Microsoft SQL - 查询与更新
查询与更新(Query & Update)
转义引号
SQL语句中字符串只能使用单引号,如果需要转义,可用单引号转义单引号。
查询(Inquire)
以下公式中的c指代列名。
规则
1.查询语句的列名区分大小写。
2.查询语句的字符串只能使用单引号。
3.为每条语句加上分号表示一条语句结束,防止当一次执行多条语句时会抛错。
关键字:select
四种基本查询格式
直接查询
select * from stu
参数查询
将查询语句作为字符参数传递给exec执行函数
exec('select * from stu')
declare @name varchar(10) , @en varchar(3)
select @name='姓名',@en='英语'
exec ('select '+@name+','+@en+' from 成绩单')
命令查询
如果查询语句里使用了变量,则只能使用命令查询。
exec sp_executesql N'select * from stu'
指定列查询
select 职称,班级 from Teacher
form子句(来源)
所有查询
select * from Person.Address
部分查询
select AddressID,City from Person.Address //只查询该表的AddressID和City字段
列别名查询:列名 as
添加as该操作符可以为列名取一个别名,可在输出结果中查看,也可以为表定义别名。
select AddressID as 地址编号,City as 所在城市 from Person.Address

数学计算查询:列名+列名……
将每行中可计算的多个列的数据相加或相减,科使用+和-号将多个列连起来查询,计算结果可as到一个新的输出列中。
create table 成绩单
(
id int identity(1,1) not null constraint pk_id primary key,
name nvarchar(20) not null ,
en int,
math int
) insert into 成绩单 values('sam',90,80)
insert into 成绩单 values('john',60,20)
insert into 成绩单 values('sam',90,50) select name as 姓名, en+math as 总分 from 成绩单


前n条记录查询:select top n[percent]
select top(1) name as 姓名, en+math as 总分 from 成绩单
//先查询每个人的名字和其英语和数学的分数总和,然后从这些结果里边只取出第一条记录
select top(50) percent * from 成绩单
//查询50%的行且是最靠前的行
列数据不重复查询:select distinct 列名
select distinct en from 成绩单
//每条记录中的en列如果有相等数据只取一条结果
完全限定表名查询
select Student.c from dbName.dbo.Student
Student:表名
c:列名
dbName:数据库名
dbo:数据库拥有者(默认,除非你更改了数据库拥有者的名字,否则直接写dbo即可)
为查询创建新表:into 新表 form 旧表
将查询结果装入一个新表,新表会存在与数据库中。
select id,name,math+en as score into 总成绩单 from 成绩单
join子句(联结)
多张表可能建立联系,比如学员表和成绩表,它们通过学员ID进行联系。join子句可以查询多张建立了联系的表,以on操作符所规定的条件进行过滤。
内联查询:inner join 另一张关联的表 on 条件(不匹配的记录不会输出)
内联查询就是将多张表联起来,以on操作符给出匹配条件,满足条件的记录会被查询。以下示例演示了如何查询多表联结的数据,查询两张表中有相同的FlimID的记录。
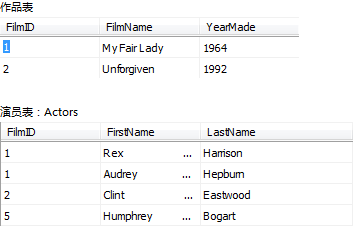
select Films.filmID,Films.FilmName,Films.YearMade,Actors.FirstName,Actors.LastName from Films inner join Actors
on Actors.filmID=Films.filmID /*或*/ select a.filmID,a.FilmName,a.YearMade,b.FirstName,b.LastName from Films as a inner join Actors as b
on b.filmID=a.filmID
两张表能匹配的FilmID列的数据为1和2 所以输出结果为:(Actors的FilmID为5的记录在Films表中没有匹配,所以不会输出)

全联结查询:full join 另一张关联的表 on 条件(不匹配的记录以null填充)
将返回两张表的所有记录,不匹配的记录以null填充。
外联查询
左外联:left outer join 另一张关联的表 on 条件(不满足匹配时,保证左边记录可以显示,右边记录以null填充)
左侧的表如果与右侧的表中的某条记录不满足on的条件也会返回该条记录,左侧表中的记录会显示,右侧表的记录则以null填充。
select Films.filmID,FilmName,YearMade,FirstName,LastName from Actors left outer join Films
