R语言-推荐系统
一.概述
目的:使用推荐系统可以给用户推荐更好的商品和服务,使得产品的利润更高
算法:协同过滤
协同过滤是推荐系统最常见的算法之一,算法适用用户过去的购买记录和偏好进行推荐
基于商品的协同过滤(IBCF计算每个商品之间的相似度矩阵):
1.任意两个商品计算相似度
2.每一个商品找出其k个最相似的商品
3.每一个用户找出那些商品与其之前购买的商品最接近的商品
基于用户的协同过滤(UBCF计算用户之间的相似度矩阵):
1.计算每个用户与用户之间的相似度,通常使用皮尔森相关系数和余弦距离
2.找出最相近的用户(KNN)
3.把新用户最相似的用户所购买的商品进行排名
4.基于相似性矩阵选出n个推荐的商品
二.案例
案例1:基于电影数据集的推荐(IBCF)
1.1导入包
library(reshape2)
library(ggplot2)
library(countrycode)
library(recommenderlab)
1.2查看数据集
data("MovieLense")
dim(MovieLense)
str(MovieLense)
head(MovieLense@data)

结论:该数据集是一个稀疏矩阵,每一行是观众对每部电影的打分,每一列是电影,一共有943观众,1664部电影
1.3找到评分大于0的电影
vector_rating <- as.vector(MovieLense@data)
table_rating <- table(vector_rating) #查看非0的评分
vector_rating <- vector_rating[vector_rating!=0]
vector_rating <- factor(vector_rating)
qplot(vector_rating) + ggtitle('Distribution of the ratings')
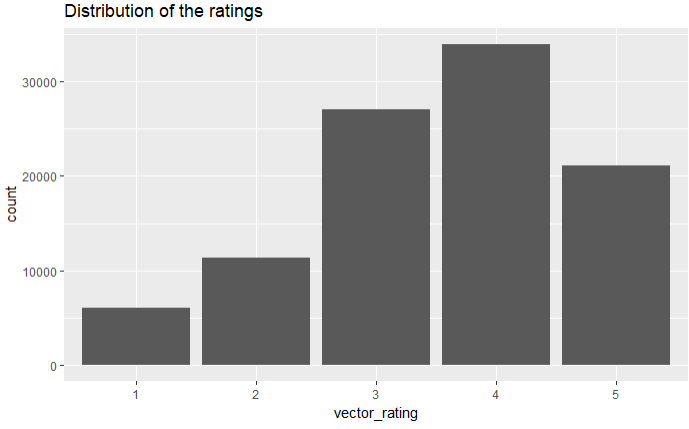
结论:3,4分的电影比较多
1.4找到被评分较多的电影和打分比较多的观众
#找到评分比较多的电影和打分比较多的用户
rating_moives <- MovieLense[rowCounts(MovieLense) > 50,colCounts(MovieLense) > 100]
dim(rating_moives)
结论:只有560部电影和322位观众符合条件
1.5划分数据集
#80%位训练集,20%位测试集
which_train <- sample(x=c(T,F),size = nrow(rating_moives),replace = T,prob = c(0.8,0.2))
recc_data_train <- rating_moives[which_train,]
recc_data_test <- rating_moives[!which_train,]
1.6建立推荐模型
#IBCF是基于商品的推荐
recc_model=Recommender(data = recc_data_train,method="IBCF")
1.7查看模型
model_detail <- getModel(recc_model)
model_detail$description
str(model_detail) dim(model_detail$sim)
n_items_top <- 20
image(model_detail$sim[1:n_items_top,1:n_items_top],main = "Heatmap of the first rows and columns")
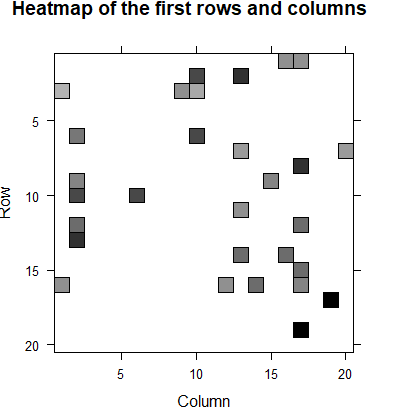
结论:从相似性矩阵中抽取20*20的数据进行热图展示,颜色越深的电影相关性越大
1.8使用模型进行推荐
#定义推荐的个数
n_recommended <- 6
recc_predicted <- predict(object = recc_model,newdata=recc_data_test,n=n_recommended)
recc_user_1 <- recc_predicted@items[[1]]
moive_user_1 <- recc_predicted@itemLabels[recc_user_1]
#查看第一个用户的推荐结果
moive_user_1

