论文阅读笔记八:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation (IEEE2017)

原文链接:https://arxiv.org/pdf/1511.00561.pdf
github(tensorflow):https://github.com/aizawan/segnet
基于SegNet的钢铁分割实验:https://github.com/fourmi1995/IronSegExprement-SegNet
摘要
Segnet是用于进行像素级别图像分割的全卷积网络,分割的核心组件是一个encoder 网络,及其相对应的decoder网络,后接一个象素级别的分类网络。encoder网络:其结构与VGG16网络的前13层卷积层的结构相似。decoder网络:作用是将由encoder的到的低分辨率的feature maps 进行映射得到与输入图像featuremap相同的分辨率进而进行像素级别的分类。Segnet的亮点:decoder进行上采样的方式,直接利用与之对应的encoder阶段中进行max-pooling时的polling index 进行非线性上采样,这样做的好处是上采样阶段就不需要进行学习。 上采样后得到的feature maps 是非常稀疏的,因此,需要进一步选择合适的卷积核进行卷积得到dense featuremaps 。作者与FCN,DeepLab-LargeFOV, DenconvNet结构进行比较,统筹内存与准确率,Segnet实现良好的分割效果。SegNet主要用于场景理解应用,需要在进行inference时考虑内存的占用及分割的准确率。同时,Segnet的训练参数较少(将前面提到的VGG16的全连接层剔除),可以用SGD进行end-to-end训练。
说明
在decoder 网络中重用encder 网络中对应max pooling index的三点好处:(i)提高边界划分 (ii)减少训练的参数 (iii)这种形式可以广泛的应用在其他encoder-decoder结构。
本文重点是分析SegNet的decoding模块和FCN网络,目前的分割网络都有相似的编码结构(VGG16)但是decoder网络的结构各异,同时训练和推理形式等也有所不同。由于大量训练参数导致进行end-to-end training困难度较大。因此产生多步训练方式,将预训练好的网络添加到FCN后进行再训练,同时,使用一些辅助性操作,如用于inference的region proposals,用于分类网络和分割网络的不相交训练,使用额外的训练数据作为预训练或者全局训练,另外,提升预处理技术也比较流行。
相关工作(可略过)
在深度网络兴起之前,实现像素级语义分割最好的是基于手工设计的特征分别对每个像素进行分类,典型的是将一个patch送入分类器(随机森林,Boosting)来预测中心那个像素的类别概率。基于外形或者SfM已被用于Camvid的场景理解测试,成对或者更高级的CRF平滑预测出的噪声进而提高准确率。而近年来更倾向于预测整个patch的每个像素的类别,而不是中心像素的类别。由于随机森林更偏向于分错类样本的训练,因此,准确率会有改善,而不利于结构性类别的分类。从Camvid视频集中计算得到的深度图被用于随机森林的分类。另一种方法是利用流行的手工设计的特征和空间超像素特征来获得更高的准确率。Camvid中表现最好的技术是将目标检测的输出与CRF中的分类器预测相结合解决标签频率不平衡问题。所有结果都表明用于提升分类特征的必要性。
NYU数据集表明通道数的对于分割效果的提升的作用较弱。用到的特征如RGB-SIFT,depth-SIFT 和像素位置。对于噪声采用CRF进行平滑。后来用更加丰富的特征集包括LBP和区域分割后接CRF来提高准确率。更近期的工作,利用RGB和基于深度的融合信息来推理类别分割,及支持关联。另一种方法致力于基于随机森林分类器的实时重建和语义分割。这些方法的共性是都是基于手工设计的特征来对RGB或者RGBD图像进行分类。
随着深度卷积网络的兴起,让研究者探索网络特征学习的能力用于分割等结构预测问题,一种是复制网络中最深层的特征并变换匹配图像尺寸,然而结果是块状的。另一种利用RRN融合多个低分辨率的预测进而生成输入图像分辨率的预测。这些相比于手工特征已经有所进步,但对界定边界仍不足。
