深度学习之Batch Normalization
在机器学习领域中,有一个重要的假设:独立同分布假设,也就是假设训练数据和测试数据是满足相同分布的,否则在训练集上学习到的模型在测试集上的表现会比较差。而在深层神经网络的训练中,当中间神经层的前一层参数发生改变时,该层的输入分布也会发生改变,也就是存在内部协变量偏移问题(Internal Covariate Shift),从而造成神经层的梯度消失,模型收敛过慢的问题。
Batch Normalization(BN,批量标准化)就是一种解决内部协变量偏移问题的方法,它通过对神经网络的中间层进行逐层归一化,让每一个中间层输入的分布保持稳定,即保持同一分布。
下面从以下四个方面来深入理解Batch Normalization的原理。
1、内部协变量偏移问题
2、训练时的Batch Normalization
3、推断时的Batch Normalization
4、Batch Normalization的优点
一、内部协变量偏移问题
1、内部协变量偏移问题的产生
在传统机器学习中,一个常见的问题是协变量偏移(Covariate Shift),大致的意思就是数据会随着时间而变化,用旧数据训练好的模型去预测新数据时,结果可能会不准确。输入数据可以看做是协变量,机器学习算法要求输入数据在训练集和测试集上满足同分布,这样把模型用来预测新的数据,才能有较好的结果。

而深层神经网络中的内部协变量偏移(Internel Covarian Shift)可以拆分为“中间”和“协变量偏移”两部分来理解。中间二字指的是神经网络的中间层(隐藏层),协变量偏移则与传统机器学习中的概念类似。在深层神经网络中,中间层的输入也就是前一层的输出,前一层的参数变化会导致该中间层的输入(WU+b)的分布发生较大的差异。在用随机梯度下降来训练网络时,每次参数更新都会导致神经网络中间层的输入分布发生变化。这就会造成同一次迭代时中间层与中间层之间的输入分布不一致,在不同的迭代轮次中同一中间层的输入分布也发生变化。而这就是内部协变量偏移问题。
传统机器学习的协变量偏移问题是源于测试集与训练集中输入分布的不一致,而深层神经网络中的内部协变量偏移问题的含义稍有不同,是不同中间层的输入分布不一致。
那么内部协变量偏移问题又是如何导致梯度消失的呢?
2、内部协变量偏移导致梯度消失
我们换一种说法,深层神经网络在做非线性变换之前的输入值(WU+b)随着网络深度的加深,或者在每一轮迭代中,其分布逐渐发生变动,一般是整体分布逐渐往非线性激活函数的y值区间的上下限两端靠近,从而导致反向传播时底层神经网络的梯度消失,从而使得神经网络收敛得越来越慢。
以sigmoid激活函数来举例,sigmoid函数是个两端饱和函数,也就是输入值(WU+b)是非常大的负值或者非常大的正值时,其导数会接近于0;而当输入值在0附近时,sigmoid函数近似于一个线性函数,导数在0.25以下,但远离0值。下面是sigmoid函数的导数。
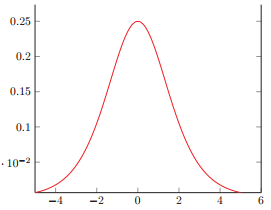
首先假设输入值的分布在没有发生改变之前服从标准正态分布,即均值为0,方差为1,那么由概率论的知识可以得到,有95%的概率这个输入值落在[-2,2]的范围内,也就是sigmoid函数接近于线性变换的区域,从上图中目测(简陋点哈哈)导数在(0.1, 0.25)的范围内,因此不会发生梯度消失问题。
然后如果输入值的分布发生了偏移,服从均值为-6,方差为1的正态分布,那么有95%的概率输入值落在[-8, -4]的区间中(均值加减两倍方差),从上图可以看到,sigmoid函数的导数在这个区间上明显趋近于0,也就是落在了梯度饱和区。那么梯度变化就会很小乃至消失。
同样,如果输入值的分布偏移到正态分布的右边,比如服从均值为6,方差为1的正态分布,则sigmoid函数的值接近于1,同样其导数值也趋近于0。
