redis学习(九)——数据持久化
一、概述
Redis的强大性能很大程度上都是因为所有数据都是存储在内存中的,然而当Redis重启后,所有存储在内存中的数据将会丢失,在很多情况下是无法容忍这样的事情的。所以,我们需要将内存中的数据持久化!典型的需要持久化数据的场景如下:
- 将Redis作为数据库使用;
- 将Redis作为缓存服务器使用,但是缓存miss后会对性能造成很大影响,所有缓存同时失效时会造成服务雪崩,无法响应。
本文介绍Redis所支持的两种数据持久化方式。
二、Redis数据持久化
Redis支持两种数据持久化方式:RDB方式和AOF方式。前者会根据配置的规则定时将内存中的数据持久化到硬盘上,后者则是在每次执行写命令之后将命令记录下来。两种持久化方式可以单独使用,但是通常会将两者结合使用。
1、RDB方式
RDB方式的持久化是通过快照的方式完成的。当符合某种规则时,会将内存中的数据全量生成一份副本存储到硬盘上,这个过程称作”快照”,Redis会在以下几种情况下对数据进行快照:
- 根据配置规则进行自动快照;
- 用户执行SAVE, BGSAVE命令;
- 执行FLUSHALL命令;
- 执行复制(replication)时。
执行快照的场景
(1)根据配置自动快照
Redis允许用户自定义快照条件,当满足条件时自动执行快照。缺省情况下,Redis把数据快照存放在磁盘上的二进制文件中,文件名为dump.rdb,此外,我们也可以通过配置文件来修改Redis服务器dump快照的频率,在打开redis.windows.conf文件之后,我们搜索save,可以看到下面的配置信息:

注意最后三行,分别表示:
在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照;
在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照;
在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。
每个快照条件独占一行,他们之间是或(||)关系,只要满足任何一个就进行快照。上面配置save后的第一个参数T是时间,单位是秒,第二个参数M是更改的键的个数,含义是:当时间T内被更改的键的个数大于M时,自动进行快照。比如save 900 1的含义是15分钟内(900s)被更改的键的个数大于1时,自动进行快照操作。
(2)执行SAVE或BGSAVE命令
除了让Redis自动进行快照外,当我们需要重启,迁移,备份Redis时,我们也可以手动执行SAVE或BGSAVE命令主动进行快照操作。
- SAVE命令:当执行SAVE命令时,Redis同步进行快照操作,期间会阻塞所有来自客户端的请求,所以放数据库数据较多时,应该避免使用该命令;
- BGSAVE命令: 从命令名字就能看出来,这个命令与SAVE命令的区别就在于该命令的快照操作是在后台异步进行的,进行快照操作的同时还能处理来自客户端的请求。执行BGSAVE命令后Redis会马上返回OK表示开始进行快照操作,如果想知道快照操作是否已经完成,可以使用LASTSAVE命令返回最近一次成功执行快照的时间,返回结果是一个Unix时间戳。
(3)执行FLUSHALL命令
当执行FLUSHALL命令时,Redis会清除数据库中的所有数据。需要注意的是:不论清空数据库的过程是否触发了自动快照的条件,只要自动快照条件不为空,Redis就会执行一次快照操作,当没有定义自动快照条件时,执行FLUSHALL命令不会进行快照操作。
(4)执行复制
当设置了主从模式时,Redis会在复制初始化时进行自动快照。
快照原理
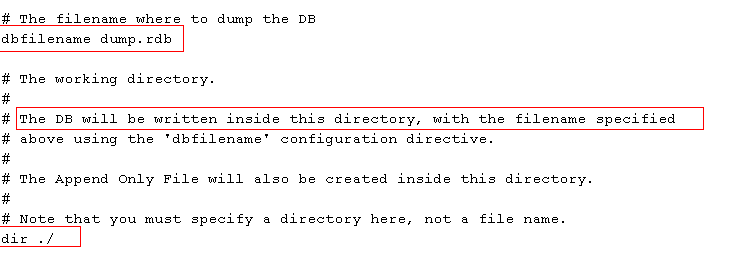
Redis默认会将快照文件存储在Redis当前进程的工作目录的dump.rdb文件中,可以通过配置文件中的dir和dbfilename两个参数分别指定快照文件的存储路径和文件名,默认的存储路径和文件名如下图所示:
快照执行的过程如下:
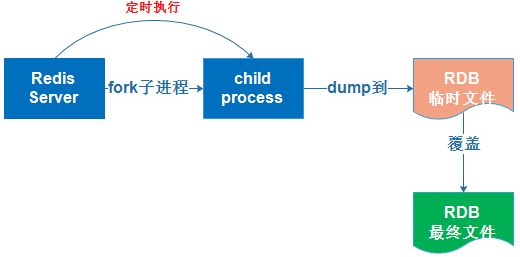
(1)Redis使用fork函数复制一份当前进程(父进程)的副本(子进程);
