scrapy 基础
安装略过
创建一个项目
scrapy startproject MySpider #或者创建时存储日志
scrapy startproject --logfile='../logf.log' MySpider #指定日志等级(--nolog表示不打印日志)
scrapy startproject --loglevel=DEBUG MySpider

scrapy命令
全局命令:不用进入项目目录的情况下即可使用
D:\>scrapy -h
Scrapy 1.5.0 - no active project Usage:
scrapy <command> [options] [args] Available commands:
bench Run quick benchmark test #测试本地硬件性能,scrapy bench
fetch Fetch a URL using the Scrapy downloader #显示爬虫爬取过程,用法 scarpy fetch 网址
参数:--headers 爬取的时候显示头信息
genspider Generate new spider using pre-defined templates #快速创建爬虫文件
#scrapy genspider -l 表示列出现有的爬虫模板
#scrapy genspider -t basic spider url 表示在spiders目录下创建一个易basic为模板名称为spider以url为爬取连接的爬虫文件
runspider Run a self-contained spider (without creating a project) #表示可以直接运行一个爬虫文件
settings Get settings values #查看对应的scrapy配置信息,用法 scrapy settings --get aa (aa表示配置文件中的一个键值)
shell Interactive scraping console #启动交互终端
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy #实现下载某个网页并用浏览器查看 [ more ] More commands available when run from project directory Use "scrapy <command> -h" to see more info about a command
项目命令:需要进入项目内使用的命令(scrapy 命令 -h 可查看相关参数 )
D:\MySpider>scrapy -h
Scrapy 1.5.0 - project: MySpider Usage:
scrapy <command> [options] [args] Available commands:
bench Run quick benchmark test
check Check spider contracts #对爬虫文件进行检查 scrapy check 文件名称
crawl Run a spider #启动一个爬虫scrapy crawl 爬虫名
edit Edit spider
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
list List available spiders #查看当前可使用的爬虫文件
parse Parse URL (using its spider) and print the results
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy Use "scrapy <command> -h" to see more info about a command
Items编写
items.py内容
import scrapy class MyspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field() #定义结构化数据,只需将scrapy的Field实例化即可,可通过python shell来理解一下
pass
python shell理解items
In [1]: import scrapy In [2]: class person(scrapy.Item):
...: name = scrapy.Field()
...: job = scrapy.Field()
...: email = scrapy.Field()
...: In [3]: spider = person(name="liejie",job="it",email="aaaaa@qq.com") #实例化类 In [4]: print (spider)
{'email': 'aaaaa@qq.com', 'job': 'it', 'name': 'liejie'} #结果以字典的方式显示 In [5]:
spider编写
spider类是scrapy中与爬虫相关的一个基类,所有的爬虫文件必须继承该类,可以通过genspider -t 创建一个爬虫文件
查看爬虫文件模板
(venv) root@ubuntu:~/mulitispd/muliti# scrapy genspider --list
Available templates:
basic
crawl
csvfeed
xmlfeed
根据模板创建爬虫文件
scrapy genspider -t basic spider www.51cto.com
items.py
# -*- coding: utf-8 -*-
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy class MyspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
urlname = scrapy.Field()
spider.py
# -*- coding: utf-8 -*-
import scrapy
from MySpider.items import MyspiderItem class SpiderSpider(scrapy.Spider):
name = 'spider' #爬虫名称(默认创建)
allowed_domains = ['www.51cto.com'] #允许爬行的域名(默认创建)
start_urls = ['http://www.51cto.com/'] #爬行的起始网址,默认属性 #自己定义要爬行的url,通过start_requests()方法
urls = ['http://www.jd.com',
'http://sina.com.cn',
'http://v.qq.com'
] #重写start_requests()方法
def start_requests(self):
for url in self.urls:
#调用self.make_requests_from_url()方法生成具体请求并通过yield返回
yield self.make_requests_from_url(url)
print (self.make_requests_from_url(url)) #处理爬虫爬行到的网页响应,返回处理后的数据
def parse(self, response):
item = MyspiderItem()
#这里表示获取 html标签下 head标签下的title标签的内容
item['urlname'] = response.xpath("/html/head/title/text()") #这里的urlname需要在items里指定,否则会报错
print(item['urlname']) 打印结果
(venv) root@ubuntu:~/myspider/myspider/spiders# scrapy crawl spider --nolog #这里spider要写spider.py文件中定义的名字
