JVM(上)
堆、栈
JVM内存≈Heap(堆内存)+PermGen(方法区)+Thrend(栈)
Heap(堆内存)=Young(年轻代)+Old(老年代),官方文档建议整个年轻代占整个堆内存的3/8,老年代占整个堆内存的5/8,但是可以配置为其他比例。
Young(年轻代)=EdenSpace+FromSurvivor+ToSurvivor,Eden区与两个存活区的内存大小比例是:8:1:1,同样可以配置为其他比例。
java项目内,迈不过去的两点:堆和栈,那么堆里面放的是什么?栈里面放的又是什么?
- 栈是运行时的单位,而堆是存储的单位。
- 栈解决程序的运行问题,即程序如何执行,或者说如何处理数据;堆解决的是数据存储的问题,即数据怎么放、放在哪儿。栈的优势是存取速度比堆要快,仅次于寄存器,栈数据可以共享。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性
- 在Java中一个线程就会相应有一个线程栈与之对应,这点很容易理解,因为不同的线程执行逻辑有所不同,因此需要一个独立的线程栈。而堆则是所有线程共享的。栈因为是运行单位,因此里面存储的信息都是跟当前线程(或程序)相关信息的。包括局部变量、程序运行状态、方法返回值等等;而堆只负责存储对象信息。堆的优势是可以动态地分配内存大小,但缺点是,由于要在运行时动态分配内存,存取速度较慢。
简而言之:
栈里面放占内存小的东西:常量,静态变量,以及一些方法等那些不变的。栈是非堆内的一部分
堆里面放 new 出来的对象,数组,占大量内存的那些东西。
然后,我们用jmeter去压这个接口,结果内存溢出:
这个是我们最常见的,堆内存溢出提示结果

那么问题来了,为什么堆内存会溢出,有的程序不会溢出,有的会溢出呢?我们今天就是带着这个问题,来看JVM的堆内存
GC的原理&步骤
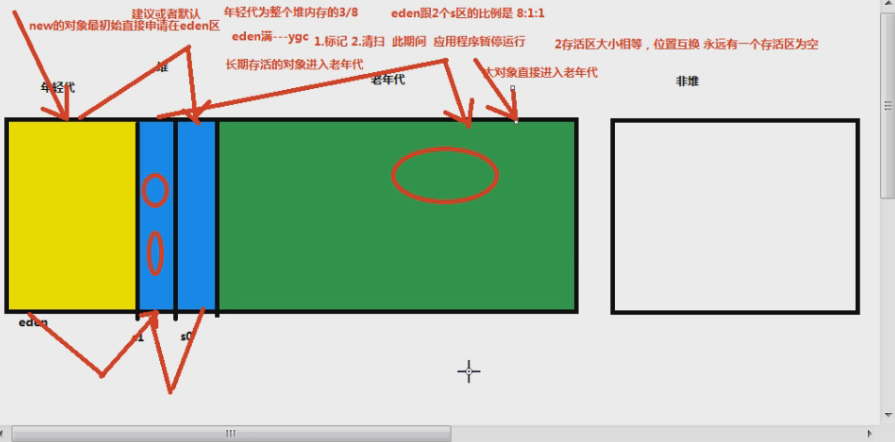
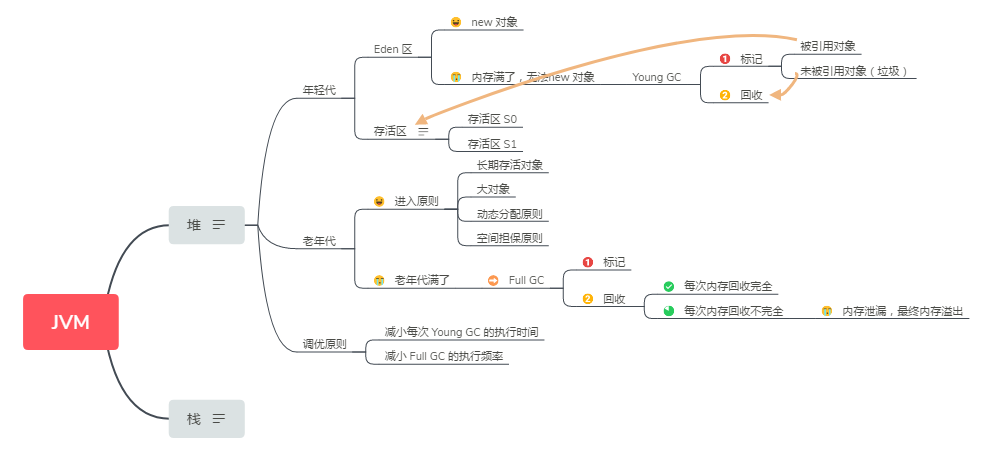
堆,首先分为两块:年轻代+老年代;年轻代里面又有三块:Eden区 + S0区 + S1区,其中S0和S1统称为Survivor,存活区。