(2)父进程继续处理来自客户端的请求,子进程开始将内存中的数据写入硬盘中的临时文件;
(3)当子进程写完所有的数据后,用该临时文件替换旧的RDB文件,至此,一次快照操作完成。
需要注意的是:
在执行fork的时候操作系统(类Unix操作系统)会使用写时复制(copy-on-write)策略,即fork函数发生的一刻,父进程和子进程共享同一块内存数据,当父进程需要修改其中的某片数据(如执行写命令)时,操作系统会将该片数据复制一份以保证子进程不受影响,所以RDB文件存储的是执行fork操作那一刻的内存数据。所以RDB方式理论上是会存在丢数据的情况的(fork之后修改的的那些没有写进RDB文件)。
通过上述的介绍可以知道,快照进行时是不会修改RDB文件的,只有完成的时候才会用临时文件替换老的RDB文件,所以就保证任何时候RDB文件的都是完整的。这使得我们可以通过定时备份RDB文件来实现Redis数据的备份。RDB文件是经过压缩处理的二进制文件,所以占用的空间会小于内存中数据的大小,更有利于传输。
Redis启动时会自动读取RDB快照文件,将数据从硬盘载入到内存,根据数量的不同,这个过程持续的时间也不尽相同,通常来讲,一个记录1000万个字符串类型键,大小为1GB的快照文件载入到内存需要20-30秒的时间。
示例
下面演示RDB方式持久化,首先使用配置有如下快照规则:
save 900 1
save 300 10
save 60 10000
dbfilename dump.rdb
dir ./
启动Redis服务:
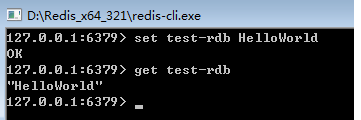
然后通过客户端设置一个键值:
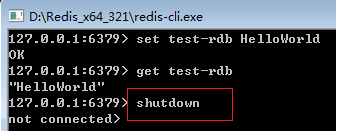
现在强行kill Redis服务,执行shutdown命令:

现在到D:\Redis_x64_321\目录看,目录下出现了Redis的快照文件dump.rdb:

现在重新启动Redis,然后再用客户端连接,检查之前设置的key是否还存在:
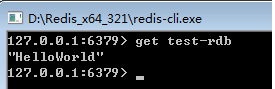
可以发现,之前设置的key在Redis重启之后又通过快照文件dump.rdb恢复了。
2、AOF方式
在使用Redis存储非临时数据时,一般都需要打开AOF持久化来降低进程终止导致的数据丢失,AOF可以将Redis执行的每一条写命令追加到硬盘文件中,这一过程显然会降低Redis的性能,但是大部分情况下这个影响是可以接受的,另外,使用较快的硬盘能提高AOF的性能。
开启AOF
默认情况下,Redis没有开启AOF(append only file)持久化功能,可以通过在配置文件中作如下配置启用:
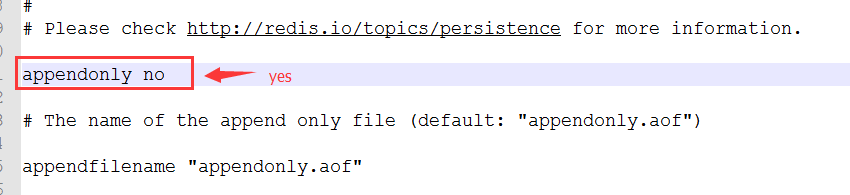
开启之后,Redis每执行一条写命令就会将该命令写入硬盘中的AOF文件。AOF文件保存路径和RDB文件路径是一致的,都是通过dir参数配置,默认文件名是:appendonly.aof,可以通过配置appendonlyfilename参数修改,例如:

AOF持久化的实现
AOF以纯文本的形式记录了Redis执行的写命令,例如在开启AOF持久化的情况下执行如下命令:

然后查看D:\Redis_x64_321\appendonly.aof文件:
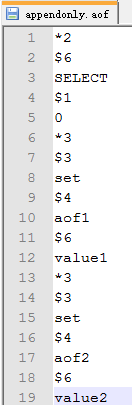
文件中的内容正是Redis刚才执行的命令的内容,内容的格式就先不展开叙述了。
AOF文件重写
AOF文件是可识别的纯文本,它的内容就是一个个的Redis标准命令,
AOF日志也不是完全按客户端的请求来生成日志的,比如命令 INCRBYFLOAT 在记AOF日志时就被记成一条SET记录,因为浮点数操作可能在不同的系统上会不同,所以为了避免同一份日志在不同的系统上生成不同的数据集,所以这里只将操作后的结果通过SET来记录。
每一条写命令都生成一条日志,AOF文件会很大。
