ranger部署文档(记)
目录
概览... 2
1. ranger-admin. 2
2. ranger-user-sync. 2
3. ranger-*-plugins. 2
安装... 3
1. ranger-admin: 3
2. ranger-user-sync: 4
3. ranger-hdfs-plugin: 5
4. ranger-hive-plugin: 6
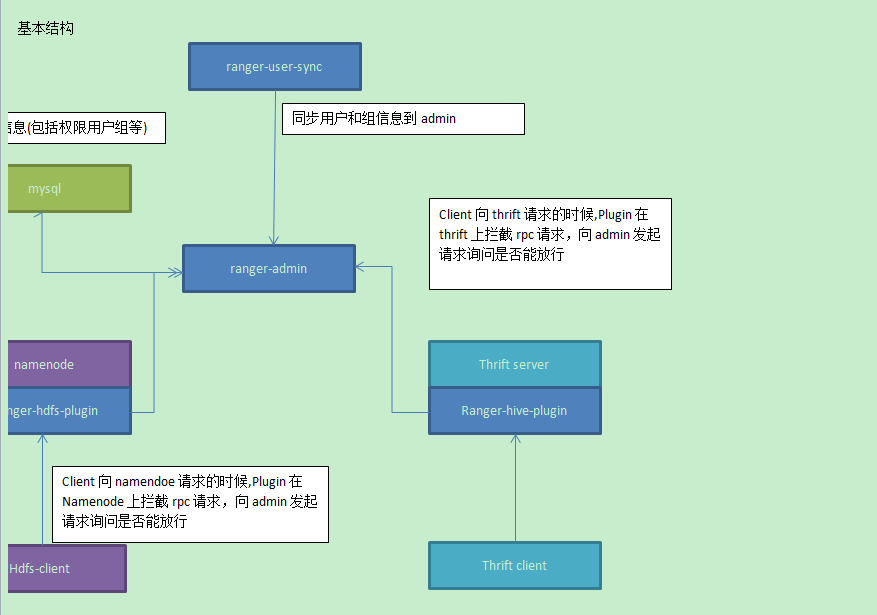
概览
1. ranger-admin
ranger的中心节点,所有鉴权访问都必须经过这个节点.
(可load balancer,请求是走HTTP协议的)
2. ranger-user-sync
同步user/group等信息到admin节点.
比如有些用户和组并不在admin节点的机器上存在的.
但在各个权限控制plugin中又有定义的,是通过这个服务同步.
3. ranger-*-plugins
各个实际的鉴权组件的hook点实现.
存在在各个服务(如HDFS)等的进程内.
安装
1. ranger-admin:
- 安装mysql,用于存放ranger的各种鉴权定义的存放等.
- 解压缩ranger-0.7.1-admin.tar.gz
- 准备solr audit(ranger会将audit log写入这个solr)
1) . cd ./contrib/solr_for_audit_setup
2) 修改install.property
# 所使用的solr的程序安装目录
SOLR_INSTALL_FOLDER=
# ranger对应的solr配置等(只需建立起空目录即可,后面自带脚本会做准备)
SOLR_RANGER_HOME=
# ranger对应的solr的数据存放位置(只需建立起空目录即可,后面自带脚本会做准备)
SOLR_RANGER_DATA_FOLDER=
# ranger audit在solr上的collection名字,默认为ranger_audits
SOLR_RANGER_COLLECTION=
3) 执行./contrib/solr_for_audit_setup/setup.sh
4) 启动(root):
${SOLR_RANGER_HOME}/scripts/start_solr.sh
停止(root):
${SOLR_RANGER_HOME}/scripts/stop_solr.sh
- 配置admin.