<GET http://www.jd.com>
<GET http://sina.com.cn>
<GET http://v.qq.com>
[<Selector xpath='/html/head/title/text()' data='腾讯视频-中国领先的在线视频媒体平台,海量高清视频在线观看'>]
[<Selector xpath='/html/head/title/text()' data='京东(JD.COM)-正品低价、品质保障、配送及时、轻松购物!'>]
[<Selector xpath='/html/head/title/text()' data='新浪首页'>]
XPath基础
XPath是一种XML路径语言,通过该语言可以再XML文档中迅速的查找相应的信息。XPath的表达式通常使用“/”选择某个标签,并且可以使用"/"进行多层标签的查找,如:
<html lang="zh-CN"> <head> <meta charset="UTF-8">
<title>京东(JD.COM)-正品低价、品质保障、配送及时、轻松购物!</title>
</head>
<body>
<h2>test大是大非发打的费</h2>
<p>123456789</p>
<p>asdfhj</p>
</body> </html>
如果要提取出<h2></h2>标签对应的内容,可以使用“/”选择某个标签,如下所示:
/html/body/h2
如果想获取该标签中的文本信息,可通过text()实现
/html/body/h2/text()
使用"//"可以提取某个标签的所有信息
//p #选取第一个p的内容
/html/p[1]/text()
如果想获取所有属性X的值为Y的<Z>标签的内容,
//Z[@X="Y"] #比如想获取 代码中class属性值为“main”的<img>标签中的内容
//img[@class='main'] #选取img标签下class为pic的属性下的title的值
//img/[@class='pic']/@title #选取文档中的所有元素
//* #获取属性的值
//@href #选取名为href的所有属性
spider传参
spider 通过 -a参数实现参数的传递,即在执行爬虫文件时,传入参数,方式为重构初始化(__init__)方法,如(传递一个参数):
items.py
import scrapy class MyspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
urlname = scrapy.Field()
spider.py
# -*- coding: utf-8 -*-
import scrapy
from myspider.items import MyspiderItem class SpiderSpider(scrapy.Spider):
name = 'spider'
allowed_domains = ['www.baidu.com']
start_urls = ['http://www.baidu.com/'] #重构__init__方法,并指定参数myurl
def __init__(self,myurl = None,*args,**kwargs):
super(SpiderSpider,self).__init__(*args,**kwargs)
#输出要爬取的网址
print ("yao paqu de wangzhi: %s" % myurl)
self.start_urls=[myurl] def parse(self, response):
item = MyspiderItem()
# 这里表示获取 html标签下 head标签下的title标签的内容
item['urlname'] = response.xpath("/html/head/title/text()") #这里的urlname要在items中指定 print("wang zhi biao ti wei: %s" % item['urlname'])
结果:
(venv) root@ubuntu:~/myspider/myspider/spiders# scrapy crawl spider -a myurl=http://www.lavion.com.cn --nolog
yao paqu de wangzhi: http://www.lavion.com.cn
wang zhi biao ti wei: [<Selector xpath='/html/head/title/text()' data='优翔抗衰老'>]
传递多个参数
spider.py
# -*- coding: utf-8 -*-
import scrapy
from myspider.items import MyspiderItem class SpiderSpider(scrapy.Spider):
name = 'spider'
allowed_domains = ['www.baidu.com']
start_urls = ['http://www.baidu.com/'] def __init__(self,myurl = None,*args,**kwargs):
super(SpiderSpider,self).__init__(*args,**kwargs) myurllist = myurl.split('|')
for i in myurllist:
print("要爬取的网址: %s" % myurl) self.start_urls=myurllist def parse(self, response):
item = MyspiderItem()
# 这里表示获取 html标签下 head标签下的title标签的内容
item['urlname'] = response.xpath("/html/head/title/text()") print("wang zhi biao ti wei: %s" % item['urlname'])
执行
scrapy crawl spider -a myurl=http://www.lavion.com.cn|http://www.iqiyi.com --nolog
XMLFeedSpider分析XML源
创建爬虫文件
scrapy genspider -t xmlfeed XmlFeedSpider sina.com.cn
定义items.py
import scrapy class MyspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
author = scrapy.Field()
XmlFeedSpider.py
# -*- coding: utf- -*-
from scrapy.spiders import XMLFeedSpider
from myspider.items import MyspiderItem class XmlfeedspiderSpider(XMLFeedSpider):
name = 'XmlFeedSpider'
allowed_domains = ['sina.com.cn']
start_urls = ['http://blog.sina.com.cn/rss/1615888477.xml']
iterator = 'iternodes' # 设置哪个是迭代器,默认为iternodes,还可以用‘html’和'xml'
itertag = 'rss' # 设置开始迭代的节点 def parse_node(self, response, node):
i = MyspiderItem()
i['title'] = node.xpath('/rss/channel/item/title/text()').extract() #xpath分析
