kudu的写数据流程

写入操作是指需进行插入、更新或删除操作的一组行。需要注意的事项是Kudu强制执行主关键字的唯一性,主关键字是可以更改行的唯一标识符。为了强制执行此约束条件,Kudu必须以不同的方式处理插入和更新操作,并且这会影响tablet服务器如何处理写入
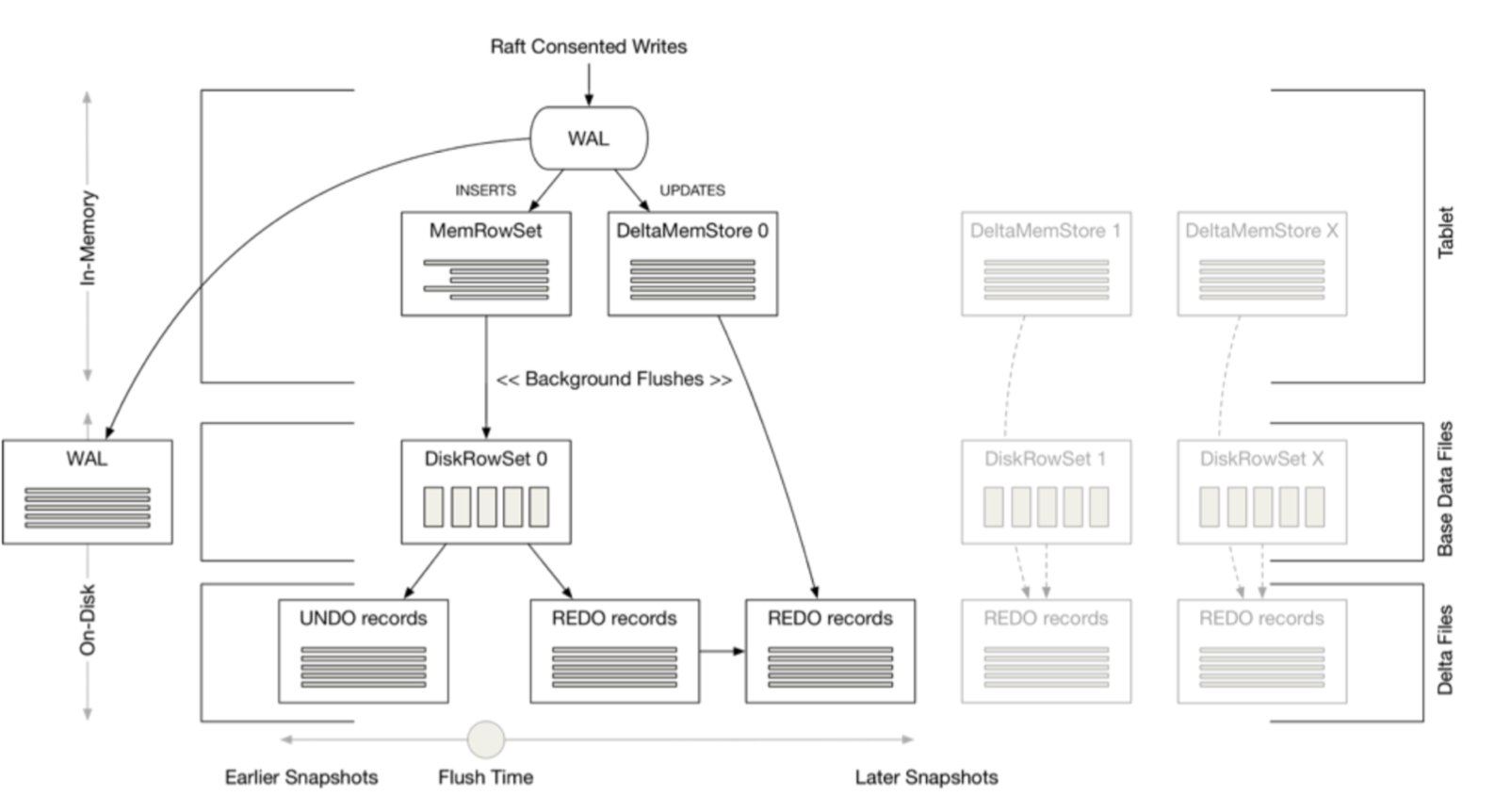
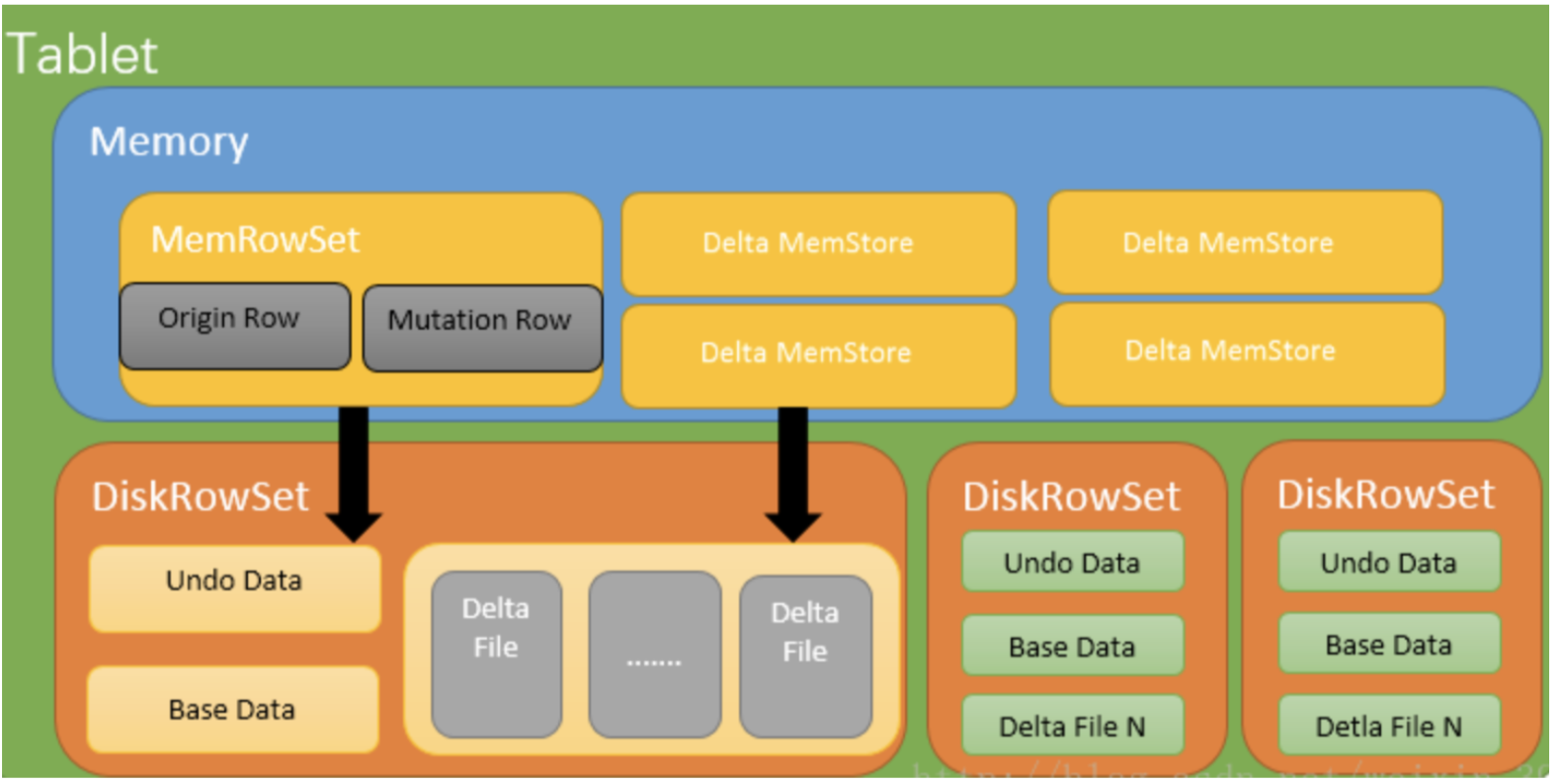
Kudu中的每个tablet包含预写式日志(WAL)和多个行集合(RowSet),它们是保存在存储器和磁盘上(被刷新时)的不相交的行集合。
写入操作先被提交到tablet的预写式日志(WAL),并根据Raft 一致性算法取得追随节点的同意,然后才会被添加到其中一个tablet的内存中;
插入会被添加到tablet的MemRowSet中。为了在MemRowSet中支持多版本并发控制(MVCC),对最近插入的行(即尚未刷新到磁盘的新的行)的更新和删除操作将被追加到MemRowSet中的原始行之后以生成重做(REDO)记录的列表。(读取者需要应用相关的重做(REDO)记录,根据扫描程序给定的时间戳构建行的正确快照。)
当MemRowSet填满时,则被刷新到磁盘并成为一个DiskRowSet。为了支持磁盘中存储数据的多版本并发控制(MVCC)功能,DiskRowSets被分为两种不同的文件类型:
MemRowSet中行的最新版本(即应用了其所有重做(REDO)记录的原始插入)被写入到基础数据文件。这是一种柱状文件格式(非常像Parquet),用于快速、高效的读取访问,其赋予了Kudu支持分析访问模式的能力。 MemRowSet中存在的行的先前版本(即重做(REDO)记录的倒序)作为一组撤销(UNDO)记录写入增量文件。时间行程读取可以应用相关的撤销(UNDO)记录,从早期的时间点构建行的正确快照。
更新已被编码和压缩的柱状格式化数据文件需要重写整个文件,因此基础数据文件一旦被刷新则被认为是不可变的。
此外,行关键字唯一性约束意味着基本记录的更新和删除不能被添加到tablet的MemRowSet中,而是被添加到名为DeltaMemStore的单独的内存存储器中。
像MemRowSet一样,所有的变化都将被添加到DeltaMemStore中作为一组重做(REDO)记录;
当DeltaMemStore填满时,重做(REDO)记录将被刷新到磁盘上存储的增量文件中。
每个DiskRowSet都存在一个单独的DeltaMemStore。如需构建行的正确快照,读取者必须在应用相关撤销(UNDO)或重做(REDO)记录之前首先找到行的基本记录
综上所述:
Kudu插入一条新数据
1、客户端连接TMaster获取表的相关信息,包括分区信息,表中所有tablet的信息;
2、客户端找到负责处理读写请求的tablet所负责维护的TServer。Kudu接受客户端的请求,检查请求是否符合要求(表结构);
