CentOS7 安装kylin2.6.0集群
1. 环境准备
JDK1.8
2. 集群规划
| ip地址 | 机器名 | 角色 |
| 192.168.1.101 | palo101 | hadoop namenode, hadoop datanode, yarn nodeManager, zookeeper, hive, hbase master,hbase region server, |
| 192.168.1.102 | palo102 | hadoop secondary namenode, hadoop datanode, yarn nodeManager, yarn resource manager, zookeeper, hive, hbase master,hbase region server |
| 192.168.1.103 | palo103 | hadoop datanode, yarn nodeManager, zookeeper, hive,hbase region server,mysql |
3. 下载kylin2.6
- wget http://mirrors.tuna.tsinghua.edu.cn/apache/kylin/apache-kylin-2.6.0/apache-kylin-2.6.0-bin-hbase1x.tar.gz #下载kylin2.6.0二进制文件
- tar -xzvf apache-kylin-2.6.-bin-hbase1x.tar.gz #解压kylin2..0二进制压缩包
- mv apache-kylin-2.6.-bin apache-kylin-2.6. #将kylin解压过的文件重命名(去掉最后的bin)
- mkdir /usr/local/kylin/ #创建目标存放路径
- mv apache-kylin-2.6. /usr/local/kylin/ #将kylin2..0文件夹移动到/usr/local/kylin目录下
4. 添加系统环境变量
- vim /etc/profile
在文件末尾添加
- #kylin
- export KYLIN_HOME=/usr/local/kylin/apache-kylin-2.6.
- export KYLIN_CONF_HOME=$KYLIN_HOME/conf
- export PATH=:$PATH:$KYLIN_HOME/bin:$CATALINE_HOME/bin
- export tomcat_root=$KYLIN_HOME/tomcat #变量名小写
- export hive_dependency=$HIVE_HOME/conf:$HIVE_HOME/lib/*:$HCAT_HOME/share/hcatalog/hive-hcatalog-core-2.3.4.jar #变量名小写
:wq保存退出,并输入source /etc/profile使环境变量生效
5. 配置kylin
5.1 配置$KYLIN_HOME/bin/kylin.sh
- vim $KYLIN_HOME/bin/kylin.sh
在文件开头添加
- export HBASE_CLASSPATH_PREFIX=${tomcat_root}/bin/bootstrap.jar:${tomcat_root}/bin/tomcat-juli.jar:${tomcat_root}/lib/*:$hive_dependency:$HBASE_CLASSPATH_PREFIX
这么做的目的是为了加入$hive_dependency环境,解决后续的两个问题,都是没有hive依赖的原因:
a) kylinweb界面load hive表会失败
b) cube build的第二步会报org/apache/Hadoop/hive/conf/hiveConf的错误。
5.2 hadoop压缩配置
关于snappy压缩支持问题,如果支持需要事先重新编译Hadoop源码,使得native库支持snappy.使用snappy能够实现一个适合的压缩比,使得这个运算的中间结果和最终结果都能占用较小的存储空间
本例的hadoop不支持snappy压缩,这个会导致后续cube build报错。
- vim $KYLIN_HOME/conf/Kylin_job_conf.xml
修改配置文件,将配置项mapreduce.map.output.compress,mapreduce.output.fileoutputformat.compress修改为false
- <property>
- <name>mapreduce.map.output.compress</name>
- <value>false</value>
- <description>Compress map outputs</description>
- </property>
- <property>
- <name>mapreduce.output.fileoutputformat.compress</name>
- <value>false</value>
- <description>Compress the output of a MapReduce job</description>
- </property>
还有一个关于压缩的地方需要修改
- vim $KYLIN_HOME/conf/kylin.properties
将kylin.hbase.default.compression.codec设置为none或者注释掉
- #kylin.storage.hbase.compression-codec=none
5.3 主配置$KYLIN_HOME/conf/kylin.properties
- vim $KYLIN_HOME/conf/kylin.properties
修改为:
- ## The metadata store in hbase
- ##hbase上存储kylin元数据
- kylin.metadata.url=kylin_metadata@hbase
- ## metadata cache sync retry times
- ##元数据同步重试次数
- kylin.metadata.sync-retries=
- ## Working folder in HDFS, better be qualified absolute path, make sure user has the right permission to this directory
- ##hdfs上kylin工作目录
- kylin.env.hdfs-working-dir=/kylin
- ## kylin zk base path
- kylin.env.zookeeper-base-path=/kylin
- ## DEV|QA|PROD. DEV will turn on some dev features, QA and PROD has no difference in terms of functions.