较新的深度结构通过学习decode或map较低频率图片表示为像素级的预测。encoder网络基于VGG16分类网络产生低分辨率的特征表示。VGG16=Conv*13+FC*3,encoder网络的权重 在ImageNet的目标分类中进行预训练。decoder网络更具不同结构而各异。同时产生多维度特征用于对每个像素进行分类。
FCN中的decoder将特征图进行上采样,同时结合相应的encoder特征图,然后送入下一个encoder。FCN encoder参数量较大(134M)而decoder很少(0.5M),整体很难进行end-to-end训练。对此,作者使用阶段性训练。在一个存在的训练网络中添加一个decoder网络直到performance不能再进行提升。FCN中在三个decoder后就停止,所以忽略了高分辨率的特征,导致edge information的损失。同时,在进行测试过程中重利用encoder中的特征使内存变得紧张。
通过在FCN网络后接RNN,同时用大数据集的fine-tune 可以提高FCN的预测性能。RNN模仿CRF较强的边界界定,也利用了FCN的特征表示。这种方式明显优于FCN-8,但随着训练数据的加大,二者效果相差不大。CRF-RNN与FCN-8等结构进行共同训练时,CRF-RNN的优势得以体现。虽然反卷积网络需要消耗更多的计算资源,但是效果比FCN要好。CRF—RNN可以被添加到任何分割网络后面。
多尺寸网络的两个特点:(i)使用多尺度的输入图片以及相应的深度特征提取网络。(ii)单个网络中不同层特征图的组合。利用在多个尺度上提取的特征来提供局部和全局的上下文信息,同时利用早期encoder保存的高质量的细节信息来锐化分类边界。
Deconvolutional网络及其半监督形式的变体,利用encoder max pooling过程最大值的位置进行非线性上采样,但其encoder 中的VGG16用到其FC层,导致训练参数很大,不易进行训练。
结构
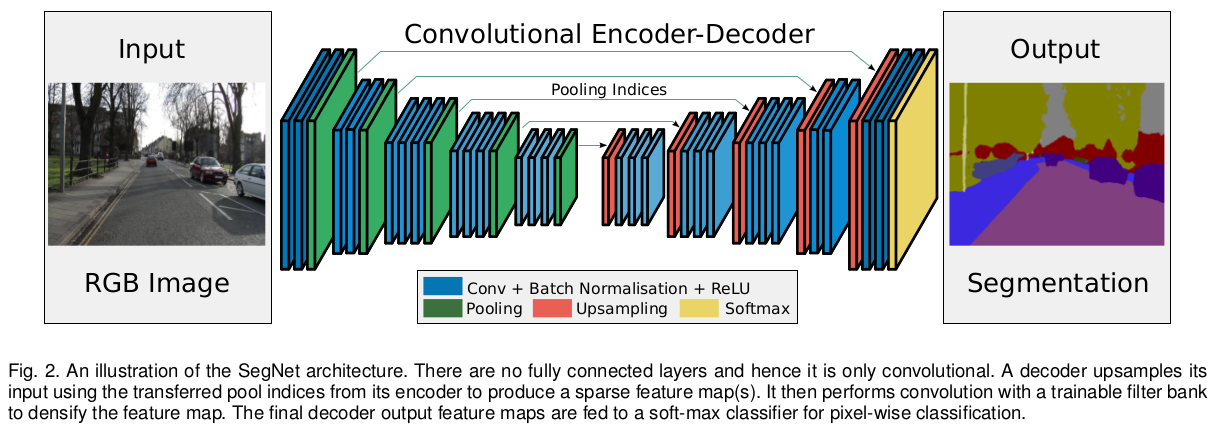
SegNet由编码网络,解码网络后接一个分类层组成。编码网络由13个卷积层组成,与VGG16的前13层卷积相同,将VGG16在大型数据集上训练得到的权重值作为编码网络的权重初始值,为了保留encoder 最深层输出的到高分辨率的feature maps,删掉VGG16中的全连接层,这么做的一个好处是可以大幅度减少encoder层中训练参数的数量(from 134M to 14.7M),每一层encoder都对应着一层decoder,因此decoder网络也是13层,在decoder网络输出后接一个多分类的soft-max分类器对每个像素生成类别概率。
encod网络中的每一个编码器通过一组卷积核来产生一系列的feature maps,后接一层BN+RELU+Max-pooling(2x2,stride=2),Max-pooling用于实现小空间移动上的空间不变性,同时,可以在feature map上有较大的感受野,但由于使用Max-pooling 导致分辨率上的损失。这种损失对边界界定产生不利的影响,因此encoder网络要在进行下采样前着重捕捉和保存边界信息。由于实际内存的限制,所以无法保存feature map 的全部信息。本文提出只保存encode Max-pooling中feature map value值最大的位置。对于pooling 2*2的窗口可以用2比特位实现,相比存储feature map的float精度,效率较高,但对准确率会有轻微的损失,但仍适用实际应用。
decode网络中的decoder 利用对应encoder feature map中保存的max-index对输入的feature map进行上采样,产生的稀疏feature maps后接一系列可训练的卷积核,输出密集的feature maps,后接BN用于规范化处理正则化减弱过拟合,与输入对应的decoder产生多通道feature map,虽然输入只有(RGB)三通道。其他的encoder,decoder的通道数,尺寸大小都是一一对应。decoder输出的高维度的特征表示被送入一个可训练的soft-max多分类器,对每个像素进行单独分类。