1) 修改install.property
# 配置所使用的mysql的root用户连接信息(需自行保证mysql这方面的权限).
db_root_user=
db_root_password=
db_host=
# ranger所使用的mysql的数据库和用户信息(后面会有自带脚本创建维护,不需手工建立)
db_name=
db_user=
db_pasword=
# 使用solr存储audit
audit_store=solr
# ranger使用的solr collection地址.
# 如果slor的设置使用默认SOLR_RANGER_COLLECTION即ranger_audit的话.
# 为http://${solr_host}:6083/solr/ranger_audits
audit_solr_urls=
# mysql JDBC的jar包路径
SQL_CONNECTOR_JAR=
2) 执行setup.sh(root)
这个脚本会建立mysql上的库信息
并会放置各个脚本到标准目录(类RPM包install动作)
3) 启动(root):
ranger-admin start
停止(root):
ranger-admin stop
4) 访问:
http://${host}:6080
默认口令admin:admin
2. ranger-user-sync:
- 解压缩ranger-0.7.1-usersync.tar
- 修改install.property
# 即ranger admin的地址
# 如http://${host}:6080
POLICY_MGR_URL=
- 执行setup.sh(root)
放置各个脚本到标准目录(类RPM包install动作)
- 启动(root)
ranger-usersync start
停止(root):
ranger-usersync stop
3. ranger-hdfs-plugin:
- 在各个namenode上解压缩ranger-0.7.1-hdfs-plugin.tar.gz
- 修改install.property
# 即ranger admin的地址
# 如http://${host}:6080
POLICY_MGR_URL=
# 配置slor audit log
XAAUDIT.SOLR.ENABLE=true
# ranger使用的solr collection地址.
# 如果slor的设置使用默认SOLR_RANGER_COLLECTION即ranger_audit的话.
# 为http://${solr_host}:6083/solr/ranger_audits
XAAUDIT.SOLR.URL=
# ranger上hdfs的policy ID/名字
# 如hadoopdev
REPOSITORY_NAME=
- namenode上的调整.
1) 确保存在HADOOP_HOME环境变量
2) 确保${HADOOP_HOME}/conf存在并指向实际使用的conf目录.
3) 执行./enable-hdfs-plugin.sh(root)
copy ${HADOOP_HOME}/lib下的ranger相关jar和目录到${HADOOP_HOME}/share/hadoop/hdfs/lib
trouble shooting:
这个是保证namenode进程的classpath能找到ranger的jar包.
原理是ranger重新实现了dfs.namenode.inode.attributes.provider.class,hook了namenode上的RPC请求.
所以前面需要知道conf的目录便于重新生成hdfs-site.xml
4) 重新启动namenode和zkfc即可.
5) 验证:
hdfs mkdir等读写操作一下应该可以在admin server的web ui看到相关audit信息
4. ranger-hive-plugin:
- 在hive thrift server上解压缩ranger-0.7.1-hive-plugin.tar.gz
- 修改install.property
# 即ranger admin的地址
# 如http://${host}:6080
POLICY_MGR_URL=
# 配置slor audit log
XAAUDIT.SOLR.ENABLE=true
# ranger使用的solr collection地址.
# 如果slor的设置使用默认SOLR_RANGER_COLLECTION即ranger_audit的话.
# 为http://${solr_host}:6083/solr/ranger_audits
XAAUDIT.SOLR.URL=
# ranger上hive的policy ID/名字.如hivedev
REPOSITORY_NAME=
- 修改hive-site.xml
添加:
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
<description>
在thrift server上关闭doAS.
开启的话,一个访问需要同时控制hdfs和hive的访问权限,坏处在于不容易维护.
关闭的话,只需要维护hive的访问权限即可,坏处是所有查询在鉴权后都是以hive用户跑.
</description>
</property>
- 执行./enable-hive-plugin.sh(root)
原理类似ranger-hdfs-plugin
- 重新启动hive thrift server即可.
- 验证:
通过beeline访问thrift做查询读写应该就能在web ui看到相关audit信息
ranger部署文档(记)的更多相关文章
- PPTP部署文档
PPTP部署文档 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 欢迎加入:高级运维工程师之路 598432640 前言:这款VPN部署起来特别简单,想对OPENVON配 ...
- hadoop2.6.0汇总:新增功能最新编译 32位、64位安装、源码包、API下载及部署文档
相关内容: hadoop2.5.2汇总:新增功能最新编译 32位.64位安装.源码包.API.eclipse插件下载Hadoop2.5 Eclipse插件制作.连接集群视频.及hadoop-eclip ...
- supervisor 部署文档
supervisor 部署文档 supervisor 需要Python支持,如果不用系统的supervisor,单独安装python python 安装 #依赖 yum install python- ...