使用基于用户的电影推荐(UBCF)
1.9建立基于用户的模型
recommender_models <- recommenderRegistry$get_entries(dataType ="realRatingMatrix")
1.10查看参数
recommender_models$UBCF_realRatingMatrix$parameters

结论:使用cosine来计算每个用户的相似性
1.11建立相关性矩阵
recc_model_UBCF = Recommender(data = recc_data_train,method='UBCF',
param=list(normalize='Z-score',nn=5,method='Cosine'))
model_detail_UBCF <- getModel(recc_model_UBCF)
names(model_detail_UBCF)
model_detail_UBCF$dat

结论:模型的参数
1.12使用模型进行推荐
recc_predicted_UBCF <- predict(object = recc_model_UBCF,newdata=recc_data_test,n=n_recommended)
1.13查看推荐的结果
recc_martix <- sapply(recc_predicted_UBCF@items, function(x){
colnames(rating_moives[x])
})
dim(recc_martix)
recc_martix[,1:4]
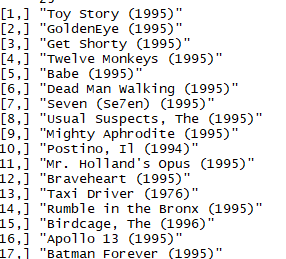
结论:根据用户进行推荐的结果
对二进制的数据进行建模(一般应用于网页的商品推荐)
## 基于商品的建模 recc_model=Recommender(recc_data_train,method="IBCF", param=list(method="Jaccard"))
model_details <- getModel(recc_model)
###定义推荐个数
n_recommended <- 6
recc_predicted <- predict(object = recc_model, newdata = recc_data_test, n = n_recommended)
recc_matrix <- sapply(recc_predicted@items, function(x){
colnames(ratings_movies)[x]
}) recc_matrix[, 1:4] ###UBCF
##基于用户的建模
recc_model=Recommender(recc_data_train,method="UBCF", param=list(method="Jaccard"))
model_details <- getModel(recc_model) n_recommended <- 6
recc_predicted <- predict(object = recc_model, newdata = recc_data_test,n = n_recommended)
recc_matrix <- sapply(recc_predicted@items, function(x){
colnames(ratings_movies)[x]
})
dim(recc_matrix) recc_matrix[, 1:4]


IBCF UBCF
使用 k-fold对模型进行验证
1.14使用交叉验证
eval_set <- evaluationScheme(data=rating_moives,method='cross-validation',k=4,given=15,goodRating=3)
# 不同类型的模型和随机推荐进行比较
models_to_evaluate <- list(
IBCF_cos = list(name='IBCF',param=list(method='cosine')),
IBCF_cor = list(name='IBCF',param=list(method='pearson')),
UBCF_cos = list(name='UBCF',param=list(method='cosine')),
UBCF_cor = list(name='UBCF',param=list(method='pearson')),
random = list(name='Random',param=NULL)
)
1.15作图比较
##定义推荐电影的个数
n_recommendations <- c(1, 5, seq(10, 100, 10)) ##开始建模
list_results <- evaluate(x = eval_sets, method = models_to_evaluate, n
= n_recommendations) ### plot #通过做图查看模型差异 plot(list_results, annotate = 1, legend = "topleft") title("ROC curve")

