spark sql运行原理
Spark sql 对SQL语句的处理,先将SQL语句进行解析(parse)形成一个tree,然后使用Rule对Tree进行绑定,优化等处理过程,通过模式匹配对不同类型的节点采用不同操作。查询优化器是Catalyst,它负责处理查询语句的解析,绑定,优化和生成物理计划等过程,Catalyst是Spark SQL最核心的部分,其性能优劣将决定整体的性能。
spark SQL由Core,Catalyst,hive和hive-thriftserver 4个部分组成:
core 负责数据的输入输出,从不同数据源获得数据(rdd,parquet,json等),然后将查询结果输出成dataframe
catalyst 负责处理查询语句的整体处理过程,包括解析,绑定,优化(Optimize),物理计划等
hive 负责对hive数据处理
hive-thriftserver 提供CLI和jdbc/odbc接口
Tree是Catalyst执行计划表示的数据结构。LogicalPlans,Expressions和Pysical Operators都可以使用Tree来表示。Tree具备一些Scala Collection的操作能力和树遍历能力。
Tree提供三种特质(trait):
- UnaryNode:一元节点,即只有一个子节点
- BinaryNode:二元节点,即有左右子节点的二叉节点
- LeafNode:叶子节点,没有子节点的节点
Tree有两个子类继承体系,即QueryPlan和Expression
QueryPlan下面的两个子类分别是LogicalPlan(逻辑执行计划)和SparkPlan(物理执行计划)。
Expression是表达式体系,是指不需要执行引擎计算,而可以直接计算或处理的节点,包括Cast操作、Porjection操作、四则运算和逻辑操作符运算等等。
Rule[TreeType <: TreeNode[_]]是一个抽象类,子类需要复写apply(plan: TreeType)方法来指定处理逻辑。对于Rule的具体实现是通过RuleExecutor完成的,凡是需要处理执行计划树进行实施规则匹配和节点处理的,都需要继承RuleExecutor[TreeType]抽象类。
spark sql 运行架构图
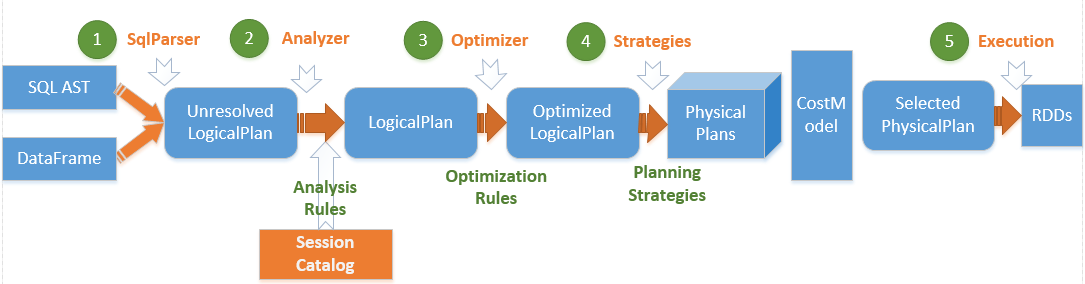
(1)、将SQL语句通过词法和语法解析生成未绑定的逻辑计划(包含Unresolved Relation、Unresolved Function和Unresolved Attribute),然后在后续步骤中使用不同的Rule应用到该逻辑计划上。
(2)、Analyzer使用Analysis Rules,配合数据元数据(如SessionCatalog或Hive Metastore),完善未绑定的逻辑计划的属性而转换成已绑定的逻辑计划。
具体的流程是:先实例化一个Simple Analyzer,然后遍历预先定义好的Batch,通过父类的Rule Exector的执行方法运行Batch里面的Rules,每个Rule会对未绑定的逻辑计划进行处理,有些可以通过一次解析处理,有些需要多次迭代,迭代至FixedPoint次数迭代或达到前后两次的树结构没有变化时停止。
(3)、Optimizer使用Optimization Rules,将绑定的逻辑计划进行合并、列裁剪、过滤器下推等优化工作后生成优化的逻辑计划。
(4)、Planner使用Planning Strategies,对优化的逻辑计划进行转换(Transform)生成可以执行的逻辑计划。根据过去的性能统计数据,选择最佳的物理执行计划CostModel,最后可以执行的物理计划树,即得到SparkPlan。
(5)、在最终真正执行物理执行计划前,还要进行preparations规则处理,最后调用SparkPlan的execute执行计算RDD。
在解析SQL语句之前需要初始化SQLContext,它定义了Spark SQL执行的上下文,并把元数据保存在SessionCatalog中,这些元数据包括表名称、表字段名称和字段类型等。
spark sql运行原理的更多相关文章
- 46、Spark SQL工作原理剖析以及性能优化
一.工作原理剖析 1.图解 二.性能优化 1.设置Shuffle过程中的并行度:spark.sql.shuffle.partitions(SQLContext.setConf()) 2.在Hive数据 ...
