将 SecondaryNameNode 配置到 s105 节点上
相关链接
0. 说明
SecondaryNameNode 的作用 参考【待补充】
在 Hadoop 完全分布式的基础之上配置
将 SecondaryNameNode 配置到 s105 节点上
集群规划如下
| 服务器主机名 | ip | 节点配置 |
| s101 | 192.168.23.101 | NameNode / ResourceManager |
| s102 | 192.168.23.102 | DataNode / NodeManager |
| s103 | 192.168.23.103 | DataNode / NodeManager |
| s104 | 192.168.23.104 | DataNode / NodeManager |
| s105 | 192.168.23.105 | SecondaryNameNode |
1. 配置 root 用户的 SSH 免密登陆
1.1 在 s101 节点上切换到 root 用户
su root
1.2 生成公私密钥对
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
1.3 配置免密登陆(完成后退出 root 用户)
ssh-copy-id root@s101
ssh-copy-id root@s102
ssh-copy-id root@s103
ssh-copy-id root@s104
ssh-copy-id root@s105
2. 编写 xcall.sh 脚本
说明
xcall.sh 脚本编写是为了多个节点同时执行相同的命令
xcall.sh 脚本如下:
#!/bin/bash # for循环
for((i= ; i<=; i++)) ; do
# 更改文本颜色
tput setaf
# 输出以下文本
echo ==================== s$i $@ ===================
# 更改文本颜色
tput setaf
# ssh 远程登陆主机 s$i ,执行输入的参数的命令
ssh s$i $@
done
为 xcall.sh 赋予可执行权限
chmod a+x xcall.sh
编写完成之后,将其发送到 /usr/local/bin 下。
mv xcall.sh /usr/local/bin
创建 jps 软链接
在 /usr/local/bin 中为 jps 创建软连接(每个服务器都要创建)
ln -s /soft/jdk/bin/jps /usr/local/bin/jps
3. 编写 xsync.sh 脚本
说明
xsync.sh 脚本编写是为了从主节点同步配置文件到子节点
xsync.sh 脚本如下:
#!/bin/bash # 指出当前用户名
name=`whoami`
# 指定文件所在文件夹名称
dir=`dirname $`
# 指定文件的文件名
filename=`basename $`
# 进入到dir中
cd $dir
# 得到当前目录的绝对路径
fullpath=`pwd` for((i= ; i<=; i++)) ; do
tput setaf
echo ==================== s$i $@ ===================
tput setaf
# 远程同步命令 l 保留软连接 r 递归文件夹
rsync -lr $filename "$name"@s"$i":$fullpath
done
为 xsync.sh 赋予可执行权限
chmod a+x xsync.sh
编写完成之后,将其发送到 /usr/local/bin 下。
mv xsync.sh /usr/local/bin
使用 root 用户权限在所有机器上安装 rsync
xcall.sh yum install -y rsync
4. 修改 & 分发配置文件
4.1 修改配置文件 [ hdfs-site.xml ]
位置在 /soft/hadoop/etc/hadoop/hdfs-site.xml
添加配置
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>s105:50090</value>
</property>
4.2 分发配置文件
删除其他节点的所有 hdfs-site.xml
ssh s102 rm -r /soft/hadoop/etc/hadoop/hdfs-site.xml
ssh s103 rm -r /soft/hadoop/etc/hadoop/hdfs-site.xml
ssh s104 rm -r /soft/hadoop/etc/hadoop/hdfs-site.xml
ssh s105 rm -r /soft/hadoop/etc/hadoop/hdfs-site.xml
使用 xsync.sh 脚本将所有配置文件进行同步
xsync.sh /soft/hadoop/etc/hadoop/hdfs-site.xml
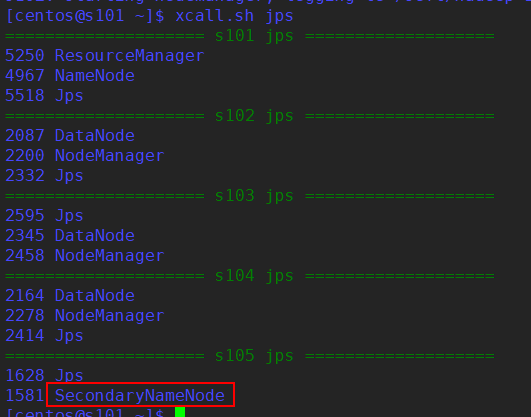
5. 启动 Hadoop & 验证 SecondaryNameNode 配置成功
启动 Hadoop
start-all.sh
验证 SecondaryNameNode 配置成功
xcall.sh jps
将 SecondaryNameNode 配置到 s105 节点上的更多相关文章
- OpenStack-Ocata版+CentOS7.6 云平台环境搭建 — 6.在计算节点上安装并配置计算服务Nova
安装和配置计算节点这个章节描述如何在计算节点上安装和配置计算服务. 计算服务支持几种不同的 hypervisors.为了简单起见,这个配置在计算节点上使用 :KVM <kernel-based ...