结论:使用基于用户的皮尔森作为推荐的模型是最优的
1.16对参数进行优化
# 参数优化
vector_k <- c(5, 10, 20, 30, 40) models_to_evaluate <- lapply(vector_k, function(k){
list(name = "IBCF", param = list(method = "cosine", k = k))
}) names(models_to_evaluate) <- paste0("IBCF_k_", vector_k) n_recommendations <- c(1, 5, seq(10, 100, 10))
list_results <- evaluate(x = eval_set, method = models_to_evaluate, n
= n_recommendations) par(mar=c(1.1 ,1.1, 1.1, 1.1)) plot(list_results, annotate = 1, legend = "topleft")
title("ROC curve")
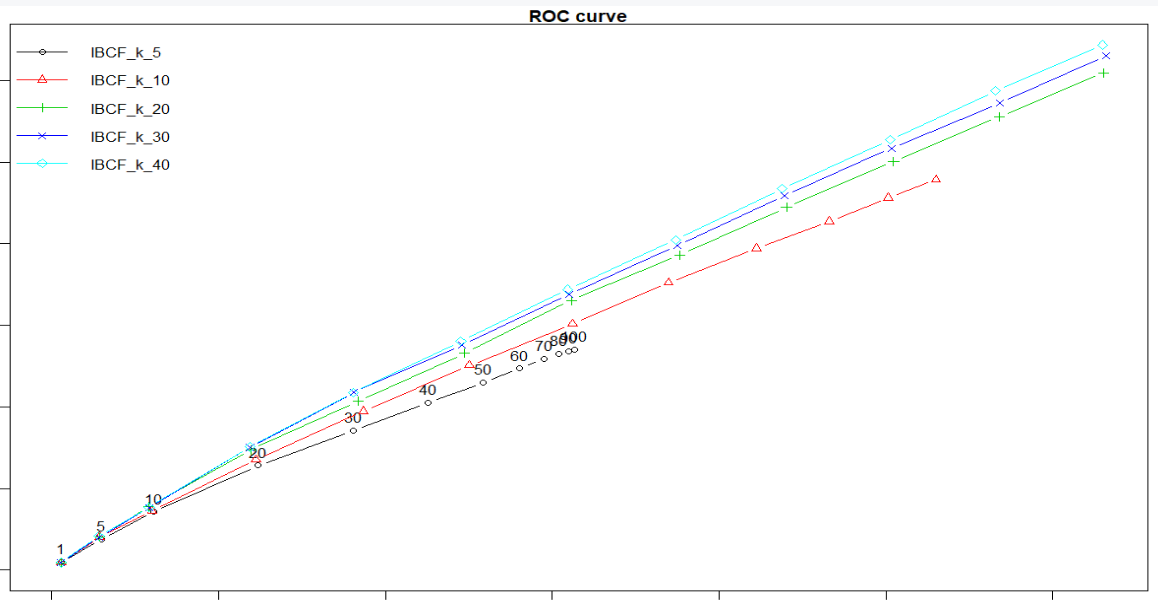
结论:基于商品的推荐模式下,每个用户推荐30部是最优策略
案例2基于网页的推荐(用户没有对网页评分,是根据用户点击浏览网页来获取用户的行为作为推荐的依据)
2.1导入包
library(data.table)
library(reshape2)
library(ggplot2)
library(countrycode)
library(recommenderlab)
2.2查看并清洗数据集
web_data <- read.csv('E:\\Udacity\\Data Analysis High\\R\\R_Study\\高级课程代码\\数据集\\第二天\\5推荐系统\\anonymous-msweb.test.txt',header=FALSE)
head(web_data)
#选择前两列
table_users <- web_data[, 1:2]
##定义成data frame
table_users <- data.table(table_users)
#定义列名称
setnames(table_users, 1:2, c("category", "value"))
table_users <- table_users[category %in% c("C", "V")]
head(table_users)


结论:
1.该数据集一共有20492个对象,每个对象有6列
2.该数据集的前两列C的value表示用户ID,V的value表示用户访问的网页ID
2.3将数据表转化成宽表
#每遇到一个新用户则chunk user +1
table_users[, chunk_user := cumsum(category == "C")]
head(table_users)
tail(table_users) ### 把user 和item 分成两列
table_long <- table_users[, list(user = value[1], item = value[-1]), by ="chunk_user"]
head(table_long) ### long to wide 长表变宽表
table_long[, value := 1]
table_wide <- reshape(data = table_long,
direction = "wide",
idvar = "user",
timevar = "item",
v.names = "value")
head(table_wide[, 1:8, with = FALSE])
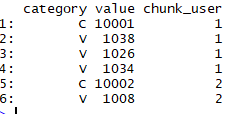
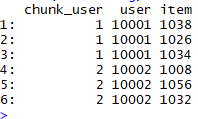

step1 step2 step3
2.4将宽表的列名进行修正(第一列是用户id,之后的每一列是Item id,每一个值是代表用户是否访问过该页面)
# 保存用户的id
vector_users <- table_wide[,user]
# 从数据集删除用户ID和chunk_user
table_wide[, user := NULL]
table_wide[, chunk_user := NULL] ##对列名称进行修正,只取前7个字符
setnames(x = table_wide,
old = names(table_wide),
new = substring(names(table_wide),7)) # 添加行名称,并转化成矩阵
matrix_wide <- as.matrix(table_wide)
rownames(matrix_wide) <- vector_users
head(matrix_wide[,1:6])

