Spring-data-jpa 学习笔记(二)
Spring Data JPA 进行持久层(即Dao)开发一般分三个步骤:
- 声明持久层的接口,该接口继承 Repository(或Repository的子接口,其中定义了一些常用的增删改查,以及分页相关的方法)。
- 在接口中声明需要的业务方法。Spring Data 将根据给定的策略生成实现代码。
- 在 Spring 配置文件中增加一行声明,让 Spring 为声明的接口创建代理对象。配置了 <jpa:repositories> 后,Spring 初始化容器时将会扫描 base-package 指定的包目录及其子目录,为继承 Repository 或其子接口的接口创建代理对象,并将代理对象注册为 Spring Bean,业务层便可以通过 Spring 自动封装的特性来直接使用该对象。
一、Repository子接口相关概述

- CrudRepository:继承Repository接口,新增了一组CRUD相关的方法
- PagingAndSortingRepository:继承CrudRepository接口,新增了一组分页排序的相关方法
- JpaRepository:继承PagingAndSortRepository接口,新增了一组JPA规范的方法
- JpaSpecificationExecutor:不属于Repository继承体系,有一组JPA Criteria查询相关方法
二、CrudRepository接口介绍
@NoRepositoryBean
public interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID> {
<S extends T> S save(S entity); //保存
<S extends T> Iterable<S> save(Iterable<S> entities);//批量保存
T findOne(ID id); //根据id查询一个对象
boolean exists(ID id); //判断对象是否存在
Iterable<T> findAll(); //查询所有的对象
Iterable<T> findAll(Iterable<ID> ids);//根据id列表查询所有的对象
long count(); //计算对象的总个数
void delete(ID id); //根据id删除
void delete(T entity); //删除对象
void delete(Iterable<? extends T> entities);//批量删除
void deleteAll(); //删除所有
}@NoRepositoryBean
public interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID> {
<S extends T> S save(S entity); //保存
<S extends T> Iterable<S> save(Iterable<S> entities);//批量保存
T findOne(ID id); //根据id查询一个对象
boolean exists(ID id); //判断对象是否存在
Iterable<T> findAll(); //查询所有的对象
Iterable<T> findAll(Iterable<ID> ids);//根据id列表查询所有的对象
long count(); //计算对象的总个数
void delete(ID id); //根据id删除
void delete(T entity); //删除对象
void delete(Iterable<? extends T> entities);//批量删除
void deleteAll(); //删除所有
}
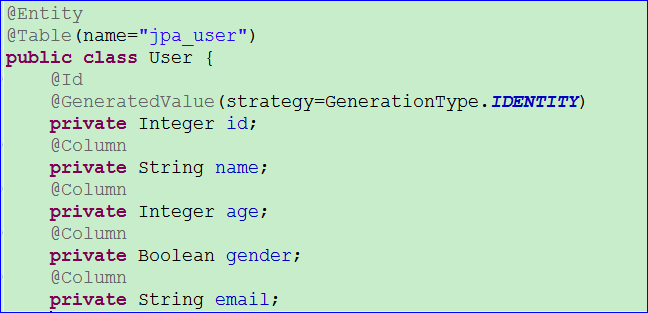
- 为了和上一篇笔记的代码区分开,这里新建一个实体类User。这个实体类的属性如下图
- Dao层接口定义如下,直接继承CrudRepository接口即可

- 测试类代码如下,首先我测试了批量保存方法,向数据库插入了26条数据。后面又测试了保存方法,发现这个保存方法可以起更新的作用的,类似于JPA中EntityManage的merge方法
/** 测试CrudRepository的批量save方法 */
@Test
public void testCrudRepositorySaveMethod(){
UserDao dao = ctx.getBean(UserDao.class);
List<User> list = new ArrayList<>();
for (int i = 'A'; i <= 'Z'; i++) {
User u = new User();
u.setName((char)i + "" + (char)i); // AA,BB这种
u.setGender(true);
u.setAge(i + 1);
u.setEmail(u.getName() + "@163.com");
list.add(u);
}
// 调用dao的批量保存
dao.save(list);
}
/** 测试CrudRepository的save */
@Test
public void testCrudRepositoryUpdate(){
UserDao dao = ctx.getBean(UserDao.class);
// 从数据库查出来
User user = dao.findOne(1);
// 修改名字
user.setName("Aa");
dao.save(user); // 经过测试发现,有id时是更新,但不是绝对的;类似jpa的merge方法
}/** 测试CrudRepository的批量save方法 */
