SQL Server-索引故事的遥远由来,原来是这样的?
前言
前段时间工作比较忙,每天回来也时不时去写有关ASP.NET Core的文章,无论是项目当中遇到的也好还是自学的也好都比较严谨的去叙述,喜欢分享,乐于分享这是我一直以来的态度,当然从中也会有些许错误,会去重新校验,接下来利用过年的几天时间将继续更新SQL Server系列,欢迎继续关注博客和个人公众号。
话题闲聊
关于SQL Server中索引已经讲了不少,为什么又拿出来讲,是源于个人看别人博客时冒出的想法,当学基础性东西时,本身就没有一个基本的知识体系,所以对于别人博客给出的定义或者是示例再进行定义,依然有种说不出的感觉,似乎明白又理解了,过了一段时间再去看却发现好像还是停留在表面,就像SQL Server中的索引,它可以说是索引的入门以及性能优化的非常重要的一个方面,如果没能很好的去理解,对于再去理解其他诸多索引依然很难啃下,所以有时候我一旦发现有更好的叙述方式就会再去唠叨一遍,不喜勿喷。
前台页面无论做的多么精致最终离不开数据的支撑,数据从何而来当然也就离不开我们键盘侠了,前端页面能够完美的呈现数据只能说是解决了用户体验的第一步,当用户查看某个页面时需要一直等待数据的加载,即使数据量巨大也要有个用户能够容忍的程度,否则将失去大量的用户,这个时候就需要留意数据库数据的优化了(排除其他因素),接下来我们进入索引的前世今生。
索引故事
唐代李世民为了使百姓修养生息、国泰民安,同时为了今后以文略来治理天下打下基础,于是就在长安做了试点设置图书馆,考虑到百姓在生息之余也能吸纳当前国家所执行的政策。图书馆所藏书籍成千上万,在每个图书架上书都没有进行任何编排,唐太宗李世民张榜告示这个消息后,百姓还是抱着怀疑的态度去看待这件事情,唐太宗不会又像之前隋朝皇帝一样是在谋划什么吧,第一天去的人都是那些求知若渴的知识分子,李世民安排房玄龄作为图书馆的管理人员,房玄龄认为这是大材小用,于是私下将这件事交给助理们去完成,自己则回自家府上休息去了,当第一个人需要一本书时,房玄龄助手不知道这本书放在哪个书架上的哪一排上,漫无目的花了6个小时到所有书架上才找到前来人员想要的那本书,但是后面排着队的人只能等待很长一段时间。
【SQL Server场景:这就像在表中没有建立主键一样,当需要在表中查找数据时,数据库引擎只能扫描所有表中的每一行来得到想要的那条行数据,所以执行起来则是非常慢】
第一批前去的人从书中受益匪浅,同时放榜的告示也被传开,前去借书的人每天都在增长,如此下来,房玄龄的助手们就苦逼了,这一天下来没借出去几本书却把自己累给半死,房玄龄(房儿)交代的事情没完成,到时皇帝老儿(小李)怪罪下来,岂是我等小儿能担待得了的,于是乎前去求救房儿,房儿听助手们讲述一番过后,房儿思索半天,立马交代助手们对所有书架上的书进行编号就可以解决他们的问题了,助手们本来累的一脸苦逼,当房儿这样一说还没明白过来脸上显示的却是十脸懵逼,唯唯诺诺的问了一句:房儿,我们可以从中受益可以不用再这么累了?房儿解释道,当前来的人给你们一本书的编号时,你们就可以很快找到书架上包含这本书的编号,然后你就可以找到这本书了,因为你们已经对这些书进行编号。
【SQL Server场景:对书进行唯一编号就像在数据库中表上创建了主键一样,当我们创建主键时,默认情况下,在B+树上就创建了一个聚集索引,包含了表中的所有行的数据页都会根据它们的主键值在磁盘文件系统上进行了物理排序,所以每当我们想要获取表中某一行记录时,数据库引擎就会优先去找使用了聚集索引的数据页(就像我们能够立马找到书在哪个书架上一样),接着很快就能找到在这个数据页上我们想要的行记录(就像找到这个书架上的那本我们想要的书一样)】
听到房儿的一番讲解后,助手们激动不已,开始对图书馆中的书进行编排,花了几天的时间对图书馆的所有书籍进行完整的编排,在此之后,到底房儿的方案管不管用呢,反正他也不顾这苦差事,要是小李怪罪下来,房儿将此罪名强加于我等之上,我们只能吃了这口黄连,他们几个助手相视一笑,我们可是机智的boy,行与不行,一试便知,他们开始进行测试,果不其然,房儿的方法果然好使, 到了第二天借书的人不出五分钟就拿到了他们想要的书,至此房儿的助手工作效率也提升了不少,脸上的苦逼和懵逼也慢慢褪去代替的是阳光般的笑容,那是相当的happy。
