PrefixSpan算法原理总结
前面我们讲到频繁项集挖掘的关联算法Apriori和FP Tree。这两个算法都是挖掘频繁项集的。而今天我们要介绍的PrefixSpan算法也是关联算法,但是它是挖掘频繁序列模式的,因此要解决的问题目标稍有不同。
1. 项集数据和序列数据
首先我们看看项集数据和序列数据有什么不同,如下图所示。
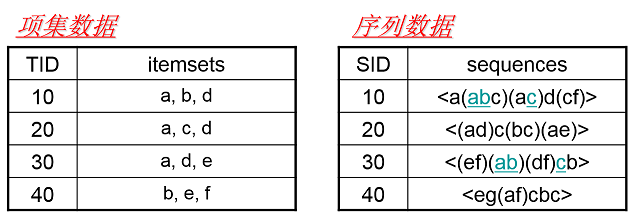
左边的数据集就是项集数据,在Apriori和FP Tree算法中我们也已经看到过了,每个项集数据由若干项组成,这些项没有时间上的先后关系。而右边的序列数据则不一样,它是由若干数据项集组成的序列。比如第一个序列<a(abc)(ac)d(cf)>,它由a,abc,ac,d,cf共5个项集数据组成,并且这些项有时间上的先后关系。对于多于一个项的项集我们要加上括号,以便和其他的项集分开。同时由于项集内部是不区分先后顺序的,为了方便数据处理,我们一般将序列数据内所有的项集内部按字母顺序排序。
2. 子序列与频繁序列
了解了序列数据的概念,我们再来看看上面是子序列。子序列和我们数学上的子集的概念很类似,也就是说,如果某个序列A所有的项集在序列B中的项集都可以找到,则A就是B的子序列。当然,如果用严格的数学描述,子序列是这样的:
对于序列A={$a_1,a_2,...a_n$}和序列B={$b_1,b_2,...b_m$},$n \leq m$,如果存在数字序列$1 \leq j_1 \leq j_2 \leq ... \leq j_n \leq m$, 满足$a_1 \subseteq b_{j_1}, a_2 \subseteq b_{j_2}...a_n \subseteq b_{j_n} $,则称A是B的子序列。当然反过来说, B就是A的超序列。
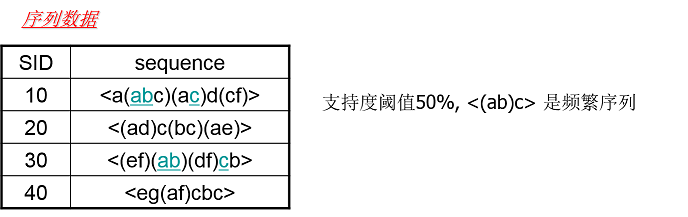
而频繁序列则和我们的频繁项集很类似,也就是频繁出现的子序列。比如对于下图,支持度阈值定义为50%,也就是需要出现两次的子序列才是频繁序列。而子序列<(ab)c>是频繁序列,因为它是图中的第一条数据和第三条序列数据的子序列,对应的位置用蓝色标示。
3. PrefixSpan算法的一些概念
PrefixSpan算法的全称是Prefix-Projected Pattern Growth,即前缀投影的模式挖掘。里面有前缀和投影两个词。那么我们首先看看什么是PrefixSpan算法中的前缀prefix。
在PrefixSpan算法中的前缀prefix通俗意义讲就是序列数据前面部分的子序列。如果用严格的数学描述,前缀是这样的:对于序列A={$a_1,a_2,...a_n$}和序列B={$b_1,b_2,...b_m$},$n \leq m$,满足$a_1 =b_1 , a_2 = b_2...a_{n-1} = b_{n-1} $,而$a_n \subseteq b_n $,则称A是B的前缀。比如对于序列数据B=<a(abc)(ac)d(cf)>,而A=<a(abc)a>,则B是A的前缀。当然B的前缀不止一个,比如<a>, <aa>, <a(ab)> 也都是B的前缀。
看了前缀,我们再来看前缀投影,其实前缀投影这儿就是我们的后缀,有前缀就有后缀嘛。前缀加上后缀就可以构成一个我们的序列。下面给出前缀和后缀的例子。对于某一个前缀,序列里前缀后面剩下的子序列即为我们的后缀。如果前缀最后的项是项集的一部分,则用一个“_”来占位表示。
下面这个例子展示了序列<a(abc)(ac)d(cf)>的一些前缀和后缀,还是比较直观的。要注意的是,如果前缀的末尾不是一个完全的项集,则需要加一个占位符。
在PrefixSpan算法中,相同前缀对应的所有后缀的结合我们称为前缀对应的投影数据库。

4. PrefixSpan算法思想
现在我们来看看PrefixSpan算法的思想,PrefixSpan算法的目标是挖掘出满足最小支持度的频繁序列。那么怎么去挖掘出所有满足要求的频繁序列呢。回忆Aprior算法,它是从频繁1项集出发,一步步的挖掘2项集,直到最大的K项集。PrefixSpan算法也类似,它从长度为1的前缀开始挖掘序列模式,搜索对应的投影数据库得到长度为1的前缀对应的频繁序列,然后递归的挖掘长度为2的前缀所对应的频繁序列,。。。以此类推,一直递归到不能挖掘到更长的前缀挖掘为止。