好,明白了内部协变量偏移会导致梯度消失的原理,并且明白了如果输入值的分布满足均值为0,方差为1的条件,那么就可以比较好地解决梯度消失问题,那么一个当然的想法就是,对神经网络的每一个中间层进行标准归一化,把每一个中间层的输入值强行从越来越偏的画风中拉回到又红又专的状态(均值为0,方差为1的标准分布) ,使得输入值落在非线性函数对输入比较敏感的区域。这样就能让梯度保持在比较大的水平,加快学习和收敛的速度。
二、训练时的Batch Normalization
先声夺人,首先说明四点:
第一点是Batch Normalization是基于小批量随机梯度下降(Mini-Batch SGB)的;
第二点是Batch Normalization是放在激活函数之前,可以视为一层;
第三点是Batch Normalization在标准归一化之后,减弱了神经网络的非线性表示,需要附加缩放和平移来变换取值区间;
第四点是由于附加了平移变换(加上一个常数),相当于给神经层加了偏置,因此标准归一化之前的输入值不用再加偏置(本来是WU+b,现在只要WU就行)。
那么,接下来慢慢说明。
1、标准归一化
对每个中间层的神经元的输入值做BN,可以视为在每个中间层之前加上了一个BN层,它位于计算输入值WU(第三点说明了这里不加偏置)之后,进行非线性变换之前。

用小批量梯度下降来训练神经网络,假设batch size是m,在第t层的输入值x=WU的维度是d,也就是一个输入值表示为x = (x(1), x(2),..., x(d)),那么首先对x的每一个维度的值都进行标准归一化:

这个标准归一化的含义是:第t层中第k个神经元(即x的第k个维度)的输入值,减去m个样本在该层的输入值第k个维度的均值E(xk),并且除以其标准差(Var(xk)开方)来进行转换。
要注意的是,本来E(xk)和Var(xk)表示x的第k维度在整个数据集上的期望和方差,可是由于是使用小批量梯度下降算法,所以用m个样本在第k维度的均值和方差来估计。计算的方程如下:
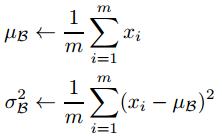
2、缩放和平移变换
对输入值x进行标准归一化会使得取值集中在0附近,如果使用sigmoid函数或者tanh激活函数,那么这个取值区间刚好是接近线性变换的区间,这会减弱非线性激活函数的表示能力。因此,为了不让标准归一化对网络的表示能力产生不良影响,就需要附加缩放(scale)和平移(shift)变换来改变标准归一化后值的区间,在一定程度上恢复网络的非线性表示能力。那么每个神经元就会增加两个调节参数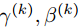 ,分别用来进行缩放和平移操作,可以通过训练来学习这两个参数。
,分别用来进行缩放和平移操作,可以通过训练来学习这两个参数。
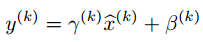
有意思的是,这个缩放和平移变换其实是标准归一化的反向操作,当缩放参数为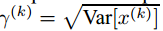 ,平移参数为
,平移参数为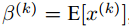 时,可以把值恢复到标准归一化之前的值x。
时,可以把值恢复到标准归一化之前的值x。
还要因为标准归一化后加了平移变换,相当于在计算输入值时加了偏置,因此在进行标准归一化之前的输入值不需要再加偏置,也就是输入值为WU,而不是WU+b。
那么Batch Normalization的算法流程如下:

当然,得到这个BN操作之后的值yi,后面该干嘛干嘛,把它输入到非线性激活函数中得到该中间层的输出。
三、推断时的Batch Normalization
运用Batch Normalization对输入值进行调整的深层神经网络,在训练阶段,是用小批量梯度下降来进行优化的,也就是每轮迭代都把batch size 个样本喂给模型,通过计算这若干个样本的均值和方差,来进行BN操作。那么在推断(Inference,我觉得测试和预测都算推断吧)阶段,每次只输入一个样本,没有多个样本可以求均值和方差,那么如何对输入值做Batch Normalization呢?