- 存活区0和存活区1,大小相等,位置互换;大小关系:老年代>年轻代>存活区
- 官方建议年轻代为整个堆内存的 3/8 ,老年代为 5/8 ,年轻代内,Eden跟两个存活区的比例为 8:1:1
Young GC
1、Eden区:可以理解为初始的地方,第一次开始发生的地方,也就是new的对象,最初始,直接生成在 Eden 区。比如 new project 要分配工作区间,就是往 Eden 区内放。
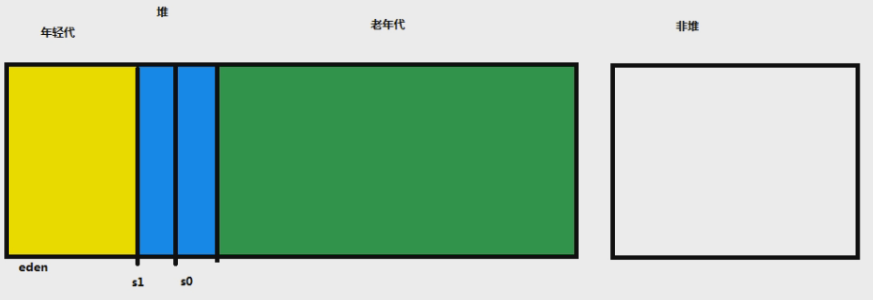
2、放着放着,Eden 区总有放满的时候(按照官方建议,Eden为整个堆内存的3/8 的 80%,也就是30%),那Eden区放满了咋办?
就会触发 young GC,young 指的是年轻代,触发年轻代GC,触发 young GC ,怎么去young GC呢?
第一步,会去寻根判断,判断什么东西?判断的对象是否为垃圾,垃圾的标准是对象等是否还在被使用或引用,还在被引用的肯定不能被回收。如果对象没有被引用,那么肯定就得被回收
第二步,进行垃圾的清扫操作,也就是说,把没被引用的对象,给干掉,有引用的怎么办???给挪到存活区里面,假设挪到存活区0
注意:Eden区满了,代码是不能继续运行的,也就是在 young GC 期间,程序是会暂停运行的
这种情况下,整个Eden区就空了,空了之后,new 的对象又可以往 Eden 区存放,才可以继续运行程序。

3、new 的对象继续往 Eden 区存放,放着放着,又放满了,怎么办?
当然是再进行 young GC ,把被引用的对象往存货区挪,上一步我们是往 存货区 S0 存放的,这一次就往 存货区 S1内存放,同时把 S0 内的对象放进 S1 这就叫位置互换。所以这种情况下,两个存活区,永远有一个为空,不可能两个存活区同时满
那么只是这样么?其实不然, young GC 也是会寻根判断存活区内的对象的,也是就会去判断 S0 内的对象是否被引用,如果没有被引用,一样会被清除,所以 S0 内被挪到 S1 内的对象是被引用的对象

4、按照上面的过程, young GC 就是这么执行在年轻代的,如此循环往复
什么情况下对象进入老年代
这里你可能会问呢,那么只有 Young GC 么 ?我们的老年代还分了那么大一块内存呢,用来干什么的?