2.5画出相关性热力图
# 转换成二进制矩阵
matrix_wide[is.na(matrix_wide)] <- 0
ratings_matrix <- as(matrix_wide, "binaryRatingMatrix") image(ratings_matrix[1:50, 1:50], main = "Binary rating matrix")

2.6获取其他的信息
# 如果有一些网页,在五千个人中访问不超过5的,则删掉
ratings_matrix <- ratings_matrix[, colCounts(ratings_matrix) >= 5]
# 如果有一些用户,在网页中点评数量少于5个则删除
ratings_matrix <- ratings_matrix[rowCounts(ratings_matrix) >= 5, ]
# 获取描述信息
table_in <- data.table(table_in)
table_items <- table_in[V1 == "A"]
head(table_items)
# 修改列名
table_items <- table_items[,c(2,4,5),with=F]
setnames(table_items,1:3,c('id','description','url'))
table_items <- table_items[order(id)]
# 新增一列category,默认是product,如果描述在country_code中则category改为region
table_items[,category := 'product']
name_countries <-c(countrycode_data$country.name)
table_items[description %in% name_countries, category := "region"] table_items[, list(n_items = .N), by = category]

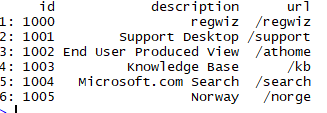

step1 step2 step3
2.7划分数据集
which_train <- sample(x=c(T,F),
size = nrow(ratings_matrix),
replace = T,
prob = c(0.8,0.2)
)
recc_data_train <- ratings_matrix[which_train,]
recc_data_test <- ratings_matrix[!which_train,]
2.8基于商品的推荐模型
web_model <- Recommender(data=recc_data_train,method='IBCF',parameter=list(method='Jaccard'))

2.9计算相似性矩阵
## item 的相似性矩阵(评分矩阵)
dist_ratings <- as(web_model@model$sim, "matrix") ## item category的相似性矩阵(商品之间的相似性矩阵)
dist_category <- table_items[, 1 - dist(category == "product")]
dist_category <- as(dist_category, "matrix") dim(dist_category)
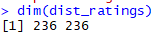
dim(dist_ratings)
## 给dist_category矩阵添加行名和列名
rownames(dist_category) <- table_items[, id]
colnames(dist_category) <- table_items[, id] ## 给dist_category矩阵抽取dist_ratings的长度,两个矩阵的大小要一致
vector_items <- rownames(dist_ratings)
dist_category <- dist_category[vector_items, vector_items]
dim(dist_category)