3、Kudu在Tablet中的所有rowset(memrowset,diskrowset)中进行查找,看是否存在与待插入数据相同主键的数据,如果存在就返回错误,否则继续;
4、写入操作先被提交到tablet的预写日志(WAL),并根据Raft一致性算法取得追随节点的同意,然后才会被添加到其中一个tablet的内存中,插入会被添加到tablet的MemRowSet中。为了在MemRowSet中支持多版本并发控制(MVCC),对最近插入的行(即尚未刷新到磁盘的新的行)的更新和删除操作将被追加到MemRowSet中的原始行之后以生成REDO记录的列表。
5、Kudu在MemRowset中写入一行新数据,在MemRowset(1G或者是120s)数据达到一定大小时,MemRowset将数据落盘,并生成一个diskrowset用于持久化数据,还生成一个memrowset继续接收新数据的请求
kudu的写数据流程的更多相关文章
- day4-hdfs的核心工作原理\写数据流程 \读数据流程
namenode元数据管理要点 1.什么是元数据? hdfs的目录结构及每一个文件的块信息(块的id,块的副本数量,块的存放位置<datanode>) 2.元数据由谁负责管理? namen ...
- Solr 写数据流程
Solr 写数据流程: 1.源字符串首先经过分词器处理,包括:拆分词以及去除stopword. 2.然后经过语言处理,包括大小写转换以及单词转换. 3.将源数据中需要的信息加入到Document中的各 ...