on Actors.filmID=Films.filmID
查询结果将会返回Actors表中的Humphrey所在行的记录,该记录不匹配FilmID,所以Film的FilmID和FilmName将会填充null。
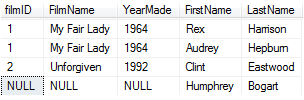
右外联:right outer join 另一张关联的表 on 条件(不满足匹配时,保证右边记录可以显示,左边记录以null填充)
左侧的表如果与右侧的表中的某条记录不满足on的条件也会返回该条记录,右侧表中的记录会显示,左侧表的记录则以null填充。
多表联结查询
超过两张表的联结查询:
/*先join两张表,再继续join其它表*/
/*先join两张表,再继续join其它表*/
select * from UserManagers as a inner join Departments as b on a.DepartmentId=b.DepartmentId
inner join TbRoses c
on a.TbRoseId=c.TbRoseId
where子句(过滤)
在select返回的查询结果里使用where子句来筛选过滤出真正需要的数据。
select * from 成绩单
where en=90
where支持的操作符
= 、<>、!=、<、>、!<、!>、<=、>=、or、and、is null、not null、in(n1,n2……)、not in(n1,n2……)、like、not like、existis(子查询)[至少返回了一条记录则返回true]、x between y 介于某值到某值之间。
select * from 成绩单
where en>=60 and (id=1 or id=2)
//查询整个成绩单,在结果中筛选出英语成绩>=60并且学员编号为1或者2的记录
select * from Schedule
where year(StartDate) = '' and month(StartDate)='' and day(StartDate)=''
//匹配StartDate列的日期必须是2013-05-18
通配符过滤
通配符会拖慢整个搜索系统、效率最慢、最低。
百分号通配符%
表示任意字符,可以是0或者空字符串。
like '%文本'
like '文本%'
like '%文本%'
下划线通配符_
表示任意一个字符。
like '_文本'
like '文本_'
like '_文本_'
方括号通配符 [ ]
匹配出现在方括号内的任意一个字符,不管方括号内有几个字符,能匹配一个就行。
select * from 学员
where 名称 like '[张李]%[三四]'
//查询学员表,在结果中过滤出名称一列中以张或者李开头以三或者四结尾的记录
方括号否定通配符 [^ ]
^是不以的意思。
select * from 学员
where 名称 like '[^张李]%[^三四]'
//查询学员表,在结果中过滤出名称一列中名称不以张或者李开头且不以三或者四结尾的记录
order by子句(排序)
该子句必须放在所有select子句的末尾。
升序查询:order by 列名 asc 此为默认,可不写asc
降序查询:order by 列名 desc
select name,math from 成绩单
order by en desc;
//这里并没有查询英语成绩,但还是可以按en进行排序
多列排序
列名之间逗号隔开,采取就近原则(离order by最近的列),如果当前排序出现数据相同的情况,会按后一个列的数据为准进行排序。
升降混排
select * from 成绩单
order by en desc,math
//按英语成绩降序排序,遇到英语成绩相同的列 就按数学成绩升序排序
字母排序
A<Z,无法按小写排序。
group by子句
普通分组:group by 列名
对表数据进行分组,纵向的一列中相同的数据会被归纳为一组,可以把分为一组的数据想象为一张表 里边存储了一个列 这个列有N行相同纪录的数据

select 英语 from 成绩
group by 英语

聚合函数分组
group by 可以组合聚合函数来实现分组计算,聚合函数的计算行为是基于分组后的列而非分组前。
select 英语,count(*) as 记录条数 from 成绩
group by 英语

过滤分组
having子句来为分组后数据过滤,类似where子句过滤。区别在于where过滤的是整张表的查询结果,而having只过滤已被分组的数据 。该子句使用的操作符与where一样。
//查询顾客的订单有2个以上的记录 :
select 顾客id,count(*) as 记录条数 from orders as 顾客订单
group by 顾客id
having count(*) >=2
//查询顾客订单表的所有记录,然后在结果里以顾客id进行分组,并临时生成一个新列统计记录条数,使用having过滤出顾客的订单有2个以上的记录
分组规则
1.靠select最近的依次为:where>group by > order by
2.select中如果出现表达式那么group by也必须出现该表达式。
3.select中查询的列必须是group by的列,group by的列有几个,select的列就得有几个,多一个都不行。
单向子查询
子查询就是在一个查询语句中使用了另一个嵌套在括号中的查询语句,嵌套子查询只朝一个方向进行,要么返回一个用于外部需要的查询的结果(单个结果值),要么返回一个值的列表(多个值),如果需要返回一个值列表,则必须在外部查询中使用in运算符。
