selenium在scrapy中的应用
引入
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值。
1.案例分析:
- 需求:爬取网易新闻的国内板块下的新闻数据
- 需求分析:当点击国内超链进入国内对应的页面时,会发现当前页面展示的新闻数据是被动态加载出来的,如果直接通过程序对url进行请求,是获取不到动态加载出的新闻数据的。则就需要我们使用selenium实例化一个浏览器对象,在该对象中进行url的请求,获取动态加载的新闻数据。
2.selenium在scrapy中使用的原理分析:
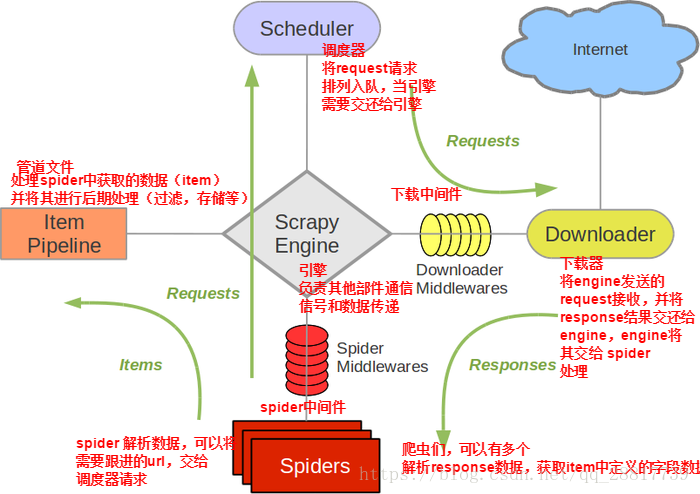
当引擎将国内板块url对应的请求提交给下载器后,下载器进行网页数据的下载,然后将下载到的页面数据,封装到response中,提交给引擎,引擎将response在转交给Spiders。Spiders接受到的response对象中存储的页面数据里是没有动态加载的新闻数据的。要想获取动态加载的新闻数据,则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截,切对其内部存储的页面数据进行篡改,修改成携带了动态加载出的新闻数据,然后将被篡改的response对象最终交给Spiders进行解析操作。
3.selenium在scrapy中的使用流程:
- 重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次)
- 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用
- 重写下载中间件的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
- 在配置文件中开启下载中间件
4.代码展示:
- 爬虫文件:
- class WangyiSpider(RedisSpider):
- name = 'wangyi'
- #allowed_domains = ['www.xxxx.com']
- start_urls = ['https://news.163.com']
- def __init__(self):
- #实例化一个浏览器对象(实例化一次)
- self.bro = webdriver.Chrome(executable_path='/Users/bobo/Desktop/chromedriver')
- #必须在整个爬虫结束后,关闭浏览器
- def closed(self,spider):
- print('爬虫结束')
- self.bro.quit()
- 中间件文件:
- from scrapy.http import HtmlResponse
- #参数介绍:
- #拦截到响应对象(下载器传递给Spider的响应对象)
- #request:响应对象对应的请求对象
- #response:拦截到的响应对象
- #spider:爬虫文件中对应的爬虫类的实例
- def process_response(self, request, response, spider):
- #响应对象中存储页面数据的篡改
- if request.url in['http://news.163.com/domestic/','http://news.163.com/world/','http://news.163.com/air/','http://war.163.com/']:
- spider.bro.get(url=request.url)
- js = 'window.scrollTo(0,document.body.scrollHeight)'
- spider.bro.execute_script(js)
- time.sleep(2) #一定要给与浏览器一定的缓冲加载数据的时间
- #页面数据就是包含了动态加载出来的新闻数据对应的页面数据
- page_text = spider.bro.page_source
- #篡改响应对象
- return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding='utf-8',request=request)
- else:
- return response
- 配置文件:
- DOWNLOADER_MIDDLEWARES = {
- 'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543,
- }
selenium在scrapy中的应用的更多相关文章
- selenium在scrapy中的使用、UA池、IP池的构建
selenium在scrapy中的使用流程 重写爬虫文件的构造方法__init__,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次). 重写爬虫文件的closed ...