随着时间的慢慢推移,房儿助手们的麻烦又来了,一个前来借书的人打破了他们私下的娱乐,前来的人这份对知识的渴望和奋劲感染了他的老婆,他的老婆在长安小店里看到别人正在看的书籍上的插画吸引了她,所以她不知道书的编号却看到了书名,这下就难倒了房儿助手们,辛辛苦苦一个阶段,又回到解放前,他们只能到每个书架上去找那本书。这个过程花了一个小时才找到,他们开始感叹,开始未对书进行编排需要花费他们6个小时的时间,但是编排了之后,根据编号去拿书籍只需要5分钟,这种情况有了一个很大的改善,谁知道来了一个不按套路出牌的人,哎。。。。
【SQL Server场景:这就像我们在数据库中有一个Blog表,在这个表中我们建立了一个主键BlogId,这个时候创建了主键BlogId的聚集索引,但是只有这一个索引没有其他索引,当我们需要根据BlogName去查找Blog表时,此时只能去扫描进行物理排序的数据页来找到想要的那条数据记录】
房儿助手们不得已只能再去找房儿讨教,房儿助手们害怕房儿说他们一点想法都没有,他们弱弱的说了一句:要不我们对书名进行重新编排。房儿一句,你们tmd傻逼啊,其他拿着的编号肿么办,得不偿失,愚蠢之极。房儿略加思索,给他们提供了一个方案,创建一个目录,这个目录里面有书名和编号,同时对这个目录中的书名进行编排和分组。
【SQL Server场景:这就像我们在Blog表中对BlogName建立了非聚集索引,当我们需要根据BlogName来获取我们需要的行记录时,此时需要经过两步来完成,比如说我们要查找BlogName =‘Jeffcky’的行记录,我们对BlogName建立了非聚集索引,此时会直接跳到首字母为J并且找到名称为Jeffcky的数据,然后找到该BlogName对应的编号,接下来就根据主键BlogId去查找对应的数据页记录】
听到房儿的完美方案之后,房儿助手们开始去创建书名的目录,接着开始进行测试,现在又只需要几分钟就快速查找到任何想要的数据,从此之后来借书的百姓获取书的速度越来越快,并且来图书馆借书的人越来越多,李世民于是在各个城池建立了图书馆,至此之后老百姓的修养和素质逐渐得到了显著的提升。
通过上述讲解之后,不知道已经看完本文的你是否已经完全理解,充分理解索引内部机制对于如何恰当创建索引是非常重要的,我们再来将整个过程梳理一遍,例如,我们有一个Blog表,此时会创建一个聚集索引(在Blog表中创建主键时默认会主动创建聚集索引),比如我们要查找BlogName,此时需要在BlogName这一列上创建非聚集索引,此时BlogName会被存储到索引页上,每个索引页上会有BlogName以及携带主键值即BlogId,当我们需要根据BlogName去查找数据时,此时回去非聚集索引树上去查找对应的聚集索引的主键值,一旦查找到主键值,接着回去聚集索引树上根据主键值去查找我们实际需要的行记录数据。如下为索引树示例图:

(图片来源:http://www.cnblogs.com/CareySon/archive/2011/12/22/2297568.html)
索引树中有三个节点,分别是根节点、中间节点(翻译不知是否准确)、叶子节点。中间节点包含一个范围值,当我们查找数据时首先从根节点开始查找,接着根据值从中间节点某一个范围去查找,然后到叶子节点,叶子节点是实际存储索引值的节点,当然如果该树是聚集索引树,那么叶子节点则存储的物理数据页即实际行数据,如果该树为非聚集索引树,那么叶子节点包含的则是索引值和聚集索引的键,查找我们需要的数据的整个过程大概是这样。
过了几年后,图书馆管理人员进行了更换,此时新晋的管理人员却发现,当别人再来借书时,此时根据原来的编号去拿书和实际需要借的书完全不一样,后来新晋管理人员发现有些人借了书之后将书弄丢了,开明的小李也不再追究,但是这对图书馆管理员造成了一定的困扰,编号对应架上的书明显是不一致的,查找所需书的效率有了明显的下降,针对于这种情况,图书管理员不得不对书进行重新编排。
【SQL Server场景:这就像当我们对数据库中表上的列建立恰当索引之后却没有得到我们期望的性能改善,例如,通过更新和删除就会造成索引碎片的出现(就像上述中借了书的百姓将书弄丢了,此时放书的那个格子就会空了出来,造成了资源的浪费,造成了所放书籍的格子的不连续性即断层也就是我们所说的索引碎片)】
通过对上述的描述想必你已经清楚了什么是索引碎片,当我们对数据库进行频繁的插入、更新、删除就会引起索引碎片,如果在数据库中存在大量的索引碎片可能会耗费大量的时间来扫描/查找索引或者根本不使用索引造成全表扫描,那么结果就是查询性能低下。索引碎片有两种类型:
(1)内部索引碎片:出现在当对数据页上的数据进行更新或者删除时,结果会引起在索引页或者数据页上的数据以稀疏矩阵的形式进行分布,也就是说在页上创建许多空行,也会引起数据页或者索引页的增加从而增加查询执行时间。