- #kylin.env=DEV
- ## Kylin server mode, valid value [all, query, job]
- ##kylin主节点模式,从节点的模式为query,只有这一点不一样
- kylin.server.mode=all
- ## List of web servers in use, this enables one web server instance to sync up with other servers.
- ##集群的信息同步
- kylin.server.cluster-servers=192.168.1.131:,192.168.1.193:,192.168.1.194:
- ## Display timezone on UI,format like[GMT+N or GMT-N]
- ##改为中国时间
- kylin.web.timezone=GMT+
- ## Timeout value for the queries submitted through the Web UI, in milliseconds
- ##web查询超时时间(毫秒)
- kylin.web.query-timeout=
- ## Max count of concurrent jobs running
- ##可并发执行的job数量
- kylin.job.max-concurrent-jobs=
- #### ENGINE ###
- ## Time interval to check hadoop job status
- ##检查hdfs job的时间间隔(秒)
- kylin.engine.mr.yarn-check-interval-seconds=
- ## Hive database name for putting the intermediate flat tables
- ##build cube 产生的Hive中间表存放的数据库
- kylin.source.hive.database-for-flat-table=kylin_flat_db
- ## The percentage of the sampling, default %
- kylin.job.cubing.inmem.sampling.percent=
- ## Max job retry on error, default : no retry
- kylin.job.retry=
- ## Compression codec for htable, valid value [none, snappy, lzo, gzip, lz4]
- ##不采用压缩
- kylin.storage.hbase.compression-codec=none
- ## The cut size for hbase region, in GB.
- kylin.storage.hbase.region-cut-gb=
- ## The hfile size of GB, smaller hfile leading to the converting hfile MR has more reducers and be faster.
- ## Set to disable this optimization.
- kylin.storage.hbase.hfile-size-gb=
- ## The storage for final cube file in hbase
- kylin.storage.url=hbase
- ## The prefix of hbase table
- kylin.storage.hbase.table-name-prefix=KYLIN_
- ## The namespace for hbase storage
- kylin.storage.hbase.namespace=default
- ###定义kylin用于MR jobs的job.jar包和hbase的协处理jar包,用于提升性能(添加项)
- kylin.job.jar=/usr/local/kylin/apache-kylin-2.6./lib/kylin-job-2.6..jar
- kylin.coprocessor.local.jar=/usr/local/kylin/apache-kylin-2.6./lib/kylin-coprocessor-2.6..jar
5.4 将配置好的kylin复制到其他两台机器上去
- scp -r /usr/local/kylin/ 192.168.1.102:/usr/local
- scp -r /usr/local/kylin/ 192.168.1.103:/usr/local
5.5 将192.168.1.102,192.168.1.103上的kylin.server.mode改为query
- vim $KYLIN_HOME/conf/kylin.properties
修改项为
- kylin.server.mode=query ###kylin主节点模式,从节点的模式为query,只有这一点不一样
6. 启动kylin
6.1 前提条件:依赖服务先启动
a) 启动zookeeper,所有节点运行
- $ZOO_KEEPER_HOME/bin/zkServer.sh start
b) 启动hadoop,主节点运行
- $HADOOP_HOME/bin/start-all.sh
c) 启动JobHistoryserver服务,master主节点启动.
