GCC编译器原理(三)------编译原理三:编译过程(2-1)---编译之词法分析
二、编译
引用文档:https://blog.csdn.net/chdhust/article/details/9040647
编译过程就是把预处理完的文件进行一系列词法分析、语法分析、语义分析及优化后生成相应的汇编代码文件,这个过程是整个程序构建的核心部分,也是最复杂的部分之一。
现在版本的 GCC 把预编译和编译两个步骤合并成一个步骤,使用 cc1 的程序来完成这两个步骤。
编译过程一般分为 6 个步骤:扫描、语法分析、语义分析、源代码优化、代码生成和目标代码优化,过程如下图:
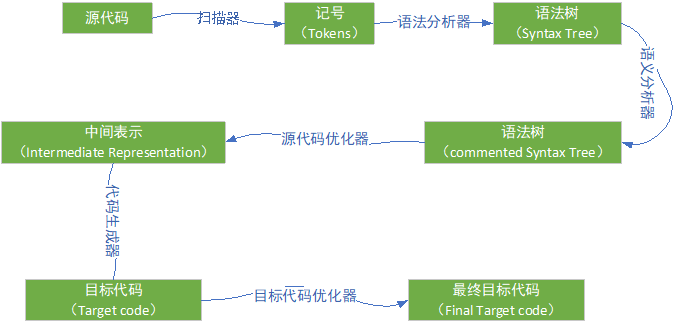
2.1 词法分析
源代码程序被输入到扫描器(Scanner),扫描器对源代码进行简单的词法分析,运用类似于有限状态机(Finite State Machine)的算法可以很轻松的将源代码字符序列分割成一系列的记号(Token)。
词法分析产生的记号一般可以分为如下几类:关键字、标识符、字面量(包含数字、字符串等)和特殊符号(如加号、等号)。在识别记号的同时,扫描器也完成了其他工作,比如将标识符存放到符号表,将数字、字符串常量存放到文字表等,以备后面的步骤使用。
词法分析可以使用 lex 工具。
2.2.1 lex 介绍
Lex 是一种生成扫描器的工具。扫描器是一种识别文本中的词汇模式的程序。 这些词汇模式(或者常规表达式)在一种特殊的句子结构中定义。
一种匹配的常规表达式可能会包含相关的动作。这一动作可能还包括返回一个标记。 当 Lex 接收到文件或文本形式的输入时,它试图将文本与常规表达式进行匹配。 它一次读入一个输入字符,直到找到一个匹配的模式。 如果能够找到一个匹配的模式,Lex 就执行相关的动作(可能包括返回一个标记)。 另一方面,如果没有可以匹配的常规表达式,将会停止进一步的处理,Lex 将显示一个错误消息。
Lex 和 C 是强耦合的。一个 .lex 文件(Lex 文件具有 .lex 的扩展名)通过 lex 公用程序来传递,并生成 C 的输出文件。这些文件被编译为词法分析器的可执行版本。
常规表达式是一种使用元语言的模式描述。表达式由符号组成。符号一般是字符和数字,但是 Lex 中还有一些具有特殊含义的其他标记。 下面两个表格定义了 Lex 中使用的一些标记并给出了几个典型的例子。
|
字符 |
含义 |
|
A-Z,0-9, a-z |
构成了部分模式的字符和数字。 |
|
. |
匹配任意字符,除了 \n。 |
|
- |
用来指定范围。例如:A-Z 指从 A 到 Z 之间的所有字符。 |
|
[ ] |
一个字符集合。匹配括号内的 任意 字符。如果第一个字符是 ^ 那么它表示否定模式。例如: [abC] 匹配 a, b, 和 C中的任何一个。 |
|
* |
匹配 0个或者多个上述的模式。 |
|
+ |
匹配 1个或者多个上述模式。 |
|
? |
匹配 0个或1个上述模式。 |
|
$ |
作为模式的最后一个字符匹配一行的结尾。 |
|
{ } |
指出一个模式可能出现的次数。 例如: A{1, 3} 表示 A 可能出现1次或3次。 |
|
\ |
用来转义元字符。同样用来覆盖字符在此表中定义的特殊意义,只取字符的本意。 |
|
^ |
否定。 |
|
| |
表达式间的逻辑或。 |
|
"<一些符号>" |
字符的字面含义。元字符具有。 |
|
/ |
向前匹配。如果在匹配的模版中的"/"后跟有后续表达式,只匹配模版中"/"前 面的部分。如:如果输入 A01,那么在模版 A0/1 中的 A0 是匹配的。 |
|
( ) |
将一系列常规表达式分组。 |
表达式例子
|
常规表达式 |
含义 |
|