- centos6 Cacti部署文档
centos6 Cacti部署文档 1.安装依赖 yum -y install mysql mysql-server mysql-devel httpd php php-pdo php-snmp ph ...
- HP DL160 Gen9服务器集群部署文档
HP DL160 Gen9服务器集群部署文档 硬件配置=======================================================Server Memo ...
- Sqlserver2008安装部署文档
Sqlserver2008部署文档 注意事项: 如果你要安装的是64位的服务器,并且是新机器.那么请注意,你需要首先需要给64系统安装一个.net framework,如果已经安装此功能,请略过这一步 ...
- CDH简易离线部署文档
CDH 离线简易部署文档 文档说明 本文为开发部署文档,生产环境需做相应调整. 以下操作尽量在root用户下操作,避免权限问题. 目录 文档说明 2 文档修改历史记录 2 目录 3 ...
- Ceph分布式存储(luminous)部署文档-ubuntu18-04
Ceph分布式存储(luminous)部署文档 环境 ubuntu18.04 ceph version 12.2.7 luminous (stable) 三节点 配置如下 node1:1U,1G me ...
- rabbitmq 3.7.8基于centos7部署文档
rabbitmq 3.7.8部署文档 安装erlang 安装依赖环境 yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel ope ...
随机推荐
- python optparser模块
python的内置模块中对于命令行的解析模块共两个getopt 和 optparse .不过getopt过于简单,往往不能满足需求.此时可以使用optparse模块.这个模块相对于getopt更新,功 ...
- P1578 奶牛浴场
P1578 奶牛浴场 题目描述 由于John建造了牛场围栏,激起了奶牛的愤怒,奶牛的产奶量急剧减少.为了讨好奶牛,John决定在牛场中建造一个大型浴场.但是John的奶牛有一个奇怪的习惯,每头奶牛都必 ...
- Vue——显示微信用户名称中enjoin表情
后端做了处理转为了Unicode编码存入数据库,但是取出来没做处理,所以前端就做下简单的处理 转换代码: function decodeUnicode(str) { str = str.replace ...
- Codeforces1065F Up and Down the Tree 【树形DP】
推荐一道联赛练习题. 题目分析: 你考虑进入一个子树就可能上不来了,如果上得来的话就把能上来的全捡完然后走一个上不来的,所以这就是个基本的DP套路. 代码: #include<bits/stdc ...
- 【BZOJ4126】【BZOJ3516】【BZOJ3157】国王奇遇记 线性插值
题目描述 三倍经验题. 给你\(n,m\),求 \[ \sum_{i=1}^ni^mm^i \] \(n\leq {10}^9,1\leq m\leq 500000\) 题解 当\(m=1\)时\(a ...
- day3 python简介 IDE选择
优势趋势基于c语言.c语言是编译底层语言,c跨平台需要重新编译,pyh可以直接使用c的库文件,比起c有绝对的开发效率目前为全球语言使用频率为第四名,第一java.从几年前第8名已超越php第6名. 擅 ...
- 51NOD1174 区间最大数 && RMQ问题(ST算法)
RMQ问题(区间最值问题Range Minimum/Maximum Query) ST算法 RMQ(Range Minimum/Maximum Query),即区间最值查询,是指这样一个问题:对于长度 ...
- Python中生成器generator和迭代器Iterator的使用方法
一.生成器 1. 生成器的定义 把所需要值得计算方法储存起来,不会先直接生成数值,而是等到什么时候使用什么时候生成,每次生成一个,减少计算机占用内存空间 2. 生成器的创建方式 第一种只要把一个列表生 ...
- springcloud干货之服务注册与发现(Eureka)
springcloud系列文章的第一篇 springcloud服务注册与发现 使用Eureka实现服务治理 作用:实现服务治理(服务注册与发现) 简介: Spring Cloud Eureka是Spr ...
- 第一次有人把5G讲的这么简单明了
第一次有人把5G讲的这么简单明了 鲜枣课堂 纯洁的微笑 今天 关于5G通信,常见的文章都讲的晦涩难懂,不忍往下看,特转载一篇,用大白话实现5G入门. 简单说,5G就是第五代通信技术,主要特点是波长为毫 ...