Java开发笔记(九十)对象序列化及其读写
有些时候,开发者想把程序运行过程中的数据临时保存到文件,可是前面介绍的字符流和字节流,要么用来读写文本字符串,要么用来读写字节数组,并不能直接保存某个对象信息,因为对象里面包括成员属性和成员方法,单就属性而言,每个属性又有各自的数据类型及其具体数值,这些复杂的信息既不能通过字符串表达,也不能通过简单的字节数组表达。虽然现有手段不容易往文件中写入对象信息,但是该想法无疑极具吸引力,倘若能够自如地对文件读写某个对象数据,必定会给程序员的开发工作带来巨大便利,况且内存都能存放对象信息,为何磁盘反而无法存储对象了呢?
解决问题的关键在于需要给对象建立某种映射关系,磁盘文件固然只能存放字节形式的数据,但如果能将某对象进行有规则的排序操作,使之变成整齐有序的信息队列,那么程序即可按照规矩把对象转为可存储的字节数据。正所谓英雄所见略同,Java确实提供了类似的解题思路,把对象转成磁盘文件可识别数据的过程,Java称之为“序列化”;反过来,把磁盘文件内容转成内存中对象的过程,Java称之为“反序列化”。如同字符串与字节数组的相互转换那般,序列化与反序列化一起完成了内存对象和磁盘文件之间的转换操作。
若想让一个对象支持序列化与反序列化,得事先声明该对象的来源类是可序列化的,也就是命令来源类实现Serializable接口,这样程序才知道由该类创建而来的所有对象都支持序列化与反序列化。举个用户信息类的例子,基本的用户信息通常包括用户名、手机号和密码三个字段,再添加Serializable接口的实现,于是可序列化的用户信息类代码变成以下这般:
//定义一个可序列化的用户信息类。实现Serializable接口表示当前类支持序列化
public class UserInfo implements Serializable {
private String name; // 用户名
private String phone; // 手机号码
private String password; // 密码 public UserInfo() {
name = "";
phone = "";
password = "";
} // 以下省略各字段的get***/set***方法
}
之后来自于UserInfo的用户对象们纷纷摇身变为结构清晰的实例,不过由于序列化后的对象是种特殊的数据,因此还需专门的输入输出流进行处理。读写序列化对象的专用I/O流包括对象输入流ObjectInputStream和对象输出流ObjectOutputStream,其中前者用来从文件中读取对象信息,它的readObject方法完成了读对象操作;后者用来将对象信息写入文件,它的writeObject方法完成了写对象操作。下面是利用ObjectOutputStream往文件写入序列化对象的代码例子:
private static String mFileName = "D:/test/user.txt";
// 利用对象输出流把序列化对象写入文件
private static void writeObject() {
// 下面创建可序列化的用户信息对象,并给予赋值
UserInfo user = new UserInfo();
user.setName("王五");
user.setPhone("15960238696");
user.setPassword("111111");
// 根据指定文件路径构建文件输出流对象,然后据此构建对象输出流对象
try (FileOutputStream fos = new FileOutputStream(mFileName);
ObjectOutputStream oos = new ObjectOutputStream(fos);) {
oos.writeObject(user); // 把对象信息写入文件
System.out.println("对象序列化成功");
} catch (Exception e) {
e.printStackTrace();
}
}
由此可见,将对象信息写入文件的代码还是蛮简单的,从文件读取对象信息也很容易,只要下面的寥寥几行代码就搞定了:
// 利用对象输入流从文件中读取序列化对象
private static void readObject() {
// 创建可序列化的用户信息对象
UserInfo user = new UserInfo();
// 根据指定文件路径构建文件输入流对象,然后据此构建对象输入流对象
try (FileInputStream fos = new FileInputStream(mFileName);
ObjectInputStream ois = new ObjectInputStream(fos);) {
user = (UserInfo) ois.readObject(); // 从文件读取对象信息
System.out.println("对象反序列化成功");
} catch (Exception e) {
e.printStackTrace();
}
// 注意用户信息的密码字段设置了禁止序列化,故而文件读到的密码字段为空
String desc = String.format("姓名=%s,手机号=%s,密码=%s",
user.getName(), user.getPhone(), user.getPassword());
System.out.println("用户信息如下:"+desc);
}
然后运行上述的对象数据读写代码,观察到下列的日志信息:
对象序列化成功