i['link'] = node.xpath('/rss/channel/item/link/text()').extract()
i['author'] = node.xpath('/rss/channel/item/author/text()').extract()
for j in range(len(i['title'])):
print("di" + str(j+)+"pian wen zhang")
print ("biaotishi:%s" % i['title'][j])
print ("lianjie shi :%s" % i['link'][j])
print ("zuo zhe shi: %s" % i["author"][j])
print ("-"*)return i
结果:

scrapy爬虫批量运行爬虫文件
执行一个爬虫文件用命令crawl,执行多个,只需要对crawl文件进行修改即可
crawl源文件地址:https://github.com/scrapy/scrapy/blob/master/scrapy/commands/crawl.py
#首先创建一个项目
root@ubuntu:~/mulitispd# scrapy startproject mulitispd
#创建爬虫文件
root@ubuntu:~/mulitispd/muliti# scrapy genspider -t baseic myspd1 sina.com.cn
root@ubuntu:~/mulitispd/muliti# scrapy genspider -t baseic myspd2 sina.com.cn
root@ubuntu:~/mulitispd/muliti# scrapy genspider -t baseic myspd3 sina.com.cn
#进入项目目录,创建一个目录,用于存放多文件执行脚本
(venv) root@ubuntu:~/mulitispd# mkdir muliti
(venv) root@ubuntu:~/mulitispd# cd muliti
#创建文件 mycrawl_muliti.py,并将crawl命令源码放进去,修改
(venv) root@ubuntu:~/mulitispd/muliti# ls
__init__.py mycrawl_muliti.py
修改后的文件
#cat mycrawl_muliti.py
import os
from scrapy.commands import ScrapyCommand
from scrapy.utils.conf import arglist_to_dict
from scrapy.utils.python import without_none_values
from scrapy.exceptions import UsageError class Command(ScrapyCommand): requires_project = True def syntax(self):
return "[options] <spider>" def short_desc(self):
return "Run many spider" #此处用于定义命令的说明 def add_options(self, parser):
ScrapyCommand.add_options(self, parser)
parser.add_option("-a", dest="spargs", action="append", default=[], metavar="NAME=VALUE",
help="set spider argument (may be repeated)")
parser.add_option("-o", "--output", metavar="FILE",
help="dump scraped items into FILE (use - for stdout)")
parser.add_option("-t", "--output-format", metavar="FORMAT",
help="format to use for dumping items with -o") def process_options(self, args, opts):
ScrapyCommand.process_options(self, args, opts)
try:
opts.spargs = arglist_to_dict(opts.spargs)
except ValueError:
raise UsageError("Invalid -a value, use -a NAME=VALUE", print_help=False)
if opts.output:
if opts.output == '-':
self.settings.set('FEED_URI', 'stdout:', priority='cmdline')
else:
self.settings.set('FEED_URI', opts.output, priority='cmdline')
feed_exporters = without_none_values(
self.settings.getwithbase('FEED_EXPORTERS'))
valid_output_formats = feed_exporters.keys()
if not opts.output_format:
opts.output_format = os.path.splitext(opts.output)[1].replace(".", "")
if opts.output_format not in valid_output_formats:
raise UsageError("Unrecognized output format '%s', set one"
" using the '-t' switch or as a file extension"
" from the supported list %s" % (opts.output_format,
tuple(valid_output_formats)))
self.settings.set('FEED_FORMAT', opts.output_format, priority='cmdline') def run(self, args, opts):
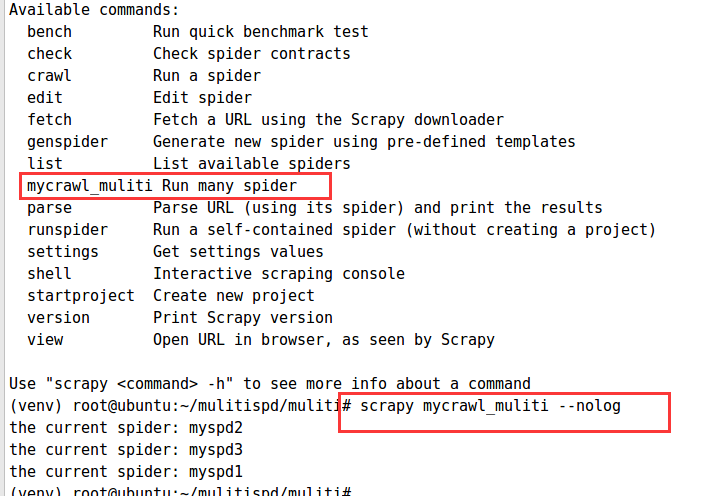
spd_loader_list= self.crawler_process.spider_loader.list() #获取所有的爬虫文件 for spname in spd_loader_list or args: #循环爬虫文件执行
self.crawler_process.crawl(spname, **opts.spargs)
print ("the current spider: "+spname )
self.crawler_process.start()
修改完以后,需要添加自定义命令,也可以说成注册信息
在settings.py里添加 COMMANDS_MODULE = "项目核心目录.自定义命令源码目录" #COMMANDS_MODULE = "muliti" #同级目录直接写命令源码目录即可
验证:
scrapy 基础的更多相关文章
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
- Learning Scrapy笔记(三)- Scrapy基础
摘要:本文介绍了Scrapy的基础爬取流程,也是最重要的部分 Scrapy的爬取流程 Scrapy的爬取流程可以概括为一个方程式:UR2IM,其含义如下图所示 URL:Scrapy的运行就从那个你想要 ...