@Test
public void testCrudRepositorySaveMethod(){
UserDao dao = ctx.getBean(UserDao.class);
List<User> list = new ArrayList<>();
for (int i = 'A'; i <= 'Z'; i++) {
User u = new User();
u.setName((char)i + "" + (char)i); // AA,BB这种
u.setGender(true);
u.setAge(i + 1);
u.setEmail(u.getName() + "@163.com");
list.add(u);
}
// 调用dao的批量保存
dao.save(list);
}
/** 测试CrudRepository的save */
@Test
public void testCrudRepositoryUpdate(){
UserDao dao = ctx.getBean(UserDao.class);
// 从数据库查出来
User user = dao.findOne(1);
// 修改名字
user.setName("Aa");
dao.save(user); // 经过测试发现,有id时是更新,但不是绝对的;类似jpa的merge方法
}
三、PagingAndSortingRepository接口介绍
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID extends Serializable> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort sort); // 不带分页的排序
Page<T> findAll(Pageable pageable); // 带分页的排序
}@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID extends Serializable> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort sort); // 不带分页的排序
Page<T> findAll(Pageable pageable); // 带分页的排序
}
- 首先Dao层改一下,把继承的接口改为PagingAndSortingRepository

- 单元测试的代码如下,这里只测试了带分页和排序的那个方法,不带分页的那个方法就不测试了;这里的重点是参数怎么传。而且springdata的分页时,页码是从0开始的,这点要特别注意。
/** 测试PagingAndSortingRepositoryd的分页且排序方法 */
@Test
public void testPagingAndSortingRepository() {
UserDao userDao = ctx.getBean(UserDao.class);
/* 需求:查询第3页的数据,每页5条 */
int page = 3 - 1; //由于springdata默认的page是从0开始,所以减1
int size = 5;
//Pageable 接口通常使用的其 PageRequest 实现类. 其中封装了需要分页的信息
//排序相关的. Sort 封装了排序的信息
//Order 是具体针对于某一个属性进行升序还是降序.
Order order1 = new Order(Direction.DESC, "id");//按id降序
Order order2 = new Order(Direction.ASC, "age");//按age升序
Sort sort = new Sort(order1,order2);
Pageable pageable = new PageRequest(page, size,sort);
Page<User> result = userDao.findAll(pageable);
System.out.println("总记录数: " + result.getTotalElements());
System.out.println("当前第几页: " + (result.getNumber() + 1));
System.out.println("总页数: " + result.getTotalPages());
System.out.println("当前页面的 List: " + result.getContent());
System.out.println("当前页面的记录数: " + result.getNumberOfElements());
System.out.println("当前的user对象的结果如下:");
for (User user : result.getContent()) {
System.out.println(user.getId() + " == " + user.getAge());
}
}/** 测试PagingAndSortingRepositoryd的分页且排序方法 */
@Test
public void testPagingAndSortingRepository() {
UserDao userDao = ctx.getBean(UserDao.class);
/* 需求:查询第3页的数据,每页5条 */
int page = 3 - 1; //由于springdata默认的page是从0开始,所以减1
int size = 5;
//Pageable 接口通常使用的其 PageRequest 实现类. 其中封装了需要分页的信息
//排序相关的. Sort 封装了排序的信息
//Order 是具体针对于某一个属性进行升序还是降序.