- HDFS 读/写数据流程
1. HDFS 写数据流程 客户端通过 Distributed FileSystem 模块向 NameNode 请求上传文件, NameNode 检查目标文件是否已存在,父目录是否存在: NameNo ...
- HA工作机制及namenode向QJM写数据流程
HA工作机制 (配置HA高可用传送门:https://www.cnblogs.com/zhqin/p/11904317.html) HA:高可用(7*24小时不中断服务) 主要的HA是针对集群的mas ...
- kudu的读取数据流程
当客户端从Kudu的表中读取数据时,必须首先建立需要连接的系列tablet服务器. 通过执行tablet发现过程(如上所述)来确定包含要读取的主关键字范围的tablet的位置(读取不必在领导者tabl ...
- HDFS数据流——写数据流程
剖析HDFS文件写入 假设文件ss.avi共200m,其写入HDFS指定路径/user/atguigu/ss.avi流程如下: 1)客户端向namenode请求上传文件到指定路径,namenode通过 ...
- HDFS写数据和读数据流程
HDFS数据存储 HDFS client上传数据到HDFS时,首先,在本地缓存数据,当数据达到一个block大小时.请求NameNode分配一个block. NameNode会把block所在的Dat ...
- Hadoop(8)-HDFS的读写数据流程以及机架感知
1. HDFS的写数据流程 1.客户端通过fs模块向NameNode申请文件上传,NameNode检查请求是否合法,如用户权限,目标文件是否已存在,父目录是否存在等等 2.NameNode返回是否可以 ...
- HDFS读写数据流程
HDFS的组成 1.NameNode:存储文件的元数据,如文件名,文件目录结构,文件属性(创建时间,文件权限,文件大小) 以及每个文件的块列表和块所在的DataNode等.类似于一本书的目录功能. 2 ...
随机推荐
- java压缩图片质量
使用了工具thumbnailator,据说thumbnailator是一个非常好的图片开源工具,使用起来很方便.不过没仔细看过,我只是需要压缩图片,让其占用空间变小而已.使用maven引入jar包 & ...
- 下载chrome插件和离线安装CRX文件的方法
自从chrome网上应用店出来后无法下载插件,必须在线安装,安装后又自动把CRX删除,而且是那么的迅速...以下是下载离线插件包的方法:第一步: 每个Google Chrome扩展都有一个固定的ID, ...
- 【原创】大叔经验分享(30)CM开启kerberos
kerberos安装详见:https://www.cnblogs.com/barneywill/p/10394164.html 一 为CM创建用户 # kadmin.local -q "ad ...
- js 数组不重复添加元素
1 前言 由于使用JS的push会导致元素重复,而ES5之前没有set(集合)方法,重复元素还要做去重处理,比较麻烦些,所以直接写一个新push来处理 2 代码 Array.prototype.pus ...
- Gradle缓存目录文件命名规则
在打开Android Studio项目的时候,会下载项目对应版本的gradle,该版本是在项目根目录下\gradle\wrapper\gradle-wrapper.properties文件中指定的: ...
- MVVM 简介
转:https://objccn.io/issue-13-1/ 所以,MVVM 到底是什么?与其专注于说明 MVVM 的来历,不如让我们看一个典型的 iOS 是如何构建的,并从那里了解 MVVM: 我 ...
- 疯狂Workflow讲义——基于Activiti的工作流应用开 PDF 下载
<疯狂Workflow讲义--基于Activiti的工作流应用开> 一:文档获取下载方式: 1:花20CSDN积分:可以下载:http://download.csdn.net/downlo ...
- Confluence 6 数据库问题解除
有关数据库相关的问题,请参考 Database Troubleshooting 中的内容. 希望获得更多的帮助,请参考 Troubleshooting Problems and Requesting ...
- 【Java】「深入理解Java虚拟机」学习笔记(1) - Java语言发展趋势
0.前言 从这篇随笔开始记录Java虚拟机的内容,以前只是对Java的应用,聚焦的是业务,了解的只是语言层面,现在想深入学习一下. 对JVM的学习肯定不是看一遍书就能掌握的,在今后的学习和实践中如果有 ...
- python之vscode配置开发调试环境
在vscode中下载python插件,下载量最多的就是 打开launch.json,把以下代码粘贴进去即可 { // 使用 IntelliSense 了解相关属性. // 悬停以查看现有属性的描述. ...