HDFS 读写数据流程
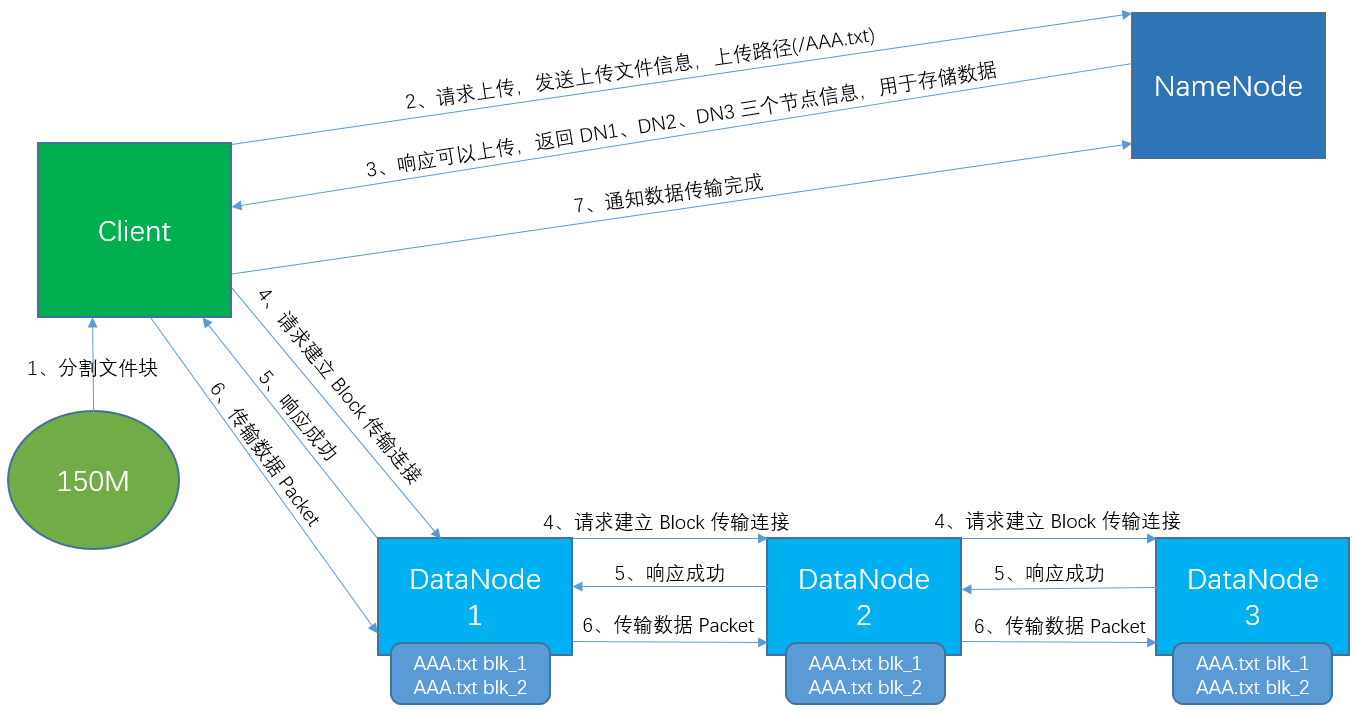
一、上传数据
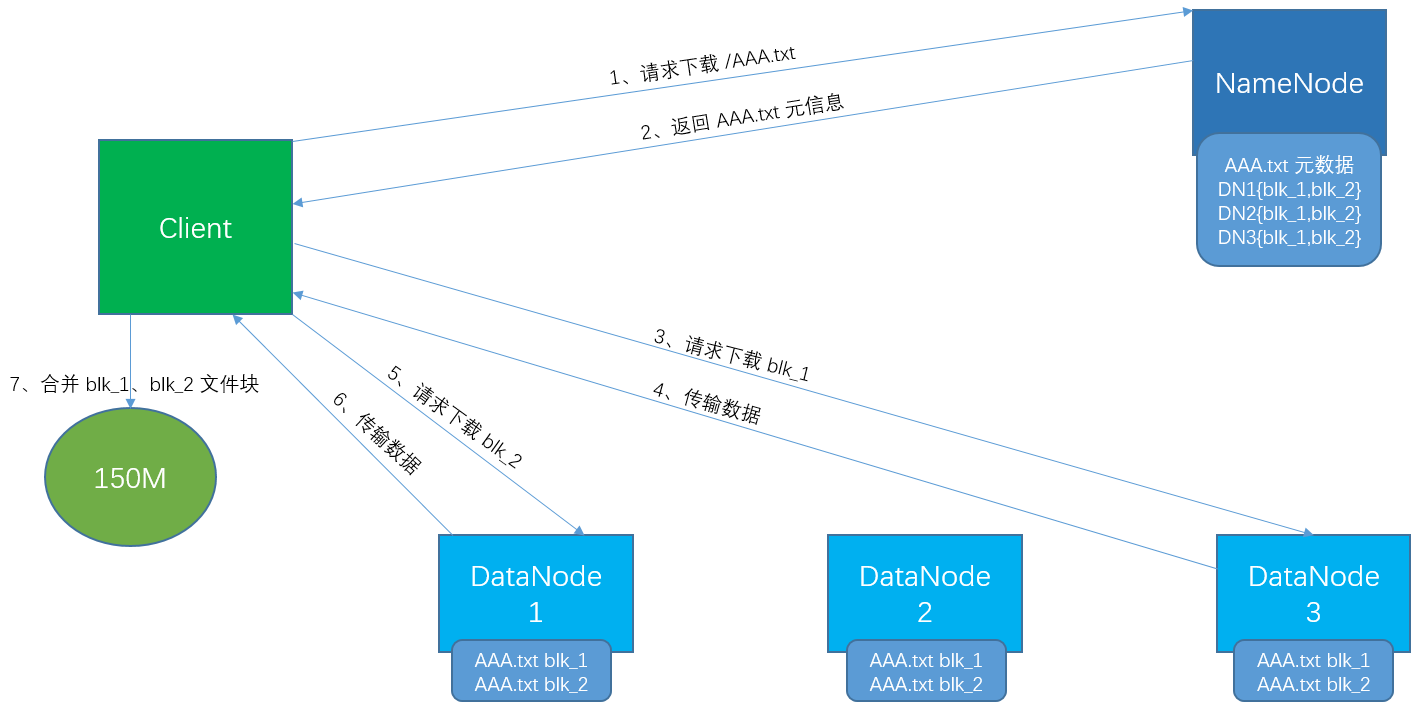
二、下载数据
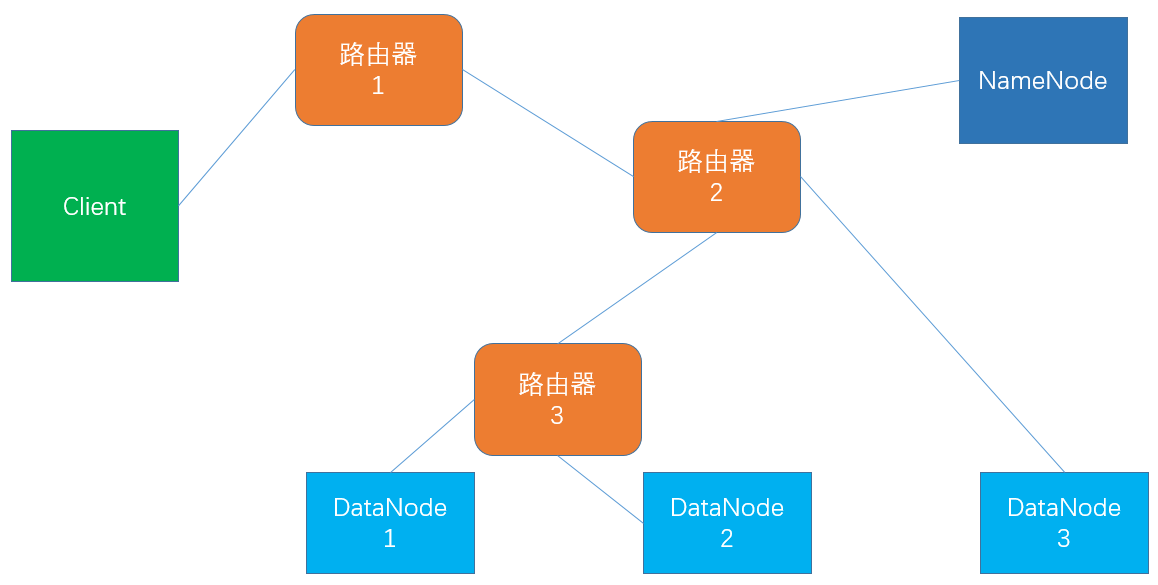
三、读写时的节点位置选择
1.网络节点距离(机架感知)
下图中:
client 到 DN1 的距离为 4
client 到 NN 的距离为 3
DN1 到 DN2 的距离为 2
2.Block 的副本放置策略
NameNode 通过 Hadoop Rack Awareness 确定每个 DataNode 所属的机架 ID
简单但非最优的策略
将副本放在单独的机架上 这可以防止在整个机架出现故障时丢失数据,并允许在读取数据时使用来自多个机架的带宽。
此策略在群集中均匀分布副本,平衡组件故障的负载。
但是此策略会增加写入消耗,因为写入时会将块传输到多个机架。
常见情况策略(HDFS 采取的策略)
当复制因子为 3 时,HDFS 的放置策略是:
若客户端位于 datanode 上,则将一个副本放在本地计算机上,否则放在随机 datanode 上
