爬虫之抓取js生成的数据
有很多页面,当我们用request发送请求,返回的内容里面并没有页面上显示的数据,主要有两种情况,一是通过ajax异步发送请求,得到响应把数据放入页面中,对于这种情况,我们可以查看关于ajax的请求,然后分析ajax请求路径和响应,拿到想要的数据;另外一种就是js动态加载得到的数据,然后放入页面中。这两种情况下,对于用户利用浏览器访问时,都不会发现有什么异常,会迅速的得到完整页面。
其实我们之前学过一个selenium模块,通过操纵浏览器,然后拿到浏览器显示出来的数据,这种方式是可以拿到数据的,但本节是要分析如何找到那个js在控制数据的生成,及js发送请求的路径,从而我们可以向这个路径发送请求,直接就得到数据。
在之前的爬虫过程中,我最烦的就是关于js动态生成的数据,我根本无法找到是哪一个js实现的(因为js太多了),今天看了大佬的博客,瞬间感觉简单了很多,谢谢大佬,祭出大佬的博客:https://www.cnblogs.com/bobo-zhang/p/10561617.html
一、需求描述及页面分析
1,需求描述
基础页面路径:https://www.xuexi.cn/f997e76a890b0e5a053c57b19f468436/018d244441062d8916dd472a4c6a0a0b.html
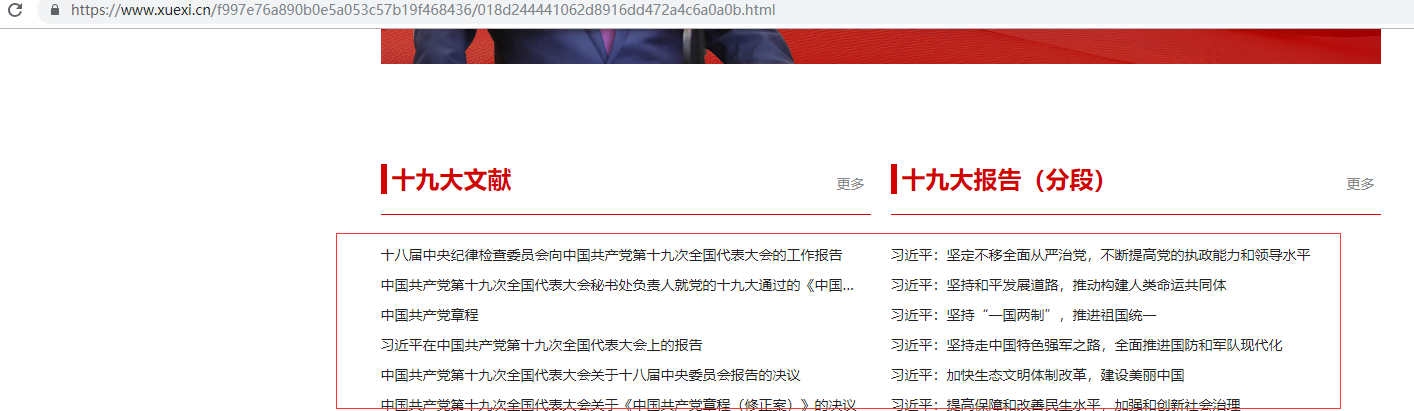