joke[rs] |
匹配 jokes 或 joker。 |
|
A{1,2}shis+ |
匹配 AAshis, Ashis, AAshi, Ashi。 |
|
(A[b-e])+ |
个。 |
Lex 中的标记声明类似 C 中的变量名。每个标记都有一个相关的表达式。 (下表中给出了标记和表达式的例子。) 使用这个表中的例子,我们就可以编一个字数统计的程序了。 我们的第一个任务就是说明如何声明标记。
声明举例:
|
标记 |
相关表达式 |
含义 |
|
数字(number) |
([0-9])+ |
个或多个数字 |
|
字符(chars) |
[A-Za-z] |
任意字符 |
|
空格(blank) |
" " |
一个空格 |
|
字(word) |
(chars)+ |
个或多个 chars |
|
变量(variable) |
(字符)+(数字)*(字符)*(数字)* |
Lex 编程可以分为三步:
- 以 Lex 可以理解的格式指定模式相关的动作。
- 在这一文件上运行 Lex,生成扫描器的 C 代码。
- 编译和链接 C 代码,生成可执行的扫描器。
下面给出一些高级的Lex:
|
yyin |
FILE* 类型。它指向 lexer 正在解析的当前文件。 |
|
yyout |
FILE* 类型。它指向记录 lexer 输出的位置。缺省情况下,yyin 和 yyout 都指向标准输入和输出。 |
|
yytext |
匹配模式的文本存储在这一变量中(char*)。 |
|
yyleng |
给出匹配模式的长度。 |
|
yylineno |
提供当前的行数信息。(lexer不一定支持。) |
|
yylex() |
这一函数开始分析。它由 Lex 自动生成。 |
|
yywrap() |
,就停止解析。因此它可以用来解析多个文件。代码可以写在第三段,这就能够解析多个文件。方法是使用 yyin 文件指针(见上表)指向不同的文件,直到所有的文件都被解析。最后,yywrap() 可以返回 1 来表示解析的结束。 |
|
yyless(int n) |
这一函数可以用来送回除了前�n? 个字符外的所有读出标记。 |
|
yymore() |
这一函数告诉 Lexer 将下一个标记附加到当前标记后。 |
2.2.2 词法分析
Lex编译器将输入的模式转换成一个状态转换图,并生成相应的实现代码,并存放到文件lex.yy.c中,这些代码模拟了状态转换图。
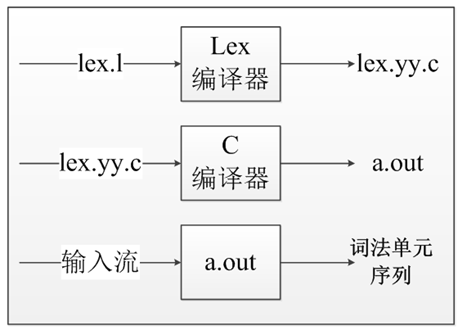
在 linux 下,使用的是 flex 工具,与 lex 相同。
词法分析需要修改 GCC 源码,这里就不叙述了。
可以查看书籍《深入分析 GCC》第 4.5.2 节
GCC编译器原理(三)------编译原理三:编译过程(2-1)---编译之词法分析的更多相关文章
- gcc编译器参数使用及解决
gcc -c CStringAndPointer.c -o CStringAndPointer.o 执行时出现问题: ./CStringAndPointer.o bash: ./CStringAndP ...
- GCC编译器原理(三)------编译原理三:编译过程---预处理
Gcc的编译流程分为了四个步骤: 预处理,生成预编译文件(.文件):gcc –E hello.c –o hello.i 编译,生成汇编代码(.s文件):gcc –S hello.i –o hello. ...
- 跟vczh看实例学编译原理——三:Tinymoe与无歧义语法分析
文章中引用的代码均来自https://github.com/vczh/tinymoe. 看了前面的三篇文章,大家应该基本对Tinymoe的代码有一个初步的感觉了.在正确分析"print ...