子查询单值返回:
create table 产品
(
产品ID int not null identity(10000,1) primary key,
产品名称 nvarchar(20) not null
) create table 订单
(
订单ID int not null identity primary key,
订单日期 smalldatetime not null ,
产品ID int not null foreign key references 产品(产品ID)
) insert into 产品(产品名称)values('奇鸟行状录')
insert into 产品(产品名称)values('爵士乐群英谱')
insert into 产品(产品名称)values('荒凉天使')
insert into 产品(产品名称)values('吴哥的微笑') insert into 订单(订单日期,产品ID)values('1990-12-12','')
insert into 订单(订单日期,产品ID)values('1990-11-11','')
insert into 订单(订单日期,产品ID)values('1990-12-11','')
insert into 订单(订单日期,产品ID)values('1990-12-10','')
现在要从内联查询的结果中找出日期最早的订单
select a.订单日期,a.产品ID,b.产品名称 from 订单 as a inner join 产品 as b
on a.产品ID=b.产品ID
where a.订单日期=(select min(订单日期) from 订单)
/*将两张表建立内联查询,获取两张表中产品ID能匹配的记录*/
/*再从结果里过滤出日期最早的订单*/

子查询多值返回:
select a.订单日期,a.产品ID,b.产品名称 from 订单 as a inner join 产品 as b
on a.产品ID=b.产品ID
where 订单日期 in (select 订单日期 from 订单 where 订单日期 >='1990-12-10' )
/*where 订单日期 in (select 订单日期 from 订单 where 订单日期 between '1990-12-10' and '1990-12-12' )*/

子查询操作符
关键字:> any (select)
>any子查询中的最小值,select是子查询语句,子查询语句必须返回一个值列表。
select a.订单日期,a.产品ID,b.产品名称 from 订单 as a inner join 产品 as b
on a.产品ID=b.产品ID
where 订单日期 > any (select 订单日期 from 订单 where 订单日期 between '1990-12-10' and '1990-12-12') /*这个any子查询就是以下逻辑,但不能直接像下面那样去写,any括号里必须是能返回值列表的查询语句*/
where 订单日期 > any ('1990-12-10','1990-12-11','1990-12-12')
关键字:< any ( 子查询 )
小于any中的最大值。
关键字:= any ( 子查询 )
等于any中的任意一个值。
关键字:> all ( 子查询 )
大于all中的最大值。
关键字:< all ( 子查询 )
小于all中的最小值。
关键字:in(子查询)
等于in中的任意一个值,与=any是一样的。
关键字:not in(子查询)
不在not in中的任意值
关键字:exists(子查询)
返回布尔值,测试子查询是否有记录。但不允许有 COMPUTE 子句和 INTO操作符。
select * from 成绩
where exists ( select 英语 from 成绩 where 英语>90 )
/*如果有英语成绩大于90的纪录就查询成绩表的所有纪录,否则不执行查询。*/
/*如果子查询为null exists也返回true*/
if exists(select null)
关键字:not exists(子查询)
返回布尔值,测试子查询是否没有记录。
双向子查询
关联子查询是双向进行,即它以外部查询的结果为基础取执行一个子查询,然后再将结果返回给外部查询,外部查询利用这个结果来生成最终的查询结果。
create table 顾客
(
顾客ID int identity(1,1) primary key,
顾客姓名 nvarchar(4) not null
) insert into 顾客(顾客姓名)values('sam')
insert into 顾客(顾客姓名)values('leo')
insert into 顾客(顾客姓名)values('korn')
insert into 顾客(顾客姓名)values('kent')
insert into 顾客(顾客姓名)values('bob')
insert into 顾客(顾客姓名)values('mary') create table 订单
(
订单ID int not null identity(1000,1) primary key,
订单日期 smalldatetime not null,
顾客ID int foreign key references 顾客(顾客ID)
) insert into 订单(订单日期,顾客ID)values('1990-12-10',2)
insert into 订单(订单日期,顾客ID)values('1991-11-05',3)