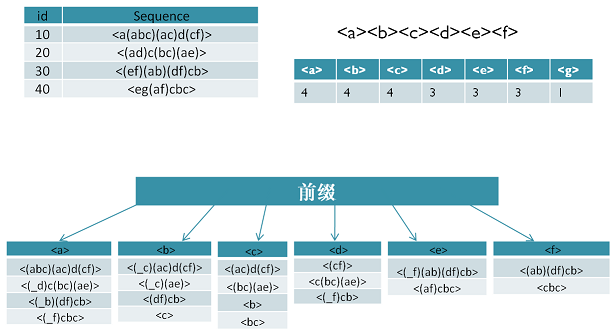
比如对应于我们第二节的例子,支持度阈值为50%。里面长度为1的前缀包括<a>, <b>, <c>, <d>, <e>, <f>,<g>我们需要对这6个前缀分别递归搜索找各个前缀对应的频繁序列。如下图所示,每个前缀对应的后缀也标出来了。由于g只在序列4出现,支持度计数只有1,因此无法继续挖掘。我们的长度为1的频繁序列为<a>, <b>, <c>, <d>, <e>,<f>。去除所有序列中的g,即第4条记录变成<e(af)cbc>
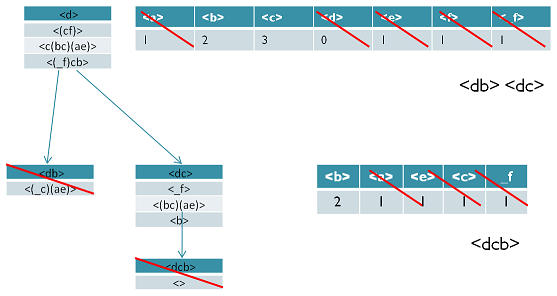
现在我们开始挖掘频繁序列,分别从长度为1的前缀开始。这里我们以d为例子来递归挖掘,其他的节点递归挖掘方法和D一样。方法如下图,首先我们对d的后缀进行计数,得到{a:1, b:2, c:3, d:0, e:1, f:1,_f:1}。注意f和_f是不一样的,因为前者是在和前缀d不同的项集,而后者是和前缀d同项集。由于此时a,d,e,f,_f都达不到支持度阈值,因此我们递归得到的前缀为d的2项频繁序列为<db>和<dc>。接着我们分别递归db和dc为前缀所对应的投影序列。首先看db前缀,此时对应的投影后缀只有<_c(ae)>,此时_c,a,e支持度均达不到阈值,因此无法找到以db为前缀的频繁序列。现在我们来递归另外一个前缀dc。以dc为前缀的投影序列为<_f>, <(bc)(ae)>, <b>,此时我们进行支持度计数,结果为{b:2, a:1, c:1, e:1, _f:1},只有b满足支持度阈值,因此我们得到前缀为dc的三项频繁序列为<dcb>。我们继续递归以<dcb>为前缀的频繁序列。由于前缀<dcb>对应的投影序列<(_c)ae>支持度全部不达标,因此不能产生4项频繁序列。至此以d为前缀的频繁序列挖掘结束,产生的频繁序列为<d><db><dc><dcb>。
同样的方法可以得到其他以<a>, <b>, <c>, <e>, <f>为前缀的频繁序列。
5. PrefixSpan算法流程
下面我们对PrefixSpan算法的流程做一个归纳总结。
输入:序列数据集S和支持度阈值$\alpha$
输出:所有满足支持度要求的频繁序列集
1)找出所有长度为1的前缀和对应的投影数据库
2)对长度为1的前缀进行计数,将支持度低于阈值$\alpha$的前缀对应的项从数据集S删除,同时得到所有的频繁1项序列,i=1.
3)对于每个长度为i满足支持度要求的前缀进行递归挖掘:
a) 找出前缀所对应的投影数据库。如果投影数据库为空,则递归返回。
b) 统计对应投影数据库中各项的支持度计数。如果所有项的支持度计数都低于阈值$\alpha$,则递归返回。
c) 将满足支持度计数的各个单项和当前的前缀进行合并,得到若干新的前缀。
d) 令i=i+1,前缀为合并单项后的各个前缀,分别递归执行第3步。
6. PrefixSpan算法小结
PrefixSpan算法由于不用产生候选序列,且投影数据库缩小的很快,内存消耗比较稳定,作频繁序列模式挖掘的时候效果很高。比起其他的序列挖掘算法比如GSP,FreeSpan有较大优势,因此是在生产环境常用的算法。
PrefixSpan运行时最大的消耗在递归的构造投影数据库。如果序列数据集较大,项数种类较多时,算法运行速度会有明显下降。因此有一些PrefixSpan的改进版算法都是在优化构造投影数据库这一块。比如使用伪投影计数。
当然使用大数据平台的分布式计算能力也是加快PrefixSpan运行速度一个好办法。比如Spark的MLlib就内置了PrefixSpan算法。
不过scikit-learn始终不太重视关联算法,一直都不包括这一块的算法集成,这就有点落伍了。
(欢迎转载,转载请注明出处。欢迎沟通交流: pinard.liu@ericsson.com)
PrefixSpan算法原理总结的更多相关文章
- 用Spark学习FP Tree算法和PrefixSpan算法
在FP Tree算法原理总结和PrefixSpan算法原理总结中,我们对FP Tree和PrefixSpan这两种关联算法的原理做了总结,这里就从实践的角度介绍如何使用这两个算法.由于scikit-l ...