- $HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver
d) 启动hivemetastore服务
- nohup $HIVE_HOME/bin/hive --service metastore /dev/null >& &
e) 启动hbase集群,主节点启动
- $HBASE_HOME/bin/start-hbase.sh
启动后的进程为:
192.168.1.101
- [root@palo101 apache-kylin-2.6.]# jps
- NameNode #hdfs NameNode
- NodeManager #yarn NodeManager
- Kafka
- QuorumPeerMain #zookeeper
- Jps
- DataNode #hadoop datanode
- HRegionServer #hbase region server
- HMaster #hbase master
192.168.1.102
- [root@palo102 ~]# jps
- QuorumPeerMain #zookeeper
- NodeManager #yarn NodeManager
- ResourceManager #yarn ResourceManager
- Jps
- HRegionServer #hbase region server
- Kafka
- SecondaryNameNode #hdfs SecondaryNameNode
- DataNode #hadoop datanode
192.168.1.103
- [root@palo103 ~]# jps
- RunJar #hive metastore
- NodeManager #yarn NodeManager
- HRegionServer #hbase region server
- QuorumPeerMain #zookeeper
- ManagerBootStrap
- Kafka
- RunJar #hive thrift server
- DataNode #hadoop datanode
- Jps
6.2 检查配置是否正确
- $KYLIN_HOME/bin/check-env.sh
- [root@palo101 bin]# $KYLIN_HOME/bin/check-env.sh
- Retrieving hadoop conf dir...
- KYLIN_HOME is set to /usr/local/kylin/apache-kylin-2.6.
- SLF4J: Class path contains multiple SLF4J bindings.
- SLF4J: Found binding in [jar:file:/usr/local/hadoop-2.7./share/hadoop/common/lib/slf4j-log4j12-1.7..jar!/org/slf4j/impl/StaticLoggerBinder.class]
- SLF4J: Found binding in [jar:file:/usr/local/apache-hive-2.3.-bin/lib/log4j-slf4j-impl-2.6..jar!/org/slf4j/impl/StaticLoggerBinder.class]
- SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
- SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
- SLF4J: Class path contains multiple SLF4J bindings.
- SLF4J: Found binding in [jar:file:/usr/local/hadoop-2.7./share/hadoop/common/lib/slf4j-log4j12-1.7..jar!/org/slf4j/impl/StaticLoggerBinder.class]
- SLF4J: Found binding in [jar:file:/usr/local/apache-hive-2.3.-bin/lib/log4j-slf4j-impl-2.6..jar!/org/slf4j/impl/StaticLoggerBinder.class]
- SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
- SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
- SLF4J: Class path contains multiple SLF4J bindings.