- 爬虫开发12.selenium在scrapy中的应用
selenium在scrapy中的应用阅读量: 370 1 引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝 ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- 如何优雅的在scrapy中使用selenium —— 在scrapy中实现浏览器池
1 使用 scrapy 做采集实在是爽,但是遇到网站反爬措施做的比较好的就让人头大了.除了硬着头皮上以外,还可以使用爬虫利器 selenium,selenium 因其良好的模拟能力成为爬虫爱(cai) ...
- Scrapy中集成selenium
面对众多动态网站比如说淘宝等,一般情况下用selenium最好 那么如何集成selenium到scrapy中呢? 因为每一次request的请求都要经过中间件,所以写在中间件中最为合适 from se ...
- 15.scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- 在Scrapy中使用selenium
在scrapy中使用selenium 在scrapy中需要获取动态加载的数据的时候,可以在下载中间件中使用selenium 编码步骤: 在爬虫文件中导入webdrvier类 在爬虫文件的爬虫类的构造方 ...
- scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- scrapy中 selenium(中间件) + 语言处理 +mysql
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现,通过 ...
随机推荐
- 记录:禁用你的元素 bootstrap
记录:禁用你的元素 bootstrap <script> $(document).ready(function() { $("#target1").css(" ...
- 20165308 《Java程序设计》第9周学习总结
20165308 <Java程序设计>第9周学习总结 教材学习内容总结 13章知识总结 获取地址 1.获取Internet上主机的地址 可以使用InetAddress类的静态方法getBy ...
- 如何使用redis计数器防止并发请求
需求描述 最近项目中有个需求,短信发送的并发请求问题:业务需求是需要限制一个号码一分钟内只能获取一次随机码,之前的实现是短信发送请求过来后,先去数据库查询发送记录,根据上一次的短信发送时间和当前时间比 ...
- dojo:如何显示ListBox风格的选择框
常见的选择框控件:Selelct.FilteringSelect和ComboBox都是下拉框风格,而不是ListBox风格. dojo还提供了一个dijit.form.MultiSelect控件可以解 ...
- 快速学习hadoop只有这些基础可不行
“学习hadoop需要什么基础”这已经不是一个新鲜的话题了,随便上网搜索一下就能找出成百上千篇的文章在讲学习hadoop需要掌握的基础.再直接的一点的问题就是——学Hadoop难吗?用一句特别让人无语 ...
- Vivado使用技巧(1)
Vivado使用技巧 (1) 1. 2.复位准则: 3. 4. 5. 6. 7. 8.
- SDI初识
SDI初识 SDI接口,即“数字分量串行接口(Serial Digital Interface)”.按照速率可以分为: 标准清晰度SD-SDI,速率为270Mb/s; 高清标准HD-SDI,速率为1. ...
- OpenSSL 1.0.0生成p12、jks、crt等格式证书的命令个过程 -参考自http://lavasoft.blog.51cto.com/62575/1104993/
OpenSSL 1.0.0生成p12.jks.crt等格式证书的命令个过程 此生成的证书可用于浏览器.java.tomcat.c++等.在此备忘! 1.创建根证私钥命令:openssl g ...
- VarIsOrdinal,VarIsFloat,VarIsNumeric判断数字
VarIsOrdinal VarIsFloat VarIsNumeric 就三个. 第一个 是否int,boolean 第二个 是否Double,Simple,Curren ...
- Linux 如何测试 IO 性能(磁盘读写速度)
这几天做MySQL性能测试,偌大一个公司,找几台性能测试机器都很纠结,终于协调到两台,IO的性能如何还不知道.数据库属于IO密集型的应用,所以还是先评估下Server的IO性能,看看是否能和线上的机器 ...