点击进入每个标题里面:
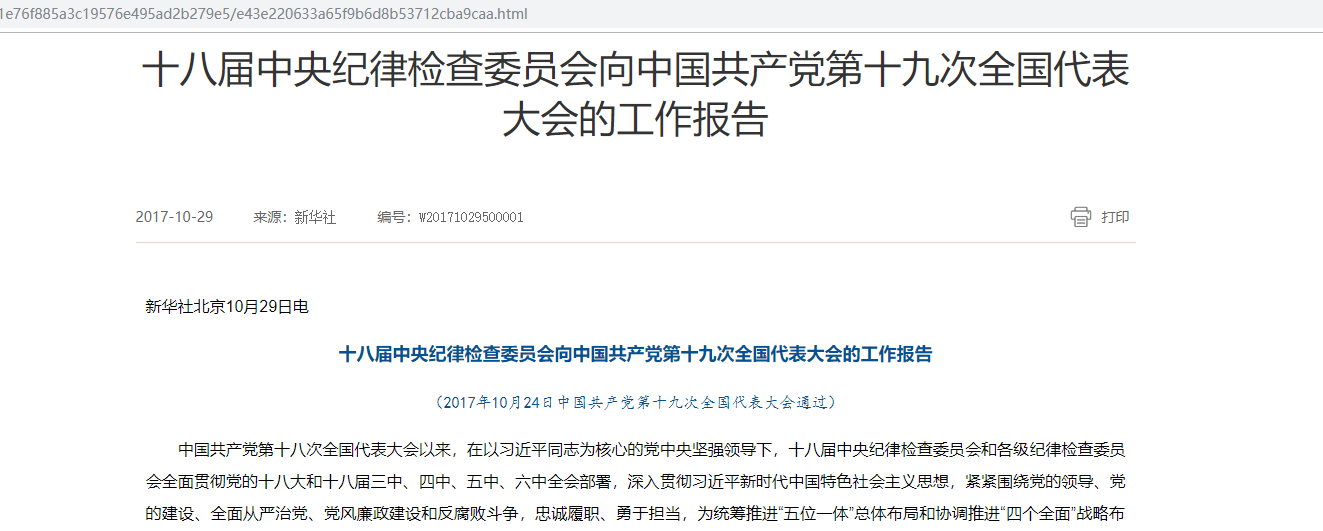
需求就是爬取每个标题下的新闻内容
2,页面分析
2.1 主页面
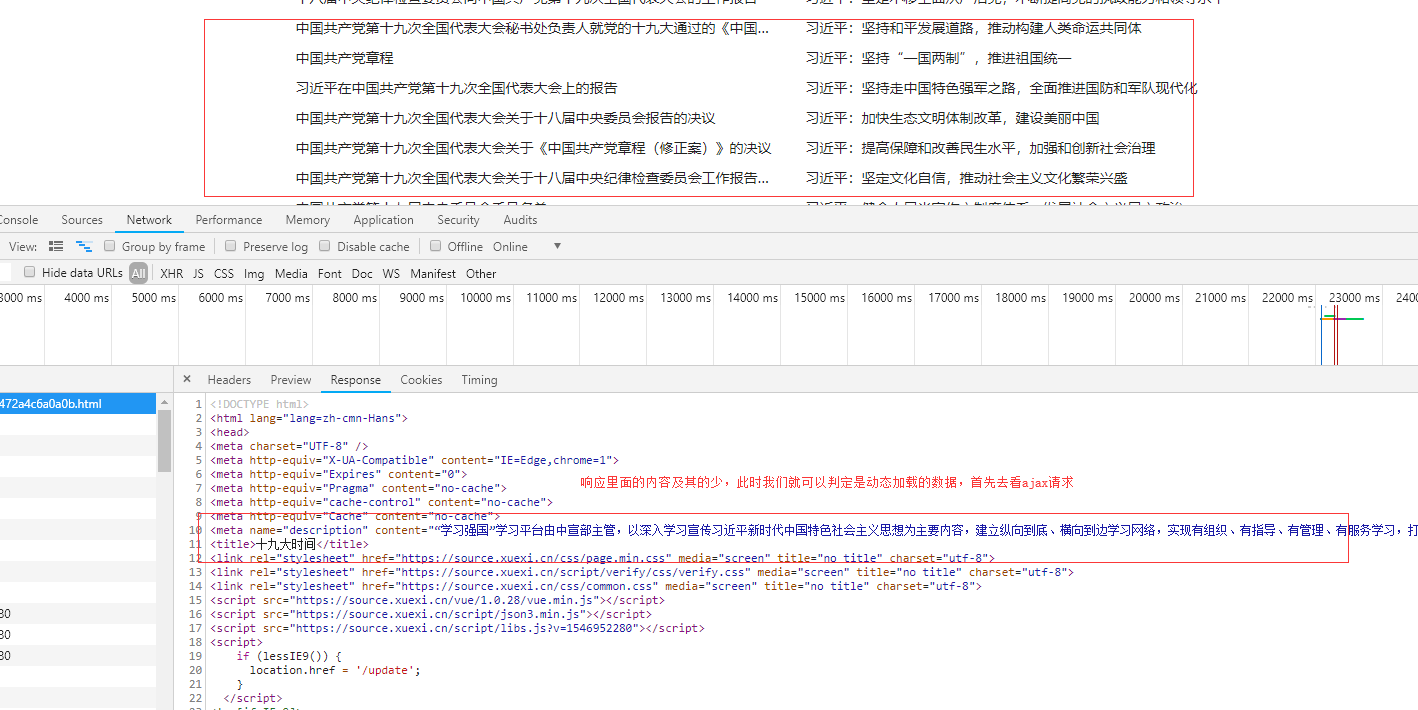
查看ajax请求:
接下来我们就解析如何找出发送请求的js
二、查找发送请求的js
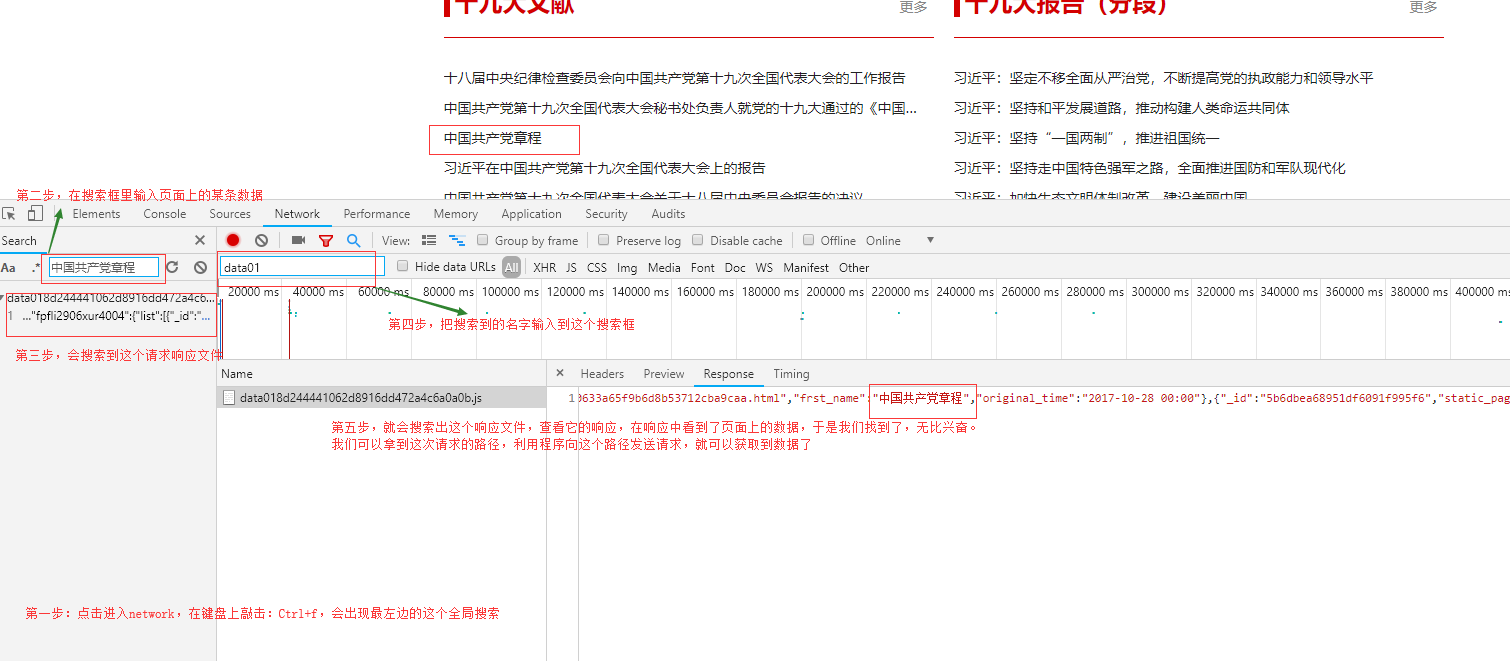
在响应的数据里,包含新闻标题,以及本条新闻的详情页路径,于是现在我们去访问详情页,以及分析详情页
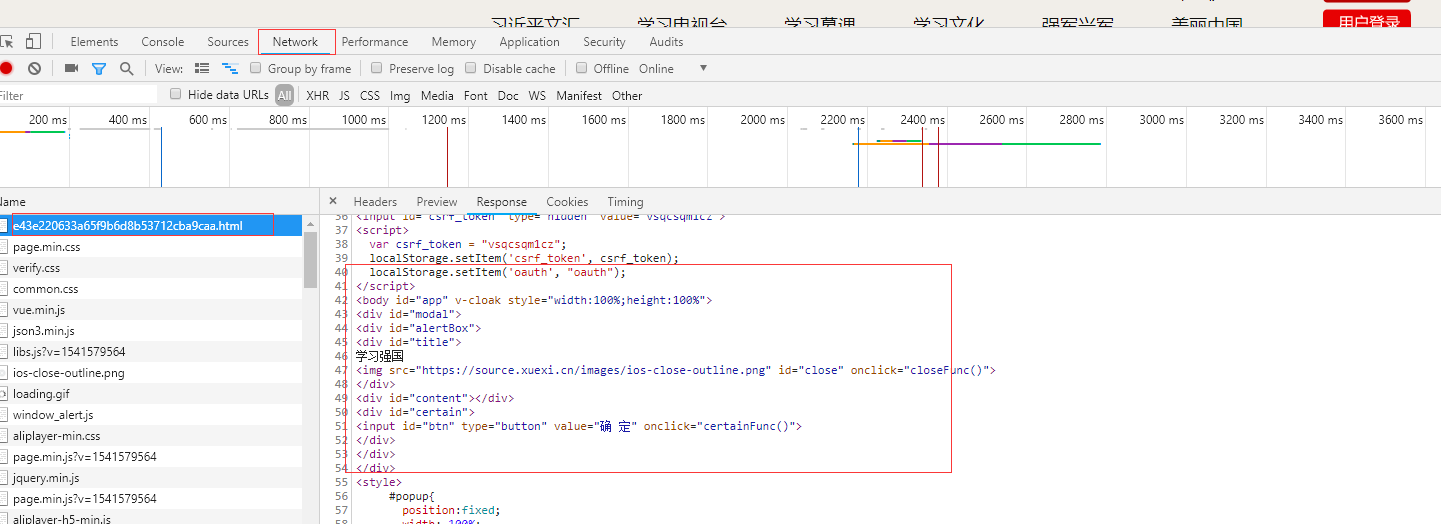
