Beautiful Soup (一)
一、Beautiful Soup库的理解
1、Beautiful Soup库可以说是对HTML进行解析、遍历、维护“标签树”的功能库
2、pip install bs4
3、from bs4 import BeautifulSoup #beautifulsoup4库使用时是简写的bs4
二、Beautiful Soup类的基本元素
1、Tag——标签,最基本的信息组织单元,分别用<>和</>表明开头和结尾
2、Name——标签的名字,<p>...</p>的名字是'p',格式:<tag>.name
3、Attributes——标签的属性,字典形式组织,格式:<tag>.attrs
4、NavigableString——标签内非属性字符串,<>...</>中的字符串,格式:<tag>.string
5、Comment——标签内字符串的注释部分,一种特殊的Comment类型(尖括号叹号表示注释开始:<!--This is a commet-->)
三、获取标签的方法
1、soup = BeautifulSoup(demo,'html.parser')
2、soup.li.name #a标签的名字
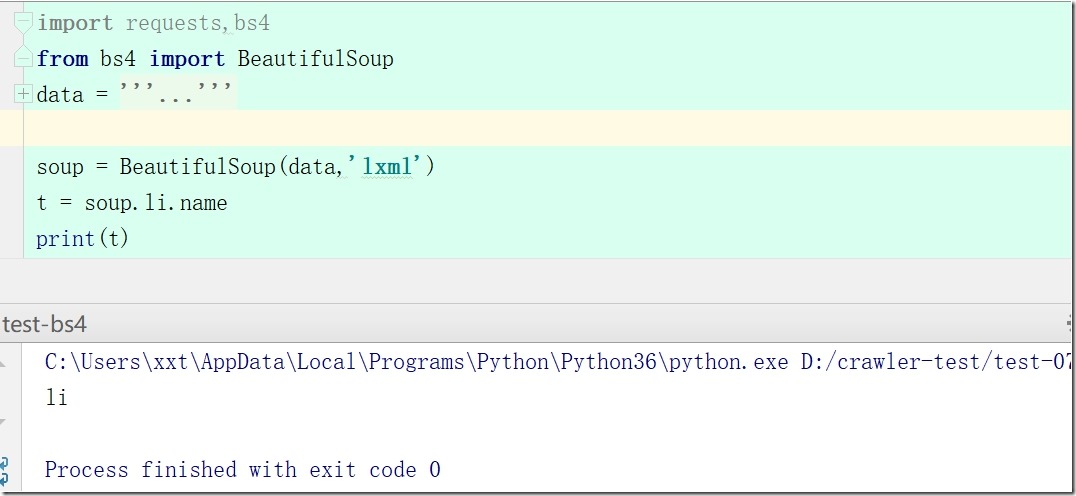
3、soup.li.parent.name #a标签的父标签的名字
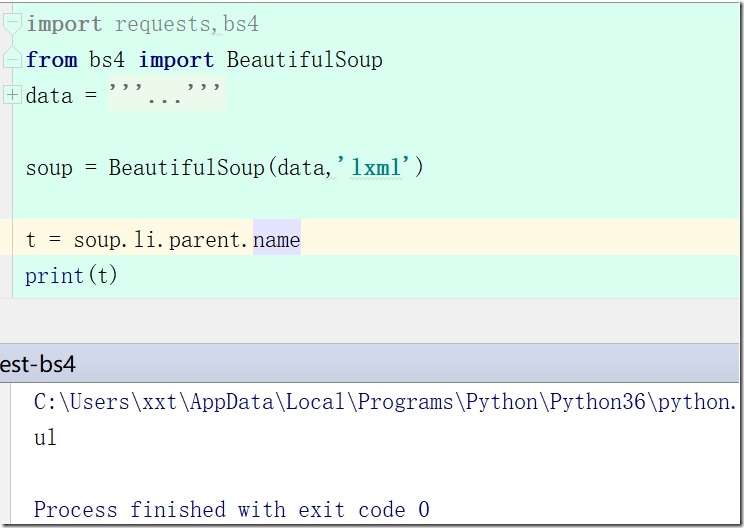
4、soup.li.parent.parent.name #a标签的父标签的父标签名字
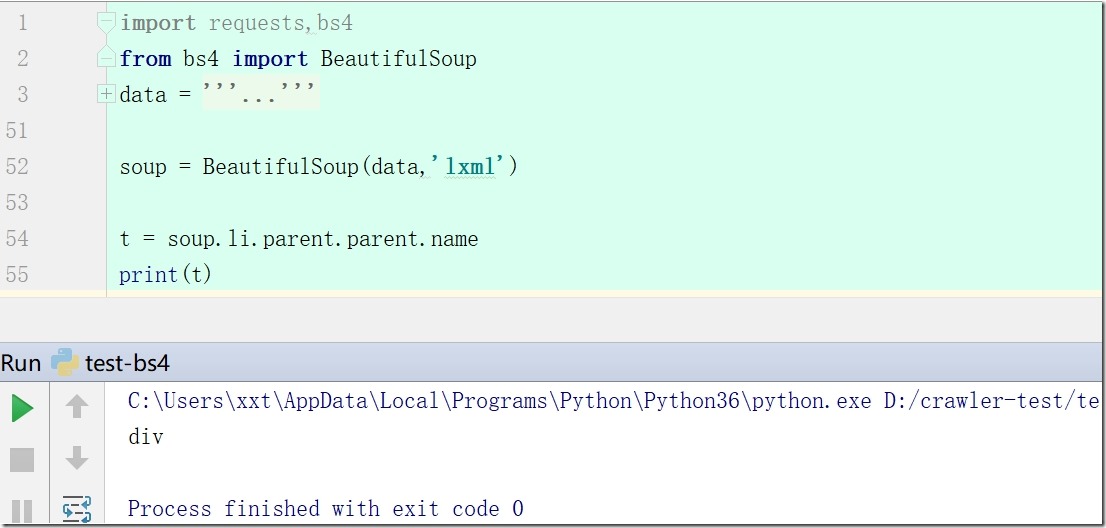
5、t = soup.li #获得第一个a标签
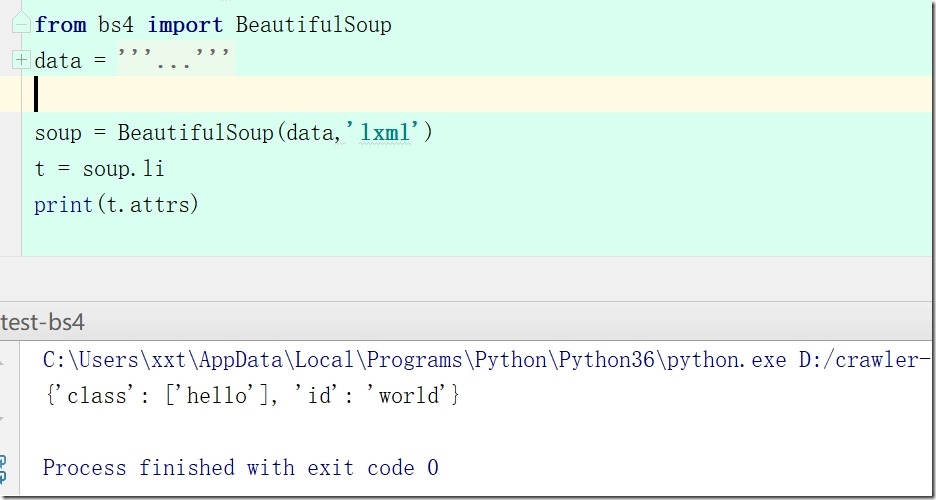
6、t.attrs #a标签的属性
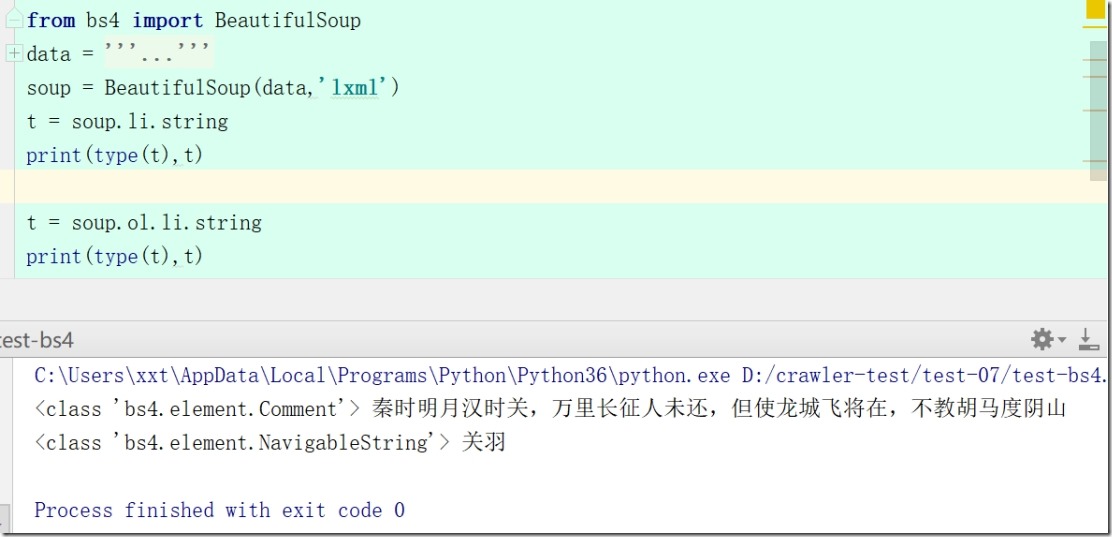
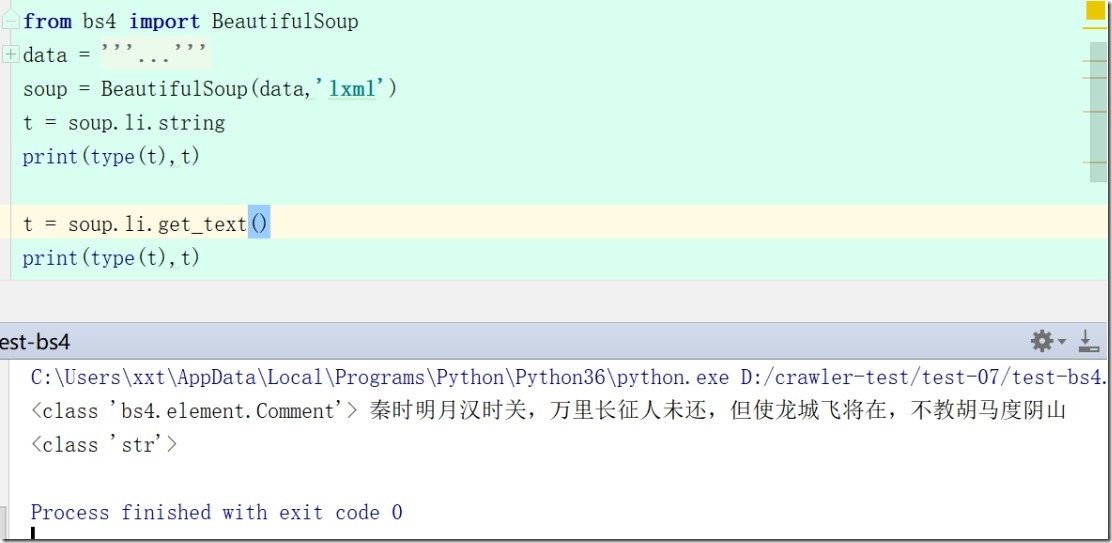
7、soup.li.string #获得a标签内非属性字符串(NavigableString )注意:
soup = BeautifulSoup(data,'lxml')
t = soup.li.string
print(type(t),t)