- Bagging与随机森林算法原理小结
在集成学习原理小结中,我们讲到了集成学习有两个流派,一个是boosting派系,它的特点是各个弱学习器之间有依赖关系.另一种是bagging流派,它的特点是各个弱学习器之间没有依赖关系,可以并行拟合. ...
- RSA算法原理
一直以来对linux中的ssh认证.SSL.TLS这些安全认证似懂非懂的.看到阮一峰博客中对RSA算法的原理做了非常详细的解释,看完之后茅塞顿开,关于RSA的相关文章如下 RSA算法原理(一) RSA ...
- LruCache算法原理及实现
LruCache算法原理及实现 LruCache算法原理 LRU为Least Recently Used的缩写,意思也就是近期最少使用算法.LruCache将LinkedHashMap的顺序设置为LR ...
- MySQL索引背后的数据结构及算法原理【转】
本文来自:张洋的MySQL索引背后的数据结构及算法原理 摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持 ...
- OpenGL学习进程(13)第十课:基本图形的底层实现及算法原理
本节介绍OpenGL中绘制直线.圆.椭圆,多边形的算法原理. (1)绘制任意方向(任意斜率)的直线: 1)中点画线法: 中点画线法的算法原理不做介绍,但这里用到最基本的画0<=k ...
- 支持向量机原理(四)SMO算法原理
支持向量机原理(一) 线性支持向量机 支持向量机原理(二) 线性支持向量机的软间隔最大化模型 支持向量机原理(三)线性不可分支持向量机与核函数 支持向量机原理(四)SMO算法原理 支持向量机原理(五) ...
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- Logistic回归分类算法原理分析与代码实现
前言 本文将介绍机器学习分类算法中的Logistic回归分类算法并给出伪代码,Python代码实现. (说明:从本文开始,将接触到最优化算法相关的学习.旨在将这些最优化的算法用于训练出一个非线性的函数 ...
随机推荐
- MySQL 同步状态
Exec_Master_Log_Pos: The position of the last event executed by the SQL thread from the master's bin ...
- linux获得目录下文件个数
获得当前目录下文件个数赋值给变量panonum: panonum=$(ls -l |grep "^-" | wc -l) 获取指定目录下文件个数赋值给指定变量: panonum=$ ...
- Delphi Math里的基本函数,以及浮点数比较函数(转)
源:Delphi Math里的基本函数,以及浮点数比较函数 Delphi里的好东西太多,多到让人觉得烦.这种感觉就是当年打游戏<英雄无敌3>,改了钱以后,有钱了每天都要造建筑,明明是好事, ...
- 在PHP语言中使用JSON
目前,JSON已经成为最流行的数据交换格式之一,各大网站的API几乎都支持它. 我写过一篇<数据类型和JSON格式>,探讨它的设计思想.今天,我想总结一下PHP语言对它的支持,这是开发 ...
- EF dbcontext上下文的处理
,那么我们整个项目里面上下文的实例会有很多个,我们又遇到了多次,当我们在编程的时候遇到多的时候,一般我们就要想想能不能解决多这个问题. (2)这里我要说的是EF上下文怎么管理呢?很简单啦,就是要保证线 ...
- p1349星屑幻想
这道题的原题目我也不知道是什么. 大致题意是有一个图,有些点的权值已确定,要求你确定其他点的权值使所有边两个点的权值的xor和最小,输出所有点的最终权值,输出有spj: 解法是最小割,由于题目要求的使 ...
- MySQL密码过期策略
如果要设置密码永不过期的全局策略,可以这样:(注意这是默认值,配置文件中可以不声明) [mysqld] default_password_lifetime=0 禁用密码过期: ALTER USER ' ...
- UVa 357 - Let Me Count The Ways
题目大意:也是硬币兑换问题,与147.674用同样的方法即可解决. #include <cstdio> #include <cstring> #define MAXN 3000 ...
- 环信 之 iOS 客户端集成三:基础功能
SDK中,大部分与网络有关的操作,都有三种方法: 同步方法 通过delegate回调的异步方法.要想能收到回调,必须要注册为:[[EaseMob sharedInstance].chatManager ...
- 360路由器+花生壳实现外网访问SVN服务器
注册花生壳账号 花生壳注册地址:https://console.oray.com/passport/register.html?fromurl=http%3A%2F%2Fhsk.oray.com%2F ...