【字符串算法2】浅谈Manacher算法
【字符串算法1】 字符串Hash(优雅的暴力)
【字符串算法2】Manacher算法
【字符串算法3】KMP算法
这里将讲述 字符串算法2:Manacher算法
问题:给出字符串S(限制见后)求出最大回文子串长度
Subtask1 对于10%的数据 |S|∈(0,100]
Subtask2 对于30%的数据|S|∈(0,5000]
Subtask3 对于100%的数据|S|∈(0,11000000]
Subtask1(10pts):最朴素的暴力 枚举字符串的所有子串,判断其是否回文,时间复杂度是O(n3)的
Subtask2(30pts):利用回文串的性质: 所有的回文串都是对称的。
长度为奇数回文串以最中间字符的位置为对称轴左右对称,
而长度为偶数的回文串的对称轴在中间两个字符之间的空隙。
可以遍历这些对称轴,
在每个对称轴上同时向左和向右扩展,直到左右两边的字符不同或者到达边界。
时间复杂度O(n2)
Subtask3(100pts):?(当然是Manacher算法囖)O(n)
改进优化 Subtask2(30pts) :
1.麻烦程度(预处理字符串)
在每两个字符中间插入另一个字符,如'#'。
也就是说,原来的字符串是这样的
现在的字符串是这样的(为了不越界以及方便,a[0]设置为‘#’)

那么这个缺点解决了(现在不用分奇数偶数讨论了qwq)
【图是哪里偷过来的,足以说明问题】
2.会出现很多子串被重复多次访问,时间效率大幅降低。
要想降维 O(n)的做法是每一位只扫一次或常数次这里每一位都扫了将近n次
------------------(正文分割线)----------------------
定义几个变量P[i]表示在处理过后的数组中的第i个点最长向左边拓展P[i]个数位都能保证他是回文(右边不记录因为左右对称)
那么p[1]=1,p[2]=2,p[3]=1,p[4]=2,p[5]=1,p[6]=2,p[7]=5,p[8]=2,p[9]=1,p[10]=2,p[11]=1,p[12]=2,p[13]=1;
可以发现所有#的地方大部分都是1
其实上面那句话是错的!!! p[7]=5 ???
重点来了:
P[i]-1代表什么? 原串(不插入#前)中第i位置的回文串长度(包含中间点)
证明:
1、显然L=2*P[i]-1即为新串(加#)中以第i个点为中心最长回文串长度。
2、以第i位 为中心的回文串一定是以#开头和#结尾的,例如“#b#b#”或“#b#a#b#”
所以L减去最前或者最后的‘#’字符就是原串中长度的二倍,即原串长度为(L-1)/2,化简的P[i]-1。
得证。
【再偷2张图片】
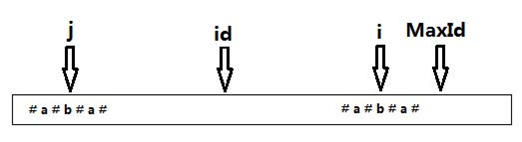
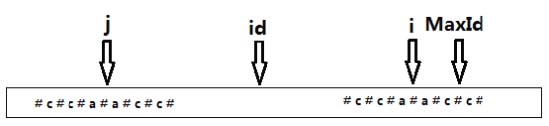
maxId表示前面运行过程中求得最大回文串的最右端
id(后面程序是MID)表示此时最大回文串的对称点,i代表当前遍历到第i个位置
显然我们可以轻易算出i关于id(MID)对称点的坐标j
由id是ij的中点可知 (i+j)/2=id,由此可知 j=2*id-i(所以程序运行的时候就不用记录j了直接用id和i算就行)
运用动态规划的思想在算P[i]的时候P[j] | j∈ [1,i) 都已经算出那么若j为i关于id(MID)的对称点那么P[i]∈ [P[j],+∞)
就是P[i]不可能比P[j]短,为什么呢?