Order order1 = new Order(Direction.DESC, "id");//按id降序
Order order2 = new Order(Direction.ASC, "age");//按age升序
Sort sort = new Sort(order1,order2);
Pageable pageable = new PageRequest(page, size,sort);
Page<User> result = userDao.findAll(pageable);
System.out.println("总记录数: " + result.getTotalElements());
System.out.println("当前第几页: " + (result.getNumber() + 1));
System.out.println("总页数: " + result.getTotalPages());
System.out.println("当前页面的 List: " + result.getContent());
System.out.println("当前页面的记录数: " + result.getNumberOfElements());
System.out.println("当前的user对象的结果如下:");
for (User user : result.getContent()) {
System.out.println(user.getId() + " == " + user.getAge());
}
}
- 运行测试方法,生成的sql和结果如下图


四、JpaRepository接口介绍
@NoRepositoryBean
public interface JpaRepository<T, ID extends Serializable>
extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
List<T> findAll(); //查询方法
List<T> findAll(Sort sort); //查询方法,带排序
List<T> findAll(Iterable<ID> ids); //查询方法,参数为id集合
<S extends T> List<S> save(Iterable<S> entities); //批量保存
void flush(); //刷新
<S extends T> S saveAndFlush(S entity); //保存并刷新,类似merge方法
void deleteInBatch(Iterable<T> entities);
void deleteAllInBatch();
T getOne(ID id);
<S extends T> List<S> findAll(Example<S> example); //根据“example”查找,参考:http://www.cnblogs.com/rulian/p/6533109.html
<S extends T> List<S> findAll(Example<S> example, Sort sort); // 根据“example”查找并排序
}@NoRepositoryBean
public interface JpaRepository<T, ID extends Serializable>
extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
List<T> findAll(); //查询方法
List<T> findAll(Sort sort); //查询方法,带排序
List<T> findAll(Iterable<ID> ids); //查询方法,参数为id集合
<S extends T> List<S> save(Iterable<S> entities); //批量保存
void flush(); //刷新
<S extends T> S saveAndFlush(S entity); //保存并刷新,类似merge方法
void deleteInBatch(Iterable<T> entities);
void deleteAllInBatch();
T getOne(ID id);
<S extends T> List<S> findAll(Example<S> example); //根据“example”查找,参考:http://www.cnblogs.com/rulian/p/6533109.html
<S extends T> List<S> findAll(Example<S> example, Sort sort); // 根据“example”查找并排序
}
- dao层,把继承的接口修改一下就ok,见下图

- 单元测试代码如下
/** 测试JpaRepository的SaveAndFlush */
@Test
public void testJpaRepositorySaveAndFlush() {
UserDao userDao = ctx.getBean(UserDao.class);
User user = new User();
user.setId(30); // id为30的话,不在数据库中。如果在数据库中,下面则是更新
user.setAge(27);
user.setName("testSaveAndFlush");
User user2 = userDao.saveAndFlush(user);
System.out.println("user==user2:" + (user == user2));
System.out.println("user.id=" + user.getId());
System.out.println("user2.id=" + user2.getId());
