排序算法的C语言实现(下 线性时间排序:计数排序与基数排序)
计数排序
计数排序是一种高效的线性排序。
它通过计算一个集合中元素出现的次数来确定集合如何排序。不同于插入排序、快速排序等基于元素比较的排序,计数排序是不需要进行元素比较的,而且它的运行效率要比效率为O(nlgn)的比较排序高。
计数排序有一定的局限性,其中最大的局限就是它只能用于整型或那么可以用整型来表示的数据集合。原因是计数排序利用一个数据的索引来记录元素出现的次数,而这个数组的索引就是元素的数值。例如,如果整数3出现过4次,那么4将存储到数组索引为3的位置上。同时,我们还需要知道集合中最大整数的值,以便于为数组分配足够的空间。
除了速度之外,计数排序的另一个优点就是非常稳定。稳定的排序能使具有相同数值的元素具有相同的顺序,就像它们在原始集合中表现出来的一样。在某些情况下这是一个重要的特性,可以在基数排序中看到这一点。
计数排序的接口定义
ctsort
int ctsort(int *data, int size, int k);
返回值:如果排序成功,返回0;否则,返回-1;
描述: 利用计数排序将数组data中的整数进行排序。data中的元素个数由size决定。参数k为data中最大的整数加1。当ctsort返回时,data中包含已经排序的元素。
复杂度:O(n+k),n为要排序的元素个数,k为data中最大的整数加1。
计数排序的实现与分析
计数排序本质上是通过计算无序集合中整数出现的次数来决定集合应该如何排序的。
在以下说明的实现方法中,data初始包含size个无序整型元素,并存放在单块连续的存储空间中。另外需要分配存储空间来临时存放已经排序的元素。在ctsort返回时,得到的有序集合将拷贝加data。
分配了存储空间以后,首先计算data中每个元素出现的次数。这些结果将存储到计数数组counts中,并且数组的索引值就是元素本身。一旦data中每个元素的出现次数都统计出来后,就要调整计数值,使元素在进入有序集合之前,清楚每个元素插入的次数。用元素本身的次数加上它前一个元素的次数。事实上,此时counts包含每个元素在有序集合temp中的偏移量。
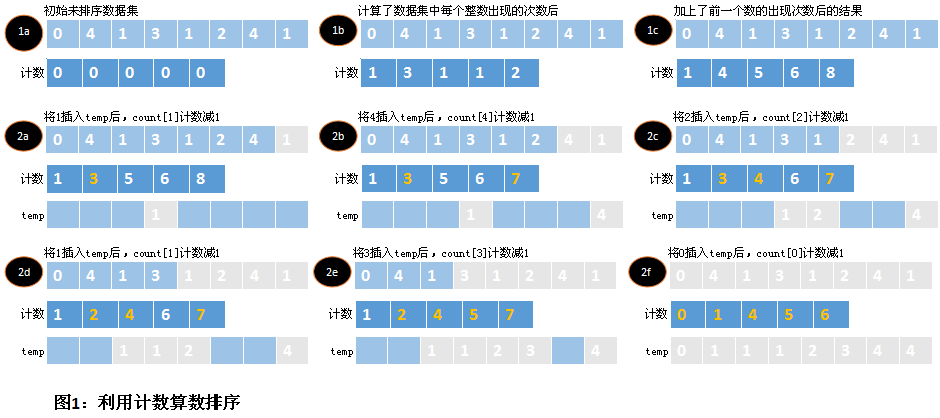
要完成排序,还必须按照元素在temp中的偏移量放置元素。当temp更新时,每个元素的计数要减1,这样,在data中出现不止一次的元素在temp中也会出现不止一次,这样保持同步。
计数排序的时间复杂度为O(n+k),其中n为要排序的元素个数,k为data中最大的整数加1。这是由于计数排序包含三个循环,其中两个的运行时间正比于n,另一个的运行时间正比于k。对于空间上来说,计数排序需要两个大小为n的数组,一个大小为k的数组。
示例:计数排序的实现
/*ctsort.c*/
#include <stdlib.h>
#include <string.h>
#include "sort.h" /*ctsort 计数排序函数*/
int ctsort(int *data, int size, int k)
{
int *counts,
*temp; int i,j; /*为计数器数组分配空间*/
if((counts = (int *)malloc(k * sizeof(int))) == NULL)
return -; /*为已排序元素临时存放数组分配空间*/
if((temp = (int *)malloc(size * sizeof(int))) == NULL)
return -; /*初始化计数数组*/
for(i = ; i < k; i++)
{
counts[i] = ;
} /*统计每个元素出现的次数(counts的下标索引即是要统计的元素本身)*/
for(j=; j<size; j++)