利用回文串的对称性j和i关于id(MID)对称,MaxId和左边MinId(对于id(MID)的对称点)关于id对称
那么j到id回文串半径为P[j],对称过来到id右边i的左边那么回文串半径也为P[j],
而P[i]没有算出来所以就是P[i]不可能比P[j]短 即 P[i]∈ [P[j],+∞)
分类讨论:
若对称过来超过MaxId那么这样的对称是不合法的 P[j]=1从该点老老实实向两边拓展
就是P[j]对称到i的左右,i右端超过MaxId(触及不该触及的地方),就是不合法,因为右边你并不知道
若对称过来没有超过MaxId那么这样的对称是合法的 P[i]=p[j]然后往右拓展
在移动的过程中顺便更新MaxId和P[i]就行
到这里你已经完成了 Subtask3 对于100%的数据|S|<10000000的数据
复杂度证明?
manacher算法只需要线性扫描一遍预处理后的字符串。
对p[]数组的处理 i 为 j 关于 id 的对称点
1. (i<MaxId)
- Maxid-i>p[j] p[j]=p[i]
- 其他情况 p[i]=MaxId-i
2.其他情况 p[i]=0
1. 在i<MaxId的情况下,p的值可以在O(1) 时间内确定
2. 在i>MaxId 的情况下,p的值需要O(n) 的时间内确定,
但是在情况2下,每次扫描都从MaxId开始,且MaxId自身的变化情况是单调递增的,
这样可以保证,字符串中的每个字符最多被访问2次,
所以,该算法的时间复杂度是线性O(n)
只需要弄清楚两点:
1.while()循环本身的时间复杂度在没有前提条件的情况下确实是O(n)
2.但是这里的MaxId,是不断往后走而不可能往前退的,它自身的值的变化是递增的。
那么你可以明白,要进入while循环,
i 的值必然是比MaxId大的,
也就是说整个程序结束为止,
while循环执行的操作数为n次(线性次),
而字符串中的每个字符,最多能被访问到2次。
时间复杂度必然为O(n)
贴下代码:
# include <bits/stdc++.h>
using namespace std;
const int MAXN=*;
char a[*MAXN];
int p[*MAXN];
int main()
{
char ch=getchar();int t=; a[]='?';//为了保险起见a[0]和最后的符号不能一样
while (isalpha(ch)) {
t++;
a[*t]=ch; a[*t-]='#';
ch=getchar();
}
a[*t+]='#';
int n=*t+;
int MID=,R=,i; //MID就是id,R就是MaxId,i就是i
for (i=;i<=n;i++) {
if (R>i) p[i]=min(p[*MID-i],R-i);
else p[i]=;
while (a[i-p[i]]==a[i+p[i]]) p[i]++;
if (i+p[i]>R) R=i+p[i],MID=i;
}
int ans=;
for (int i=;i<=n;i++) ans=max(ans,p[i]-);
printf("%d\n",ans);
return ;
}
这是一道真正的模板题qwq:
P3805 【模板】manacher算法
题目描述
给出一个只由小写英文字符a,b,c...y,z组成的字符串S,求S中最长回文串的长度.
字符串长度为n
输入输出格式
输入格式:
一行小写英文字符a,b,c...y,z组成的字符串S
输出格式:
一个整数表示答案
输入输出样例
aaa
3
说明
字符串长度|S| <= 11000000
这里有着注意点:不能判断回车否则是TLE,应该判断不是字母时果断跳出
【字符串算法2】浅谈Manacher算法的更多相关文章
- 浅谈Manacher算法与扩展KMP之间的联系
首先,在谈到Manacher算法之前,我们先来看一个小问题:给定一个字符串S,求该字符串的最长回文子串的长度.对于该问题的求解.网上解法颇多.时间复杂度也不尽同样,这里列述几种常见的解法. 解法一 ...
- 浅谈Manacher算法
Manacher manacher是一种\(O(n)\)求最长回文子串的算法,俗称马拉车(滑稽) 直接步入正题 首先可以知道的是:每一个回文串都有自己的对称中心,相应的也有自己的最大延伸长度(可以称之 ...
- 浅谈分词算法(3)基于字的分词方法(HMM)
目录 前言 目录 隐马尔可夫模型(Hidden Markov Model,HMM) HMM分词 两个假设 Viterbi算法 代码实现 实现效果 完整代码 参考文献 前言 在浅谈分词算法(1)分词中的 ...
- 浅谈分词算法基于字的分词方法(HMM)
前言 在浅谈分词算法(1)分词中的基本问题我们讨论过基于词典的分词和基于字的分词两大类,在浅谈分词算法(2)基于词典的分词方法文中我们利用n-gram实现了基于词典的分词方法.在(1)中,我们也讨论了 ...