t = soup.ol.li.string
print(type(t),t)
8、soup.ol.string #也可能是获得Comment标签;可通过类型进行判断
四、使用
数据文件:
data = '''<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>soup测试</title>
<title class="warm">你那温情的一笑,搞得我瑟瑟发抖</title>
</head>
<body>
<div class="tang">
<ul>
<li class="hello" id="world"><a href="http://www.baidu.com" title="出塞"><!--秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山--></a></li>
<list><a href="https://www.baidu.com" title="出塞" style="font-weight: bold"><!--秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山--></a></list>
<li><a href="http://www.163.com" class="taohua" title="huahua">人面不知何处去,桃花依旧笑春风</a></li>
<lists class="hello"><a href="http://mi.com" id="hong" title="huahua">去年今日此门中,人面桃花相映红</a></lists>
<li id="wo"><a href="http://qq.com" name="he" id="gu">故人西辞黄鹤楼,烟花三月下扬州</a></li>
</ul>
<ul>
<li class="hello" id="sf"><a href="http://www.baidu.com" title="出塞"><!--秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山--></a></li>
<list><a href="https://www.baidu.com" title="出塞"><!--秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山--></a></list>
<li><a href="http://www.163.com" class="taohua">人面不知何处去,桃花依旧笑春风</a></li>
<lists class="hello"><a href="http://mi.com" id="fhsf">去年今日此门中,人面桃花相映红,不知桃花何处去,出门依旧笑楚风</a></lists>
<li id="fs"><a href="http://qq.com" name="he" id="gufds">故人西辞黄鹤楼,烟花三月下扬州</a></li>
</ul>
</div>
<div id="meng">
<p class="jiang">
<span>三国猛将</span>
<ol>
<li>关羽</li>
<li>张飞</li>
<li>赵云</li>
<li>马超</li>
<li>黄忠</li>
</ol>
<div class="cao">
<ul>
<li>典韦</li>
<li>许褚</li>
<li>张辽</li>
<li>张郃</li>
<li>于禁</li>
<li>夏侯惇</li>
</ul>
</div>
</p>
</div>
</body>
</html>'''
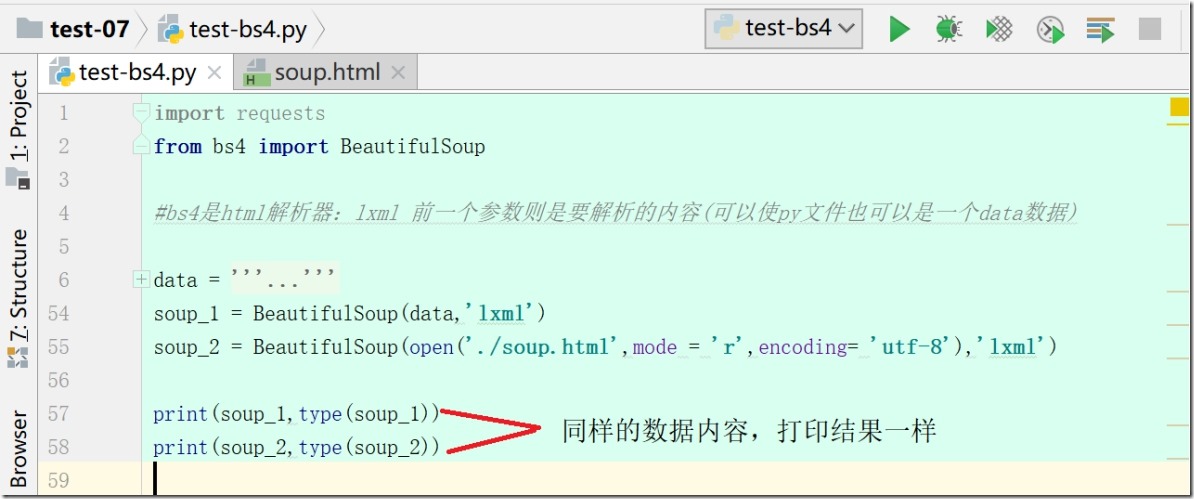
1、第一类对象:BeautifulSoup
2、第二类标签 Tag,只会返回第一个标签里的所有内容
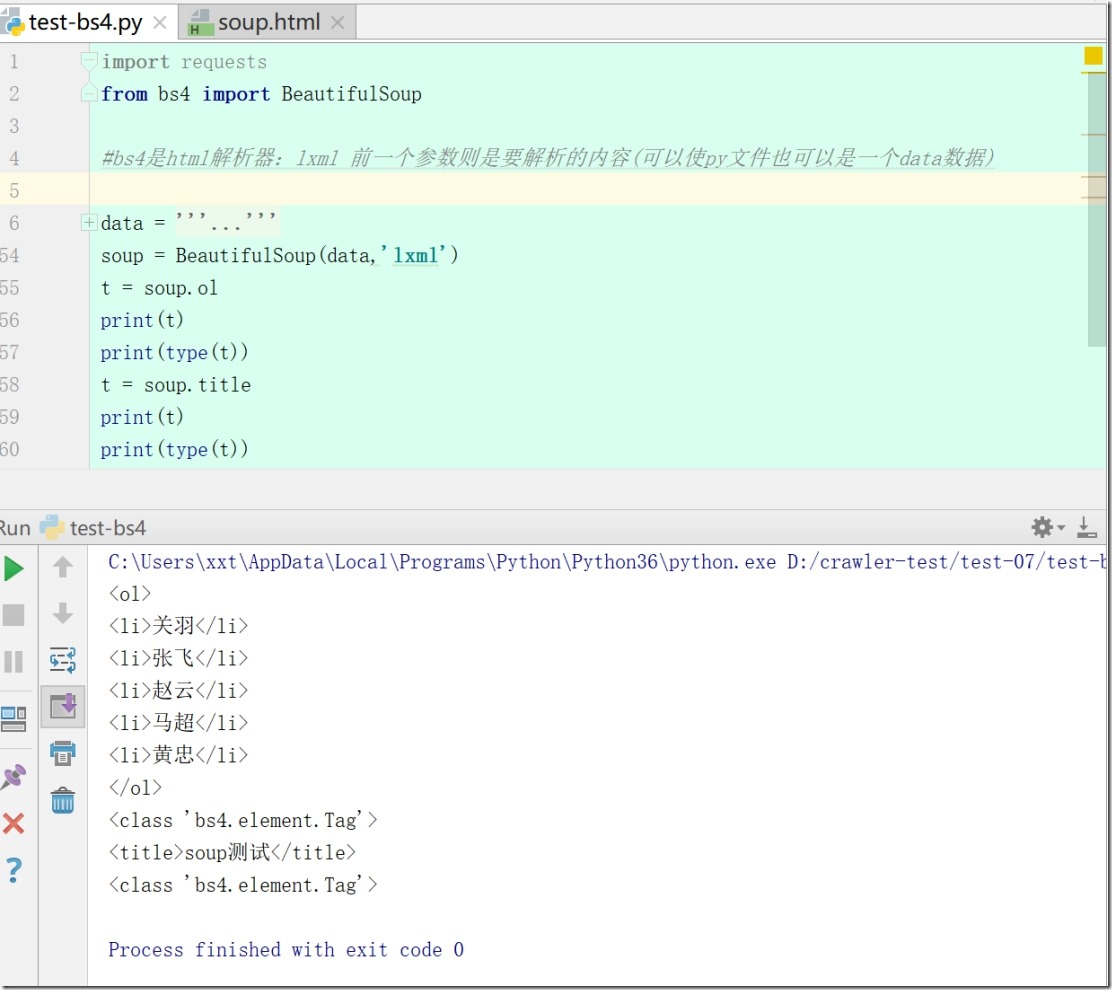
3、第三类数据类型NavigableString
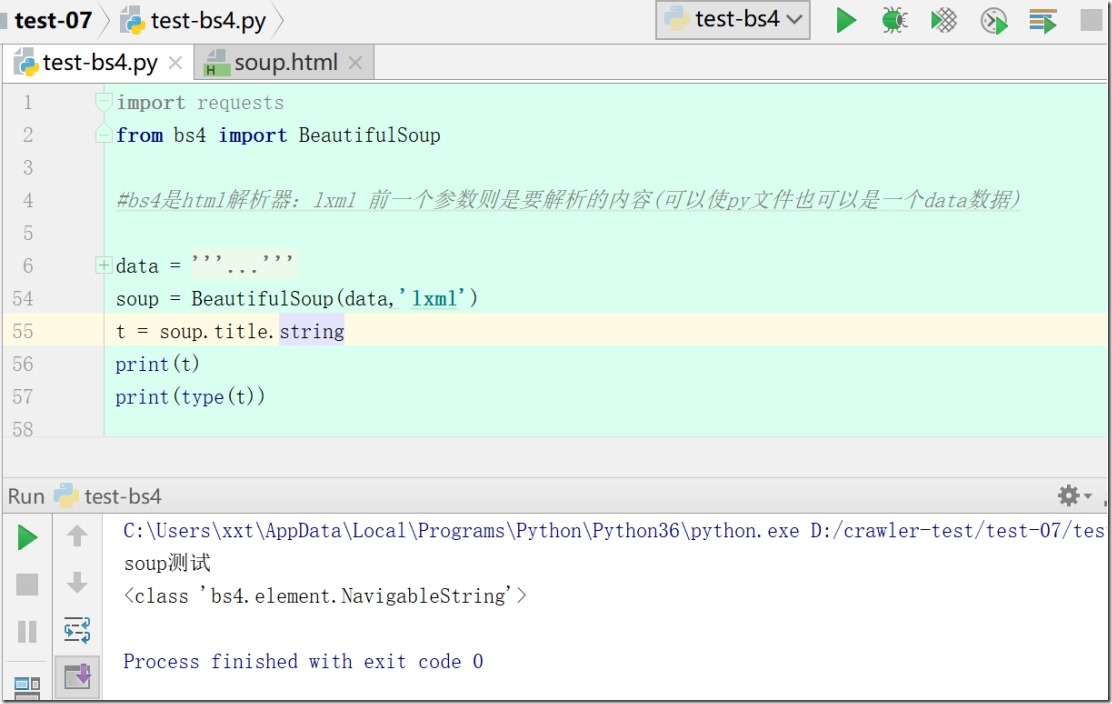
4、第四种,Comment,注释
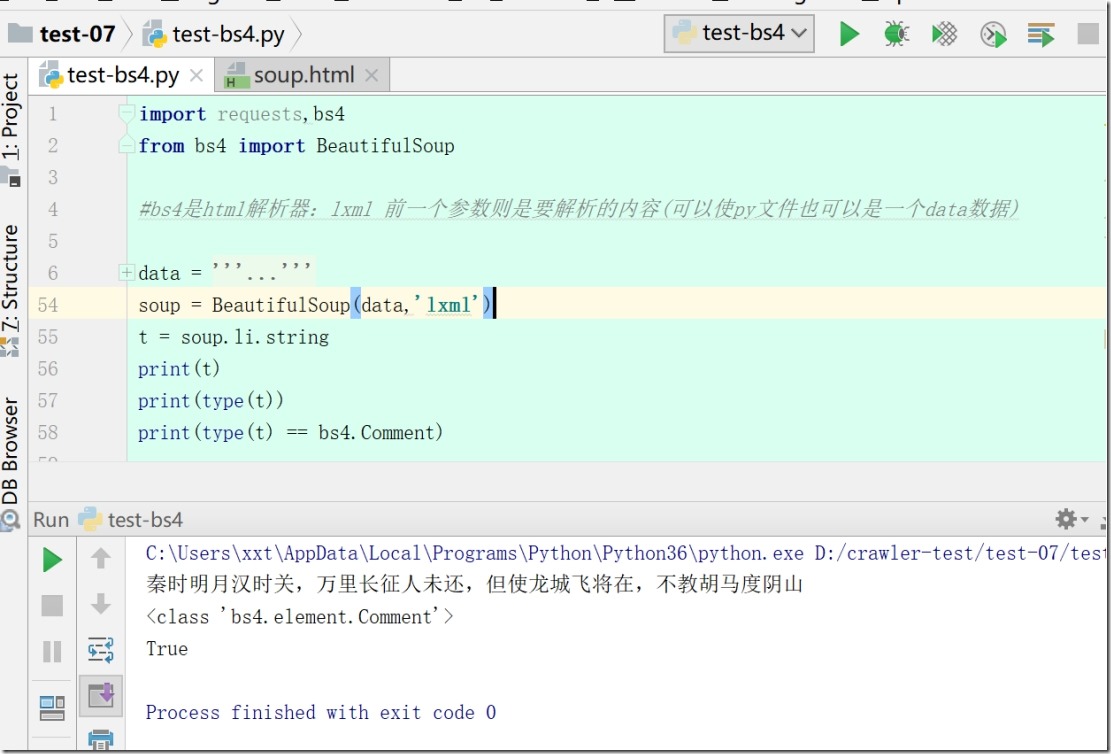
5、遍历(获取子节点)
1)soup = BeautifulSoup(data,'lxml')
t = soup.ul.children
print(t)
for i in t:
print(i)
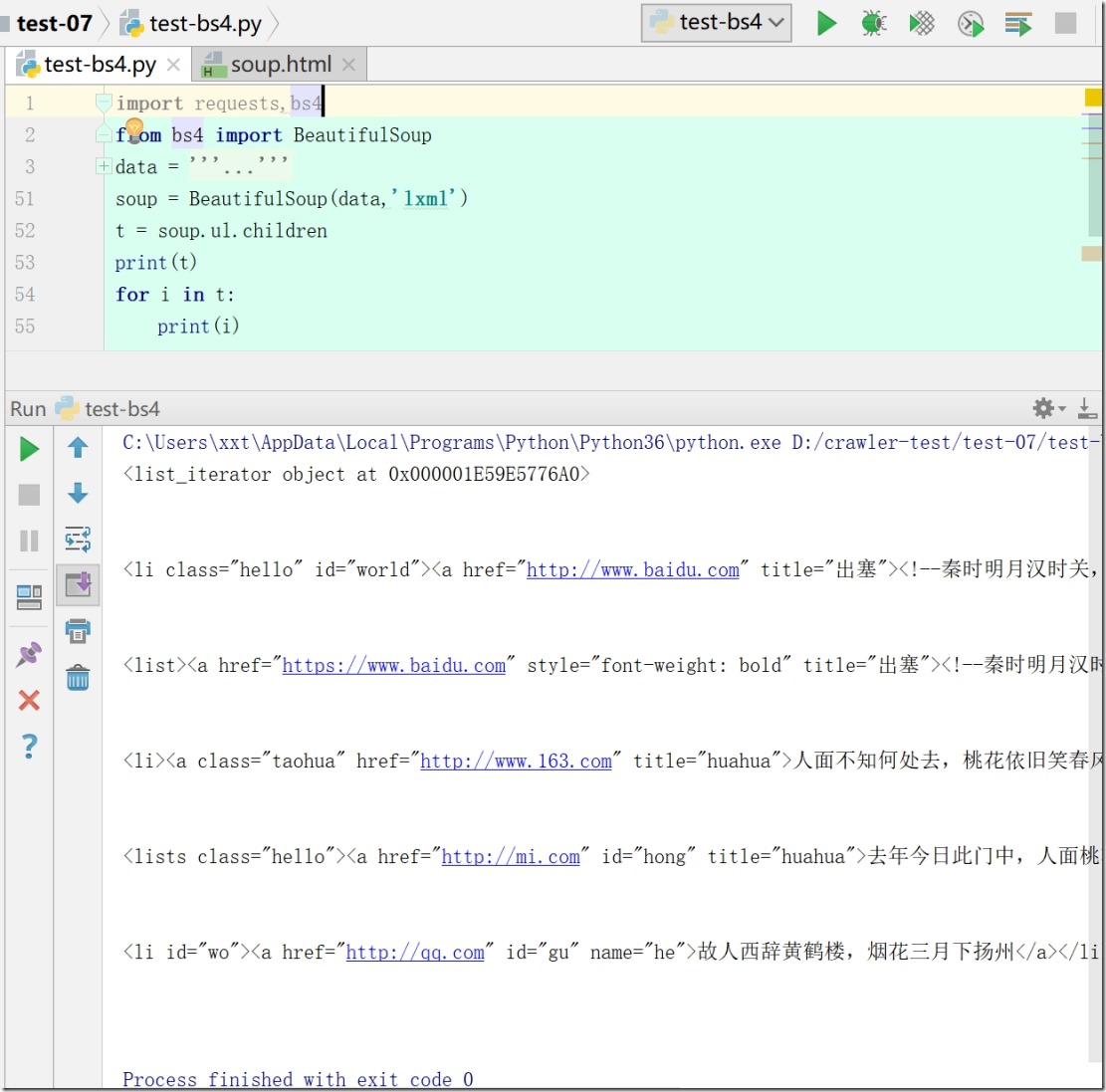