counts[data[j]]=counts[data[j]] + ; /*将元素本身的次数加上它前一个元素的次数(得到元素偏移量)*/
for(i = ; i < k; i++)
counts[i]=counts[i] + counts[i-]; /*关键代码:使用上面得到的计数数组去放置每个元素要排序的位置*/
for(j = size -; j >= ; j--)
{
temp[counts[data[j]]-] = data[j]; /*counts的值是元素要放置到temp中的偏移量*/
counts[data[j]] = counts[data[j]] - ; /*counts的计数减1*/
} /*将ctsort已排序的元素从temp拷贝回data*/
memcpy(data,temp,size * sizeof(int)); /*释放前面分配的空间*/
free(counts);
free(temp); return ;
}
基数排序
基数排序是另外一种高效的线性排序算法。
其方法是将数据按位分开,并从数据的最低有效位到最高有效位进行比较,依次排序,从而得到有序数据集合。
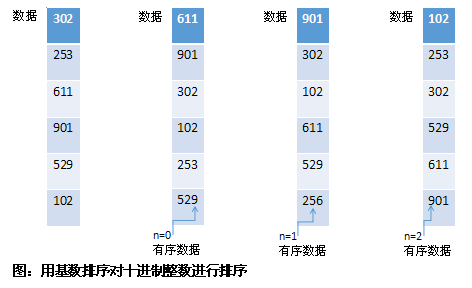
我们来看一个例子,用基数排序对十进制数据{15,12,49,16,36,40}进行排序。在对个位进行排序之后,其结果为{40,12,15,16,36,49},在对十位进行排序之后,其结果为{12,15,16,36,40,49}。
有一点非常重要,在对每一位进行排序时其排序过程必须是稳定的。一旦一个数值通过较低有效位的值进行排序之后,此数据的位置不应该改变,除非通过较高有效位的值进行比较后需要调整它的位置。例如,在上述的例子中,12和15的十位都是1,当对其十位进行排序时,一个不稳定的排序算法可能不会维持其在个数排序过程中的顺序。而一个稳定的排序算法可以保证它们不重新排序。基数排序会用到计数排序,对于基数排序来说,除了稳定性,它还是一种线性算法,且必须知道每一位可能的最大整数值。
基数排序并不局限于对整数进行排序,只要能把元素分割成整型数,就可以使用基数排序。例如,可以对一个以28为基数字符串进行基数排序;或者,可以对一个64位的整数,按4位以216为基数的值进行排序。具体该选择什么值作为基数取决于数据本身,同时考虑到空间的限制,需要将pn+pk最小化。(其中p为每个元素的位数,n为元素的个数,k为基数)。一般情况下,通常使k小于等于n。
基数排序的接口定义
rxsort
int rxsort(int *data, int size, int p, int k);
返回值:如果排序成功,返回0;否则返回-1。
描述:利用计数排序将数组data中的整数进行排序。数组data中整数的个数由size决定。参数p指定每个整数包含的位数,k指定基数。当rxsort返回时,data包含已经排序的整数。
复杂度:O(pn+pk),n为要排序的元素个数,k为基数,p为位的个数。
基数排序的实现与分析
基数排序实质上是在元素每一位上应用计数排序来对数据集合排序。在以下介绍的实现方法中,data初始包含size个无序整型元素,并存放在单块连续的存储空间中。当rxsort返回时,data中的数据集完全有序。
如果我们理解了计数排序的方法,那么基数排序也就非常简单了。单个循环控制正在进行排序的位置。从最低位开始一个位置一个位置地应用计数排序来不断调整元素。一旦调整完了最高有效位的数值,排序过程就完成了。
获取每位数值的简单方法就是使用幂运算和模运算。这对整数来说特别有效,但不同的数据类型需要使用不同的方法。有一些方法可能需要考虑机器具体细节,例如字节顺序和字对齐等。
毫无疑问,基数排序的时间复杂度取决于它选择哪种稳定排序来对数值进行排序。由于基数排序对每个p位置的位数值使用计数排序,因此基数排序消耗的运行时间是计数排序的p倍,即O(pn+pk)。其对空间的要求与计数排序一样:两个大小为n的数组,一个大小为k的数组。