(2)外部索引碎片:出现在当对数据页上的数据进行插入或者更新时,结果会引起页拆分和在磁盘文件系统上数据页或者索引页重新分配的不连续性。这严重降低了性能,当然取决于是否在查询结果集上的WHERE条件上指定了一定的范围。因为无法保证下一个相关联数据页是连续的,所以不会进行预读操作,下一个相关联数据页可能在数据文件的任何地方。
那么我们怎么知道是否出现了索引碎片呢,这里我们给出一个通用查看数据库是否出现索引碎片的代码,将下面AdventureWorks2012代替为你的目标数据库即可
SELECT object_name(dt.object_id) Tablename,si.name
IndexName,dt.avg_fragmentation_in_percent AS
ExternalFragmentation,dt.avg_page_space_used_in_percent AS
InternalFragmentation
FROM
(
SELECT object_id,index_id,avg_fragmentation_in_percent,avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats (db_id('AdventureWorks2012'),null,null,null,'DETAILED'
)
WHERE index_id <> ) AS dt INNER JOIN sys.indexes si ON si.object_id=dt.object_id
AND si.index_id=dt.index_id AND dt.avg_fragmentation_in_percent>
AND dt.avg_page_space_used_in_percent< ORDER BY avg_fragmentation_in_percent DESC
如下是查看AdventureWorks2012索引碎片的情况
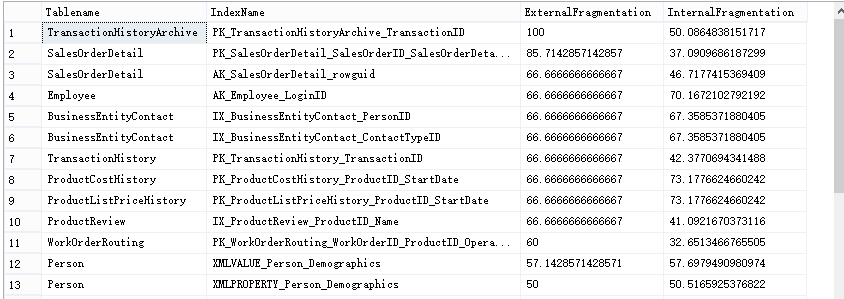
通过如下规则来对比是否已经出现索引碎片。
(1)当ExternalFragmentation > 10时说明出现了外部索引碎片。
(2)当InternalFragmentation < 75时说明出现了内部索引碎片。
上面我们分析索引碎片以及判定索引碎片的规则,那么我们又该如何进行磁盘索引碎片整理呢?如下有两种方式,我们接着往下讲。
(1)通过如下代码重组磁盘索引碎片
ALTER INDEX ALL ON TableName REORGANIZE
(2)通过如下代码重建磁盘索引碎片
ALTER INDEX ALL ON TableName REBUILD WITH (FILLFACTOR=,ONLINE=ON)
当然我们也可以通过数据库中UI界面的形式来重组和重建索引碎片。那么问题又来了,我们又应该什么时候来重组和重建索引碎片呢?我们再往下看。
当标识外部索引碎片中的列ExternalFragmentation在10-15之间并且标识内部索引碎片中的列InternalFragmentation在60-75之间应该重组索引碎片,否则应该重建索引碎片。
重建索引比较重要的一点是,当对特定的表进行重建索引时,此时整个表将会被加锁,这种情况在重组索引中不会出现,所以如果在生产环境中的数据库服务器上重建索引时,对于大表需要很久才能完成,但是在SQL Server 2005之后有了一个解决方案,可以通过如上设置ONLINE = ON即可。
总结
貌似这是写博客以来没有出现什么实践代码的一篇博客,虽然写博客是非常耗费时间和精力的一件事情,但是乐在其中,同时在写博客的过程中也一直在探索怎样才能将写出的博客通俗易懂并且让大家能够接受,以上故事纯属虚构,如有雷同,请联系我,说你不是抄袭的。本节我们重点讲述了索引的理论知识,对于其他如覆盖索引、过滤索引等我们在前面系列都已经详细讨论过,有所疑惑的地方请参考前面系列。下节我们开始讲述事务,敬请期待。
SQL Server-索引故事的遥远由来,原来是这样的?的更多相关文章
- SQL Server-索引故事的遥远由来,原来是这样的?(二十八)
前言 前段时间工作比较忙,每天回来也时不时去写有关ASP.NET Core的文章,无论是项目当中遇到的也好还是自学的也好都比较严谨的去叙述,喜欢分享,乐于分享这是我一直以来的态度,当然从中也会有些许错 ...
