回归算法比较(线性回归,Ridge回归,Lasso回归)
代码实现:
# -*- coding: utf-8 -*-
"""
Created on Mon Jul 16 09:08:09 2018 @author: zhen
""" from sklearn.linear_model import LinearRegression, Ridge, Lasso
import mglearn
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
# 线性回归
x, y = mglearn.datasets.load_extended_boston()
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0) linear_reg = LinearRegression()
lr = linear_reg.fit(x_train, y_train) print("lr.coef_:{}".format(lr.coef_)) # 斜率
print("lr.intercept_:{}".format(lr.intercept_)) # 截距 print("="*25+"线性回归"+"="*25)
print("Training set score:{:.2f}".format(lr.score(x_train, y_train)))
print("Rest set score:{:.2f}".format(lr.score(x_test, y_test))) """
总结:
训练集和测试集上的分数非常接近,这说明可能存在欠耦合。
训练集和测试集之间的显著性能差异是过拟合的明显标志。解决方式是使用岭回归!
"""
print("="*25+"岭回归(默认值1.0)"+"="*25)
# 岭回归
ridge = Ridge().fit(x_train, y_train) print("Training set score:{:.2f}".format(ridge.score(x_train, y_train)))
print("Test set score:{:.2f}".format(ridge.score(x_test, y_test))) print("="*25+"岭回归(alpha=10)"+"="*25)
# 岭回归
ridge_10 = Ridge(alpha=10).fit(x_train, y_train) print("Training set score:{:.2f}".format(ridge_10.score(x_train, y_train)))
print("Test set score:{:.2f}".format(ridge_10.score(x_test, y_test))) print("="*25+"岭回归(alpha=0.1)"+"="*25)
# 岭回归
ridge_01 = Ridge(alpha=0.1).fit(x_train, y_train) print("Training set score:{:.2f}".format(ridge_01.score(x_train, y_train)))
print("Test set score:{:.2f}".format(ridge_01.score(x_test, y_test))) # 可视化
fig = plt.figure(10)
plt.subplots_adjust(wspace =0, hspace =0.6)#调整子图间距
ax1 = plt.subplot(2, 1, 1) ax2 = plt.subplot(2, 1, 2) ax1.plot(ridge_01.coef_, 'v', label="Ridge alpha=0.1")
ax1.plot(ridge.coef_, 's', label="Ridge alpha=1")
ax1.plot(ridge_10.coef_, '^', label="Ridge alpha=10") ax1.plot(lr.coef_, 'o', label="LinearRegression") ax1.set_ylabel("Cofficient magnitude")
ax1.set_ylim(-25,25)
ax1.hlines(0, 0, len(lr.coef_))
ax1.legend(ncol=2, loc=(0.1, 1.05)) print("="*25+"Lasso回归(默认配置)"+"="*25)
lasso = Lasso().fit(x_train, y_train) print("Training set score:{:.2f}".format(lasso.score(x_train, y_train)))
print("Test set score:{:.2f}".format(lasso.score(x_test, y_test)))
print("Number of features used:{}".format(np.sum(lasso.coef_ != 0))) print("="*25+"Lasso回归(aplpha=0.01)"+"="*25)
lasso_001 = Lasso(alpha=0.01, max_iter=1000).fit(x_train, y_train) print("Training set score:{:.2f}".format(lasso_001.score(x_train, y_train)))
print("Test set score:{:.2f}".format(lasso_001.score(x_test, y_test)))
print("Number of features used:{}".format(np.sum(lasso_001.coef_ != 0))) print("="*15+"Lasso回归(aplpha=0.0001)太小可能会过拟合"+"="*15)
lasso_00001 = Lasso(alpha=0.0001, max_iter=1000).fit(x_train, y_train) print("Training set score:{:.2f}".format(lasso_00001.score(x_train, y_train)))
print("Test set score:{:.2f}".format(lasso_00001.score(x_test, y_test)))
print("Number of features used:{}".format(np.sum(lasso_00001.coef_ != 0))) # 可视化
ax2.plot(ridge_01.coef_, 'o', label="Ridge alpha=0.1")
ax2.plot(lasso.coef_, 's', label="lasso alpha=1")
ax2.plot(lasso_001.coef_, '^', label="lasso alpha=0.001")
ax2.plot(lasso_00001.coef_, 'v', label="lasso alpha=0.00001") ax2.set_ylabel("Cofficient magnitude")
ax2.set_xlabel("Coefficient index")
ax2.set_ylim(-25,25)
ax2.legend(ncol=2, loc=(0.1, 1))
结果:


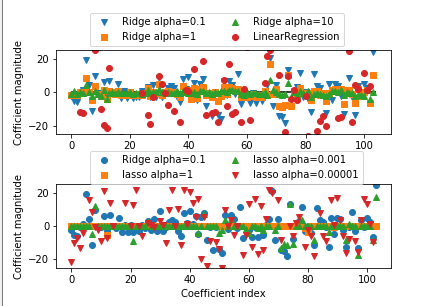
总结:各回归算法在相同的测试数据中表现差距很多,且算法内的配置参数调整对自身算法的效果影响也是巨大的,
因此合理挑选合适的算法和配置合适的配置参数是使用算法的关键!