AOF重写是重新生成一份AOF文件,新的AOF文件中一条记录的操作只会有一次,而不像一份老文件那样,可能记录了对同一个值的多次操作。其生成过程和RDB类似,也是fork一个进程,直接遍历数据,写入新的AOF临时文件。在写入新文件的过程中,所有的写操作日志还是会写到原来老的AOF文件中,同时还会记录在内存缓冲区中。当重完操作完成后,会将所有缓冲区中的日志一次性写入到临时文件中。然后调用原子性的rename命令用新的 AOF文件取代老的AOF文件。
命令:BGREWRITEAOF, 我们应该经常调用这个命令来来重写。
=============================================================================
假设Redis执行了如下命令:

如果这所有的命令都写到AOF文件的话,将是一个比较蠢的行为,因为前面两个命令会被第三个命令覆盖,所以AOF文件完全不需要保存前面两个命令,事实上Redis确实就是这么做的。删除AOF文件中无用的命令的过程称为"AOF重写",AOF重写可以在配置文件中做相应的配置,当满足配置的条件时,自动进行AOF重写操作。配置如下:
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
第一行的意思是,目前的AOF文件的大小超过上一次重写时的AOF文件的百分之多少时再次进行重写,如果之前没有重写过,则以启动时AOF文件大小为依据。
第二行的意思是,当AOF文件的大小大于64MB时才进行重写,因为如果AOF文件本来就很小时,有几个无效的命令也是无伤大雅的事情。
这两个配置项通常一起使用。
我们还可以手动执行BGREWRITEAOF命令主动让Redis重写AOF文件:

执行重写命令之后查看现在的AOF文件:
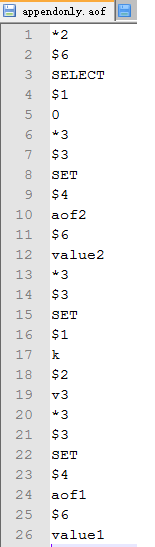
可以看到,文件中并没有再记录set k v1这样的无效命令。
同步硬盘数据
虽然每次执行更改数据库的内容时,AOF都会记录执行的命令,但是由于操作系统本身的硬盘缓存的缘故,AOF文件的内容并没有真正地写入硬盘,在默认情况下,操作系统会每隔30s将硬盘缓存中的数据同步到硬盘,但是为了防止系统异常退出而导致丢数据的情况发生,我们还可以在Redis的配置文件中配置这个同步的频率:
# appendfsync always
appendfsync everysec
# appendfsync no
第一行表示每次AOF写入一个命令都会执行同步操作,这是最安全也是最慢的方式;
第二行表示每秒钟进行一次同步操作,一般来说使用这种方式已经足够;
第三行表示不主动进行同步操作,这是最不安全的方式。
选项:
1、appendfsync no
当设置appendfsync为no的时候,Redis不会主动调用fsync去将AOF日志内容同步到磁盘,所以这一切就完全依赖于操作系统的调试了。对大多数Linux操作系统,是每30秒进行一次fsync,将缓冲区中的数据写到磁盘上。
2、appendfsync everysec
当设置appendfsync为everysec的时候,Redis会默认每隔一秒进行一次fsync调用,将缓冲区中的数据写到磁盘。但是当这一次的fsync调用时长超过1秒时。Redis会采取延迟fsync的策略,再等一秒钟。也就是在两秒后再进行fsync,这一次的fsync就不管会执行多长时间都会进行。这时候由于在fsync时文件描述符会被阻塞,所以当前的写操作就会阻塞。所以,结论就是:在绝大多数情况下,Redis会每隔一秒进行一次fsync。在最坏的情况下,两秒钟会进行一次fsync操作。这一操作在大多数数据库系统中被称为group commit,就是组合多次写操作的数据,一次性将日志写到磁盘。
3、appednfsync always
当设置appendfsync为always时,每一次写操作都会调用一次fsync,这时数据是最安全的,当然,由于每次都会执行fsync,所以其性能也会受到影响。
建议采用 appendfsync everysec(缺省方式)
快照模式可以和AOF模式同时开启,互补影响。
三、二者的区别
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。

四、二者优缺点
RDB存在哪些优势呢?