insert into 订单(订单日期,顾客ID)values('1992-08-10',6)
insert into 订单(订单日期,顾客ID)values('1993-05-06',4)
insert into 订单(订单日期,顾客ID)values('1985-12-10',2)
insert into 订单(订单日期,顾客ID)values('1964-12-10',2)
insert into 订单(订单日期,顾客ID)values('1935-08-10',6)
insert into 订单(订单日期,顾客ID)values('1912-08-10',6)
insert into 订单(订单日期,顾客ID)values('1911-05-06',4)
insert into 订单(订单日期,顾客ID)values('1933-05-06',4) select a.订单日期,b.顾客姓名 from 订单 as a inner join 顾客 as b
on a.顾客ID=b.顾客ID
where 订单日期=(select min(订单日期) from 订单 where a.顾客ID=顾客ID)
/*还可以使用分组+表变量的方式来查询 如:*/
declare @table table
(
顾客ID int,
订单时间 smalldatetime
) insert into @table
select 顾客ID,min(订单时间) as 订单时间 from 订单
group by 顾客ID select b.顾客名字,a.订单时间 as 最早的订单时间 from @table a inner join 顾客b
on a.顾客ID=b.顾客ID
派生表
派生表也称为内联视图,在执行更复杂的查询时可能会用到派生表,派生表就是子查询里使用了join子句的查询 。
/*订单表引用了顾客表和产品表,现在要查询订购了歌德音响和小狗吸尘器的顾客*/
create table 顾客
(
顾客ID int not null primary key,
顾客名字 varchar(10) not null
) create table 产品
(
产品ID int not null primary key,
产品名称 varchar(20) not null,
) create table 订单
(
订单ID int not null primary key,
订单号 int not null,
订单时间 smalldatetime not null,
顾客ID int not null foreign key references 顾客(顾客ID),
产品ID int not null foreign key references 产品(产品ID)
) /*插入数据到顾客表*/
insert into 顾客(顾客ID,顾客名字)values(1,'sam')
insert into 顾客(顾客ID,顾客名字)values(2,'leo')
insert into 顾客(顾客ID,顾客名字)values(3,'korn')
insert into 顾客(顾客ID,顾客名字)values(4,'lily') /*插入数据到产表*/
insert into 产品(产品ID,产品名称)values(1,'农夫山泉')
insert into 产品(产品ID,产品名称)values(2,'旺仔小馒头')
insert into 产品(产品ID,产品名称)values(3,'小狗吸尘器')
insert into 产品(产品ID,产品名称)values(4,'歌德音响') /*插入数据到订单表*/
insert into 订单(订单ID,订单号,顾客ID,产品ID)values(1,1001,1,4)
insert into 订单(订单ID,订单号,顾客ID,产品ID)values(2,1002,1,2)
insert into 订单(订单ID,订单号,顾客ID,产品ID)values(3,1003,1,3)
insert into 订单(订单ID,订单号,顾客ID,产品ID)values(4,1004,2,2)
insert into 订单(订单ID,订单号,顾客ID,产品ID)values(5,1005,2,3)
insert into 订单(订单ID,订单号,顾客ID,产品ID)values(6,1006,2,1)
insert into 订单(订单ID,订单号,顾客ID,产品ID)values(7,1007,3,4)
insert into 订单(订单ID,订单号,顾客ID,产品ID)values(8,1008,3,3)
insert into 订单(订单ID,订单号,顾客ID,产品ID)values(9,1009,3,1) /*首先查询订购了歌德音响的客户*/
select 产品名称,顾客.顾客ID from 订单
join 顾客
on 订单.顾客ID=顾客.顾客ID
join 产品
on 订单.产品ID=产品.产品ID
where 产品名称='歌德音响' /*再查询订购了小狗吸尘器的客户*/
select 产品名称,顾客.顾客ID from 订单
join 顾客
on 订单.顾客ID=顾客.顾客ID
join 产品
on 订单.产品ID=产品.产品ID
where 产品名称='小狗吸尘器' /*将以上查询结果存入表变量里就可以得到两张临时表。使用join子句将三张表联接起来查询就可以得到既订购了歌德音响又订购了小狗吸尘器的客户。*/
declare @table1 table
(
产品名称varchar(30),
顾客ID int
)