soft-max输出的是一个K(类别数)同的的概率图,预测后的分割图中的每个类别是每个像素中概率值最大所对应的类别。
DeconvNet与U-Net有与Se gNet相似的结构,但DeconvNet有更多的训练参数,需要更多的计算资源而且不利于进行end-to-end的训练。
U-Net不利用max-pooling index而是将整个feature map 送到decoder 拼接到上采样后的feature map,十分占用内存资源,因此U-Net中无法使用到conv5和max-pool5模块,而SegNet却可以利用VGG16全部预训练过的卷积层的权重值。
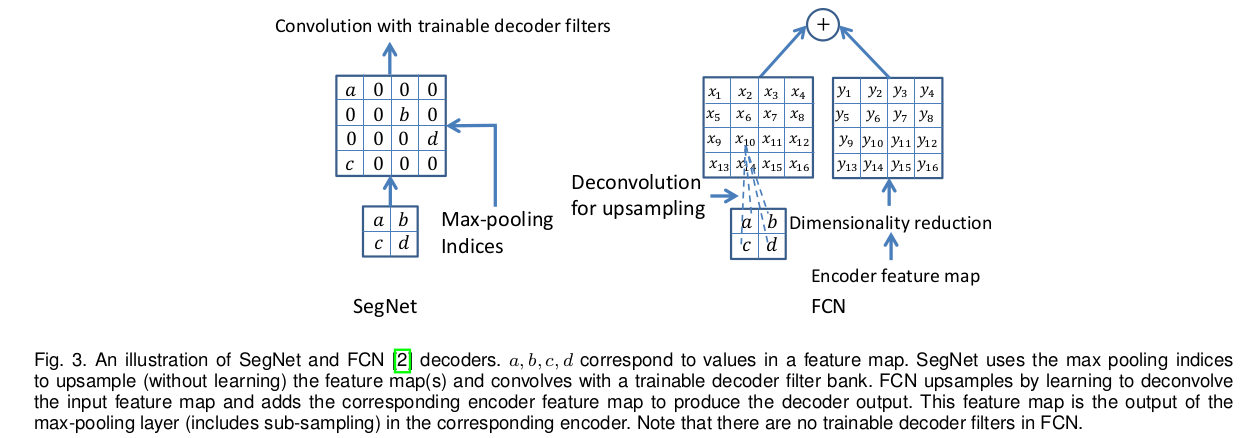
Decoder Variants
许多分割网络的编码网大同小异,而其解码网络的形式却相差很大。SegNet decoding 上采样阶段借用encode阶段产生的最大值的索引,这里不存在可学习的变量,但是上采样后的feature map需要经过可训练的多通道decoder 卷积核来降低输入feature map 的稀疏性。其通道数与上采样得到的feature map数目相同。有种变体是卷积核都是单通道的,只卷积与之对应的上采样后的feature map,此种变体可以减少大量的训练参数。
FCN中一个亮点是编码过程中维度降低,将encoder feature map进行压缩后用于对应的decoder feature map中。encode层中一个64通道的feature map 与1x1x64xK个卷积核卷积将维度讲到K,encoder将压缩后的这K通道的feature map送入decode层。FCN中通过使用固定可训练的多通道的反卷积核实现上采样。这里设置其核的大小为8x8,这里FCN将decode层反卷积后的feature map与对应的encode层的feature map进行相加作为decode层的输出。核的权重值通常采用双线性插值初始化。FCN需要在inference 有特征明显的feature map,这就会造成内存资源的紧张。
其他变体有,将SegNet的decode层通过使用固定的双线性插值赋值,消除可训练参数,另一种极端是,在每一个decode层添加64个对应encode层的feature map。上述两中的maxpooling Index都被使用,后接卷积操作,最后将featur map逐像素送入编码网络作为解码网络的输出。还有将编码层的下采样层去掉,占用计算资源较多且效果较差。
训练
数据集:CamVid (训练:367张,测试:233,图片尺寸:360X480,11个类别)
优化方法:SGD
learning_rate:0.1
momentum: 0.9
mini-batch: 12
loss: cross-entropy
分析
使用三种评价指标:global accuracy 数据集中被正确分类的像素所占的比例。
class average accuracy 每种类别准确率和取平均。
mIoU 惩罚 FalsePositivate 的预测,在每个类别上计算IOU然后取平均值。
实现性能最好的是当encoder 的feature map全部被保存,对于一个给定的encoder 网络,更大的decode网络可以提升性能,当inference 内存被限制时,encoder层压缩后的feature maps(降维,max-pooling indices) 可以进行保存并用适当的解码器来提升性能。
[1] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
个人实验结果


论文阅读笔记八:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation (IEEE2017)的更多相关文章
- 论文阅读笔记五十七:FCOS: Fully Convolutional One-Stage Object Detection(CVPR2019)
论文原址:https://arxiv.org/abs/1904.01355 github: tinyurl.com/FCOSv1 摘要 本文提出了一个基于全卷积的单阶段检测网络,类似于语义分割,针对每 ...