也比较简单,因为幸运的是此时模型已经训练完毕了,那我们可以用整个数据集上的均值μ和方差σ来代替每次小批量样本的均值和方差,然后在推断阶段就使用这两个全局统计量来进行BN操作。
那整个数据集上的均值和方差如何得到呢?这样做,在小批量梯度下降的每轮迭代中,都会输入batch size 个样本,然后得到这些样本的均值和方差,那么每次都把这些样本的均值和方差记录下来。整个数据集都迭代完毕后,再对得到的所有均值和方差求数学期望,就可以得到全局的均值和方差:

用全局的均值和方差来进行标准归一化,就完成了BN操作的第一步。
那么还有第二步啊,对标准归一化后的输入值进行缩放和平移变换。由于在训练阶段结束后,中间层中每个神经元对应的缩放参数γ和平移参数β都已经求出来了,那么就可以直接用来进行变换。由于在推断阶段,无论是样本的均值和方差,还是缩放参数和平移参数都已经是常数了,不再变化了,那么为了计算更快速,就把标准归一化和缩放、平移变换这两步的参数整合到一起,存放起来,当输入新样本时,直接调用就好了。这也就是把公式进行了以下变换:
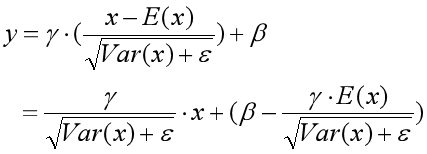
四、Batch Normalization的优点
1、通过标准归一化,使得输入值的均值为0,方差为1,而不是绝对值非常大的数,就可以大大提升训练速度,加快模型收敛。
2、带有轻微的正则化效果,与Dropout类似。Dropout通过给隐藏层的神经元以一定的概率乘以0或者1,而给隐藏层的激活值增加了噪音。相比之下,BN操作通过对输入值减去均值和进行缩放,也给隐藏层的神经元添加了轻微的噪音。
3、使得调参过程简单了不少。使用梯度下降法对参数进行优化学习时,非常关键的一个问题是如何合理地初始化参数值,为此提出了Xavier初始化和He初始化等方法,而使用BN操作后,对于参数初始化的要求就没那么高了。而且也可以使用大的学习率。
4、使用饱和型激活函数,比如sigmoid函数和tanh函数,也不怕出现梯度消失问题了。
一句话,妈妈再也不用担心我在训练神经网络时出现梯度消失问题啦!
以上这句话是假的,还需要配合其他方法,来得到更好的效果。
参考资料:
1、邱锡鹏:《神经网络与深度学习》
2、深入理解Batch Normalization批标准化
https://i.cnblogs.com/EditPosts.aspx?postid=10756382
3、《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift 》
https://arxiv.org/pdf/1502.03167.pdf
深度学习之Batch Normalization的更多相关文章
- 深度学习中 Batch Normalization
深度学习中 Batch Normalization为什么效果好?(知乎) https://www.zhihu.com/question/38102762
- 深度学习中 Batch Normalization为什么效果好
看mnist数据集上其他人的CNN模型时了解到了Batch Normalization 这种操作.效果还不错,至少对于训练速度提升了很多. batch normalization的做法是把数据转换为0 ...
- 深度学习中batch normalization
目录 1 Batch Normalization笔记 1.1 引包 1.2 构建模型: 1.3 构建训练函数 1.4 结论 Batch Normalization笔记 我们将会用MNIST数 ...
- zz详解深度学习中的Normalization,BN/LN/WN
详解深度学习中的Normalization,BN/LN/WN 讲得是相当之透彻清晰了 深度神经网络模型训练之难众所周知,其中一个重要的现象就是 Internal Covariate Shift. Ba ...