- jQuery-1.9.1源码分析系列(三) Sizzle选择器引擎——编译原理
这一节要分析的东东比较复杂,篇幅会比较大,也不知道我描述后能不能让人看明白.这部分的源码我第一次看的时候也比较吃力,现在重头看一遍,再分析一遍,看能否查缺补漏. 看这一部分的源码需要有一个完整的概念后 ...
- gcc/g++等编译器 编译原理: 预处理,编译,汇编,链接各步骤详解
摘自http://blog.csdn.net/elfprincexu/article/details/45043971 gcc/g++等编译器 编译原理: 预处理,编译,汇编,链接各步骤详解 C和C+ ...
- 正则表达式引擎的构建——基于编译原理DFA(龙书第三章)——3 计算4个函数
整个引擎代码在github上,地址为:https://github.com/sun2043430/RegularExpression_Engine.git nullable, firstpos, la ...
- GCC编译器原理(二)------编译原理一:ELF文件(2)
四. ELF 文件格式分析 ELF文件(目标文件)格式主要四种: 可重定向文件: 文件保存着代码和适当的数据,用来和其他的目标文件一起来创建一个可执行文件或者是一个共享目标文件.(目标文件或者静态库文 ...
- 学了编译原理能否用 Java 写一个编译器或解释器?
16 个回答 默认排序 RednaxelaFX JavaScript.编译原理.编程 等 7 个话题的优秀回答者 282 人赞同了该回答 能.我一开始学编译原理的时候就是用Java写了好多小编译器和 ...
- 浅谈C++编译原理 ------ C++编译器与链接器工作原理
原文:https://blog.csdn.net/zyh821351004/article/details/46425823 第一篇: 首先是预编译,这一步可以粗略的认为只做了一件事情,那就 ...
- Knowledge Point 20180303 对比编译器、解释器与Javac编译原理
编译器与Javac编译原理 在前文我们知道了Java是一种编译语言和解释语言,它的源代码经过编译器Javac编译为能够被JVM识别的二进制语言,然后JVM将其解释为能够被平台识别的机器语言.那么什么是 ...
随机推荐
- HR_Counting Valleys
把字符串数字化之后应该从 i>0开始判断而不是 i>1 因此错了4个testcases. #!/bin/python3 import math import os import rando ...
- centos7搭建ELK Cluster集群日志分析平台(三):Kibana
续 centos7搭建ELK Cluster集群日志分析平台(一) 续 centos7搭建ELK Cluster集群日志分析平台(二) 已经安装好elasticsearch 5.4集群和logst ...
- linux(fedora) 第三课
树形打印所有进程名:pstree pstree | grep pstree -A2 -B2(查看pstree前后两行) NI的值[-20,20) nice(改变NI的值):改变程序优先级 nice - ...
- Python3 与 C# 扩展之~模块专栏
代码裤子:https://github.com/lotapp/BaseCode/tree/maste 在线编程:https://mybinder.org/v2/gh/lotapp/BaseCode ...
- twitter api
1,twurl安装 1.1,安装软件管理包工具,在管理员身份打开的cmd中执行: @"%SystemRoot%\System32\WindowsPowerShell\v1.0\powersh ...
- Django(十二)—关于查询知识点总结
https://www.cnblogs.com/haiyan123/p/7763710.html models.Book.objects.filter(**kwargs): querySet ...
- vcf文件去除非变异的基因型(use GATK exclude nonvariant in vcf format,0|0,0/0)
对于某些特殊vcf,想去除没有变异的基因型(主要形式为0|0或者0/0),则需要用到GATK的--excludeNonVariants参数,命令行如下: java -Xmx8g -jar Genome ...
- hdu 2973"YAPTCHA"(威尔逊定理)
传送门 题意: 给出自然数 n,计算出 Sn 的值,其中 [ x ]表示不大于 x 的最大整数. 题解: 根据威尔逊定理,如果 p 为素数,那么 (p-1)! ≡ -1(mod p),即 (p-1)! ...
- CSS 条件判断、等宽字体以及ch单位
<!DOCTYPE> <html lang="en"> <head> <meta charset="utf-8"> ...
- (基础 输入方法 栈)P1427 小鱼的数字游戏 洛谷
题目描述 小鱼最近被要求参加一个数字游戏,要求它把看到的一串数字(长度不一定,以0结束,最多不超过100个,数字不超过2^32-1),记住了然后反着念出来(表示结束的数字0就不要念出来了).这对小鱼的 ...