2)print(soup.div.contents)# 返回一个列表
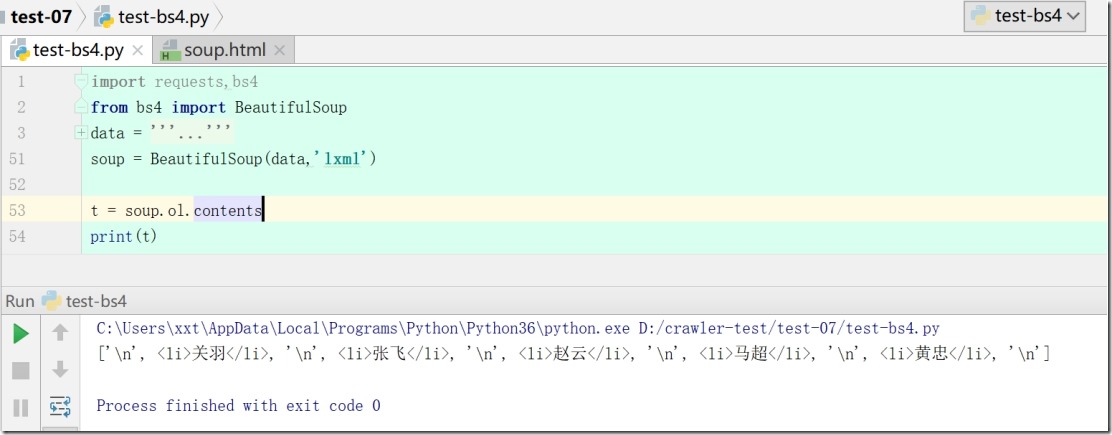
3)print(soup.div.descendants)# 返回的是一个迭代器
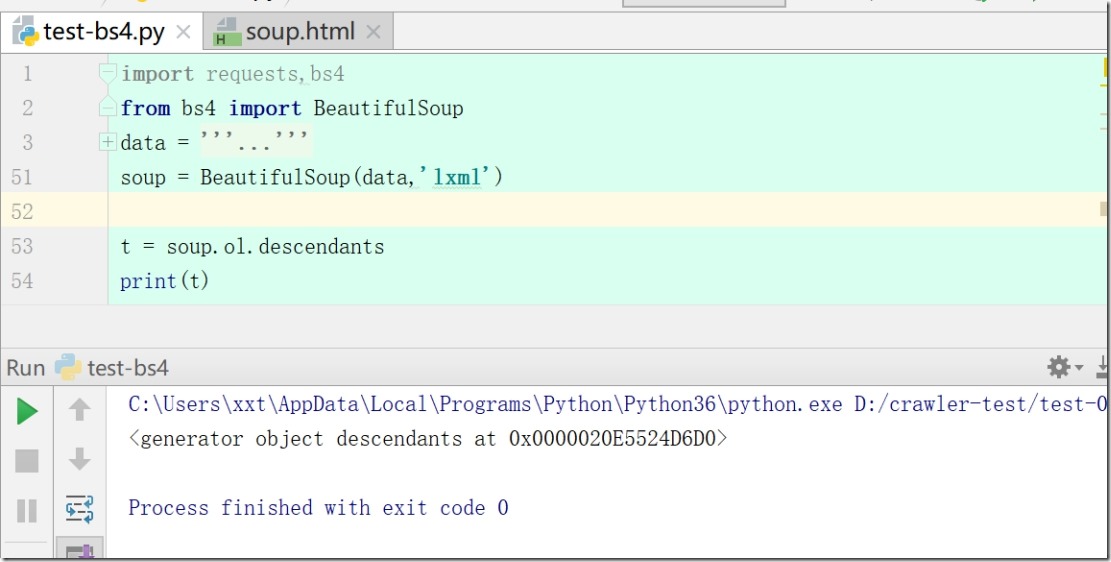
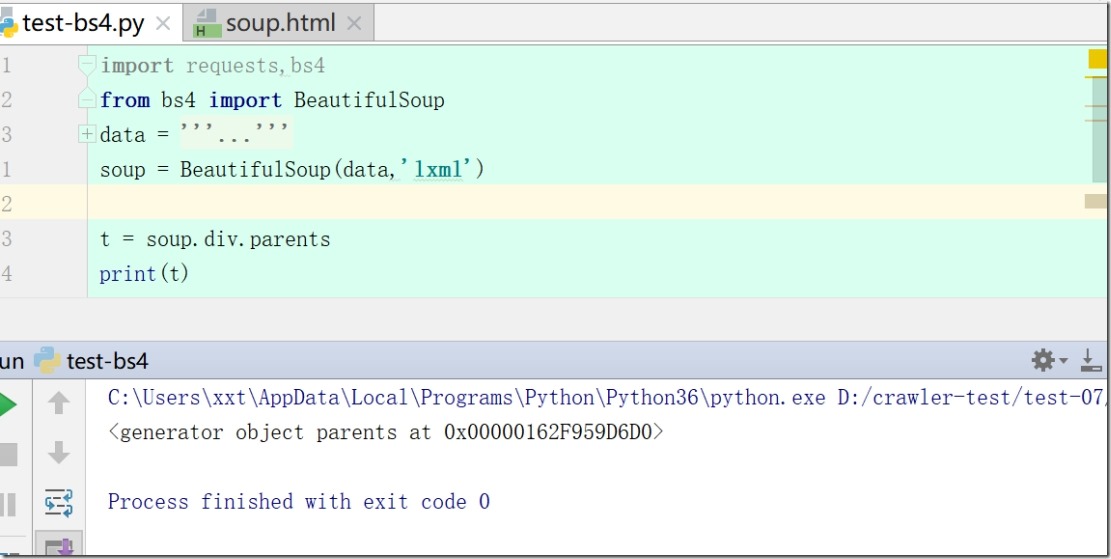
4)print(soup.div.parents)#获取所有的祖先节点
.parent属性是获取父节点,返回来的是整个父节点,里面包含该子节点。.parents就是获取所有的祖先节点,返回的是一个生成器
注:>生成器是只能遍历一次的。
>生成器是一类特殊的迭代器。
6、bs库的更高级的用法(获取任意一个指定属性的标签)
soup.find_all( name , attrs , recursive , text , **kwargs )
name:需要获取的标签名
attrs:接收一个字典,为属性的键值,或者直接用关键字参数来替代也可以,下面
recursive:设置是否搜索直接子节点
text:对应的字符串内容
limit:设置搜索的数量
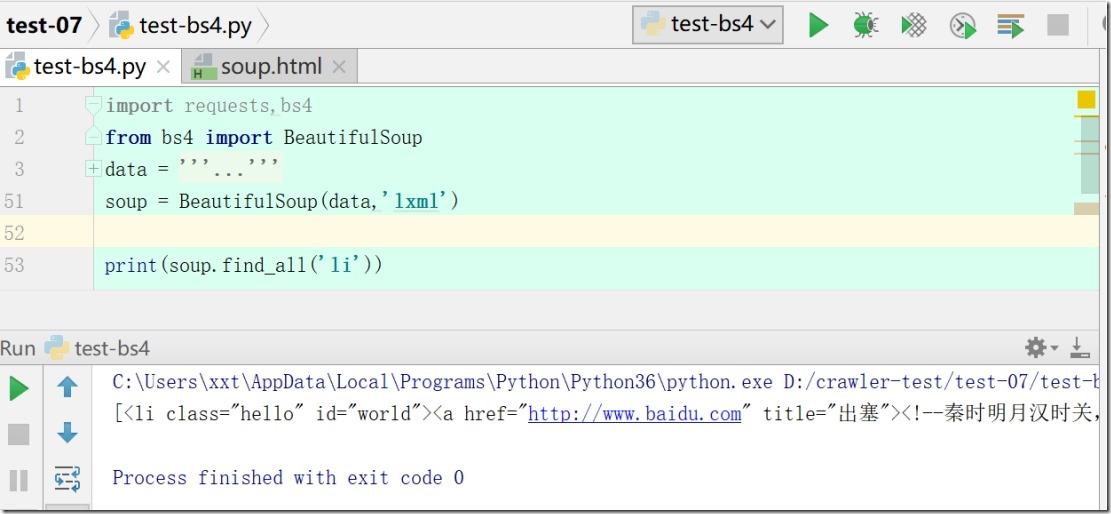
1)先使用name参数来进行搜索(print(soup.find_all('li')))
2) 使用name和attrs参数(print(soup.find_all('div', {'class':'more-meta'})))
注:这个对上个进行了筛选,属性参数填的是一个字典类型的
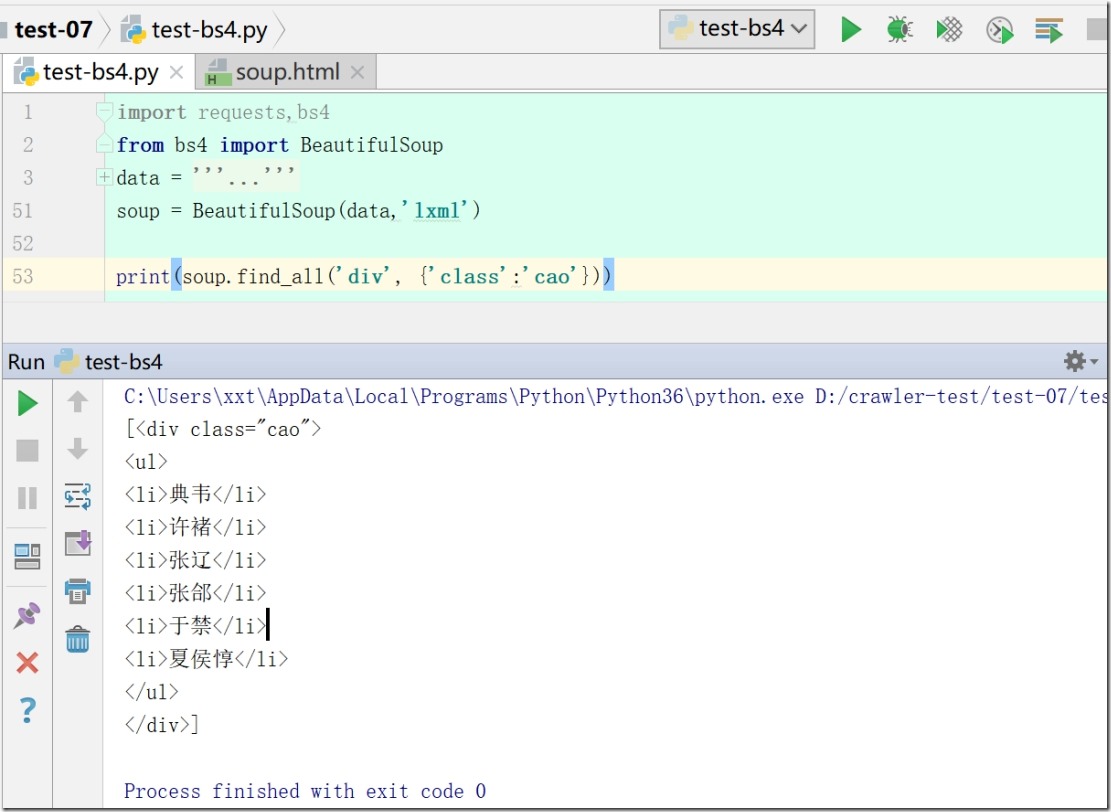
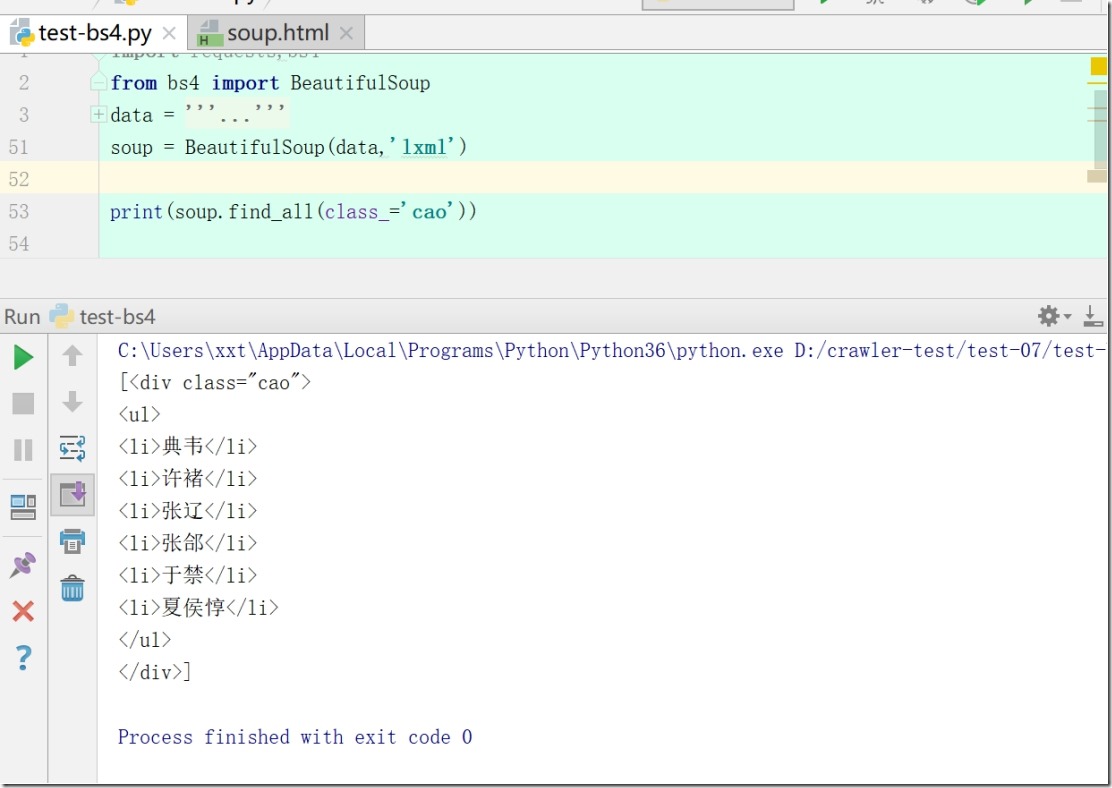
3)根据关键字参数来搜索
print(soup.find_all(class_='cao'))
注:因为class是python关键字,所以关键字参数时需要加多一个下划线来进行区别
4) find()方法
此方法与find_all()方法一样,只不过这个方法只是查找一个标签而已,后者是查找所有符合条件的标签。
5) select()方法
这个方法是使用css选择器来进行筛选标签的。
css选择器:就是根据标签的名字,id和class属性来选择标签。