- 深度学习中的Normalization模型
Batch Normalization(简称 BN)自从提出之后,因为效果特别好,很快被作为深度学习的标准工具应用在了各种场合.BN 大法虽然好,但是也存在一些局限和问题,诸如当 BatchSize ...
- [优化]深度学习中的 Normalization 模型
来源:https://www.chainnews.com/articles/504060702149.htm 机器之心专栏 作者:张俊林 Batch Normalization (简称 BN)自从提出 ...
- 深度学习之Batch归一化
前言 以下内容是个人学习之后的感悟,转载请注明出处~ Batch归一化 在神经网络中,我们常常会遇到梯度消失的情况,比如下图中的sigmod激活函数,当离零点很远时,梯度基本为0 ...
- 关于深度学习之中Batch Size的一点理解(待更新)
batch 概念:训练时候一批一批的进行正向推导和反向传播.一批计算一次loss mini batch:不去计算这个batch下所有的iter,仅计算一部分iter的loss平均值代替所有的. 以下来 ...
- 算法工程师<深度学习基础>
<深度学习基础> 卷积神经网络,循环神经网络,LSTM与GRU,梯度消失与梯度爆炸,激活函数,防止过拟合的方法,dropout,batch normalization,各类经典的网络结构, ...
随机推荐
- Centos 7安装python3
纯傻瓜式步骤,保证成功. 下面的操作,按照步骤来就可以了,不要在中途cd 到别的文件目录下,要想查看效果可以用 lsj加上对应的目录,不需要切换进去. 首先不管你当前在哪个目录下,输入以下命令. [r ...
- ThinkPHP5从零基础搭建CMS系统(一)
了解学习thinkphp5应该是2016年年底的事情,当时还没有接触过thinkphp3版本,觉得通过手册直接上手学习tp5蛮轻松的,现在从零记录下,搭建可扩展的CMS. 1.ThinkPHP环境搭建 ...
- Effective Java 第三版——41.使用标记接口定义类型
Tips <Effective Java, Third Edition>一书英文版已经出版,这本书的第二版想必很多人都读过,号称Java四大名著之一,不过第二版2009年出版,到现在已经将 ...
- 分布式服务通讯框架XXL-RPC
<分布式服务通讯框架XXL-RPC> 一.简介 1.1 概述 XXL-RPC 是一个分布式服务通讯框架,提供稳定高性能的RPC远程服务调用功能.现已开放源代码,开箱即用. 1.2 特 ...
- java基础- Collection和map
使用构造方法时,需要保留一个无参的构造方法 静态方法可以直接通过类名来访问,而不用创建对象. -- Java代码的执行顺序: 静态变量初始化→静态代码块→初始化静态方法→初始化实例变量→代码块→构造方 ...
- 语音识别中的CTC算法的基本原理解释
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文作者:罗冬日 目前主流的语音识别都大致分为特征提取,声学模型,语音模型几个部分.目前结合神经网络的端到端的声学模型训练方法主要CTC和基 ...
- 微信小程序开发入门:10分钟从0开始写一个hello-world
小程序开发需要三个描述整体程序的app文件 和 一个描述多个页面的 pages文件夹. (1)三个app文件分别是app.js,app.json,app.wxss. app.js文件是脚本文件处理一些 ...
- linux timerfd系列函数总结
网上关于timerfd的文章很多,在这儿归纳总结一下方便以后使用,顺便贴出一个timerfd配合epoll使用的简单例子 一.timerfd系列函数 timerfd是Linux为用户程序提供的一个定时 ...
- Socket TCP/UDP
TCP TCPClient package com.tcp; import java.io.*; import java.net.*; class TCPClient { public static ...
- 利用AOP实现SqlSugar自动事务
先看一下效果,带接口层的三层架构: BL层: public class StudentBL : IStudentService { private ILogger mLogger; private r ...