- Scrapy基础(十三)————ItemLoader的简单使用
ItemLoader的简单使用:目的是解决在爬虫文件中代码结构杂乱,无序,可读性差的缺点 经过之前的基础,我们可以爬取一些不用登录,没有Ajax的,等等其他的简单的爬虫回顾我们的代码,是不是有点冗长, ...
- Scrapy基础(一) ------学习Scrapy之前所要了解的
技术选型: Scrapy vs requsts+beautifulsoup 1,reqests,beautifulsoup都是库,Scrapy是框架 2,Scrapy中可以加入reques ...
- scrapy基础教程
1. 安装Scrapy包 pip install scrapy, 安装教程 Mac下可能会出现:OSError: [Errno 13] Permission denied: '/Library/Pyt ...
- python scrapy 基础
scrapy是用python写的一个库,使用它可以方便的抓取网页. 主页地址http://scrapy.org/ 文档 http://doc.scrapy.org/en/latest/index.ht ...
- Scrapy基础(十四)————Scrapy实现知乎模拟登陆
模拟登陆大体思路见此博文,本篇文章只是将登陆在scrapy中实现而已 之前介绍过通过requests的session 会话模拟登陆:必须是session,涉及到验证码和xsrf的写入cookie验证的 ...
- 【Python】Scrapy基础
一.Scrapy 架构 Engine(引擎):负责 Spider(爬虫).Item Pipeline(管道).Downloader(下载器).Scheduler(调度器)中的通讯和数据传递. Sche ...
- scrapy基础二
应对反爬虫机制 ①.禁止cookie :有的网站会通过用户的cookie信息对用户进行识别和分析,此时可以通过禁用本地cookies信息让对方网站无法识别我们的会话信息 settings.py里开启禁 ...
随机推荐
- Auth模块使用方法大全
auth认证 导包 from django.contrib import auth 默认数据库中使用auth_user表 创建超级用户 python manage.py createsuperuser ...
- Django的View(视图)
Django的View(视图) 一个视图函数(类),简称视图,是一个简单的Python 函数(类),它接受Web请求并且返回Web响应. 响应可以是一张网页的HTML内容,一个重定向,一个404错误, ...
- 部署 Django
补充说明:关于项目部署,历来是开发和运维人员的痛点.造成部署困难的主要原因之一是大家的Linux环境不同,这包括发行版.解释器.插件.运行库.配置.版本级别等等太多太多的细节.因此,一个成功的部署案例 ...
- 最简单的socket服务器与客户端
服务器: //服务器 #include <stdio.h> #include <netinet/in.h> #include <unistd.h> #include ...
- oracle的用户账号密码设置
1. 可以用sqlplus system/你输入的密码 可以用sqlplus /nolog 可以用sqlplus /as sysdba2. @你scott.sql的路径3. 修改你的账号 alter ...
- BZOJ3275Number——二分图最大权独立集
题目描述 有N个正整数,需要从中选出一些数,使这些数的和最大.若两个数a,b同时满足以下条件,则a,b不能同时被选1:存在正整数C,使a*a+b*b=c*c2:gcd(a,b)=1 输入 第一行一个正 ...
- subprocess 模块
import subprocess # 就用来执行系统命令 import os cmd = r'dir D:\上海python全栈4期\day23 | findstr "py"' ...
- 洛谷P4891 序列(势能线段树)
洛谷题目传送门 闲话 考场上一眼看出这是个毒瘤线段树准备杠题,发现实在太难调了,被各路神犇虐哭qwq 考后看到各种优雅的暴力AC......宝宝心里苦qwq 思路分析 题面里面是一堆乱七八糟的限制和性 ...
- BSGS算法及扩展
BSGS算法 \(Baby Step Giant Step\)算法,即大步小步算法,缩写为\(BSGS\) 拔山盖世算法 它是用来解决这样一类问题 \(y^x = z (mod\ p)\),给定\(y ...
- [2017-7-25]Android Learning Day3
最近真的有点迷茫,感觉没有一个完整的教学体系很难进行下去,有的都是自己瞎捉摸,就跟以前ACM的时候一样,动不动就“这就是一道,水题暴力就行了”.“我们枚举一下所有的状态,找一下规律就行了”,mmp哟. ...