- SQL Server索引 (原理、存储)聚集索引、非聚集索引、堆 <第一篇>
一.存储结构 在SQL Server中,有许多不同的可用排列规则选项. 二进制:按字符的数字表示形式排序(ASCII码中,用数字32表示空格,用68表示字母"D").因为所有内容都 ...
- SQL Server索引进阶:第一级,索引简介
这个并不是我翻译的,全文共有15篇,但我发现好多网站已经不全,所以自己整理. 原文地址: Stairway to SQL Server Indexes: Level 1, Introduction t ...
- 【译】索引进阶(一):SQL SERVER索引介绍
[译注:此文为翻译,由于本人水平所限,疏漏在所难免,欢迎探讨指正] 原文链接:http://www.sqlservercentral.com/articles/Stairway+Series/7 ...
- sql server 索引总结一
一.存储结构 在SQL Server中,有许多不同的可用排列规则选项. 二进制:按字符的数字表示形式排序(ASCII码中,用数字32表示空格,用68表示字母"D").因为所有内容都 ...
- 【译】SQL Server索引进阶第八篇:唯一索引
原文:[译]SQL Server索引进阶第八篇:唯一索引 索引设计是数据库设计中比较重要的一个环节,对数据库的性能其中至关重要的作用,但是索引的设计却又不是那么容易的事情,性能也不是那么轻易就 ...
- 转: SQL Server索引的维护 - 索引碎片、填充因子
转:http://www.cnblogs.com/kissdodog/archive/2013/06/14/3135412.html 实际上,索引的维护主要包括以下两个方面: 页拆分 碎片 这两个问题 ...
- SQL Server 索引结构及其使用(一)
转载:SQL Server 索引结构及其使用(一) 作者:freedk 一.深入浅出理解索引结构 实际上,您可以把索引理解为一种特殊的目录.微软的SQL SERVER提供了两种索引:聚集索引(clus ...
- SQL Server 索引的图形界面操作 <第十二篇>
一.索引的图形界面操作 SQL Server非常强大的就是图形界面操作.关于索引方面也一样那么强大,很多操作比如说重建索引啊,查看各种统计信息啊,都能够通过图形界面快速查看和操作,下面来看看SQL S ...
随机推荐
- jQuery + json 实现省市区三级联动
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 简单制作 OS X Yosemite 10.10 正式版U盘USB启动安装盘方法教程 (全新安装 Mac 系统)
原文地址: http://www.iplaysoft.com/osx-yosemite.html 简单制作 Mac OS X Yosemite 正式版 USB 启动盘的方法教程: 其实制作 OS X ...
- 一个UWSGI的例子
摘要:uwsgi执行顺序:启动master进程,执行python脚本的公共代码(import同一层).然后生成worker进程,uwsgi.post_fork_hook=init_functions, ...
- CodeForces 620E New Year Tree
线段树+位运算 首先对树进行DFS,写出DFS序列,记录下每一个节点控制的区间范围.然后就是区间更新和区间查询了. 某段区间的颜色种类可以用位运算来表示,方便计算. 如果仅有第i种颜色,那么就用十进制 ...
- java数组的声明由几种方式
数组的声明由几种方式: 1,String []a = new String[length];再赋值 a[0]=?;....... 2,new完就直接初始化: String []a = new Stri ...
- 7、手把手教你Extjs5(七)自定义菜单1
顶部和底部区域已经作好,在顶部区域有一个菜单的按钮,这一节我们设计一个菜单的数据结构,使其可以展示出不同样式的菜单.由于准备搭建的是一个系统模块自定义的系统,因此菜单也是自定义的,在操作员系统登录的时 ...
- Android应用运行过程(转)
源:Android应用运行过程 首先,ActivityThread从main()函数开始执行,调用prepareMainLooper()为UI线程创建一个消息队列(MessageQueue). 然后创 ...
- 【转】Linux Shell脚本面试25问
Q:1 Shell脚本是什么.它是必需的吗? 答:一个Shell脚本是一个文本文件,包含一个或多个命令.作为系统管理员,我们经常需要使用多个命令来完成一项任务,我们可以添加这些所有命令在一个文本文件( ...
- Leetcode 182. Duplicate Emails
Write a SQL query to find all duplicate emails in a table named Person. +----+---------+ | Id | Emai ...
- Built-in functions
转自::http://blog.csdn.net/luyuncheng/article/details/11674123 — Built-in Function: int __builtin_ff ...