- 从0开始搭建SQL Server AlwaysOn 第四篇(配置异地机房节点)
从0开始搭建SQL Server AlwaysOn 第四篇(配置异地机房节点) 第一篇http://www.cnblogs.com/lyhabc/p/4678330.html第二篇http://www ...
- TaskTracker节点上的内存管理器
Hadoop平台的最大优势就是充分地利用了廉价的PC机,这也就使得集群中的工作节点存在一个重要的问题——节点所在的PC机内存资源有限(这里所说的工作节点指的是TaskTracker节点),执行任务时常 ...
- SQL Server Alwayson配置两个节点加共享文件夹仲裁见证
标签:MSSQL/节点和共享文件夹多数 概述 之前讲过多数节点的仲裁配置,多数节点一般3个节点以上的奇数个节点:常见的是使用3个节点节点多了也是浪费因为Alwayson的只读路由只能利用到一个只读副本 ...
- OpenStack搭建Q版在控制节点上的环境准备(step2)
接下来是只需要在控制节点上准备的环境配置.其中虽然NTP服务需要在所有节点上都安装,但NTP服务在控制节点和其他的节点上的配置是不同的,所以不把它放在step1的公共配置中进行准备.如下: 1.配置N ...
- NodePort 只能在node节点上访问,外部无法访问
创建了一个NodePort类型的jenkins service,node port 30000,node节点ip为192.168.56.101, 在node节点上通过浏览器能正常访问http://19 ...
- OpenStack-Ocata版+CentOS7.6 云平台环境搭建 — 5.在控制节点上部署计算服务Nova
计算服务Nova使用OpenStack Compute来托管和管理云计算系统. OpenStack Compute是基础架构即服务(IaaS)系统的主要部分. 主要模块用Python实现.OpenSt ...
- hdfs 如何实现退役节点快速下线(也就是退役节点上的数据块快速迁移)speed up decommission blocks removal
以下是选择复制源节点的代码 代码总结: A=datanode上要复制block的Queue size与 target datanode没被选出之前待处理复制工作数之和. 1. 优先选择退役中的节点,因 ...
- 三、安装并配置Kubernetes Node节点
1. 安装并配置Kubernetes Node节点 1.1 安装Kubernetes Node节点所需服务 yum -y install kubernetes 通过yum安装kubernetes服 ...
随机推荐
- VGG 论文研读
VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION 论文地址 摘要 研究主要贡献是通过非常小的3x3卷积核的神经网络架 ...
- Spring @Conditional简单使用 以及 使用时注意事项一点
@Conditional注解在类的方法中 @Conditional注解失效的一种原因 @Conditional注解在类上 手写的低配版@ConditionalOnClass Spring @Cond ...
- zoj 1109 Language of FatMouse(map映照容器的典型应用)
题目连接: acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=1109 题目描述: We all know that FatMouse doe ...
- [USACO 07DEC]Best Cow Line, Gold
Description 题库链接 给以长度为 \(n\) 的字符串,要求每次只能从两边取一个字符,使得取出来之后字典序最小. \(1\leq n\leq 30000\) Solution 将字符串翻转 ...
- .19-浅析webpack源码之compile流程-rules参数处理(2)
第一步处理rule为字符串,直接返回一个包装类,很简单看注释就好了. test/include/exclude 然后处理test.include.exclude,如下: if (rule.test | ...
- Core Foundation 官方文档翻译
Core Foundation框架中常用的隐含类型: 使用这些隐含类型时需要自己初始化,自己去释放内存.所以需要记住,在初始化的同时在相应位置释放.以防出现内存问题. 1.CFStringRe ...
- 【Java并发编程】7、线程池
1. 为什么使用线程池 诸如 Web 服务器.数据库服务器.文件服务器或邮件服务器之类的许多服务器应用程序都面向处理来自某些远程来源的大量短小的任务.请求以某种方式到达服务器,这种方式可能是通过网络协 ...
- 撩课-Web大前端每天5道面试题-Day35
1.React 中 refs 的作用是什么? Refs 是 React 提供给我们的安全访问 DOM 元素或者某个组件实例的句柄. 我们可以为元素添加 ref 属性然后在回调函数中接受该元素在 DOM ...
- Mybatis之SessionFactory原理
Mybatis在使用前需进行初始化,下面就针对Mybatis的初始化过程进行介绍.Mybatis的初始化过程有两种:基于XML和基于Java API两种方式,下面就针对基于XML的方式进行展开. 一. ...
- JavaScript--DOM操作表格及样式(21)
一 操作表格 // <table>标签是HTML中结构最为复杂的一个,我们可以通过DOM来创建生成它,或者HTMLDOM来操作它; // 使用DOM来创建表格; var table = d ...