通过标签名:直接写该标签名,如li a,这个就是找li标签下的a标签
通过class属性:用. 符号加class属性值,如.title .time这个就是找class值为title下的class值为time的标签
通过id属性:用# 加id属性值来进行查找,如#img #width这个就是找id值为img下的id值为width的标签
上面三者可以混合使用,如ul .title #width
6).get_text()方法和前面的.string属性有点不一样哈,这里的他会获取该标签的所有文本内容,不管有没有子标签
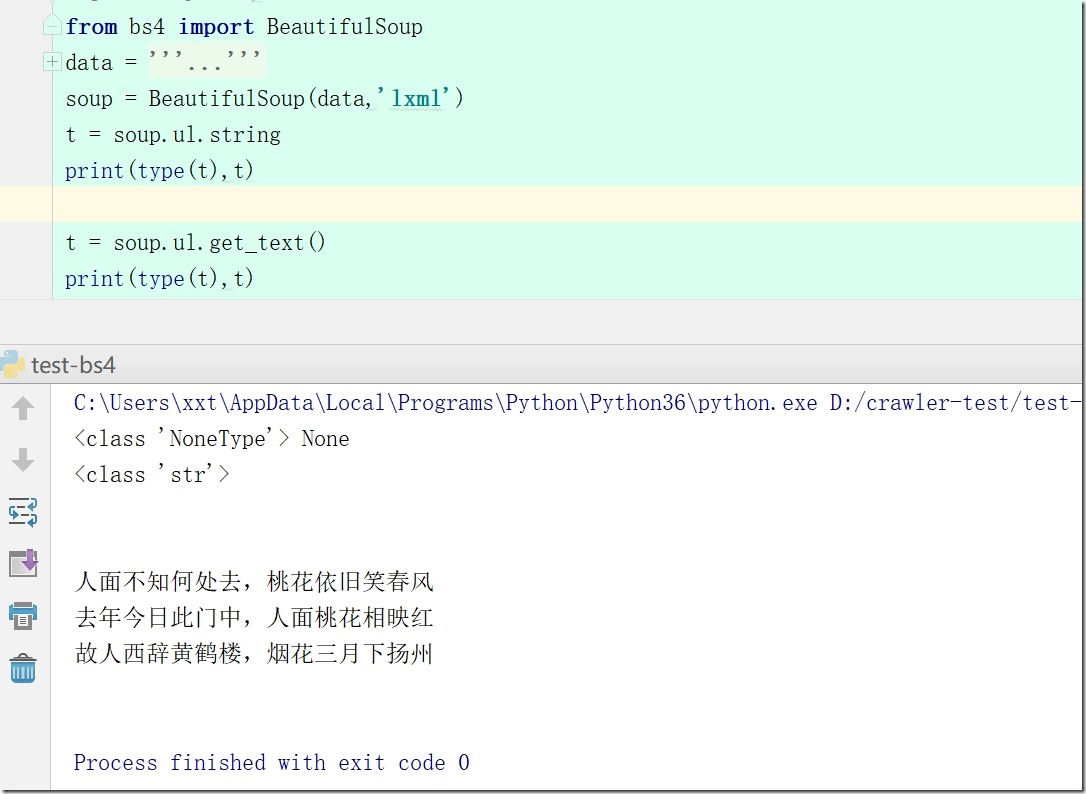
注:.string会把注释也打印出来,若标签没有内容,只有子标签有,就返回None;
.get_text()不打印注释,会把标签本身和子标签内容都打印出来;
7)还可以用标签选择器来进行筛选元素, 返回的都是一个列表
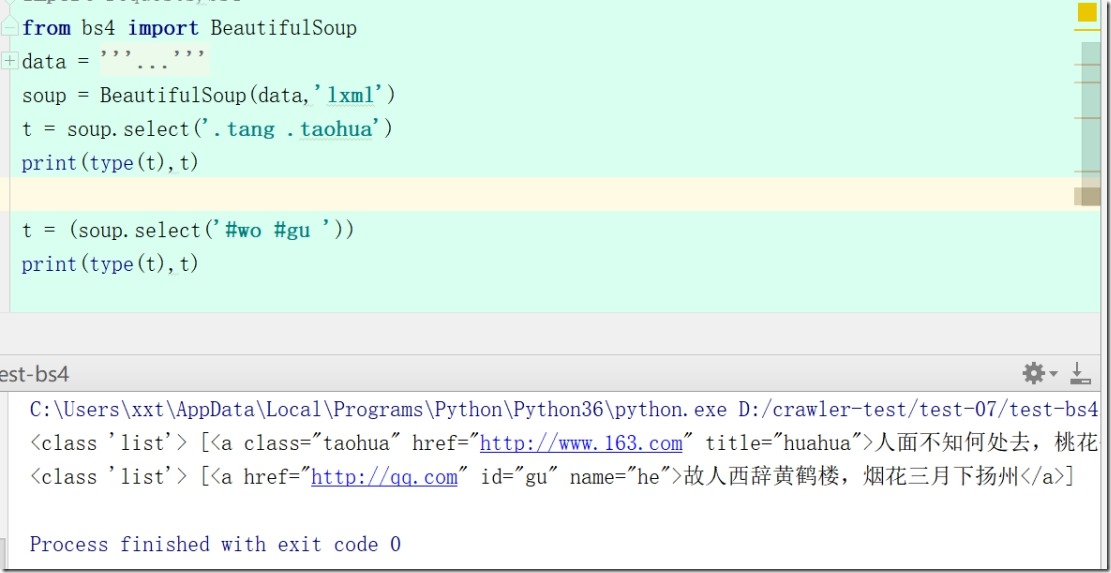
print(soup.select('div ul li'))# 这个是根据标签名进行筛选
print(soup.select('.tang .taohua'))# 这个是根据class来进行筛选
print(soup.select('#wo #gu '))# 这个是根据id来进行筛选
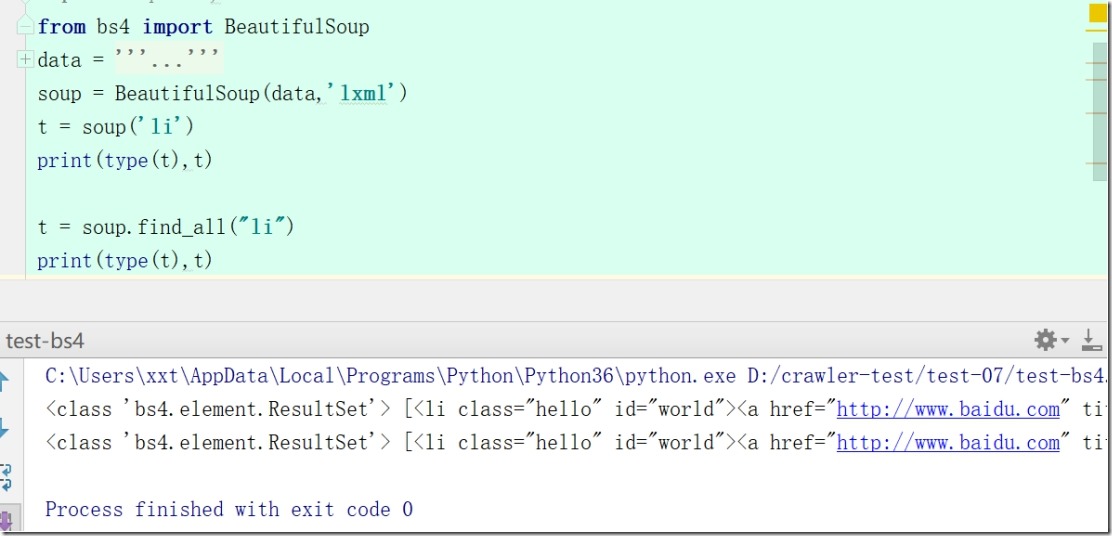
8)等价标签
t = soup('li')
print(type(t),t)
t = soup.find_all("li")
print(type(t),t)
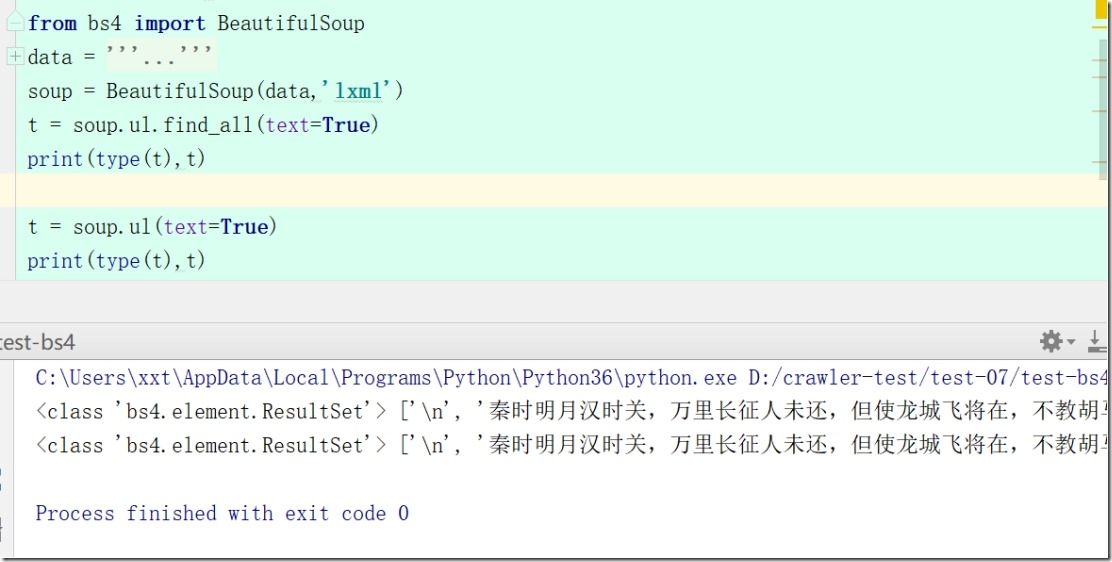
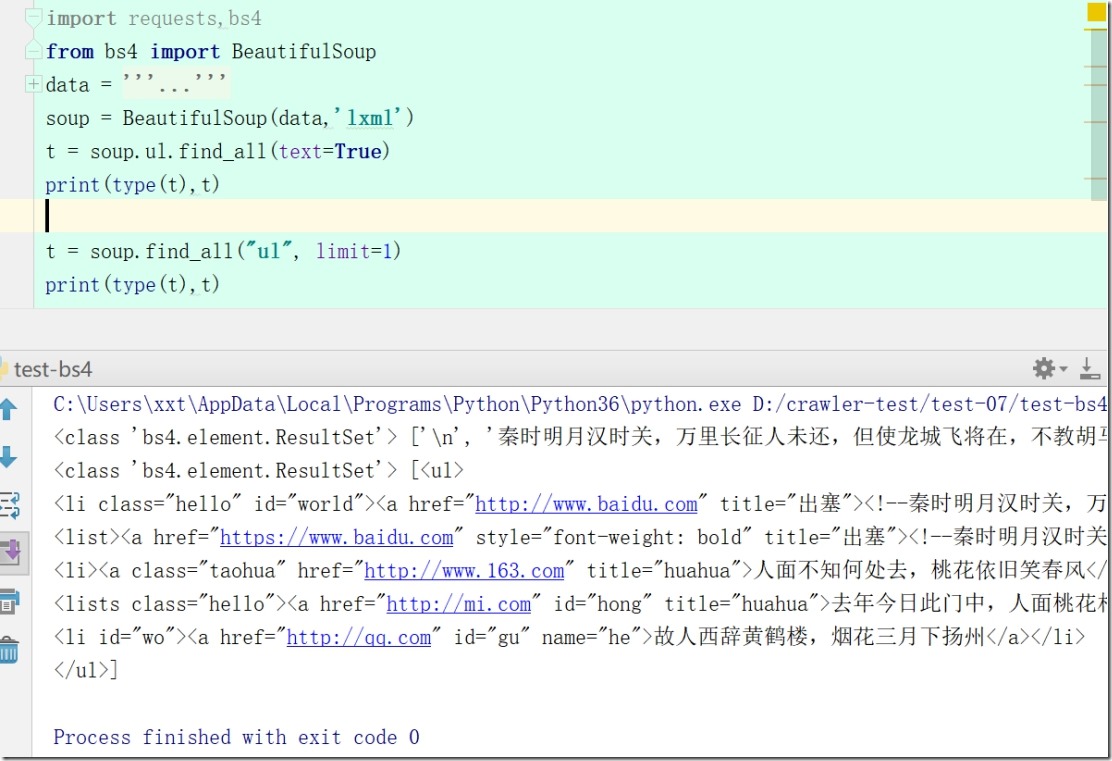
t = soup.ul.find_all(text=True)
print(type(t),t)
t = soup.ul(text=True)
print(type(t),t)
soup.find_all("ul",limit=1)
9)soup.ul.find_all
soup.ul.find_all(text=True) #只有内容的列表
soup.ul.find_all() #带有li标签的列表