那么,什么对象能进入老年代呢?原则有哪几个?(往老年代内挪,都是发生在 Young GC 阶段内)
长期存活的对象进入老年代(Young GC 多次还存在年轻代,默认是15次,age>15,这个age是可配置的)
大对象直接进入老年代(多大算大?也是有参数指定的,默认是多少?XX:+PretenuerSizeThreshold 控制”大对象的“的大小),这样做的目的是避免在Eden区及两个Survivor区之间发生大量的内存复制,因为 Eden 比较小,如果大对象进 Eden,那么会频繁Young GC
动态分配原则(往下看)
空间担保原则(往下看)
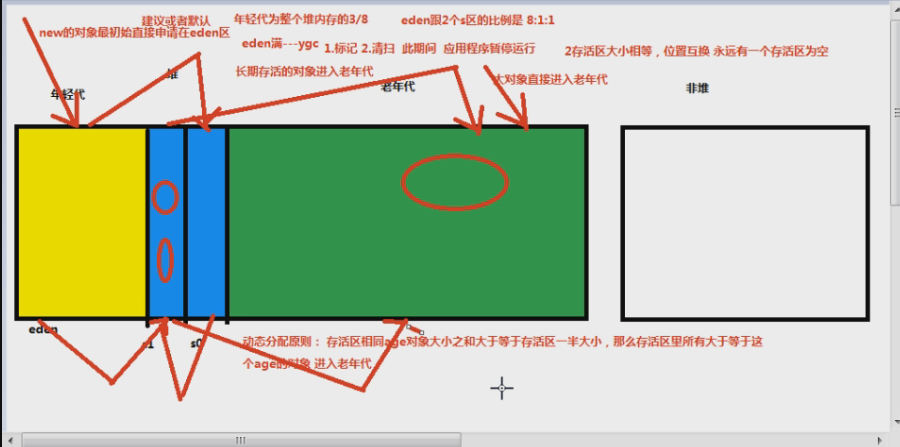
试想下,是不是有一种特殊情况,存活区我放满了,之后 Eden 区也满了,在执行 Young GC 的过程中,怎么GC?往存活区放肯定是放不下的,那么怎么解决?也就是怎么避免存活区放不下的尴尬情况。
动态分配原则:存活区相同 age 对象内存大小之和 >= 存活区的一半内存大小,那么存活区内所有大于等于这个 age 的对象全部进入老年代
假设有以下几个对象
| A | B | C | D | E | F | G | H | I | G | K | L | O | M | N | O | P | Q | R | S | T |
| 1 | 2 | 2 | 3 | 3 | 4 | 6 | 8 | 9 | 7 | 6 | 2 | 3 | 10 | 8 | 7 | 6 | 5 | 4 | 3 | 2 |
假设,存活区 age 为 4 的对象内存大小之和(F+R) > 存活区一半内存大小,那么存活区内,所有 >= 4 的所有对象,全部进入老年代,也就是上表的:F,G,H,I,J,K,M,N,O,P,Q,R,都进入老年代
这就是动态分配原则
空间担保原则:会去根据历史经验算法去计算,下次 Young GC 大概会有多少对象进入老年代,然后去判断,老年代能否放下,放不下,之后不会执行 Young GC而是触发空间担保原则, 而是执行 Full GC
也就是说,老年代满了,触发 Full GC ,那么 Full GC 会产生什么影响?
触发 Full GC,会清扫整个堆以及非堆内存,Full GC 的耗时比 Young GC 长。相当于清扫整个屋子和整栋楼的区别。Full GC 的步骤其实是一样的,先判定对象是否被引用;下一步做清扫操作,清扫没有被引用的对象;那么引用的对象放哪?当然是放在 老年代区内,对象是不可能扔到非堆里面的。
那么可以理解,Full GC 清扫的是整个堆+非堆,存活的对象依旧在老年代里面。耗时肯定很长
那么再极端点,假设我们 Full GC 后,在老年代内依旧是满的,会出现什么情况?就会出现我们刚的那个错误。往老年代里面放不进去,Full GC 之后也放不进去,就会报这个错误

也就是说,内存曲线是这样:每次 Full GC ,内存没有释放回收到底的话,剩余的存活对象越来越多,剩余内存就越来越小。是很容易出现内存泄漏,最终导致内存溢出(图中红线)
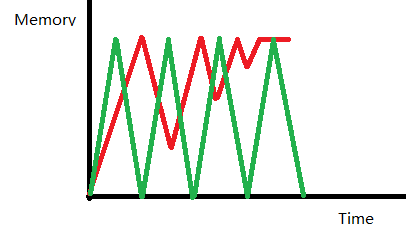
内存泄漏跟溢出有什么区别?泄漏是过程,溢出是结果
那么我们想要的结果是什么?是绿线,每次垃圾回收,都能将内存彻底地回收,没有剩余的对象和内存被占用
那内存溢出了,怎么办?