对象反序列化成功
用户信息如下:姓名=王五,手机号=15960238696,密码=111111
看到这些日志,有没有发现什么不对劲的地方?也许有人猛然惊醒,密码这么重要的字段居然会从文件里读到了明文?赶紧找到示例代码中的磁盘文件user.txt,使用文本编辑软件如UEStudio打开user.txt,在该文件末尾附近赫然出现了六位数字密码111111,详见下图所示的右下角。
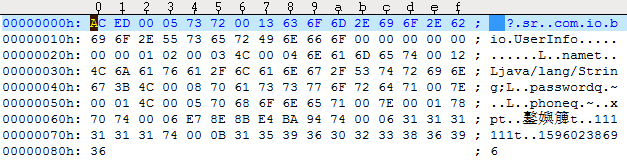
显然密码值不应保存在文件里面,尤其是光天化日之下也能看到的明文。可见对象序列化应当有所取舍,寻常字段允许序列化,而私密字段不允许序列化。为此Java新增了关键字transient,凡是被transient修饰的字段,会在序列化之时自动予以屏蔽,也就是说,序列化无法保存该字段的数值。如此一来,用户信息UserInfo的类定义需要把password密码字段的声明代码改成下面这样:
// 关键字transient可让它所修饰的字段无法序列化,也就是说,序列化无法保存该字段的数值
private transient String password; // 密码
给密码字段添加了transient修饰之后,重新运行对象数据读写代码,根据下列的日志信息可知密码值已经屏蔽了序列化:
对象序列化成功
对象反序列化成功
用户信息如下:姓名=王五,手机号=15960238696,密码=null
另外,UserInfo类后续可能会增加新的成员属性,比如整型的年龄字段。然而一旦在UserInfo的代码定义中增加了新字段,再去读取原先保存在文件中的序列化对象,程序运行时竟然扔出异常,提示“java.io.InvalidClassException: com.io.bio.UserInfo; local class incompatible: stream classdesc serialVersionUID = ***, local class serialVersionUID = ***”,意思是本地类不兼容,IO流中的序列化编码与本地类的序列化编码不一致。其中的缘由说来话长,对象的每次序列化都需要一个编码serialVersionUID,程序通过该编码来校验读到的对象是否为原先的对象类型,而默认的编码数值是根据类名、接口名、成员方法及成员属性等联合运算得到的哈希值,所以只要类名、接口名、方法与属性任何一项发生变更,都会导致serialVersionUID编码产生变化,进而影响正常的序列化和反序列化操作。
这个序列化编码的校验规则,像极了Java版本的刻舟求剑,每次序列化的小船出发之前,都要在落剑的船身处做个标记,表示刚才宝剑是在该位置掉进水里的。其后小船的状态发生了改变,譬如开到了河对岸,此时船员开始活动筋骨,准备在标记处跳下船,意图潜水寻回宝剑。结果当然是徒劳无功,根本找不到先前落水的宝剑,因为标记刻在船身上,它跟随着小船运动,水里的剑未动而船已动,按照移动后的标记去找留在原地的宝剑,自然是竹篮打水一场空了。正确的做法是记下固定不动的方位信息,例如详细的经纬度,这样无论船怎么开,落剑的位置都是不变的。如此一来,还需在UserInfo的定义代码中添加以下的serialVersionUID赋值语句,从一开始就设置固定的版本编码数值:
// 该类的实例在序列化时的版本编码
private static final long serialVersionUID = 1L;
总结一下,支持序列化的类定义与普通的类定义主要有下述三项区别:
1、可序列化的类实现了Serializable接口;
2、可序列化的类需要给serialVersionUID字段赋值,避免出现版本编码不一致的情况;
3、可序列化的类可能有部分字段被关键字transient所修饰,表示这些字段无需进行序列化;
最后整合上述的三点要求,重新修改用户信息的类定义,改后的UserInfo代码片段示例如下:
//定义一个可序列化的用户信息类。实现Serializable接口表示当前类支持序列化
public class UserInfo implements Serializable {
// 该类的实例在序列化时的版本编码
private static final long serialVersionUID = 1L; private String name; // 用户名
private String phone; // 手机号码
// 关键字transient可让它所修饰的字段无法序列化,也就是说,序列化无法保存该字段的数值
private transient String password; // 密码 public UserInfo() {
name = "";
phone = "";
password = "";
} // 以下省略各字段的get***/set***方法
}
更多Java技术文章参见《Java开发笔记(序)章节目录》
Java开发笔记(九十)对象序列化及其读写的更多相关文章
- java学习笔记之对象序列化
1.简述 java对象序列化就是将对象编程二进制数据流的一种方法,从而实现对对象的传输和存储 2.作用 java是门面向对象编程语言,即一切皆对象,但是java对象只能存在于jvm中,一旦jvm停掉那 ...
- Java开发笔记(八十七)随机访问文件的读写
前面介绍了字符流读写文件的两种方式,包括文件字符流和缓存字符流,但是它们的写操作都存在一个问题:不管是write方法还是append方法,都只能从文件开头写入,而不能追加到文件末尾或者在文件中间某个位 ...