}/** 测试JpaRepository的SaveAndFlush */
@Test
public void testJpaRepositorySaveAndFlush() {
UserDao userDao = ctx.getBean(UserDao.class);
User user = new User();
user.setId(30); // id为30的话,不在数据库中。如果在数据库中,下面则是更新
user.setAge(27);
user.setName("testSaveAndFlush");
User user2 = userDao.saveAndFlush(user);
System.out.println("user==user2:" + (user == user2));
System.out.println("user.id=" + user.getId());
System.out.println("user2.id=" + user2.getId());
}
- 运行结果得好好说一下。运行该方法,发现id为30的记录不在数据库中,则新增一条记录,把属性值copy过去,保存到数据库。截图如下所示,从sql语句可以看出是先查询然后新增

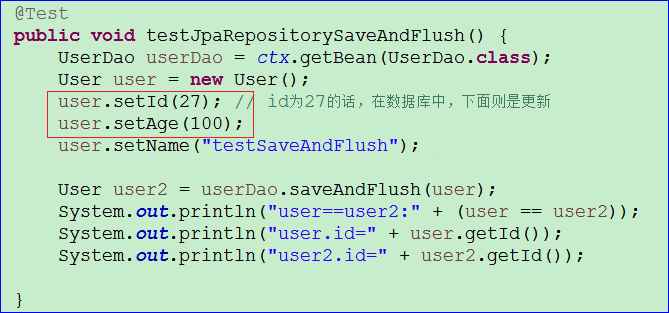
- 当我们把测试代码中按下图修改下,再运行。则发现id在数据库中存在,就更新。测试代码及结果见下图
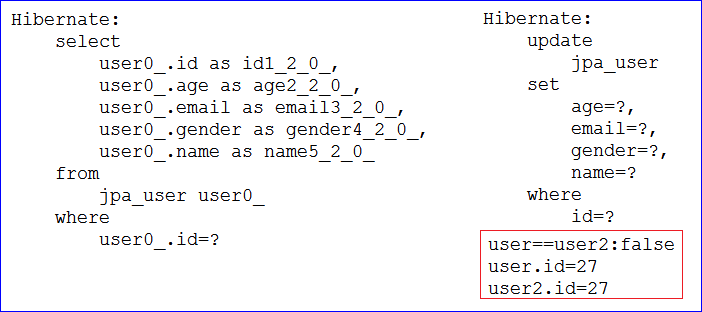
- 功能和jpa的EntityManage的merge方法是一致的,如果对象的id在数据库存在,则是更新;如果不存在则是保存
- 返回的对象和原来的对象之所以不相等时因为返回的是持久化对象的引用。也就是返回的是一级缓存中对象的引用。
- 欲实现user等于user2的话,则可以这样玩:
- 在service层定义一方法,开始事务;
- 方法第一步从数据库查询出id为27的user实体,然后修改一个属性,这个user实体此时是在一级缓存中的。
- 方法的第二步是saveAndFlush这个user实体,返回一个user2实体,这个user2实体就是一级缓存中的那个user实体。
- 比较user和user2的地址,你会发现结果是true;但是我们一般也不会去刻意比较这2个对象。之所以在这个解释这个返回值,可能也是由于笔者有强迫症。
五、JpaSpecificationExecutor接口介绍
public interface JpaSpecificationExecutor<T> {
T findOne(Specification<T> spec);
List<T> findAll(Specification<T> spec);
Page<T> findAll(Specification<T> spec, Pageable pageable); //条件查询,且支持分页
List<T> findAll(Specification<T> spec, Sort sort);
long count(Specification<T> spec);
}public interface JpaSpecificationExecutor<T> {
T findOne(Specification<T> spec);
List<T> findAll(Specification<T> spec);
Page<T> findAll(Specification<T> spec, Pageable pageable); //条件查询,且支持分页
List<T> findAll(Specification<T> spec, Sort sort);
long count(Specification<T> spec);
}
- dao层做了小小的改动,继承JpaRepository的同时也继承JpaSpecificationExecutor,具体见下图

- 测试代码如下,这个测试的是 Page<T> findAll(Specification<T> spec, Pageable pageable) 这个方法
/**
* 目标: 实现带查询条件的分页. id > 3 的条件
* 调用 JpaSpecificationExecutor 的 Page<T> findAll(Specification<T> spec, Pageable pageable);
* Specification: 封装了 JPA Criteria 查询的查询条件
* Pageable: 封装了请求分页的信息: 例如 pageNo, pageSize, Sort
*/
@Test
public void testJapSpecificationExecutor() {
// 目标:查询id>3 的第3页的数据,页大小为5
UserDao userDao = ctx.getBean(UserDao.class);
Pageable pageable = new PageRequest(3 - 1, 5);
//通常使用 Specification 的匿名内部类
Specification<User> spec = new Specification<User>() {
/**
* @param root: 代表查询的实体类.
* @param query: 可以从中可到 Root 对象, 即告知 JPA Criteria 查询要查询哪一个实体类. 还可以
* 来添加查询条件, 还可以结合 EntityManager 对象得到最终查询的 TypedQuery 对象.
* @param cb: CriteriaBuilder 对象. 用于创建 Criteria 相关对象的工厂. 当然可以从中获取到 Predicate 对象
* @return: Predicate 类型, 代表一个查询条件.