insert into @table1
select 产品名称,顾客.顾客ID from 订单
join 顾客
on 订单.顾客ID=顾客.顾客ID
join 产品
on 订单.产品ID=产品.产品ID
where 产品名称='歌德音响' declare @table2 table
(
产品名称varchar(30),
顾客ID int
)
insert into @table2
select 产品名称,顾客.顾客ID from 订单
join 顾客
on 订单.顾客ID=顾客.顾客ID
join 产品
on 订单.产品ID=产品.产品ID
where 产品名称='小狗吸尘器' /*联接三张表得出结果,该顾客必须满足'歌德音响'表有他的记录且'小狗吸尘器'表中也有他的记录*/
select 顾客名字from 顾客
join @table1 as a
on 顾客.顾客ID=a.顾客ID
join @table1 as b
on 顾客.顾客ID=b.顾客ID
插入(Insert)
关键字:insert
insert into 表名(列名1,列名2,……)
values(值1,值2)
//或
insert into 表名 values(值,值……)
//后一种写法,null或有默认值的列必须填写为null、default,使列和值能对应 use mydb1
insert into 成绩(学员名称,英语,数学)
values('sam',90,100)
insert into Teacher(TeacherName,TeacherAge,TeacherPay,TeacherAdress)values('sam','','3800.0000','广西');
insert into Teacher(TeacherName,TeacherAge,TeacherPay,TeacherAdress)values('leo','','4500.0000','重庆');
insert into Teacher(TeacherName,TeacherAge,TeacherPay,TeacherAdress)values('korn','','5000.0000','黑龙江大庆');
insert into Teacher(TeacherName,TeacherAge,TeacherPay,TeacherAdress)values('kent','','6000.0000','马来西亚');
insert into Teacher(TeacherName,TeacherAge,TeacherPay,TeacherAdress)values('ben','','8800.0000','弗吉尼亚');
insert into Teacher(TeacherName,TeacherAge,TeacherPay,TeacherAdress)values('jim','','7000.0000','北京');
插入规则
1.是主键并且自动增长的列不能被insert,每inset一次,该主键列默认会自动增长。
2.如果确实需要手动插入数据到主键列,可使用set identity_insert=on,如此后续数据插入时的主键列将以你手动设置的主键列值为基础进行增加。
3.尽量使用指定列名的形式来插入数据,不指定列名的插入方式不够明确,万一表结构发生变化就会出现插入错误。
6.一次只能插入一条数据到表,不支持多个values子句
将查询结果插入另一张表
可能会遇到将来自其它数据源的数据插入到表 这些数据源可能是:另一张表、同一台服务器上完全不同的数据库的表,需保证表结构是一样的。
insert into 新表(列名)
select 列名 from 旧表
//以上将旧表的数据插入了相同结构的新表,如果数据路中没有这个新表,会自动在数据库中创建 declare @员工副本 table
(
员工ID int,
员工名称 varchar(50)
) insert into @员工副本
select 员工ID,员工名称 from 员工 select * from @员工副本 //以上声明了一个表变量,将员工表的数据插入了表变量,这相当于一个临时的存储表,命令执行完成@员工副本即被销毁,因为它只是一个变量。
更新(Update)
关键字:update
update 表名
set 列名=值
where 条件 update 成绩
set 英语=100
where 学员编号=1001
//更新数据必须+where条件,否则整张表的所有行的数据都会被更新
//更新多个列时,用逗号将列隔开
删除(Delete)
关键字:delete
delete from 表名
where 条件 delete from 成绩
where 学员编号=1001
//删除数据必须+where条件,否则整张表的所有行的数据都会被删除
关联删除
多张表有联系时,可使用join子句联起来删除需要删除的记录。

delete from 表名
from join子句 //删除在电影表中没有记录的演员
delete from 演员
from 演员 left join 电影
on 演员.电影ID=电影.电影ID
where 电影.电影ID is null
//删除演员表的记录,从左联表中找出没有参加过电影的演员,将其删除
Microsoft SQL - SQL SERVER学习总目录
Microsoft SQL - 查询与更新的更多相关文章
- mybatis_动态sql 查询、更新
1)sql where 条件 select id="find" parameterType="User" resultType="User" ...