在另一个(远程)机架上的节点上放置另一个副本,最后一个在同一个远程机架中的另一个节点上。 机架故障的可能性远小于节点故障的可能性。
此策略可以减少机架间写入流量,从而提高写入性能,而不会影响数据可靠性和可用性(读取性能)。
这样减少了读取数据时使用的聚合网络带宽,因为块只放在两个唯一的机架,而不是三个。
如果复制因子大于 3,则随机确定第 4 个及后续副本的放置,同时保持每个机架的副本数量低于上限(基本上是(副本 - 1)/机架+ 2)。
由于 NameNode 不允许 DataNode 具有同一块的多个副本,因此创建的最大副本数是此时DataNode的总数。
原文(Replica Placement: The First Baby Steps 章节): http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
3.下载时副本的选择
为了最大限度地减少全局带宽消耗和读取延迟,HDFS 会选择最接客户端的节点中的副本来响应读取请求。 如果客户端与 DataNode 节点在同一机架上,且存在所需的副本,则该副本会首读用来响应取请求。 如果 HDFS 群集跨越多个数据中心,则驻留在本地数据中心的副本优先于任何远程副本。
原文(Replica Selection 章节): http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
HDFS 读写数据流程的更多相关文章
- 大数据:Hadoop(HDFS 读写数据流程及优缺点)
一.HDFS 写数据流程 写的过程: CLIENT(客户端):用来发起读写请求,并拆分文件成多个 Block: NAMENODE:全局的协调和把控所有的请求,提供 Block 存放在 DataNode ...
- HDFS读写数据流程
HDFS的组成 1.NameNode:存储文件的元数据,如文件名,文件目录结构,文件属性(创建时间,文件权限,文件大小) 以及每个文件的块列表和块所在的DataNode等.类似于一本书的目录功能. 2 ...
- HDFS读写数据块--${dfs.data.dir}选择策略
最近工作需要,看了HDFS读写数据块这部分.不过可能跟网上大部分帖子不一样,本文主要写了${dfs.data.dir}的选择策略,也就是block在DataNode上的放置策略.我主要是从我们工作需要 ...