*/
@Override
public Predicate toPredicate(Root<User> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
// 一般用root和cb就ok了
return cb.gt(root.get("id"), 3);
// 多条件查询的案例
/*List<Predicate> predicates = new ArrayList<>();
Predicate p1 = cb.notEqual(root.get("id"), 15);
Predicate p2 = cb.like(root.get("email"),"%163.com");
predicates.add(p1);
predicates.add(p2);
// 即使predicates集合里面没元素,也能查询,就变成了查全部
return cb.and(predicates.toArray(new Predicate[predicates.size()]));*/
}
};
Page<User> list = userDao.findAll(spec, pageable);
for (User user : list) {
System.out.println(user);
}
}/**
* 目标: 实现带查询条件的分页. id > 3 的条件
* 调用 JpaSpecificationExecutor 的 Page<T> findAll(Specification<T> spec, Pageable pageable);
* Specification: 封装了 JPA Criteria 查询的查询条件
* Pageable: 封装了请求分页的信息: 例如 pageNo, pageSize, Sort
*/
@Test
public void testJapSpecificationExecutor() {
// 目标:查询id>3 的第3页的数据,页大小为5
UserDao userDao = ctx.getBean(UserDao.class);
Pageable pageable = new PageRequest(3 - 1, 5);
//通常使用 Specification 的匿名内部类
Specification<User> spec = new Specification<User>() {
/**
* @param root: 代表查询的实体类.
* @param query: 可以从中可到 Root 对象, 即告知 JPA Criteria 查询要查询哪一个实体类. 还可以
* 来添加查询条件, 还可以结合 EntityManager 对象得到最终查询的 TypedQuery 对象.
* @param cb: CriteriaBuilder 对象. 用于创建 Criteria 相关对象的工厂. 当然可以从中获取到 Predicate 对象
* @return: Predicate 类型, 代表一个查询条件.
*/
@Override
public Predicate toPredicate(Root<User> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
// 一般用root和cb就ok了
return cb.gt(root.get("id"), 3);
// 多条件查询的案例
/*List<Predicate> predicates = new ArrayList<>();
Predicate p1 = cb.notEqual(root.get("id"), 15);
Predicate p2 = cb.like(root.get("email"),"%163.com");
predicates.add(p1);
predicates.add(p2);
// 即使predicates集合里面没元素,也能查询,就变成了查全部
return cb.and(predicates.toArray(new Predicate[predicates.size()]));*/
}
};
Page<User> list = userDao.findAll(spec, pageable);
for (User user : list) {
System.out.println(user);
}
}
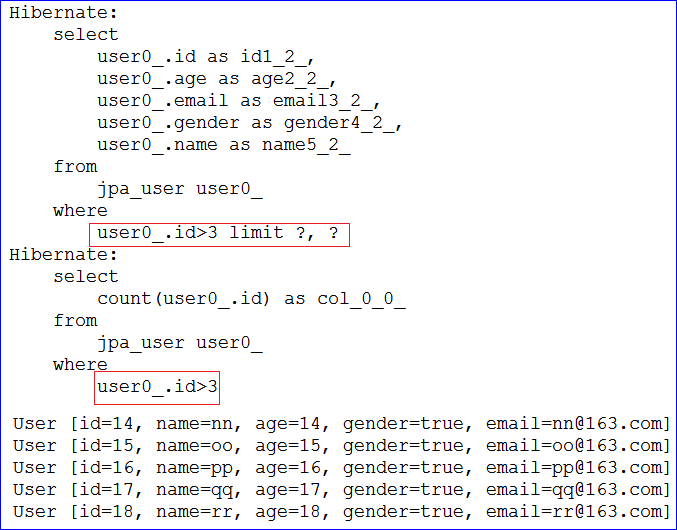
- 运行后生成的sql语句和结果如下图
六、本文小结
Spring-data-jpa 学习笔记(二)的更多相关文章
- spring data jpa 学习笔记
springboot 集成 springData Jpa 1.在pom.xml添加依赖 <!-- SpringData-Jpa依赖--> <dependency <groupI ...
- Spring Data JPA学习笔记
下面先来介绍一下JPA中一些常用的查询操作: //And --- 等价于 SQL 中的 and 关键字,比如 findByHeightAndSex(int height,char sex): publ ...
- Spring Data JPA 学习记录1 -- 单向1:N关联的一些问题
开新坑 开新坑了(笑)....公司项目使用的是Spring Data JPA做持久化框架....学习了一段时间以后发现了一点值得注意的小问题.....与大家分享 主要是针对1:N单向关联产生的一系列问 ...