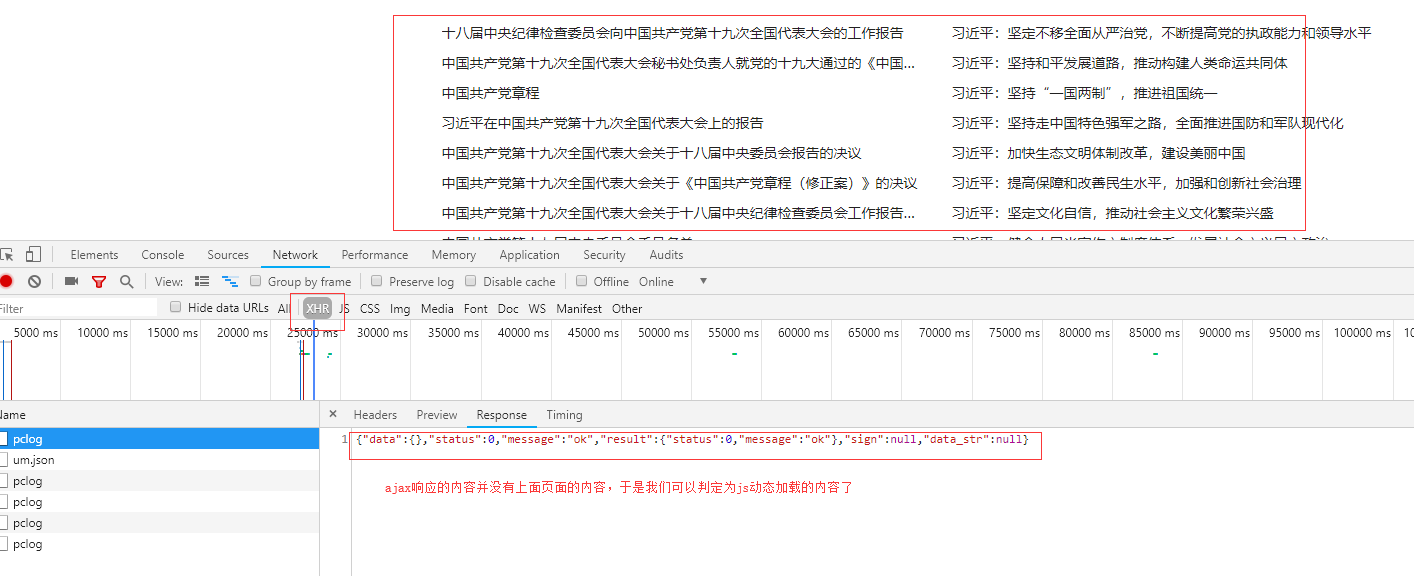
访问详情页,查看详情页的响应,数据里面也没包含具体数据,那它就和主页面一样,接下来去看ajax:
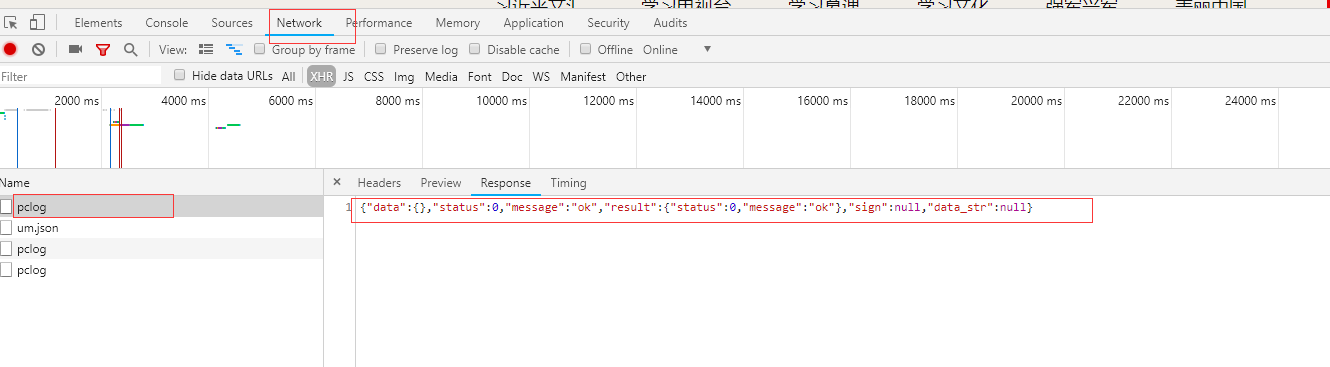
ajax并没有新闻相关数据,所以不是利用ajax请求拿到数据的,那只有剩下js了,我们就去寻找是哪个js发送的请求来获取数据,步骤上面一致:
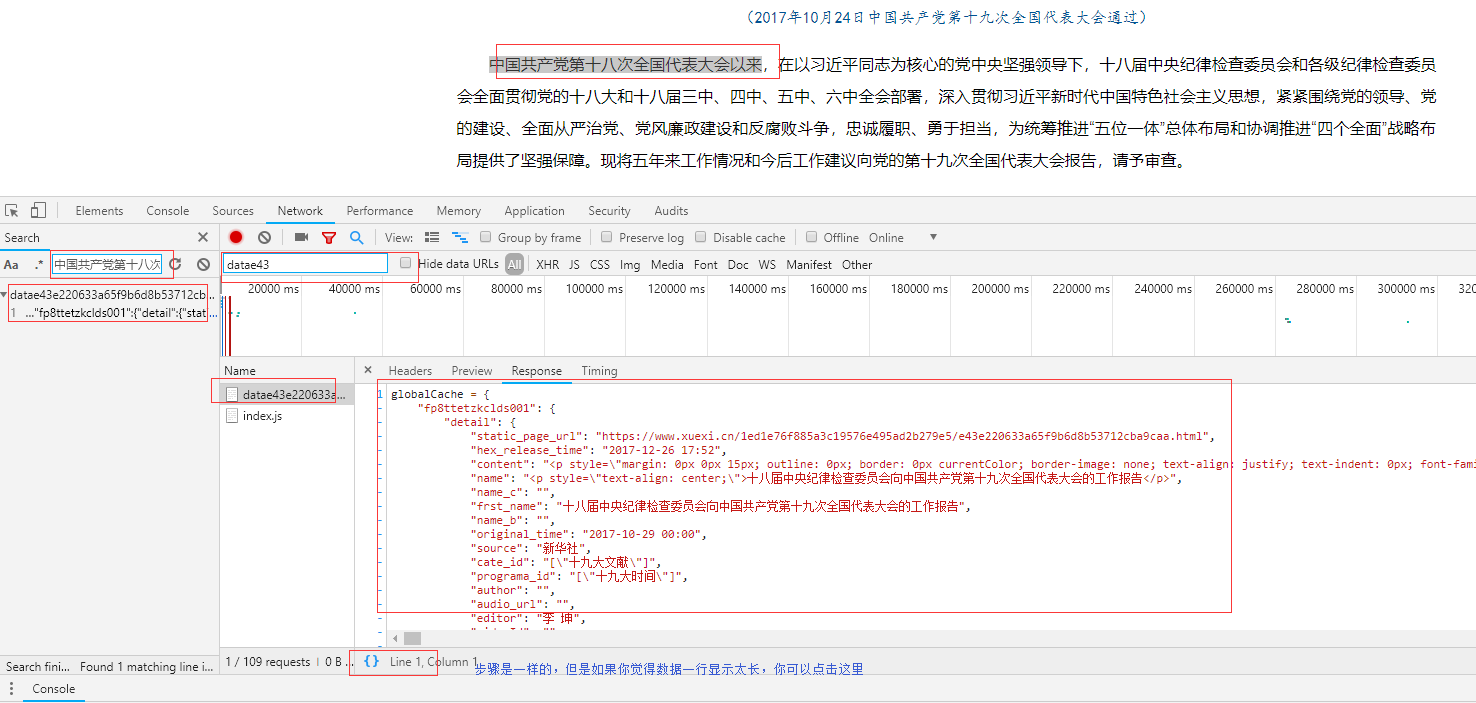
详情页数据的js请求路径:

详情页请求路径:

我们可以看到,详情页数据的请求路径在最后一个斜杠前面的路径和详情页的请求路径在最后一个斜杠前面都是一样的。于是我们可以这样:
第一步:拿到详情页的请求路径:
url1='https://www.xuexi.cn/1ed1e76f885a3c19576e495ad2b279e5/e43e220633a65f9b6d8b53712cba9caa.html'
第二步:把url1最后一个斜杠后面的内容替换掉
url2='https://www.xuexi.cn/%s/datae43e220633a65f9b6d8b53712cba9caa.js'%(url1.split('/')[3]) #把url1用‘/’分割,拿到第四部分,即索引为3,然后拼接进去既可
这样就构造好了一个详情页数据请求路径,然后直接去访问这个路径既可拿到数据,就不用去访问详情页了
爬虫之抓取js生成的数据的更多相关文章
- 如何用python抓取js生成的数据 - SegmentFault
如何用python抓取js生成的数据 - SegmentFault 如何用python抓取js生成的数据 1赞 踩 收藏 想写一个爬虫,但是需要抓去的的数据是js生成的,在源代码里看不到,要怎么才能抓 ...
- htmilunit-- 针对抓取js生成的数据
public static String getHtml(String html){ // 模拟一个浏览器 @SuppressWarnings("resou ...