- 浅谈分词算法(5)基于字的分词方法(bi-LSTM)
目录 前言 目录 循环神经网络 基于LSTM的分词 Embedding 数据预处理 模型 如何添加用户词典 前言 很早便规划的浅谈分词算法,总共分为了五个部分,想聊聊自己在各种场景中使用到的分词方法做 ...
- 浅谈分词算法(4)基于字的分词方法(CRF)
目录 前言 目录 条件随机场(conditional random field CRF) 核心点 线性链条件随机场 简化形式 CRF分词 CRF VS HMM 代码实现 训练代码 实验结果 参考文献 ...
- 【字符串算法3】浅谈KMP算法
[字符串算法1] 字符串Hash(优雅的暴力) [字符串算法2]Manacher算法 [字符串算法3]KMP算法 这里将讲述 [字符串算法3]KMP算法 Part1 理解KMP的精髓和思想 其实KM ...
- Manacher算法(马拉车算法)浅谈
什么是Manacher算法? 转载自百度百科 Manachar算法主要是处理字符串中关于回文串的问题的,它可以在 O(n) 的时间处理出以字符串中每一个字符为中心的回文串半径,由于将原字符串处理成两倍 ...
- [随机化算法] 听天由命?浅谈Simulate Anneal模拟退火算法
Simulate Anneal模拟退火算法,是一种用于得到最优解的随机化算法. 如果可以打一手漂亮的随机化搜索,也许当你面对一筹莫展的神仙题时就有一把趁手的兵器了. 这篇题解将教你什么?SA的基本思路 ...
随机推荐
- [Noi2014]购票 BZOJ3672 点分治+斜率优化+CDQ分治
Description 今年夏天,NOI在SZ市迎来了她30周岁的生日.来自全国 n 个城市的OIer们都会从各地出发,到SZ市参加这次盛会.全国的城市构成了一棵以SZ市为根的有根树,每个城市与它的 ...
- Scala--集合
一.主要的集合特质 Seq有先后顺序的序列,如数组列表.IndexedSeq通过下标快速的访问元素.不可变:Vector, Range, List 可变:ArrayBuffer, LinkedList ...
- Swoole Timer 的应用
目录 你好,Swoole Timer 应用场景 参考文档 你好,Swoole PHP 的协程高性能网络通信引擎,使用 C/C++ 语言编写,提供了多种通信协议的网络服务器和客户端模块. Swoole ...
- 20155217《网络对抗》Exp05 MSF基础应用
20155217<网络对抗>Exp05 MSF基础应用 实践内容 本实践目标是掌握metasploit的基本应用方式,重点常用的三种攻击方式的思路.具体需要完成: 一个主动攻击实践,如ms ...
- #20155232《网络对抗》Exp9 Web安全基础
20155232<网络对抗>Exp9 Web安全基础 本实践的目标理解常用网络攻击技术的基本原理.Webgoat实践下相关实验. 实验过程 WebGoat Webgoat是OWASP组织研 ...
- 20155307实验八 《网络对抗》 Web基础
20155307实验八 <网络对抗> Web基础 实验过程 Web前端:HTML 使用netstat -aptn查看80端口是否被占用(上次实验设置为Apache使用80端口),如果被占用 ...
- 《网络对抗》Exp5 MSF基础应用
20155336<网络对抗>Exp5 MSF基础应用 一.基础知识回答 用自己的话解释什么是exploit,payload,encode exploit:渗透攻击的模块合集,将真正要负责攻 ...
- Scracpy爬取图片实例
非常简单,直接上爬虫代码 # -*- coding: utf-8 -*- import scrapy import urllib import logging class TopitComSpider ...
- 计算机基础知识 一 Basic knowledge of computers One
计算机硬件由CPU(Central Processing Unit).存储器.输入设备.输出设备组成. CPU通常由控制单元(控制器)和算数逻辑单元(运算器)组成. 运算器:负责进行算数运算和逻辑运算 ...
- git 和 github 链接
第一步 再电脑上安装git 请自行搜索 到你需要的一个目录下:例如/gittest 首先创建文件,然后 git add 和 git commit 不然直接查看 git branch - ...