- 论文阅读笔记二十:LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation(CVPR2017)
源文网址:https://arxiv.org/abs/1707.03718 tensorflow代码:https://github.com/luofan18/linknet-tensorflow 基于 ...
- 论文阅读笔记十三:The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation(FC-DenseNets)(CVPR2016)
论文链接:https://arxiv.org/pdf/1611.09326.pdf tensorflow代码:https://github.com/HasnainRaz/FC-DenseNet-Ten ...
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
- [论文阅读笔记] Structural Deep Network Embedding
[论文阅读笔记] Structural Deep Network Embedding 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 现有的表示学习方法大多采用浅层模型,这可能不能 ...
- 论文阅读笔记(十八)【ITIP2019】:Dynamic Graph Co-Matching for Unsupervised Video-Based Person Re-Identification
论文阅读笔记(十七)ICCV2017的扩刊(会议论文[传送门]) 改进部分: (1)惩罚函数:原本由两部分组成的惩罚函数,改为只包含 Sequence Cost 函数: (2)对重新权重改进: ① P ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
- 论文阅读笔记二十一:MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS(ICRL2016)
论文源址:https://arxiv.org/abs/1511.07122 tensorflow Github:https://github.com/ndrplz/dilation-tensorflo ...
- 论文阅读笔记十七:RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation(CVPR2017)
论文源址:https://arxiv.org/abs/1611.06612 tensorflow代码:https://github.com/eragonruan/refinenet-image-seg ...
随机推荐
- C++中,有哪4种与类型转换相关的关键字?各有什么特点?应该在什么场合下使用?
转:https://www.cnblogs.com/mjiang2017/p/9358032.html C++中,四个与类型转换相关的关键字:static_cast.const_cast.reinte ...
- Curator实现分布式锁
分布式锁的应用 分布式锁服务宕机, ZooKeeper 一般是以集群部署, 如果出现 ZooKeeper 宕机, 那么只要当前正常的服务器超过集群的半数, 依然可以正常提供服务 持有锁资源服务器宕机, ...
- laravel 关闭 csrf 验证 TokenMismatchException
csrf验证失败 注释掉kernel.php 的 csrf 行代码
- GridView item设置点击背景
GridView item设置点击背景 android:listSelector="@android:color/transparent"
- mac使用技巧之截图
1.选定区域截图 command+shift+3 选定区域按住control,可以直接截图到剪切板, 按option可以进行比例缩放. 按住shift可以选定区域 按住空格键可以进入窗口截图模式. 2 ...
- DCL单例模式
我们第一次写的单例模式是下面这样的: public class Singleton { private static Singleton instance = null; public static ...
- oracle加密传输
参考文章: http://blog.itpub.net/24052272/viewspace-2129175/ oracle在传输过程中,正常是明文传输的,例如SQL以及执行的结果. 看看做的测试: ...
- HSSFWorkbook操作excel读写
//exlel读操作 MultipartHttpServletRequest multipartRequest = (MultipartHttpServletRequest) request; Ite ...
- Linux more和less
一.more命令 more功能类似 cat ,cat命令是整个文件的内容从上到下显示在屏幕上. more会以一页一页的显示方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按 ...
- 鼠标hover图片时遮罩层匀速上升显示内容top、定位
1.html <div class="div1"> <div class="div11"> <p >Dolor nu ...