- 【转】Python爬虫:抓取新浪新闻数据
案例一 抓取对象: 新浪国内新闻(http://news.sina.com.cn/china/),该列表中的标题名称.时间.链接. 完整代码: from bs4 import BeautifulSou ...
- Python爬虫:抓取新浪新闻数据
案例一 抓取对象: 新浪国内新闻(http://news.sina.com.cn/china/),该列表中的标题名称.时间.链接. 完整代码: from bs4 import BeautifulSou ...
- java网络爬虫----------简单抓取慕课网首页数据
© 版权声明:本文为博主原创文章,转载请注明出处 一.分析 1.目标:抓取慕课网首页推荐课程的名称和描述信息 2.分析:浏览器F12分析得到,推荐课程的名称都放在class="course- ...
- Python爬虫:抓取手机APP的数据
摘要 大多数APP里面返回的是json格式数据,或者一堆加密过的数据 .这里以超级课程表APP为例,抓取超级课程表里用户发的话题. 1.抓取APP数据包 表单: 表单中包括了用户名和密码,当然都是加密 ...
- 抓取Js动态生成数据且以滚动页面方式分页的网页
代码也可以从我的开源项目HtmlExtractor中获取. 当我们在进行数据抓取的时候,如果目标网站是以Js的方式动态生成数据且以滚动页面的方式进行分页,那么我们该如何抓取呢? 如类似今日头条这样的网 ...
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据 1.豆瓣地址:https://movie.douban.com/top250?start=25&filter= 2.主要流程是抓取该网址下的Top25 ...
随机推荐
- 转发对python装饰器的理解
[Python] 对 Python 装饰器的理解的一些心得分享出来给大家参考 原文 http://blog.csdn.net/sxw3718401/article/details/3951958 ...
- poj 3687 Labeling Balls(拓补排序)
Description Windy has N balls of distinct weights from 1 unit to N units. Now he tries to label them ...
- SSRF
SSRF 关于SSRF SSRF(Server-Side Request Forgery:服务器端请求伪造),攻击者通过伪造服务器端发起的请求,获取客户端所不能得到的数据.一般情况下,SSRF攻击的目 ...
- Windows与系统信息相关的DOS命令
首先,以管理员身份打开CMD命令框, 输入 start msinfo32:回车之后,出现一个弹窗,上面有大部分的系统信息:系统版本,电脑名称,BIOS,CPU,内存等: wmic bios:显示BIO ...
- docker install
1.安装必要工具集 sudo yum install -y yum-utils 2.安装Docker官方源 sudo yum-config-manager \ --add-repo \ https:/ ...
- 《java多线程编程核心技术》(一)使用多线程
了解多线程 进程和多线程的概念和线程的优点: 提及多线程技术,不得不提及"进程"这个概念.百度百科对"进程"的解释如下: 进程(Process)是计算机中的程序 ...
- (二)Javascript面向对象编程:构造函数的继承
Javascript面向对象编程:构造函数的继承 这个系列的第一部分,主要介绍了如何"封装"数据和方法,以及如何从原型对象生成实例. 今天要介绍的是,对象之间的"继承 ...
- bash基础特性3(shell编程)
Linux上文本处理三剑客: grep:文本过滤工具 sed:stream editor,文本编辑工具 awk:文本报告生成器 grep -v:显示不能够被pattern匹配到的行 -i:忽略字符大小 ...
- CTF中文件包含的一些技巧
i春秋作家:lem0n 原文来自:浅谈内存取证 0x00 前言 网络攻击内存化和网络犯罪隐遁化,使部分关键数字证据只存在于物理内存或暂存于页面交换文件中,这使得传统的基于文件系统的计算机取证不能有效应 ...
- 基于kNN的手写字体识别——《机器学习实战》笔记
看完一节<机器学习实战>,算是踏入ML的大门了吧!这里就详细讲一下一个demo:使用kNN算法实现手写字体的简单识别 kNN 先简单介绍一下kNN,就是所谓的K-近邻算法: [作用原理]: ...