Spark MLlib线性回归代码实现及结果展示
线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。
这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为一元线性回归,大于一个自变量情况的叫做多元线性回归。
代码实现:
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrame
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.regression.LinearRegression
/**
* Created by zhen on 2018/3/10.
*/
object LinearRegression {
def main(args: Array[String]) {
//设置环境
val spark = SparkSession.builder ().appName ("LinearRegressionTest").master ("local[2]").getOrCreate()
val sc = spark.sparkContext
val sqlContext = spark.sqlContext
//准备训练集合
val raw_data = sc.textFile("src/sparkMLlib/man.txt")
val map_data = raw_data.map{x=>
val mid = x.replaceAll(","," ,")
val split_list = mid.substring(0,mid.length-1).split(",")
for(x <- 0 until split_list.length){
if(split_list(x).trim.equals("")) split_list(x) = "0.0" else split_list(x) = split_list(x).trim
}
( split_list(1).toDouble,split_list(2).toDouble,split_list(3).toDouble,split_list(4).toDouble,
split_list(5).toDouble,split_list(6).toDouble,split_list(7).toDouble,split_list(8).toDouble,
split_list(9).toDouble,split_list(10).toDouble,split_list(11).toDouble)
}
val mid = map_data.sample(false,0.6,0)//随机取样,训练模型
val df = sqlContext.createDataFrame(mid)
val colArray = Array("c1", "c2", "c3", "c4", "c5", "c6", "c7", "c8", "c9", "c10", "c11")
val data = df.toDF("c1", "c2", "c3", "c4", "c5", "c6", "c7", "c8", "c9", "c10", "c11")
val assembler = new VectorAssembler().setInputCols(colArray).setOutputCol("features")
val vecDF = assembler.transform(data)
//准备预测集合
val map_data_for_predict = map_data
val df_for_predict = sqlContext.createDataFrame(map_data_for_predict)
val data_for_predict = df_for_predict.toDF("c1", "c2", "c3", "c4", "c5", "c6", "c7", "c8", "c9", "c10", "c11")
val colArray_for_predict = Array("c1", "c2", "c3", "c4", "c5", "c6", "c7", "c8", "c9", "c10", "c11")
val assembler_for_predict = new VectorAssembler().setInputCols(colArray_for_predict).setOutputCol("features")
val vecDF_for_predict: DataFrame = assembler_for_predict.transform(data_for_predict)
// 建立模型,进行预测
// 设置线性回归参数
val lr1 = new LinearRegression()
val lr2 = lr1.setFeaturesCol("features").setLabelCol("c5").setFitIntercept(true)
// RegParam:正则化
val lr3 = lr2.setMaxIter(10).setRegParam(0.3).setElasticNetParam(0.8)
// 将训练集合代入模型进行训练
val lrModel = lr3.fit(vecDF)
// 输出模型全部参数
lrModel.extractParamMap()
//coefficients 系数 intercept 截距
println(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}")
// 模型进行评价
val trainingSummary = lrModel.summary
trainingSummary.residuals.show()
println(s"均方根差: ${trainingSummary.rootMeanSquaredError}")//RMSE:均方根差
println(s"判定系数: ${trainingSummary.r2}")//r2:判定系数,也称为拟合优度,越接近1越好
val predictions = lrModel.transform(vecDF_for_predict)
val predict_result = predictions.selectExpr("features","c5", "round(prediction,1) as prediction")
predict_result.rdd.saveAsTextFile("src/sparkMLlib/manResult")
sc.stop()
}
}
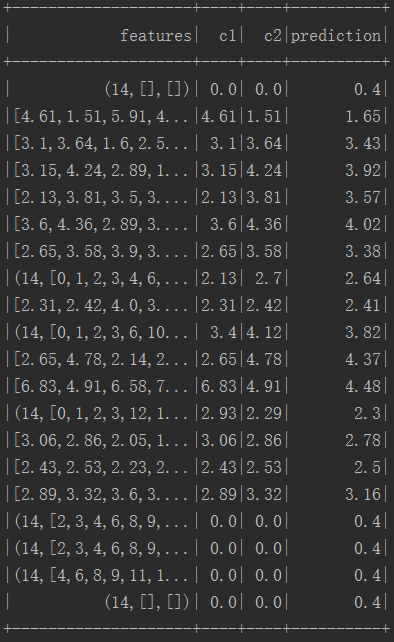
性能评估:

结果:
Spark MLlib线性回归代码实现及结果展示的更多相关文章
- Spark MLlib 示例代码阅读
阅读前提:有一定的机器学习基础, 本文重点面向的是应用,至于机器学习的相关复杂理论和优化理论,还是多多看论文,初学者推荐Ng的公开课 /* * Licensed to the Apache Softw ...