- Hadoop(8)-HDFS的读写数据流程以及机架感知
1. HDFS的写数据流程 1.客户端通过fs模块向NameNode申请文件上传,NameNode检查请求是否合法,如用户权限,目标文件是否已存在,父目录是否存在等等 2.NameNode返回是否可以 ...
- Hadoop -- HDFS 读写数据
一.HDFS读写文件过程 1.读取文件过程 1) 初始化FileSystem,然后客户端(client)用FileSystem的open()函数打开文件 2) FileSyst ...
- HDFS读写数据过程
一.文件的打开 1.1.客户端 HDFS打开一个文件,需要在客户端调用DistributedFileSystem.open(Path f, int bufferSize),其实现为: public F ...
- Hdfs读写数据出错
1.Hdfs读数据出错:若在读数据的过程中,客户端和DataNode的通信出现错误,则会尝试连接下一个 包含次文件块的DataNode.同时记录失败的DataNode,此后不再被连接. 2.Hdfs在 ...
- HDFS读写文件流程
读取: 写入:https://www.imooc.com/article/70527
- HDFS写数据和读数据流程
HDFS数据存储 HDFS client上传数据到HDFS时,首先,在本地缓存数据,当数据达到一个block大小时.请求NameNode分配一个block. NameNode会把block所在的Dat ...
随机推荐
- python 模块之-json
python 模块json import json x="[null,true,false,1]" print(json.loads(x)) #---------------- ...
- HDU 4344-Mark the Rope-大数素因子分解
注意只有一个素因子的情况. #include <cstdio> #include <algorithm> #include <cstring> using name ...
- 洛谷P2085最小函数值题解
题目 首先我们先分析一下题目范围,\(a,b,c\) 都是整数,因此我们可以得出它的函数值在\((0,+\infty )\)上是单调递增的,,然后我们可以根据函数的性质,将每个函数设置一个当前指向位置 ...
- BZOJ1012 最大数maxnumber
单调栈的妙处!! 刚看到这题差点写个splay..但是后来看到询问范围的只是后L个数,因为当有一个数新进来且大于之前的数时,那之前的数全都没有用了,满足这种性质的序列可用单调栈维护 栈维护下标(因为要 ...
- Get Luffy Out * HDU - 1816(2 - sat 妈的 智障)
题意: 英语限制了我的行动力....就是两个钥匙不能同时用,两个锁至少开一个 建个图 二分就好了...emm....dfs 开头low 写成sccno 然后生活失去希望... #include & ...
- bzoj 2588 : Spoj 10628. Count on a tree
Description 给定一棵N个节点的树,每个点有一个权值,对于M个询问(u,v,k),你需要回答u xor lastans和v这两个节点间第K小的点权.其中lastans是上一个询问的答案,初始 ...
- TP5调用微信JSSDK 教程 —— 之异步使用
细节请参考前一篇文章:JSSDK.PHP 修改下: <?php namespace jssdk; class Jssdk { private $appId; private $appSecret ...
- css标准文档流
css标准文档流 所谓的标准文档流指的是网页当中的一个渲染顺序,就如同人类读书一样,从上向下,从左向右.网页的渲染顺序也是如此.而我们使用的标签默认都是存在于标准文档流当中. 标准文档流当中的特性 空 ...
- Nagios 监控 Httpd 并发数插件
工作需要监控Httpd并发数,找不到合适的插件,花时间研究了一下Nagios监控内存的脚本,做了一些修改,完成了脚本.监控内存脚本:http://www.cnblogs.com/Mrhuangrui/ ...
- JLOI2015 DAY1 简要题解
「JLOI2015」有意义的字符串 题意 给你 \(b, d, n\) 求 \[ [(\frac{b + \sqrt d}2)^n] \mod 7528443412579576937 \] \(0 & ...