soup.find_all("ul", limit=1) #带有ul li list标签的列表,limit限制返回的数量
欢迎关注小婷儿的博客:
csdn:https://blog.csdn.net/u010986753
博客园:http://www.cnblogs.com/xxtalhr/
有问题请在博客下留言或加QQ群:483766429 或联系作者本人 QQ :87605025
OCP培训说明连接:https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接:https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
重要的事说三遍。。。。。。


Beautiful Soup (一)的更多相关文章
- 使用Beautiful Soup编写一个爬虫 系列随笔汇总
这几篇博文只是为了记录学习Beautiful Soup的过程,不仅方便自己以后查看,也许能帮到同样在学习这个技术的朋友.通过学习Beautiful Soup基础知识 完成了一个简单的爬虫服务:从all ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(1): 基础知识Beautiful Soup
开始学习网络数据挖掘方面的知识,首先从Beautiful Soup入手(Beautiful Soup是一个Python库,功能是从HTML和XML中解析数据),打算以三篇博文纪录学习Beautiful ...
- Python爬虫学习(11):Beautiful Soup的使用
之前我们从网页中提取重要信息主要是通过自己编写正则表达式完成的,但是如果你觉得正则表达式很好写的话,那你估计不是地球人了,而且很容易出问题.下边要介绍的Beautiful Soup就可以帮你简化这些操 ...
- 推荐一些python Beautiful Soup学习网址
前言:这几天忙着写分析报告,实在没精力去研究django,虽然抽时间去看了几遍中文文档,还是等实际实践后写几篇操作文章吧! 正文:以下是本人前段时间学习bs4库找的一些网址,在学习的可以参考下,有点多 ...
- 错误 You are trying to run the Python 2 version of Beautiful Soup under Python 3. This will not work