- spark 任务运行原理
调优概述 在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都可以在spark-submit命令中作为参数设置.很多Spark初学者,通常不知道该设置哪些必要的参数,以 ...
- 7. Spark SQL的运行原理
7.1 Spark SQL运行架构 Spark SQL对SQL语句的处理和关系型数据库类似,即词法/语法解析.绑定.优化.执行.Spark SQL会先将SQL语句解析成一棵树,然后使用规则(Rule) ...
- 第7章 Spark SQL 的运行原理(了解)
第7章 Spark SQL 的运行原理(了解) 7.1 Spark SQL运行架构 Spark SQL对SQL语句的处理和关系型数据库类似,即词法/语法解析.绑定.优化.执行.Spark SQL会先将 ...
- Spark SQL原理及实战
一.Spark SQL的发展 1.spark SQL和shark SparkSQL的前身是Shark,给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,Hive应运而生,它是当 ...
- Spark SQL概念学习系列之如何使用 Spark SQL(六)
val sqlContext = new org.apache.spark.sql.SQLContext(sc) // 在这里引入 sqlContext 下所有的方法就可以直接用 sql 方法进行查询 ...
- Spark SQL Catalyst源代码分析之TreeNode Library
/** Spark SQL源代码分析系列文章*/ 前几篇文章介绍了Spark SQL的Catalyst的核心执行流程.SqlParser,和Analyzer,本来打算直接写Optimizer的,可是发 ...
- Spark SQL源代码分析之核心流程
/** Spark SQL源代码分析系列文章*/ 自从去年Spark Submit 2013 Michael Armbrust分享了他的Catalyst,到至今1年多了,Spark SQL的贡献者从几 ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
随机推荐
- jenkins 邮件配置 二 ***
Jenkins 有两种邮件通知方式: 1.Jenkins自带的“E-mail Notification” 2.插件:Extended E-mail Notification,是可编辑的邮件配置方式. ...
- WCF类型共享技巧【转载】
调用过WCF服务的同学可能都会遇到这样的问题,同一个实体类型,不同的服务Visual Studio生成了不同的版本,例如Service1.User和Service2.User,对于C#来说,这是两个不 ...
- <亲测>CentOS7 安装mysql8.0(YUM方式)
CentOS7 安装mysql(YUM方式) 1.下载mysql源安装包 shell> wget http://dev.mysql.com/get/mysql80-community-rel ...
- 【java】之Method和Field反射获取和设置属性值
package com.javaluna.reflect; import java.lang.reflect.Field; import java.lang.reflect.Method; impor ...
- Spring @Async实现异步调用示例
什么是“异步调用”? “异步调用”对应的是“同步调用”,同步调用指程序按照定义顺序依次执行,每一行程序都必须等待上一行程序执行完成之后才能执行:异步调用指程序在顺序执行时,不等待异步调用的语句返回结果 ...
- 学习笔记之GitHub
GitHub https://github.com/ GitHub - Wikipedia https://en.wikipedia.org/wiki/GitHub GitHub (originall ...
- 远程服务器安装mysql数据库
https://www.cnblogs.com/renjidong/p/7047396.html 1.新开的云服务器,需要检测系统是否自带安装mysql # yum list installed | ...
- solusvm安装过程
openvz solusvm ** Testing connectivity PING solusvm.com (69.168.233.94) 56(84) bytes of data. 64 byt ...
- laraval一键安装包的下载地址
http://laravelacademy.org/resources-download
- DockerFile服务
Dockerfile分为四部分:基础镜像信息.镜像创建者信息.镜像操作指令.容器启动执行指令. 一.Dockerfile的书写规则及指令使用方法 Dockerfile的指令是忽略大小写的,建议使用大写 ...