正确做法是找到内存溢出的原因并解决,关机重启并不能解决问题
有几个注意点
一、Full GC 出现在什么时候?
1、老年代满的时候
2、 大对象进老年代的时候。
3、还有清非堆内存的时候。
4、代码内显示调用 Full GC 方法(System.gc();和Runtime.getRuntime().gc();)
5、进行 jmap -dump 的时候
6、RMI 框架
二、Young GC 出现在什么时候?有且只会在 Eden 区满的时候触发,存活区只可能有一个满,不会说等到两个存活区满了,Eden区满了再去 Young GC,这种说法是错误的。
三、JVM调优的核心原则:
尽可能让 Full GC 的次数或者频率小一些,延长其间隔时间
尽可能减少每次执行 Young GC 的执行时间,次数我们控制不了
JVM垃圾回收机制

1、new出来的对象先放在Eden区,Eden区放满后第一次触发Young GC(垃圾回收),把存活对象移到S1存活区。
2、第二次Eden区又满了,再次触发Young GC,把Eden区的存活对象移到S1存活区,把S0存活区的存活对象也移到S2存活区,这时S1存活区清空了。
3、第三次Eden区又满了,再次触发Young GC,把Eden区的存活对象移到S0存活区,把S1存活区的存活对象也移到S1存活区,这时S2存活区清空了。
4、这样S0和S1交替互换,轮流为清空,大大拉长了存活对象进入老年代的时间间隔。
类对象什么时候进入老年代:
a、大对象直接进入老年代:Eden区放不下直接进入老年代
b、长期存活的对象进入老年代:以Young GC次数进行判断的,默认次数15次后进入老年代
c、执行Young GC时,存活区放不下时,存活对象也直接进入老年代
5、一直这样循环往复直到老年代满了,触发Full GC。首先清除老年代中的没有引用的对象,再对Eden区进行GC,还会对持久代进行GC(持久代一般没什么可清理)
6、老年代里面放满以后,执行Full GC也释放不了内存空间,就会报内存溢出的错误了。
总结:
1、Young GC只发生在Eden区,Eden区是整个Java堆内存分配的入口,new对象优先分配到Eden区,Eden区满之后触发Young GC
2、Young GC触发后,然后它会判断Eden区的对象是否是存活的,如果是存活的则放到存活区,不是存活的则清除掉释放内存空间。
3、触发Full GC是虽然也清理了Eden区,但是Young GC次数不会+1,它是Full GC在干活。
什么时候触发Full GC:
a、老年代空间不足
b、持久代空间不足的时候也会触发Full GC
c、显示调用也可以触发Full GC,比如说RunTime.GC、System.GC
d、RMI框架,会产生大量的对象,会进行显示调用,触发Full GC
e、Young GC时的悲观策略dump live的内存信息时(jmap-dump:live)
4、执行Young GC和Full GC应用程序的所有线程都是暂停的、停止工作,但Full GC时间比较长
5、JVM调优的核心思想:
a、尽量减少Full GC的次数,或者说延长Full GC间隔时间。不要频繁触发Full GC,因为执行Full GC的时间比较长。
b、尽量减少Young GC执行的时间
命令
那么上面我们基本了解了,堆内存的 GC 以及内存溢出的一些基本概念,那么在我们实际的工作过程中,内存泄漏的过程能不能知晓?溢出的结果要怎么查看呢?我们有某些命令可以知道
一、JMAP
比如说我们看一个 java 项目,首先肯定要知道这个进程的 pid :
# ps -ef | grep java | grep -v grep
root Mar16 ? :: /opt/jdk1./bin/java -Djava.util.logging.config.file=/opt/tomcat8/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djdk.tls.ephemeralDHKeySize= -Djava.protocol.handler.pkgs=org.apache.catalina.webresources -Dorg.apache.catalina.security.SecurityListener.UMASK= -Dignore.endorsed.dirs= -classpath /opt/tomcat8/bin/bootstrap.jar:/opt/tomcat8/bin/tomcat-juli.jar -Dcatalina.base=/opt/tomcat8 -Dcatalina.home=/opt/tomcat8 -Djava.io.tmpdir=/opt/tomcat8/temp org.apache.catalina.startup.Bootstrap start