Win 10 下python3.6 使用Beautiful Soup 4错误 You are trying to run the Python 2 version of Beautiful ...
- Python学习笔记之Beautiful Soup
如何在Python3.x中使用Beautiful Soup 1.BeautifulSoup中文文档:http://www.crummy.com/software/BeautifulSoup/bs3/d ...
- Python Beautiful Soup学习之HTML标签补全功能
Beautiful Soup是一个非常流行的Python模块.该模块可以解析网页,并提供定位内容的便捷接口. 使用下面两个命令安装: pip install beautifulsoup4 或者 sud ...
- 转:Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时 ...
- Beautiful Soup教程 转
Python中使用Beautiful Soup库的超详细教程 转 http://www.jb51.net/article/65287.htm 作者:崔庆才 字体:[增加 减小] 类型:转载 时间:20 ...
- Beautiful Soup第三方爬虫插件
什么是BeautifulSoup? Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree). 它提供简单又常用的 ...
随机推荐
- mysql常用语句练习-基于ecshop2.7.3数据库(1)
SELECT * FROM ecs_goods WHERE goods_id = 1;SELECT goods_id, goods_name FROM ecs_goods WHERE goods_id ...
- OSGI企业应用开发(一)OSGI简介
一.OSGI简介 OSGI全称为Open Service Gateway Initiative(开放服务网关规范),有两个层面的含义,一方面它指OSGi Alliance组织:另一方面指该组织制定的一 ...
- hadoop完全分布式的安装