- SLF4J: Found binding in [jar:file:/usr/local/hadoop-2.7./share/hadoop/common/lib/slf4j-log4j12-1.7..jar!/org/slf4j/impl/StaticLoggerBinder.class]
- SLF4J: Found binding in [jar:file:/usr/local/apache-hive-2.3.-bin/lib/log4j-slf4j-impl-2.6..jar!/org/slf4j/impl/StaticLoggerBinder.class]
- SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
- SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
hive依赖检查find-hive-dependency.sh
hbase依赖检查find-hbase-dependency.sh
所有的依赖检查可吃用check-env.sh
6.3 所有节点运行下面命令来启动kylin
- $KYLIN_HOME/bin/kylin.sh start
启动时如果出现下面的错误
Failed to find metadata store by url: kylin_metadata@hbase
解决办法 为:
1)将$HBASE_HOME/conf/hbase-site.html的属性hbase.rootdir改成与$HADOOP_HOME/etc/hadoop/core-site.xml中的属性fs.defaultFS一致
2)进入zk的bin的zkCli,将/hbase删除,然后重启hbase可以解决
6.4 登录kylin
http://192.168.1.101:7070/kylin, 其他几台也可以登录,只要切换相应的ip即可
默认登录名密码为:admin/KYLIN

登录后的主页面为:

7 FAQ
7.1 如果遇到类似下面的错误
WARNING: Failed to process JAR
[jar:file:/home/hadoop-2.7.3/contrib/capacity-scheduler/.jar!/] for
这个问题只是一些小bug问题把这个脚本的内容改动一下就好了${HADOOP_HOME}/etc/hadoop/hadoop-env.sh,把下面的这一段循环语句给注释掉
- vim ${HADOOP_HOME}/etc/hadoop/hadoop-env.sh
- #for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do
- # if [ "$HADOOP_CLASSPATH" ]; then
- # export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f
- # else
- # export HADOOP_CLASSPATH=$f
- # fi
- #done
7.2 如果遇到Caused by: java.lang.ClassCastException: com.fasterxml.jackson.datatype.joda.JodaModule cannot be cast to com.fasterxml.jackson.databind.Module的错误
产生这个问题的原因是hive使用的jackson-datatype-joda-2.4.6.jar,而kylin使用的是jackson-databind-2.9.5.jar,jar包版本不一致造成的。
hive:

kylin:
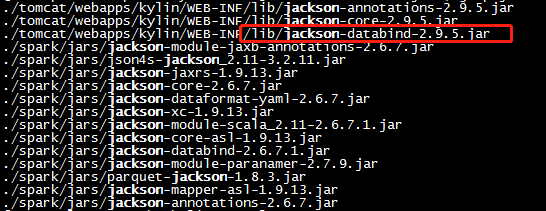
解决办法为:
- mv $HIVE_HOME/lib/jackson-datatype-joda-2.4..jar $HIVE_HOME/lib/jackson-datatype-joda-2.4..jarback
即不使用hive的这个jar包,详情请参见https://issues.apache.org/jira/browse/KYLIN-3129
7.3 如果遇到Failed to load keystore type JKS with path conf/.keystore due to (No such file or directory)
解决办法为:
打开apache-kylin-2.6.0/tomcat/conf/server.xml文件,把其中的https的配置删除掉(或者注释掉)
- <!--
- <Connector port="7443" protocol="org.apache.coyote.http11.Http11Protocol"
- maxThreads="150" SSLEnabled="true" scheme="https" secure="true"
- keystoreFile="conf/.keystore" keystorePass="changeit"