root : pts/ :: /opt/jdk1./bin/java -Djava.util.logging.config.file=/opt/tomcat9/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djdk.tls.ephemeralDHKeySize= -Djava.protocol.handler.pkgs=org.apache.catalina.webresources -Dorg.apache.catalina.security.SecurityListener.UMASK= -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port= -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=47.107.183.88 -agentpath:/opt/jprofiler7/bin/linux-x64/libjprofilerti.so=port=,nowait -Dignore.endorsed.dirs= -classpath /opt/tomcat9/bin/bootstrap.jar:/opt/tomcat9/bin/tomcat-juli.jar -Dcatalina.base=/opt/tomcat9 -Dcatalina.home=/opt/tomcat9 -Djava.io.tmpdir=/opt/tomcat9/temp org.apache.catalina.startup.Bootstrap start
这个很显然,是我们启动的 toncat ,pid 显而易见是 20304
接下来,第一个命令,是用来看该 java 进程的:jmap pid号,可以看到大致的内存使用,但是这个并不是很详细,所以没什么用,下一个
# jmap
Attaching to process ID , please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.191-b12
0x0000000000400000 8K /opt/jdk1./bin/java
0x00007ffb008fb000 276K /opt/jdk1./jre/lib/amd64/libsunec.so
0x00007ffb0199a000 110K /opt/jdk1./jre/lib/amd64/libnet.so
0x00007ffb01bb1000 91K /opt/jdk1./jre/lib/amd64/libnio.so
0x00007ffb020c6000 50K /opt/jdk1./jre/lib/amd64/libmanagement.so
0x00007ffb12b40000 123K /opt/jdk1./jre/lib/amd64/libzip.so
0x00007ffb12d5c000 64K /lib64/libnss_files-2.12.so
0x00007ffb13278000 88K /lib64/libgcc_s-4.4.-.so.
0x00007ffb1348e000 887K /opt/jprofiler7/bin/linux-x64/libstdc++.so.
0x00007ffb1367e000 86K /lib64/libz.so.1.2.
0x00007ffb13894000 1808K /opt/jprofiler7/bin/linux-x64/libjprofilerti.so
0x00007ffb13bc2000 226K /opt/jdk1./jre/lib/amd64/libjava.so
0x00007ffb13df1000 64K /opt/jdk1./jre/lib/amd64/libverify.so
0x00007ffb18047000 139K /opt/jprofiler7/bin/linux-x64/libexpat.so.
0x00007ffb1816a000 43K /lib64/librt-2.12.so
0x00007ffb18372000 582K /lib64/libm-2.12.so
0x00007ffb185f6000 16623K /opt/jdk1./jre/lib/amd64/server/libjvm.so
0x00007ffb195da000 1879K /lib64/libc-2.12.so
0x00007ffb1996e000 19K /lib64/libdl-2.12.so
0x00007ffb19b72000 106K /opt/jdk1./lib/amd64/jli/libjli.so
0x00007ffb19d8a000 139K /lib64/libpthread-2.12.so
0x00007ffb19fa7000 155K /lib64/ld-2.12.so
jmap -heap pid号 ,查看堆内存的各区内存使用情况
# jmap -heap
Attaching to process ID , please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.191-b12 using thread-local object allocation.