回归算法比较(线性回归,Ridge回归,Lasso回归)的更多相关文章
- 线性回归大结局(岭(Ridge)、 Lasso回归原理、公式推导),你想要的这里都有
本文已参与「新人创作礼」活动,一起开启掘金创作之路. 线性模型简介 所谓线性模型就是通过数据的线性组合来拟合一个数据,比如对于一个数据 \(X\) \[X = (x_1, x_2, x_3, ..., ...
- Lasso回归算法: 坐标轴下降法与最小角回归法小结
前面的文章对线性回归做了一个小结,文章在这: 线性回归原理小结.里面对线程回归的正则化也做了一个初步的介绍.提到了线程回归的L2正则化-Ridge回归,以及线程回归的L1正则化-Lasso回归.但是对 ...
- 多元线性回归模型的特征压缩:岭回归和Lasso回归
多元线性回归模型中,如果所有特征一起上,容易造成过拟合使测试数据误差方差过大:因此减少不必要的特征,简化模型是减小方差的一个重要步骤.除了直接对特征筛选,来也可以进行特征压缩,减少某些不重要的特征系数 ...
- SparkMLlib学习分类算法之逻辑回归算法
SparkMLlib学习分类算法之逻辑回归算法 (一),逻辑回归算法的概念(参考网址:http://blog.csdn.net/sinat_33761963/article/details/51693 ...
- SparkMLlib分类算法之逻辑回归算法
SparkMLlib分类算法之逻辑回归算法 (一),逻辑回归算法的概念(参考网址:http://blog.csdn.net/sinat_33761963/article/details/5169383 ...
- LASSO回归与L1正则化 西瓜书
LASSO回归与L1正则化 西瓜书 2018年04月23日 19:29:57 BIT_666 阅读数 2968更多 分类专栏: 机器学习 机器学习数学原理 西瓜书 版权声明:本文为博主原创文章,遵 ...
- 线性回归——lasso回归和岭回归(ridge regression)
目录 线性回归--最小二乘 Lasso回归和岭回归 为什么 lasso 更容易使部分权重变为 0 而 ridge 不行? References 线性回归很简单,用线性函数拟合数据,用 mean squ ...
- Spark MLlib回归算法------线性回归、逻辑回归、SVM和ALS
Spark MLlib回归算法------线性回归.逻辑回归.SVM和ALS 1.线性回归: (1)模型的建立: 回归正则化方法(Lasso,Ridge和ElasticNet)在高维和数据集变量之间多 ...
- 【机器学习】正则化的线性回归 —— 岭回归与Lasso回归
注:正则化是用来防止过拟合的方法.在最开始学习机器学习的课程时,只是觉得这个方法就像某种魔法一样非常神奇的改变了模型的参数.但是一直也无法对其基本原理有一个透彻.直观的理解.直到最近再次接触到这个概念 ...
随机推荐
- .Net 事件总线之Autofac解耦
事件总线是通过一个中间服务,剥离了常规事件的发布与订阅(消费)强依赖关系的一种技术实现.事件总线的基础知识可参考圣杰的博客[事件总线知多少] 本片博客不再详细概述事件总线基础知识,核心点放置使用Aut ...
- NET 泛型,详细介绍
今天的文章是因为再给一个朋友讲这个的时候随手记录下整理出来的.说白了就是把前辈们曾经给我吹过的我又吹了出去. 泛型:是C# FrameWork 2.0 时代 加入进来的,可以说对与Net开发人员来说泛 ...
- Java-每日编程练习题①
1.输出打印一个九九乘法表 代码如下,很简单的一个for的嵌套循环即可实现 /** * 输出9*9口诀. * * @author ChenZX * */ public class Test01 { p ...
- java接口与抽象类
本片随笔讲讲java中接口与抽象类. 一,接口 1.什么是接口? 那在日常生活中接口是什么呢?就是两个对象之间进行连接的部分就是接口,就比如热水器与水管的接口一样,他可以确保不同的东西之间的顺利连接, ...
- 将展示内容(div、iframe)放在Expand控件中
Expand是ArcGIS JavaScript API 4.3推出的一个widget(控件),用于承载一个HTML DOM元素,可以把一个自己编写的div或者是一个其他的Esri widget控件放 ...
- Android-----Intent中通过startActivity(Intent intent )隐式启动新的Activity
显式Intent我已经简单使用过了,也介绍过概念,现在来说一说隐式Intent: 隐式Intent:就是只在Intent中设置要进行的动作,可以用setAction()和setData()来填入要执行 ...
- navicate for mysql之-Can't connect to MySQL server on 'localhost'(10038)
1. 卸载navicate for mysql 会留下很多坑,主要是卸载不干净,卸载之后重新安装会出现之前的库内容和库链接还存在的问题,这种情况的出现是卸载残余. 解决办法,清理注册表(网上很多教程但 ...
- Windows系统配置OutLook邮箱教程一
本示例演示Windows系统中OutLook邮箱设置 1.打开控制面板->类型选择小图标->找到Mail(Microsoft OutLook 2016). 2.鼠标左键双击Mail. 3. ...
- ReactiveSwift源码解析(三) Signal代码的基本实现
上篇博客我们详细的聊了ReactiveSwift源码中的Bag容器,详情请参见<ReactiveSwift源码解析之Bag容器>.本篇博客我们就来聊一下信号量,也就是Signal的的几种状 ...
- Golang之轻松化解defer的温柔陷阱
目录 什么是defer? 为什么需要defer? 怎样合理使用defer? defer进阶 defer的底层原理是什么? 利用defer原理 defer命令的拆解 defer语句的参数 闭包是什么? ...