1). 一旦采用该方式,那么你的整个Redis数据库将只包含一个文件,这对于文件备份而言是非常完美的。比如,你可能打算每个小时归档一次最近24小时的数据,同时还要每天归档一次最近30天的数据。通过这样的备份策略,一旦系统出现灾难性故障,我们可以非常容易的进行恢复。
2). 对于灾难恢复而言,RDB是非常不错的选择。因为我们可以非常轻松的将一个单独的文件压缩后再转移到其它存储介质上。
3). 性能最大化。对于Redis的服务进程而言,在开始持久化时,它唯一需要做的只是fork出子进程,之后再由子进程完成这些持久化的工作,这样就可以极大的避免服务进程执行IO操作了。
4). 相比于AOF机制,如果数据集很大,RDB的启动效率会更高。
RDB又存在哪些劣势呢?
1). 如果你想保证数据的高可用性,即最大限度的避免数据丢失,那么RDB将不是一个很好的选择。因为系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。
2). 由于RDB是通过fork子进程来协助完成数据持久化工作的,因此,如果当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟。
AOF的优势有哪些呢?
1). 该机制可以带来更高的数据安全性,即数据持久性。Redis中提供了3中同步策略,即每秒同步、每修改同步和不同步。事实上,每秒同步也是异步完成的,其效率也是非常高的,所差的是一旦系统出现宕机现象,那么这一秒钟之内修改的数据将会丢失。而每修改同步,我们可以将其视为同步持久化,即每次发生的数据变化都会被立即记录到磁盘中。可以预见,这种方式在效率上是最低的。至于无同步,无需多言,我想大家都能正确的理解它。
2). 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。
3). 如果日志过大,Redis可以自动启用rewrite机制。即Redis以append模式不断的将修改数据写入到老的磁盘文件中,同时Redis还会创建一个新的文件用于记录此期间有哪些修改命令被执行。因此在进行rewrite切换时可以更好的保证数据安全性。
4). AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建。
AOF的劣势有哪些呢?
1). 对于相同数量的数据集而言,AOF文件通常要大于RDB文件。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
2). 根据同步策略的不同,AOF在运行效率上往往会慢于RDB。总之,每秒同步策略的效率是比较高的,同步禁用策略的效率和RDB一样高效。
二者选择的标准,就是看系统是愿意牺牲一些性能,换取更高的缓存一致性(aof),还是愿意写操作频繁的时候,不启用备份来换取更高的性能,待手动运行save的时候,再做备份(rdb)。rdb这个就更有些 eventually consistent的意思了。
五、常用配置
RDB持久化配置
Redis会将数据集的快照dump到dump.rdb文件中。此外,我们也可以通过配置文件来修改Redis服务器dump快照的频率,在打开6379.conf文件之后,我们搜索save,可以看到下面的配置信息:
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。
AOF持久化配置
在Redis的配置文件中存在三种同步方式,它们分别是:
appendfsync always #每次有数据修改发生时都会写入AOF文件。
appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
appendfsync no #从不同步。高效但是数据不会被持久化。
redis学习(九)——数据持久化的更多相关文章
- Redis进阶:数据持久化,安全,在PHP中使用
一.redis数据持久化 由于redis是一个内存数据库,如果系统遇到致命问题需要关机或重启,内存中的数据就会丢失,这是生产环境所不能允许的.所以redis提供了数据持久化的能力. redis提供了两 ...
- Redis 中的数据持久化策略(RDB)
Redis 是一个内存数据库,所有的数据都直接保存在内存中,那么,一旦 Redis 进程异常退出,或服务器本身异常宕机,我们存储在 Redis 中的数据就凭空消失,再也找不到了. Redis 作为一个 ...