示例:基数排序的实现
/*rxsort.c*/
#include <limits.h>
#include <math.h>
#include <stdlib.h>
#include <string.h> #include "sort.h" /*rxsort*/
int rxsort(int *data, int size, int p, int k)
{
int *counts, *temp;
int index, pval, i, j, n; /*为计数器数组分配空间*/
if((counts = (int *)malloc(k * sizeof(int))) == NULL)
return -;
/*为已排序元素集分配空间*/
if((temp = (int *)malloc(size * sizeof(int))) == NULL)
return -; /*从元素的最低位到最高位开始排序*/
for(n=; n<p; n++)
{
/*初始化计数器*/
for(i=; i<k; i++)
count[i] = ;
/*计算位置值(幂运算k的n次方)*/
pval = (int)pow((double)k,(double)n); /*统计当前位上每个数值出现的次数*/
for(j=; j<size; j++)
{
index = (int)(data[j] / pval) % k;
counts[index] = counts[index]+;
}
/*计算偏移量(本身的次数加上前一个元素次数)*/
for(i=; i<k; i++)
counts[i] = counts[i] + counts[i-]; /*使用计数器放置元素位置*/
for(j=size-; j>=; j--)
{
index = (int)(data[j] / pval) % k;
temp[counts[index]-] = data[j];
counts[index] = counts[index] - ;
} /*将已排序元素拷贝回data*/
memcpy(data, temp, size*sizeof(int)); } /*释放已排序空间*/
free(counts);
free(temp); return ;
}
排序算法的C语言实现(下 线性时间排序:计数排序与基数排序)的更多相关文章
- 【最全】经典排序算法(C语言)
算法复杂度比较: 算法分类 一.直接插入排序 一个插入排序是另一种简单排序,它的思路是:每次从未排好的序列中选出第一个元素插入到已排好的序列中. 它的算法步骤可以大致归纳如下: 从未排好的序列中拿出首 ...
- 排序算法总结(C语言版)
排序算法总结(C语言版) 1. 插入排序 1.1 直接插入排序 1.2 Shell排序 2. 交换排序 2.1 冒泡排序 2.2 快速排序 3. 选择 ...
- 【转载】常见十大经典排序算法及C语言实现【附动图图解】
原文链接:https://www.cnblogs.com/onepixel/p/7674659.html 注意: 原文中的算法实现都是基于JS,本文全部修改为C实现,并且统一排序接口,另外增加了一些描 ...
- [算法] 常见排序算法总结(C语言版)
常见排序算法总结 本文对比较常用且比较高效的排序算法进行了总结和解析,并贴出了比较精简的实现代码,包括选择排序.插入排序.归并排序.希尔排序.快速排序等.算法性能比较如下图所示: 1 冒泡排序 基本原 ...
- [answerer的算法课堂]简单描述4种排序算法(C语言实现)
[answerer的算法课堂]简单描述4种排序算法(C语言实现) 这是我第一次写文章,想要记录自己的学习生活,写得不好请包涵or指导,本来想一口气写好多种,后来发现,写太多的话反而可读性不强,而且,我 ...