- Java开发笔记(八十六)通过缓冲区读写文件
前面介绍了利用文件写入器和文件读取器来读写文件,因为FileWriter与FileReader读写的数据以字符为单位,所以这种读写文件的方式被称作“字符流I/O”,其中字母I代表输入Input,字母O ...
- Java开发笔记(八十五)通过字符流读写文件
前面介绍了文件的信息获取.管理操作,以及目录下的文件遍历,那么文件内部数据又是怎样读写的呢?这正是本文所要阐述的内容.File工具固然强大,但它并不能直接读写文件,而要借助于其它工具方能开展读写操作. ...
- Java开发笔记(九十四)文件通道的性能优势
前面介绍了字节缓存的一堆概念,可能有的朋友还来不及消化,虽然文件通道的用法比起传统I/O有所简化,可是平白多了个操控繁琐的字节缓存,分明比较传统I/O更加复杂了.尽管字节缓存享有缓存方面的性能优势,但 ...
- Java开发笔记(九十三)深入理解字节缓存
前面介绍了文件通道的读写操作,其中用到字节缓存ByteBuffer,它是位于通道内部的存储空间,也是通道唯一可用的存储形式.ByteBuffer有两种构建方式,一种是调用静态方法wrap,根据输入的字 ...
- Java开发笔记(九十二)文件通道的基本用法
前面介绍的各色流式IO在功能方面着实强大,处理文件的时候该具备的操作应有尽有,可流式IO在性能方面不尽如人意,它的设计原理使得实际运行效率偏低,为此从Java4开始增加了NIO技术,通过全新的架构体系 ...
- Java开发笔记(五十二)对象的类型检查
前面介绍了类的多态性,来自于鸡类的实例chicken,既能用来表达公鸡实例,也能用来表达母鸡实例.可是这导致了一个问题,假如在call方法内部需要手工判断输入参数属于公鸡实例还是母鸡实例,那该如何是好 ...
- Java开发笔记(九十六)线程的基本用法
每启动一个程序,操作系统的内存中通常会驻留该程序的一个进程,进程包含了程序的完整代码逻辑.一旦程序退出,进程也就随之结束:反之,一旦强行结束进程,程序也会跟着退出.普通的程序代码是从上往下执行的,遇到 ...
随机推荐
- git-------基础(一)
更改连接仓库只用操作一次(先删后加) (1)git remote rm origin //若本地已经关联了一个远程库,则先删除已关联的 ...
- UnicodeDecodeError: 'utf-8' codec can't decode byte 0xef in position 99: invalid continuation byte
Traceback (most recent call last): File "/Users/c2apple/PycharmProjects/easyToPython/fileMethod ...
- spring 切入点表达式
spring表达式有多种的指示符,如: 切入点指示符用来指示切入点表达式目的,,在Spring AOP中目前只有执行方法这一个连接点,Spring AOP支持的AspectJ切入点指示符如下: exe ...
- Tiny4412之重力感应器驱动
一:Tiny4412 裸板重力感应驱动编写 整个编写过程大概分为如下几步: (1)在底板上找到重力感应器的所在位置,找到芯片型号(我用的板子上重力感应器芯片型号为:MMA7660FC) (2)通过型号 ...
- java基础-学java util类库总结
JAVA基础 Util包介绍 学Java基础的工具类库java.util包.在这个包中,Java提供了一些实用的方法和数据结构.本章介绍Java的实用工具类库java.util包.在这个包中,Java ...
- Windows上设置Mozilla Thunderbird邮件客户端后台运行
作者:荒原之梦 操作系统: Windows 10 Thunderbird版本: 52.6.0(32-bit) Thunderbird官网页面:https://www.mozilla.org/zh-CN ...
- REST风格框架实战:从MVC到前后端分离(附完整Demo)
既然MVC模式这么好,难道它就没有不足的地方吗?我认为MVC至少有以下三点不足:(1)每次请求必须经过“控制器->模型->视图”这个流程,用户才能看到最终的展现的界面,这个过程似乎有些复杂 ...
- Ueditor 专题
https://github.com/xwjie/SpringBootUeditor 提交表单提交表单设置按照部署编辑器的教程,完成编辑器加载 把容器放到form表单里面,设置好要提交的路径,如下面代 ...
- Spring Boot + Websocket + Thymeleaf + Lombok
https://github.com/guillermoherrero/websocket 验证错误消息文件名字:是默认名ValidationMessages.properties,编译后存放在cla ...
- Spring Boot ConfigurationProperties validate
使用@Query可以在自定义的查询方法上使用@Query来指定该方法要执行的查询语句,比如:@Query("select o from UserModel o where o.uuid=?1 ...