- Spring学习笔记(八)Spring Data JPA学习
jpa简单的命名规则如下,这个不多做介绍,放在这里也是给自己以后查找起来方便,这篇文章主要介绍之前一直忽略了的几个点,像@NoRepositoryBean这个注解,以及怎么自定义Repositor ...
- [Spring Data Repositories]学习笔记--使用现有的repository
以下内容是在学习Spring-Data-mongoDB中的Spring Data Repositories时做的一些笔记.备忘! 感觉学习还是看官方的资料比较透彻一些. Spring Data Rep ...
- 031 Spring Data Elasticsearch学习笔记---重点掌握第5节高级查询和第6节聚合部分
Elasticsearch提供的Java客户端有一些不太方便的地方: 很多地方需要拼接Json字符串,在java中拼接字符串有多恐怖你应该懂的 需要自己把对象序列化为json存储 查询到结果也需要自己 ...
- [Spring Data MongoDB]学习笔记--MongoTemplate查询操作
查询操作主要用到两个类:Query, Criteria 所有的find方法都需要一个query的object. 1. 直接通过json来查找,不过这种方式在代码中是不推荐的. BasicQuery q ...
- spring in action 学习笔记二:aop的理解
一: aop的思想的来在哪里? 一个系统一般情况下由多个组件组成,而每一个组件除了干自己的本职工作以外,有时还会干一些杂活(如:日志(logging).事务管理(transaction manager ...
- Spring in Action 学习笔记二-DI
装配bean 2015年10月9日 9:49 Sprng中,对象无需自己负责查找或创建其关联的其他对象.相关,容器负责吧需要相互协作的对象引用赋予各个对象. 创建应用对象之间协 ...
- [Spring Data MongoDB]学习笔记--MongoTemplate插入修改操作
插入操作: 直接给个例子 import static org.springframework.data.mongodb.core.query.Criteria.where; import static ...
随机推荐
- Android--自定义控件---自动分页的GridView
最近,根据项目需求,需要一个能够自动分页的导航,所以便自定义了一个自动分页的GridView. 思路:继承RelativeLayout,然后在里面放了一个viewpager和一个GridView... ...
- Expo大作战(七)--expo如何使用Genymotion模拟器
简要:本系列文章讲会对expo进行全面的介绍,本人从2017年6月份接触expo以来,对expo的研究断断续续,一路走来将近10个月,废话不多说,接下来你看到内容,将全部来与官网 我猜去全部机翻+个人 ...
- 【转】qt-vs-addin:Qt4和Qt5之VS插件如何共存与使用
原则上,两者是不可以同时存在的,但是如果都安装了,该如何分别使用他们呢? Qt4 Visual Studio Add-in:官网可以下载安装程序,qt-vs-addin-1.1.11-opensour ...
- Sql Server Tempdb原理-日志机制解析实践
笔者曾经在面试DBA时的一句”tempdb为什么比其他数据库快?”使得95%以上的应试者都一脸茫然.Tempdb作为Sqlserver的重要特征,一直以来大家对它可能即熟悉又陌生.熟悉是我们时时刻刻都 ...
- MySQL数据行溢出的深入理解
一.从常见的报错说起 故事的开头我们先来看一个常见的sql报错信息: 相信对于这类报错大家一定遇到过很多次了,特别对于OMG这种已内容生产为主要工作核心的BG,在内容线的存储中,数据大一定是个绕不开的 ...
- django导入自定义模块
自定义模块cust.py位于应用aptest目录下 1.编辑settings.py from aptest import cust 2.编辑views.py from cust import pc # ...
- selenium-键盘和鼠标事件
常见的键盘操作 from selenium.webdriver.common.keys import Keys 模拟enter键:send_keys(Keys.ENTER)键盘F1~F12: send ...
- List集合的特有功能
import java.util.ArrayList; import java.util.List; /** * * List集合的特有功能 * A:添加功能 * void add(int index ...
- es6安装babel包
1.前面下载node.js及安装淘宝镜像可以查看我写的vue.js环境搭建 2.安装完node后,安装babel npm install -g babel-cli 3.检验babel是否安装成功: b ...
- SpringMVC之ajax+select下拉框交互常用方式
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...