- 排序算法的C语言实现(上 比较类排序:插入排序、快速排序与归并排序)
总述:排序是指将元素集合按规定的顺序排列.通常有两种排序方法:升序排列和降序排列.例如,如整数集{6,8,9,5}进行升序排列,结果为{5,6,8,9},对其进行降序排列结果为{9,8,6,5}.虽然 ...
- 几种经典排序算法的R语言描述
1.数据准备 # 测试数组 vector = c(,,,,,,,,,,,,,,) vector ## [] 2.R语言内置排序函数 在R中和排序相关的函数主要有三个:sort(),rank(),ord ...
- 链表插入和删除,判断链表是否为空,求链表长度算法的,链表排序算法演示——C语言描述
关于数据结构等的学习,以及学习算法的感想感悟,听了郝斌老师的数据结构课程,其中他也提到了学习数据结构的或者算法的一些个人见解,我觉的很好,对我的帮助也是很大,算法本就是令人头疼的问题,因为自己并没有学 ...
- 常用七大经典排序算法总结(C语言描述)
简介 其中排序算法总结如下: 一.交换排序 交换排序的基本思想都为通过比较两个数的大小,当满足某些条件时对它进行交换从而达到排序的目的. 1.冒泡排序 基本思想:比较相邻的两个数,如果前者比后者大,则 ...
随机推荐
- UNIX网络编程——ICMP报文分析:端口不可达
ICMP的一个规则是,ICMP差错报文必须包括生成该差错报文的数据报IP首部(包含任何选项),还必须至少包括跟在该IP首部后面的前8个字节(包含源端口和目的端口).在我们的例子中,跟在IP首部后面的前 ...
- SIM900A设备在保加利亚无法正常使用GPRS问题
1. SIM900A设备在保加利亚GPRS功能无法正常使用 我们一款手持设备采用SIM900A模块,在发货之前测试正常,但到了保加利亚,客户发现无法正常上网,我们技术支持反馈的邮件反馈的现象 ...
- Chapter 2 User Authentication, Authorization, and Security(2):创建登录帐号
原文出处:http://blog.csdn.net/dba_huangzj/article/details/38705965,专题目录:http://blog.csdn.net/dba_huangzj ...
- outlook邮箱邮件与企业邮箱同步(outlook本地文件夹邮件,web邮箱里没有)
用惯了outlook2010, 问题:今天将邮件放到自定义文件夹后,发现在web邮箱中看不到邮件了.不能同步到企业邮箱. 解决忙了一天,才知道是账户类型问题,pop3类型,只下载不上传.所以outlo ...
- 简单的C语言猜数字小游戏
猜数字小游戏可谓是C语言最为基础的一个知识点了,我们可以在此基础上进行延伸,实现随机数的猜测,然后是加入再来一局的模式,等等.这里是抛砖引玉,希望你能做出你的经典之作. #include <st ...
- OC内存管理-OC笔记
内存管理细节:http://blog.sina.com.cn/s/blog_814ecfa90102vus2.html 学习目标 1.[理解]内存管理 2.[掌握]第一个MRC程序 3.[掌握]内存管 ...
- naoting
生活就像一锅菠菜汤 20160714 夜
- 深入 JAVA里面关于byte数组和String之间的转换问题
把byte转化成string,必须经过编码. 例如下面一个例子: importjava.io.UnsupportedEncodingException; publicclass test{ pub ...
- (NO.00001)iOS游戏SpeedBoy Lite成形记(九)
我们回到matchRun方法中去尝试第一次修改,部分代码如下: CCActionMoveBy *moveBy = [CCActionMoveBy actionWithDuration:duration ...
- 14_Android中Service的使用,关于广播接收者的说明
服务:长期后台运行的没有界面的组件 android应用:什么地方需要用到服务? 天气预报:后台的连接服务器的逻辑,每隔一段时间获取最新的天气信息 股票显示:后台的连接服务器的逻辑,每隔一段时间获 ...