressed = rle_compress(raw_string)
rle_decompress = rle_decompress(rle_compressed)
print(' raw string: %s' % raw_string)
print(' rle compress: %s' % rle_compressed)
print('rle decompress: %s' % rle_decompress)
执行效果:
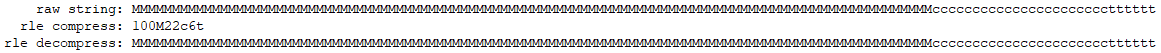
可以看到,128个字符的原始数据被压缩成9个字符,大约是原来的7%。
但是上面的不支持数字是个硬伤,为什么不支持数字呢,因为没办法区分一个数字究竟是表示连续出现次数的数字还是重复字符,这个是编码中经常出现的问题,一个很有效的方式是使数据结构化。
啥是结构化呢,看这个“100M22c6t”,表示连续出现次数的数字100占用三个字符,22占用两个字符,6占用1个字符,不是定长的啊,这个时候可以规定我的整个字符串可以从最开始按两个字符进行分组,每一组的第一个字符表示连续出现次数,第二个字符表示连续出现的字符,这样我按照位置区分数据的类型,就能够存储任意字符了:
#! /usr/bin/python3
# -*- coding: utf-8 -*- import random
import string def rle_compress(s):
"""
对字符串使用RLE算法压缩,s可以出现任意字符,包括数字,因为采用了定长表示重复次数
:param s:
:return:
"""
result = ''
last = s[0]
count = 1
for _ in s[1:]:
# 采用一个字符表示重复次数,所以count最大是9
if last == _ and count < 9:
count += 1
else:
result += str(count) + last
last = _
count = 1
result += str(count) + last
return result def rle_decompress(s):
result = ''
for _ in range(len(s)):
if _ % 2 == 0:
result += int(s[_]) * s[_ + 1]
return result def random_rle_friendly_string(length):
"""
生成对RLE算法友好的字符串以演示压缩效果
:param length:
:return:
"""
char_list_to_be_choice = string.digits + string.ascii_letters
result = ''
while length > 0:
current_length = random.randint(1, length)
current_char = random.choice(char_list_to_be_choice)
result += (current_char * current_length)
length -= current_length
return result if __name__ == '__main__':
# raw_string = random_rle_friendly_string(128)
raw_string = "MMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMcccccccccccccccccccccctttttt"
rle_compressed = rle_compress(raw_string)
rle_decompress = rle_decompress(rle_compressed)
print(' raw string: %s' % raw_string)
print(' rle compress: %s' % rle_compressed)
print('rle decompress: %s' % rle_decompress)
执行效果:
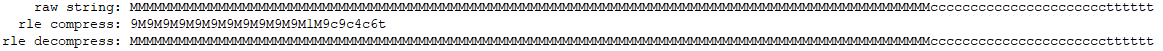
采用定长表示连续出现次数,但是因为一个字符最大能够表示9,所以同样的数据压缩之后比原来大了一些。
三、 压缩字节(二进制文件)
前面的例子使用游程编码压缩文本,看起来很好理解,那么游程编码能不能用来压缩二进制文件呢。
二进制文件在内存中的表示是字节,所以需要想办法能够压缩字节,压缩字节和压缩字符其实是一样一样的,还是结构化的存储,每两个字节一组,每组的第一个字节表示连续出现次数,第二个字节表示连续出现的字节。
#! /usr/bin/python3
# -*- coding: utf-8 -*- def compress_file_use_rle(src_path, dest_path):
with open(dest_path, 'wb') as dest:
with open(src_path, 'rb') as src:
last = None
count = 0
t = src.read(1)
while t:
if last is None:
last = t
count = 1
else:
# 一个字节能够存储的最大长度是255
if t == last and count < 255:
count += 1
else:
dest.write(int.to_bytes(count, 1, byteorder='big'))
dest.write(last)
last = t
count = 1
t = src.read(1)
dest.write(int.to_bytes(count, 1, byteorder='big'))
dest.write(last) def decompress_file_use_rle(src_path, dest_path):
with open(dest_path, 'wb') as dest:
with open(src_path, 'rb') as src:
count = src.read(1)
byte = src.read(1)
while count and byte:
dest.write(int.from_bytes(count, byteorder='big') * byte)
count = src.read(1)
byte = src.read(1) if __name__ == '__main__':
img_name = 'test-bmp-24'
suffix = 'bmp'
raw_img_path = 'data/%s.%s' % (img_name, suffix)
rle_compressed_img_save_path = 'data/%s-rle-compressed.%s' % (img_name, suffix)
rle_decompress_img_save_path = 'data/%s-rle-decompress.%s' % (img_name, suffix) compress_file_use_rle(raw_img_path, rle_compressed_img_save_path)
decompress_file_use_rle(rle_compressed_img_save_path, rle_decompress_img_save_path)
对文件进行压缩比较适合的情况是文件内的二进制有大量的连续重复,一个经典的例子就是具有大面积色块的BMP图像,BMP因为没有压缩,所以看到的是什么样子存储的时候二进制就是什么样子,来做一个简单的实验,Win+R,输入mspaint打开Windows自带的画图程序,随便涂抹一副具有大面积色块的图片:

保存时选择256色的BMP:
为什么一定要是BMP呢,因为这种算法不压缩,存储二进制的规律与看到的一致,那为什么是256色呢,因为上面写的程序只计算后面一个字节的重复次数,而一个字节能够表示最大256色,如果表示一个像素超过了一个字节,那么上面的代码将很可能越压越大起不到任何作用。
然后对比一下结果:

压缩效果很惊人,原来370K的文件压缩后只有7K,是原来的1.9%,相当于98.1%的数据被压掉了,并且是无损压缩。
那么试一下对于颜色比较丰富的256色图图片呢,随便搞一张信息量比较大的贴到画图中然后保存为256色BMP:

将其转为256色之后会损失一些颜色,然后看下效果:

效果并不太理想,所以还是具有大面积色块的256色以下的BMP更合适,当然存储图片时一般也没有使用BMP格式的,太奢侈了,这里只是强行举了一个例子。
另外值得一提的是,因为是边读取边压缩边写入,所以这种也可以读取输入流中的数据写到输出流,不受文件大小的限制可以无限压缩下去。
四、总结
游程编码适合的场景是数据本身具有大量连续重复出现的内容。
.
游程编码(Run Length Code)的更多相关文章
- 游程编码run length code
今天突然看到一个名词,游程编码.也叫行程编码. 简单理解就是,几个相同连续的字符,然后用数字统计表示. 举个例子: aaaabbbccc 用游程编码的表示就是4a3b3c 如果:连续字符只有一个 那么 ...
- Two-Pointer 之 Run Length Coding (RLC)
游程编码(Run Length Coding, RLC)是串处理中常见的预处理方法.其写法是典型的双指针(Two-Pointer).下面总结其写法1.输入为一串整数可以不把整数存在数组里
- poj-1782 Run Length Encoding
http://poj.org/problem?id=1782 Run Length Encoding Time Limit: 1000MS Memory Limit: 30000K Total S ...
- How to run Python code from Sublime
How to run Python Code from Sublime,and How to run Python Code with input from sublime Using Sublime ...
- phpstorm之"Can not run PHP Code Sniffer"
前言 其实我是不太愿意写这种工具使用博客的,因为实在没有营养,只是有些简单问题,搜索一番,却始终找不到答案,遂以博客记录下来,希望后面的人,可以省去搜索之苦. 相信你搜到这篇博客,肯定是已经安装好了P ...
- SDUT 2352 Run Length Encoding
点我看题目 题意 :将给定的字符串编码,编码的规则根据两条,1.如果字符串里有连续相等的字符,就变为两个字符,一个是这些连续相同的字符的个数,另一个是这个字符,但是如果数量超过了9个,那就输出9再输出 ...
- Hadoop-No.4之列式存储格式
列式系统可提供的优势 对于查询内容之外的列,不必执行I/O和解压(若适用)操作 非常适合仅访问小部分列的查询.如果访问的列很多,则行存格式更为合适 相比由多行构成的数据块,列内的信息熵更低,所以从压缩 ...
- Code First :使用Entity. Framework编程(6) ----转发 收藏
Chapter6 Controlling Database Location,Creation Process, and Seed Data 第6章 控制数据库位置,创建过程和种子数据 In prev ...
- Code First :使用Entity. Framework编程(7) ----转发 收藏
第7章 高级概念 The Code First modeling functionality that you have seen so far should be enough to get you ...
随机推荐
- ace -- api
Ace The main class required to set up an Ace instance in the browser. 在浏览器中设置一个ace实例所需要的主要类. Methods ...
- 2013337朱荟潼 Linux第五章读书笔记——系统调用
摘要: [20135337朱荟潼]原创作品转载请注明出处 第五章 系统调用 5.1 与内核通信 中间层 作用三个:1.为用户空间提供一种硬件的抽象接口:2.保证系统稳定和安全:3.除异常和陷入,是内核 ...
- Java的三大特性:封装、继承、多态
一.类的概念: 类一般包括两个部分:属性(成员变量)和方法(成员方法)方法组成部分:修饰符(可选) 返回值类型(必须) 方法名(必须)参数列表(可选) package com.classTest.pr ...
- 使用Samba服务程序,让linux系统之间共享文件
yum install -y cifs-utils mkdir /database 创建挂载目录 在root家目录创建认证文件(依次为SMB用户名.SMB用户密码.SMB共享域) v ...
- 【补】debug
懒得翻别人博客了,之前的按钮不显示名字,应该是文字ui文件名写错了. 现在不存在任何已知bug.
- helm的安装于与简单使用
根据 csdn 博客整理学习 原始博客地址: https://blog.csdn.net/weiguang1017/article/details/78045013 1. 下载所需要的文件: 客户端文 ...
- Android Manifest文件
Manifest文件内容 1.自定义权限(Permission) : <permission android:description="string resource" a ...
- java 重载 : 1.参数个数不同,2.参数类型不同
参数个数相同时,参数类型需要不同,即使是不同变量名也不行.和是和变量的个数或者是变量的类型有关系 如果相同的话是覆盖 会报错 重载(overloading) 是在一个类里面,方法名字相同,而参数不同 ...
- Emmagee—开源Android性能测试工具
下载:https://github.com/NetEase/Emmagee/releases/download/V2.5/Emmagee.apk 1.Emmagee——Android性能测试工具 Em ...
- pgm7
和 Koller 的 video 最大的不同莫过于书上讲 LBP 的角度不是 procedural 的,而是原理性的.我们先看个 procedural 的,在一般的 cluster graph 上的 ...