吴裕雄 python 机器学习——分类决策树模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier,DecisionTreeRegressor def load_data():
'''
加载用于分类问题的数据集。数据集采用 scikit-learn 自带的 iris 数据集
'''
# scikit-learn 自带的 iris 数据集
iris=datasets.load_iris()
X_train=iris.data
y_train=iris.target
return train_test_split(X_train, y_train,test_size=0.25,random_state=0,stratify=y_train) #分类决策树DecisionTreeClassifier模型
def test_DecisionTreeClassifier(*data):
X_train,X_test,y_train,y_test=data
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
print("Training score:%f"%(clf.score(X_train,y_train)))
print("Testing score:%f"%(clf.score(X_test,y_test))) # 产生用于分类问题的数据集
X_train,X_test,y_train,y_test=load_data()
# 调用 test_DecisionTreeClassifier
test_DecisionTreeClassifier(X_train,X_test,y_train,y_test)

def test_DecisionTreeClassifier_criterion(*data):
'''
测试 DecisionTreeClassifier 的预测性能随 criterion 参数的影响
'''
X_train,X_test,y_train,y_test=data
criterions=['gini','entropy']
for criterion in criterions:
clf = DecisionTreeClassifier(criterion=criterion)
clf.fit(X_train, y_train)
print("criterion:%s"%criterion)
print("Training score:%f"%(clf.score(X_train,y_train)))
print("Testing score:%f"%(clf.score(X_test,y_test))) # 调用 test_DecisionTreeClassifier_criterion
test_DecisionTreeClassifier_criterion(X_train,X_test,y_train,y_test)

def test_DecisionTreeClassifier_splitter(*data):
'''
测试 DecisionTreeClassifier 的预测性能随划分类型的影响
'''
X_train,X_test,y_train,y_test=data
splitters=['best','random']
for splitter in splitters:
clf = DecisionTreeClassifier(splitter=splitter)
clf.fit(X_train, y_train)
print("splitter:%s"%splitter)
print("Training score:%f"%(clf.score(X_train,y_train)))
print("Testing score:%f"%(clf.score(X_test,y_test))) # 调用 test_DecisionTreeClassifier_splitter
test_DecisionTreeClassifier_splitter(X_train,X_test,y_train,y_test)

def test_DecisionTreeClassifier_depth(*data,maxdepth):
'''
测试 DecisionTreeClassifier 的预测性能随 max_depth 参数的影响
'''
X_train,X_test,y_train,y_test=data
depths=np.arange(1,maxdepth)
training_scores=[]
testing_scores=[]
for depth in depths:
clf = DecisionTreeClassifier(max_depth=depth)
clf.fit(X_train, y_train)
training_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test)) ## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(depths,training_scores,label="traing score",marker='o')
ax.plot(depths,testing_scores,label="testing score",marker='*')
ax.set_xlabel("maxdepth")
ax.set_ylabel("score")
ax.set_title("Decision Tree Classification")
ax.legend(framealpha=0.5,loc='best')
plt.show() # 调用 test_DecisionTreeClassifier_depth
test_DecisionTreeClassifier_depth(X_train,X_test,y_train,y_test,maxdepth=100)

import os
import pydotplus from io import StringIO
from sklearn.tree import export_graphviz
from sklearn.tree import DecisionTreeClassifier,DecisionTreeRegressor X_train,X_test,y_train,y_test=load_data()
clf = DecisionTreeClassifier()
clf.fit(X_train,y_train)
export_graphviz(clf,"F://out")


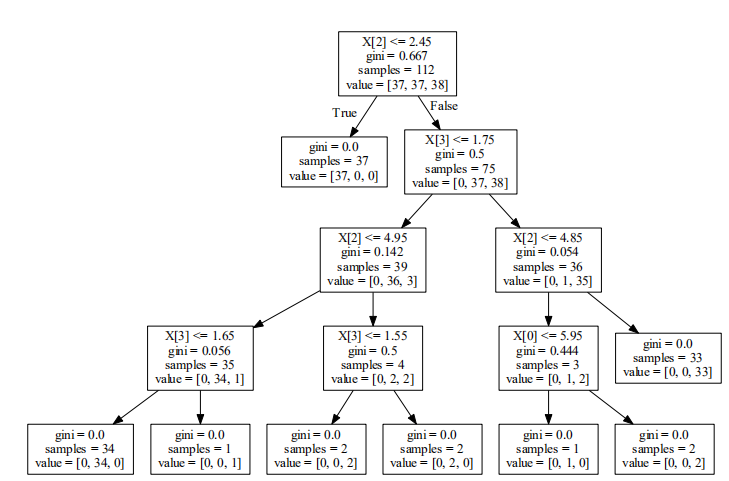
吴裕雄 python 机器学习——分类决策树模型的更多相关文章
- 吴裕雄 python 机器学习——回归决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——核化PCAKernelPCA模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——KNN分类KNeighborsClassifier模型
import numpy as np import matplotlib.pyplot as plt from sklearn import neighbors, datasets from skle ...
- 吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——支持向量机线性分类LinearSVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——模型选择分类问题性能度量
import numpy as np import matplotlib.pyplot as plt from sklearn.svm import SVC from sklearn.datasets ...
随机推荐
- IntellijIDEA常用快捷键总结
转载自:http://blog.csdn.net/qq_17586821/article/details/52554731 下面的这些常用快捷键需要在实际操作中不断地体会才能真正感受到它们的方便之处. ...
- keepalived+mysql主从环境,keepalived返回值是RST,需求解决方法?
环境描述: mysql版本5.6.37 keepalived-1.2.19 系统centos 7:3.10.0-514.26.2.el7 web是:windows server 2 ...
- thinkphp框架 的 链接数据库和操作数据
框架有时会用到数据库的内容,在"ThinkPhp框架知识"的那篇随笔中提到过,现在这篇随笔详细的描述下. 一.链接数据库 (1)找到模块文件夹中的Conf文件夹,然后进行编写con ...
- Dijkstra求最短路径&例题
讲了半天好像也许maybe听懂了一点,先写下来233 先整理整理怎么存(开始绕) 最简单的是邻接矩阵存,但是开到10000*10000就MLE了,所以我们用链式前向星存(据说是叫这个名字吧) 这是个什 ...
- redis中key的过期键删除策略
Redis过期键删除策略 Redis key过期的方式有三种: 被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key 主动删除:由于惰性删除策略无法保证冷数据被及时删 ...
- netmap配置
1.配置流程 环境:centos 7.2.1511,内核版本3.10.0-327.el7.x86_64 [1]下载内核源码,https://buildlogs.cdn.centos.org/c7.15 ...
- c#判断字符串是否为空或null
通常有: string str=""; .if(str=="") .if(str==String.Empty) .) 三种方法的效果一样,都可以判断字符串是否为 ...
- C# 控件之数据绑定
增加一个委托方法,可以实现后台多线程直接更新UI界面的值,利用了控件的DataBindings,以及 INotifyPropertyChanged接口和事件委托机制. 如果只是通过INotifyPro ...
- .net 上传文件
Controller层接收文件 参数 [FromServices] IHostingEnvironment env public IActionResult UploadFile([FromS ...
- less和sass的区别
首先sass和less都是css的预编译处理语言,他们引入了mixins,参数,嵌套规则,运算,颜色,名字空间,作用域,JavaScript赋值等 加快了css开发效率,当然这两者都可以配合gulp和 ...