- Spark MLlib回归算法------线性回归、逻辑回归、SVM和ALS
Spark MLlib回归算法------线性回归.逻辑回归.SVM和ALS 1.线性回归: (1)模型的建立: 回归正则化方法(Lasso,Ridge和ElasticNet)在高维和数据集变量之间多 ...
- Spark MLlib之线性回归源代码分析
1.理论基础 线性回归(Linear Regression)问题属于监督学习(Supervised Learning)范畴,又称分类(Classification)或归纳学习(Inductive Le ...
- Spark mllib 随机森林算法的简单应用(附代码)
此前用自己实现的随机森林算法,应用在titanic生还者预测的数据集上.事实上,有很多开源的算法包供我们使用.无论是本地的机器学习算法包sklearn 还是分布式的spark mllib,都是非常不错 ...
- Spark Mllib里如何生成KMeans的训练样本数据、生成线性回归的训练样本数据、生成逻辑回归的训练样本数据和其他数据生成
不多说,直接上干货! 具体,见 Spark Mllib机器学习(算法.源码及实战详解)的第2章 Spark数据操作
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- Spark MLlib 机器学习
本章导读 机器学习(machine learning, ML)是一门涉及概率论.统计学.逼近论.凸分析.算法复杂度理论等多领域的交叉学科.ML专注于研究计算机模拟或实现人类的学习行为,以获取新知识.新 ...
- 《Spark MLlib机器学习实践》内容简介、目录
http://product.dangdang.com/23829918.html Spark作为新兴的.应用范围最为广泛的大数据处理开源框架引起了广泛的关注,它吸引了大量程序设计和开发人员进行相 ...
- Spark入门实战系列--8.Spark MLlib(下)--机器学习库SparkMLlib实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .MLlib实例 1.1 聚类实例 1.1.1 算法说明 聚类(Cluster analys ...
随机推荐
- Android利用Intent与其他应用交互
前言: 上一篇博客给大家聊了Intent的定义,分类.属性和功能,相信大家对于Intent在Android中的作用已经清楚,这一篇博客将会给大家聊Intent的用法. Android系统的一个重要特性 ...
- kafka配置项host.name advertised.host.name
遇到的问题: 在本机或者其他机器telnet IP 9092,通,使用域名也通,telnet 127.0.0.1 9092不通 host.name:按配置文件说明,是Kafka绑定的interface ...
- MFC控件编程之 按钮编辑框.静态文本的使用,以及访问控件的七种方法.
MFC控件编程之 按钮编辑框.静态文本的使用以及访问控件的七种方法. 一丶按钮.静态文本的通用属性. 他们都有一个属性.就是可以输入标题内容.以及可以自定义控件ID. 创建一个MFC Dlg对话框. ...
- linux 两个查找工具 locate,find
linux 中有很多查找工具,今天主要讲解locate,find两个工具. 一.locate 1.性能介绍 查询系统上预建的文件索引数据库 /var/lib/mlocate/mlocate.db 注意 ...
- Spring基础系列-Spring事务不生效的问题与循环依赖问题
原创作品,可以转载,但是请标注出处地址:https://www.cnblogs.com/V1haoge/p/9476550.html 一.提出问题 不知道你是否遇到过这样的情况,在ssm框架中开发we ...
- Asp.Net项目的部署到Linux中(Linux + Jexus+Nginx )
因为老项目用的Asp.Net Web API技术开发部署到Window系统上,而新项目用的是.Net Core部署到Ubuntu系统中,所以在管理切换上有些不便.于是决定将老项目的测试服部署到Ubun ...
- 应用负载均衡之LVS(三):ipvsadm命令
*/ .hljs { display: block; overflow-x: auto; padding: 0.5em; color: #333; background: #f8f8f8; } .hl ...
- 分布式系统监视zabbix讲解七之分布式监控--技术流ken
分布式监控 概述 Zabbix通过Zabbix proxy为IT基础设施提供有效和可用的分布式监控 代理(proxy)可用于代替Zabbix server本地收集数据,然后将数据报告给服务器. Pro ...
- 【转载】微软官方提供的Sqlserver数据库操作帮助类SQLHelper类
在.NET平台中,C#语言一般使用ADO.NET组件来操作Sqlserver数据库,通过ADO.NET组件可以实现连接数据库.查询数据集.执行SQL语句以及关闭数据库连接等操作,为此网上有很多开发者自 ...
- nginx静态资源文件无法访问,403 forbidden错误
在安装 nginx 服务器后,我想把网站的根目录设置为 /root/www/ ,于是对 nginx 的 nginx.conf 文件进行配置 先打开 nginx.conf #user nobody; w ...