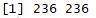
step1 step2
2.10使用模型进行预测
## category matrix 包含信息较少,所以只给0.25的权重
weight_catrgory <- 0.25
dist_tot <- dist_category * weight_catrgory + dist_ratings * (1-weight_catrgory)
## 转换成相似性矩阵
web_model@model$sim <- as(dist_tot,'dgCMatrix')
## 设定推荐的个数
n_recommend <- 10
web_predict <- predict(object = web_model,newdata=recc_data_test,n=n_recommend)
head(web_predict@itemLabels,10)
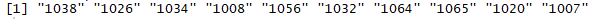
结论:该用户最想看到的10个网站的ID
总结:
1.了解业务需求
2.载入包
3.清洗并转换数据集
4.拆分数据集
5.建立IBCF模型,如果两个网站被相同用户访问的越多,其相似度越大
6.使用对网站的描述建立描述相似性矩阵,如果是相同的类型则为1,否则是0
7.对两个相似性矩阵进行加权平均
8.使用模型进行预测
数据集:https://github.com/Mounment/R-Project
R语言-推荐系统的更多相关文章
- R语言实战实现基于用户的简单的推荐系统(数量较少)
R语言实战实现基于用户的简单的推荐系统(数量较少) a<-c(1,1,1,1,2,2,2,2,3,3,3,4,4,4,5,5,5,5,6,6,7,7) b<-c(1,2,3,4,2,3,4 ...
- R语言书籍的学习路线图
现在对R感兴趣的人越来越多,很多人都想快速的掌握R语言,然而,由于目前大部分高校都没有开设R语言课程,这就导致很多人不知道如何着手学习R语言. 对于初学R语言的人,最常见的方式是:遇到不会的地方,就跑 ...
- R 语言的优劣势是什么?
R 语言的优劣势是什么? 2015-05-27 程序员 大数据小分析 R,不仅仅是一种语言 本文原载于<程序员>杂志2010年第8期,因篇幅所限,有所删减,这里刊登的是全文. 工欲善其 ...
- R语言︱SNA-社会关系网络—igraph包(社群划分、画图)(三)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 社群划分跟聚类差不多,参照<R语言与网站 ...
- 协同过滤的R语言实现及改进
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 协同过滤算法是推荐系统最常用的算法之一,本文将介绍一种方法来使它可以在大型数据集上快速训练. 协同过滤算法(CF)是构建推荐系统时最常用的技 ...
- R语言 一套内容 从入门 到放弃
[怪毛匠子整理] 1.下载 wget http://mirror.bjtu.edu.cn/cran/src/base/R-3/R-3.0.1.tar.gz 2.解压: tar -zxvf R-3.0. ...
- R语言:recommenderlab包的总结与应用案例
R语言:recommenderlab包的总结与应用案例 1. 推荐系统:recommenderlab包整体思路 recommenderlab包提供了一个可以用评分数据和0-1数据来发展和测试推荐算 ...
- R语言学习笔记—K近邻算法
K近邻算法(KNN)是指一个样本如果在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.即每个样本都可以用它最接近的k个邻居来代表.KNN算法适 ...
- R语言rvest包网络爬虫
R语言网络爬虫初学者指南(使用rvest包) 钱亦欣 发表于 今年 06-04 14:50 5228 阅读 作者 SAURAV KAUSHIK 译者 钱亦欣 引言 网上的数据和信息无穷无尽,如 ...
随机推荐
- Java .classpath文件Classpath entry org.maven.eclipse.MAVEN2_CLASSPATH_CONTAINER will not be exported or published异常解决办法
在实际用Maven构建Java Web项目开发过程中,有时候会出现上述情况的警告,如果不解决这个警告,就会在启动Web服务器的时候抛出无法加载Maven管理的第三方jar包的异常. 所以,要解决上面的 ...
- ubuntu,kali linux和windows三系统流水账——写给自己
我先说一下ubuntu和windows双系统安装的几种方法,最后总结kali linux的安装,想起什么写什么,所以有点乱.然后记录一下自己的使用过程中遇见的问题和解决的方法,还有我的个人建议. 我个 ...
- object转字符串
1.obj.tostring() obj为空时,抛异常. 2.convert.tostring(obj) obj为空时,返回null: 3.(string)obj obj为空时,返回null:obj不 ...
- MySQL的奇怪的删表数据文件而表照样能打开
MySQL的奇怪的删表数据文件而表照样能打开 author:headsen chen 2017-11-02 17:57:17 现象:删除一个正在运行的mysql数据库的表的数据文件:* ...
- 数字不断递增 可控制js
(function($){ $.fn.numberRock=function(options){ var defaults={ speed:, count: }; var opts=$.extend( ...
- NGINX压力测试
目录 1 硬件配置 3 1.1 型号 3 1.2 CPU 3 1.3 内存 3 2 软件环境 3 2.1 操作系统 3 2.2 ...
- Xcode9的xib只支持iOS7.0及以上版本
Xcode升级到9以后,对xib的最低编译版本有了限制,以前未指定版本的xib会报错,如下 遇到这个情况,根据错误提示很明显提示的是ib文件支持的最低版本是iOS7,所以我就将该xib的版本设为iOS ...
- poj-1146 ID codes
Description It is 2084 and the year of Big Brother has finally arrived, albeit a century late. In or ...
- Redis --> Ubuntu安装redis
Ubuntu安装redis 一.下载安装 root@21ebdf03a086:/# apt-cache search redis root@21ebdf03a086:/# apt-get inst ...
- Algorithm --> 棋盘中求出A到B的最小步数
求出A到B的最小步数 给定象棋盘,以及位置A和B, 求出从A到B的最小步数 代码: #include <cstdio> #include <iostream> #include ...