- clientAuth="false" sslProtocol="TLS" />
- -->
8. 简单使用入门
8.1 执行官方发布的样例数据
- $KYLIN_HOME/bin/sample.sh
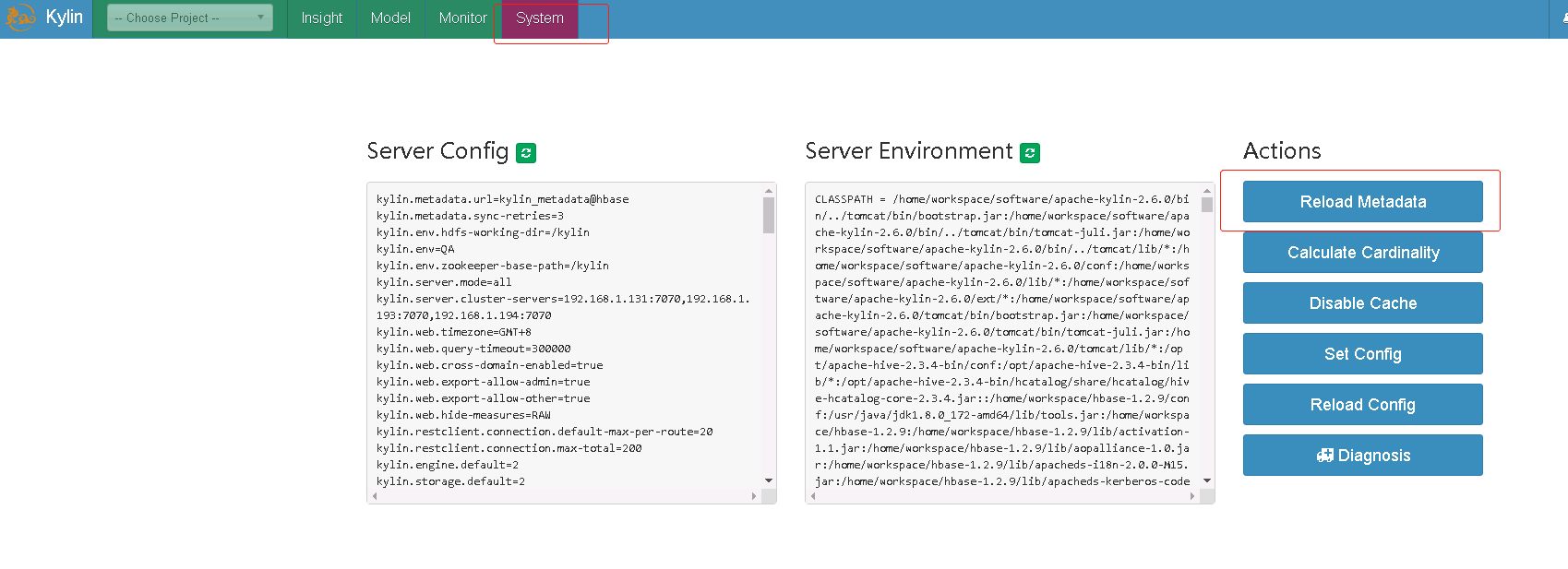
如果出现Restart Kylin Server or click Web UI => System Tab => Reload Metadata to take effect,就说明示例cube创建成功了,如图:

8.2 重启kylin或者重新加载元数据让数据生效
本例中选择重新加载元数据,操作如图所示
8.3 进入hive,查看kylin cube表结构
- $HIVE_HOME/bin/hive #进入hive shell客户端
- hive>show databases; #查询hive中数据库列表
- hive>use kylin_flat_db; #切换到kylin的hive数据库
- hive>show tables; #查询kylin hive数据库中的所有表
输入如下:
- [druid@palo101 kafka_2.-2.1.]$ $HIVE_HOME/bin/hive
- SLF4J: Class path contains multiple SLF4J bindings.
- SLF4J: Found binding in [jar:file:/home/workspace/apache-hive-2.3.-bin/lib/log4j-slf4j-impl-2.6..jar!/org/slf4j/impl/StaticLoggerBinder.class]
- SLF4J: Found binding in [jar:file:/home/workspace/hadoop-2.7./share/hadoop/common/lib/slf4j-log4j12-1.7..jar!/org/slf4j/impl/StaticLoggerBinder.class]
- SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
- SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
- Logging initialized using configuration in file:/home/workspace/apache-hive-2.3.-bin/conf/hive-log4j2.properties Async: true
- Hive-on-MR is deprecated in Hive and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive .X releases.
- hive> show databases;
- OK
- default
- dw_sales
- kylin_flat_db
- ods_sales
- Time taken: 1.609 seconds, Fetched: row(s)
- hive> use kylin_flat_db;
- OK
- Time taken: 0.036 seconds
- hive> show tables;
- OK
- kylin_account
- kylin_cal_dt
- kylin_category_groupings
- kylin_country
- kylin_sales
- Time taken: 0.321 seconds, Fetched: row(s)
- hive>
再来看hbase
- [druid@palo101 kafka_2.-2.1.]$ hbase shell
- SLF4J: Class path contains multiple SLF4J bindings.
- SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
- SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
- HBase Shell; enter 'help<RETURN>' for list of supported commands.
- Type "exit<RETURN>" to leave the HBase Shell
- Version 1.3., rfd0d55b1e5ef54eb9bf60cce1f0a8e4c1da073ef, Sat Nov :: CST
- hbase(main)::> list
- TABLE
- dev
- kylin_metadata
- test
- row(s) in 0.3180 seconds
- => ["dev", "kylin_metadata", "test"]
hbase中多了个叫kylin_metadata的表,说明使用官方示例数据的cube已经创建成功了!