下载地址: centos 7.5 下载地址 清华 http://mirrors.tuna.tsinghua.edu.cn/centos/7/isos/x86_64/CentOS-7-x86_64-DV ...
- CentOS7+ApacheServer2.4+MariaDB10.0+PHP7.0+禅道项目管理软件8.0环境部署
CentOS7+ApacheServer2.4+MariaDB10.0+PHP7.0+禅道项目管理软件8.0环境部署 by:授客 QQ:1033553122 目录 一. 二. 三. 四. 五. 六. ...
- 通过 Cobalt Strike 利用 ms14-068
拓扑图 攻击者(kali) 位于 192.168.245.0/24 网段,域环境位于 192.168.31.0/24 网段. 域中有一台 win7 有两张网卡,可以同时访问两个网段,以这台机器作为跳板 ...
- Android逆向 Android平台虚拟机
一 Dalvik:是Google开发运行在Android平台的Java虚拟机, Android程序编译后会生成dex文件.Dalvik虚拟机下运行Java时,要将字节码通过即时编译器(just in ...
- jsp隐式对象
隐式对象使用位置 隐式对象在转译为Servlet后,是_jspService()中的局部变量.隐式对象只能在<%与%>之间,或<%=与%>之间直接使用. 无法在<%!与% ...
- TI(德州仪器) TMS320C674x逆向分析之二
TI官网文档: http://www.ti.com/product/tms320c6745/technicaldocuments 里面资料非常详细,可以对着里面一个个看,用的比较多的两个文档: TMS ...
- android dev概念快速入门
apk: android将源代码依赖库等经过编译后打包分发的应用. 打包详细过程如下: android-studio安装 由于google被qiang,需要制定proxy,可以使用sock,同时安装完 ...
- webservice安全性浅谈
原文地址:http://www.cnblogs.com/chhuic/archive/2009/11/19/1606109.html 做项目时,经常会用到WebService来通讯,但WebServi ...