- Redis学习笔记9--Redis持久化
redis是一个支持持久化的内存数据库,也就是说redis需要经常将内存中的数据同步到磁盘来保证持久化.redis支持四种持久化方式,一是 Snapshotting(快照)也是默认方式:二是Appen ...
- Redis 中的数据持久化策略(AOF)
上一篇文章,我们讲的是 Redis 的一种基于内存快照的持久化存储策略 RDB,本质上他就是让 redis fork 出一个子进程遍历我们所有数据库中的字典,进行磁盘文件的写入. 但其实这种方式是有缺 ...
- iOS学习之数据持久化详解
前言 持久存储是一种非易失性存储,在重启设备时也不会丢失数据.Cocoa框架提供了几种数据持久化机制: 1)属性列表: 2)对象归档: 3)iOS的嵌入式关系数据库SQLite3: 4)Core Da ...
- Android学习_数据持久化
数据持久化:将内存中的瞬时数据存储到设备中 1. 文件存储 存储一些简单的文本数据或二进制数据. 核心:Context类提供的openFileOutput()和openFileInput()方法,然后 ...
- Redis学习笔记(一)-持久化
一.RDB持久方式 RDB持久化是把当前进程的数据已快照的形式保存到硬盘的过程. 触发方式: 1.手动触发命令:save和bgsave save:阻塞式,内存较大的实例在执行过程中会造成长时间的阻塞, ...
- redis 学习笔记——数据同步、事务
redis主从同步 redis支持简单易用的主从复制(master-slave replication)功能,该功能也是redis高可用性实现的基础. redis复制原理 re ...
- Redis学习笔记-数据操作篇(Centos7)
一.基本操作 1.插入数据 127.0.0.1:6379> set name cos1eqlg0 OK 这样就在redis中设置了一个key-value键值对 2.查询数据 127.0.0.1: ...
- MYSQL数据库学习九 数据的操作
9.1 插入数据记录 1. 插入完整或部分数据记录: INSERT INTO table_name(field1,field2,field3,...fieldn) VALUES(value1,valu ...
随机推荐
- js中判断空及获取当前服务的根路径
function isValue(o) { return (this.isObject(o) || this.isString(o) || this.isNumber(o) || this.isBoo ...
- JMeter 报告监听器导入.jtl结果文件报错解决方案
JMeter 报告监听器导入.jtl结果文件报错解决方案 by:授客 QQ:1033553122 1. 问题描述 把jmeter压测时生成的 .jtl结果文件导入监听器报告中,弹出如下错误提示 ...
- 性能测试 CentOS下结合InfluxDB及Grafana图表实时展示JMeter相关性能数据
CentOS下结合InfluxDB及Grafana图表实时展示JMeter相关性能数据 by:授客 QQ:1033553122 实现功能 1 测试环境 1 环境搭建 2 1.安装influxdb ...
- Android EditText手机号格式化输入XXX-XXXX-XXXX
先来效果图: 设置手机格式化操作只需要设置EditText的addTextChangedListener的监听,下面看代码 /*editText输入监听*/ et_activity_up_login_ ...
- OkHttpUtils简单的网络去解析使用
先添加依赖: implementation 'com.google.code.gson:gson:2.2.4' implementation 'com.zhy:okhttputils:2.0.0' 网 ...
- matlab练习程序(旋转矩阵、欧拉角、四元数互转)
欧拉角转旋转矩阵公式: 旋转矩阵转欧拉角公式: 旋转矩阵转四元数公式,其中1+r11+r22+r33>0: 四元数转旋转矩阵公式,q0^2+q1^2+q2^2+q3^2=1: 欧拉角转四元数公式 ...
- Java 一些知识点总结
本篇文章会对面试中常遇到的Java技术点进行全面深入的总结,帮助我们在面试中更加得心应手,不参加面试的同学也能够借此机会梳理一下自己的知识体系,进行查漏补缺(阅读本文需要有一定的Java基础).本文的 ...
- JS 文本框格式化
页面: <script src="http://libs.baidu.com/jquery/1.9.1/jquery.min.js"></script> & ...
- js获取地址栏中的数据
window.location.href:设置或获取整个 URL 为字符串window.location.pathname:设置或获取对象指定的文件名或路径window.location.search ...
- 单线程泵问题(com操作时间超过60s报错)
CLR 无法从 COM 上下文 0x197bf0 转换为 COM 上下文 0x197a80,这种状态已持续 60 秒.拥有目标上下文/单元的线程很有可能执行的是非 ...