8.4 构建cube
刷新http://192.168.1.101:7070/kylin,我们发现多了个项目learn_kylin
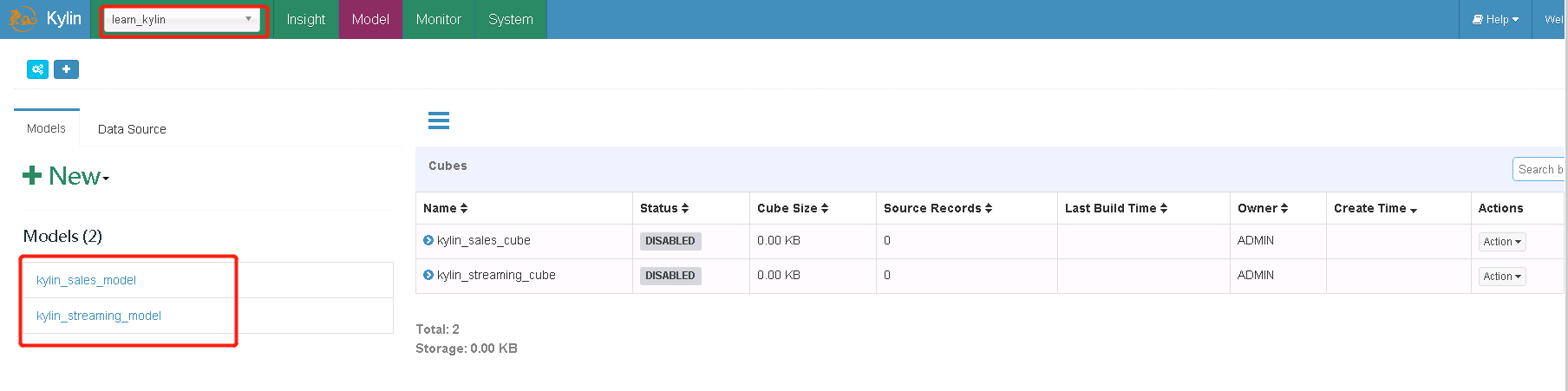
选择kylin_sales_model,进行构建
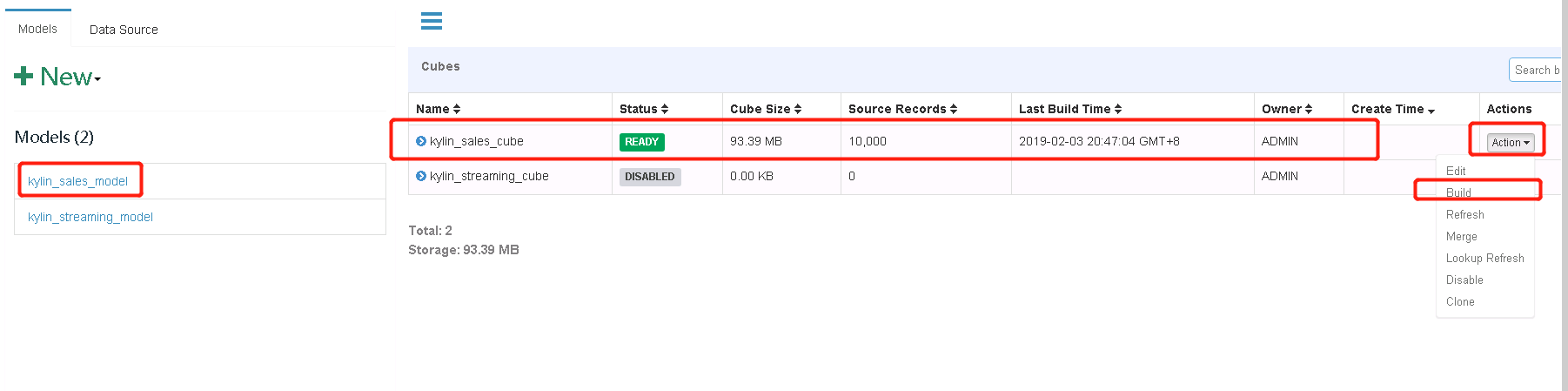
可以在monitor里查看构建的进度

Build成功之后model里面会出现storage信息,之前是没有的,可以到hbase里面去找对应的表,同时cube状态变为ready,表示可查询。

8.5 kylin中进行查询
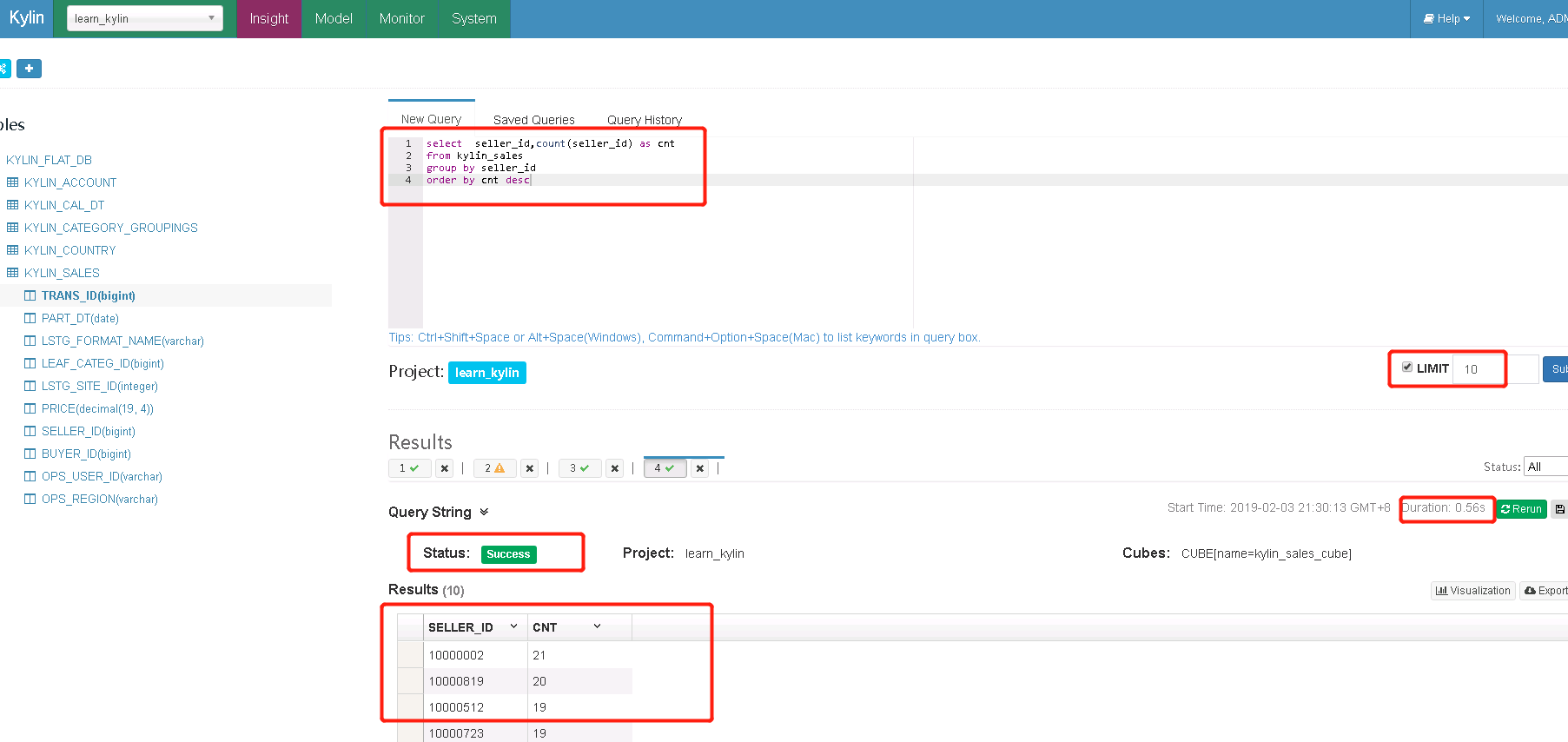
至此,kylin集群部署结束。
CentOS7 安装kylin2.6.0集群的更多相关文章
- Ubuntu12.04-x64编译Hadoop2.2.0和安装Hadoop2.2.0集群
本文Blog地址:http://www.cnblogs.com/fesh/p/3766656.html 本文对Hadoop-2.2.0源码进行重新编译(64位操作系统下不重新编译会有版本问题) ...
- CentOS7搭建Hadoop2.8.0集群及基础操作与测试
环境说明 示例环境 主机名 IP 角色 系统版本 数据目录 Hadoop版本 master 192.168.174.200 nameNode CentOS Linux release 7.4.1708 ...