- sql查询,更新,删除,操作。
UPDATE ht_plan_triptime pptSET ppt.lock_status = '1'WHERE ppt.lock_status <> '1' AND ppt.pl ...
- Microsoft SQL - 学习总目录
Microsoft SQL - 数据库管理系统 Microsoft SQL - 数据类型 Microsoft SQL - 查询与更新 Microsoft SQL - 操作语句 Microsoft SQ ...
- Sql Server Text 类型列 查询和更新
Text(ntext.image)类型为大数据字段,因为存储方式不同,也决定了其查询和更新不同于一般方法. 1.表定义: 2.查询: Like查询是可用的: select * from dbo.nod ...
- Querying Microsoft SQL Server 2012 读书笔记:查询和管理XML数据 1 -使用FOR XML返回XML结果集
XML 介绍 <CustomersOrders> <Customer custid="1" companyname="Customer NRZBB&qu ...
- sql查询,如果有更新时间则按更新时间倒序,没有则按创建时间倒序排列
原文:sql查询,如果有更新时间则按更新时间倒序,没有则按创建时间倒序排列 ORDER BY IFNULL(update_time,create_time) DESC IFNULL(expr1,exp ...
- Microsoft SQL Server中的事务与并发详解
本篇索引: 1.事务 2.锁定和阻塞 3.隔离级别 4.死锁 一.事务 1.1 事务的概念 事务是作为单个工作单元而执行的一系列操作,比如查询和修改数据等. 事务是数据库并发控制的基本单位,一条或者一 ...
- 最有效地优化 Microsoft SQL Server 的性能
为了最有效地优化 Microsoft SQL Server 的性能,您必须明确当情况不断变化时,性能将在哪些方面得到最大程度的改进,并集中分析这些方面.否则,在这些问题上您可能花费大量的时间和精力 ...
- (转)经典SQL查询语句大全
(转)经典SQL查询语句大全 一.基础1.说明:创建数据库CREATE DATABASE database-name2.说明:删除数据库drop database dbname3.说明:备份sql s ...
随机推荐
- PEP8规范
目录 一 代码编排 二 文档编排 三 空格使用 四 注释 五 文档描述 六 命名规范 七 编码建议 代码编排 1缩进,4个空格,不用tab键(因为可能不同系统tab的空格数不一定) 2每行最大长度79 ...
- cmd解压压缩包
需要安装有winrar start winrar x C:\Users\systme\Desktop\xxx.rar c:\123
- day15-ajax和jquery
回顾: 分页: 将数据按照页码划分,提高用户的体验度. 分类: 逻辑分页:一次性将内容加载到内存(list),获取自己想要的数据 sublist截取.缺点:维护起来麻烦 物理分页:(经常使用) 每次只 ...
- 关于串session
关于session: 最近在用IE浏览器调试不同用户所拥有的权限功能,出现了串session.串session,主要的流程结构如下: 解决方法: 在IE快捷方式上点击鼠标右键>属性>快捷方 ...
- Go多组Raft库
Go多组Raft库 https://github.com/lni/dragonboat/blob/master/README.CHS.md 使用用例 https://github.com/lni/dr ...
- mssql的 for xml path 与 mysql中的group_concat类似MSSQL For xml Path
/****** Script for SelectTopNRows command from SSMS ******/ SELECT D_ID,[D_Name] as Name FROM [LFBMP ...
- c++后台开发路线
- Date类、SimpleDateFormat类
Date 构造方法: 1.无参数构造方法: Date date = new Date(); System.out.println(date);// Thu Mar 28 16:28:40 CST 20 ...
- Python自定义分页组件
为了防止XSS即跨站脚本攻击,需要加上 safe # 路由 from django.conf.urls import url from django.contrib import admin from ...
- HTML&CSS总结
HTML 如果把网页比作房子的话,那么HTML就是搭建房子的整体结构,CSS就是对房子进行装修,HTML主要涉及各种标签的使用,总结如下,需要补充的一点是行内标签与块级标签的区别 inline:在一行 ...