- CentOS7搭建Hadoop-3.3.0集群手记
前提 这篇文章是基于Linux系统CentOS7搭建Hadoop-3.3.0分布式集群的详细手记. 基本概念 Hadoop中的HDFS和YARN都是主从架构,主从架构会有一主多从和多主多从两种架构,这 ...
- centos 安装 redis3.2.0 集群
这里创建6个redis节点,其中三个为主节点,三个为从节点. redis和端口对应关系: 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 从: 127.0.0 ...
- centos7安装elasticsearch6.3.x集群并破解安装x-pack
一.环境信息及安装前准备 主机角色(内存不要小于1G): 软件及版本(百度网盘链接地址和密码:链接: https://pan.baidu.com/s/17bYc8MRw54GWCQCXR6pKjg 提 ...
- centos7安装zookeeper3.4.12集群
zookeeper的三要素: 1.一致,能够保证数据的一致性 2.有头,始终有一个leader,node/2+1个节点有效,就能正常工作 3.数据树,树状结构且每个树必须有数据 1. 环境准备 操作系 ...
- linux安装spark-2.3.0集群
(安装spark集群的前提是服务器已经配置了jdk并且安装hadoop集群(主要是hdfs)并正常启动,hadoop集群安装可参考<hadoop集群搭建(hdfs)>) 1.配置scala ...
- centos7安装redis3.2.5集群
安装参照 https://blog.csdn.net/mingliangniwo/article/details/54600640 https://blog.csdn.net/u013820 ...
- Centos7 安装部署Kubernetes(k8s)集群
目录 一.系统环境 二.前言 三.Kubernetes 3.1 概述 3.2 Kubernetes 组件 3.2.1 控制平面组件 3.2.2 Node组件 四.安装部署Kubernetes集群 4. ...
随机推荐
- oracle-srvctl-output
############################## [grid@rac01 ~]$ crsctl query crs administratorCRS Administrator List: ...
- 永无BUG
/*************************************************************** * _ooOoo_ * * o8888888o * * 88" ...
- day9大纲
01 作业内容回顾 函数的初识: 封装一个功能. def 函数名(): 函数体 函数的返回值:return 1,结束函数. 2,返回给执行者(函数名())值. return ----> None ...
- “更新时间”字段的:ON UPDATE CURRENT_TIMESTAMP 含义
"更新时间"字段的:ON UPDATE CURRENT_TIMESTAMP 含义: 表示在数据库数据有更新的时候UPDATE_TIME的时间会自动更新(如果数据库数据值没有变化的话 ...
- Elasticsearch(四)优化用户体验
改正用户拼写 Term suggester:词项匹配建议:可以通过wiki的插件来下载wiki上面的单词以及短语,来作为你的拼写提示基础仓库: Phrase suggester:n-gram算法,短语 ...
- IDEA各个版本激活(亲测有效,永久有效)(转)
之前使用的license server 老是失效,今天又失效了,于是乎,在强大的网上找到了永久激活的方式,有个网站专门提供注册码,但是很这激活码有一定的期限,到期之后再获取一次即可,灰常方便. 激活方 ...
- CF 316G3 Good Substrings——广义后缀自动机
题目:http://codeforces.com/contest/316/problem/G3 对询问串和模式串一起建一个后缀自动机,做出在每个串上的 right 集合大小之后枚举自动机上的每个点看看 ...
- 阿里云香港B区通过IPV6规避Google验证码
最近买了阿里云香港B来FQ,然而被Google的验证码折磨的死去活来.四处查询,终于找到了一个合适的方案. 添加IPV6支持 阿里云香港是没有IPV6地址的,需要一个tunnel,这边使用HE.NET ...
- Xshell中vim退出内容仍停留在屏幕的问题
Xshell中vim退出内容仍停留在屏幕的问题 我每次在vim中退出后内容都显示在屏幕上面,看上去特别烦,就在网上看了下,通过调试成功. 第一种方法:在xshell中设置 1.这是我在vim中退出的状 ...
- Python3中Urllib库基本使用
什么是Urllib? Python内置的HTTP请求库 urllib.request 请求模块 urllib.error 异常处理模块 urllib.par ...