Mark Sweep Compact GC Heap Configuration:
MinHeapFreeRatio =
MaxHeapFreeRatio =
MaxHeapSize = (.0MB)
NewSize = (.625MB)
MaxNewSize = (.3125MB)
OldSize = (.375MB)
NewRatio =
SurvivorRatio =
MetaspaceSize = (.796875MB)
CompressedClassSpaceSize = (.0MB)
MaxMetaspaceSize = MB
G1HeapRegionSize = (.0MB) Heap Usage:
New Generation (Eden + Survivor Space):
capacity = (.3125MB)
used = (.6611480712890625MB)
free = (.651351928710938MB)
23.9095384247449% used
Eden Space:
capacity = (.625MB)
used = (.9736480712890625MB)
free = (.651351928710938MB)
14.485490431479358% used
From Space:
capacity = (.6875MB)
used = (.6875MB)
free = (.0MB)
100.0% used
To Space:
capacity = (.6875MB)
used = (.0MB)
free = (.6875MB)
0.0% used
tenured generation:
capacity = (.89453125MB)
used = (.030616760253906MB)
free = (.863914489746094MB)
76.79886931687219% used interned Strings occupying bytes.
但是,这里我们只是里看到了,内存溢出的现象,老年代满了,但是具体的原因是啥呢?我们还没找到,继续往下走,找到占内存的方法
检测内存溢出的方法:
jmap -histo pid 号,内容太多,我们重定向到一个文本内去查看
# jmap -histo > .log
# vi .log
看的过程中,g可以跳到第一行,G可以直接到最后一行
或者使用:jmap -histo:live pid 号,更加准确,插看存活的对象,可以排除非存活对象,对我们判断的影响
可以看到一下内容,可以看到堆内存里面占用内存的类,和类的方法,输出在文件内
# sed -n '1,23p' .log num #instances #bytes class name
----------------------------------------------
: [C
: [I
: java.lang.String
: java.lang.reflect.Method
: [B
: java.util.HashMap$Node
: java.lang.Class
: [Ljava.lang.Object;
: com.mysql.jdbc.ConnectionPropertiesImpl$BooleanConnectionProperty
: java.util.Hashtable$Entry
: java.util.concurrent.ConcurrentHashMap$Node
: [Ljava.util.HashMap$Node;
: java.lang.ref.WeakReference
: [Ljava.lang.String;
: [Ljava.lang.Class;
: java.util.HashMap
: java.lang.ref.SoftReference
: java.util.LinkedHashMap$Entry
: javax.servlet.jsp.tagext.TagAttributeInfo
: [Ljava.util.Hashtable$Entry;
怎么看是哪个占内存了?这个是按大小排序的
那么这里的 [B ,[C ,这些是什么呢?B叫 bit C叫char ,I是int,L是long str 这些都是数据类型。这些东西并不知道是谁调用的,int , char这些谁知道哪里调用了?并不知晓。
很明显,这个 cn.test.TestBean ,cn.test 是包名,相当于路径,cn.test的里面的,TestBean类,调用了次,占内存147681616 bytes 。说明我们找打了类/类下的某的方法,调用的次数太多,占用了大量内存,并且这个方法一看就是开发写的,不是java自带的。这个类,可能就是导致内存溢出的原因。
那么我们怎么知道是不是这个类导致的呢?首先我们去看下这个类的内容:一般来讲,类都在 工程路径内的 WEB-INF/classes/ 内
# cd /usr/local/tomcat1/webapps/test1/WEB-INF/classes/
# cd /cn/test
# ls
.log heap.bin TestBean.class TestMain.class
由此可见,我们刚刚在 jmap -histo pid 内,占内存最大的类就是 cn.tset.TsetBean 的class ,进去看一下:

显示为乱码,是因为没下反编译工具,我们可以直接查看 init1.jsp 文件看看,切换到工程路径的 test1 里面:
# cd /usr/local/tomcat1/webapps/test1
# ls
catalina.policy catalina.properties context.xml init1.jsp init2.jsp META-INF server.xml test.jsp tomcat-users.xml WEB-INF web.xml
# vi init1.jsp <%@ page language="java" import="cn.test.*" pageEncoding="ISO-8859-1"%> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> <head> <title>init</title> </head> <body><% for(int i=;i<;i++){ TestBean b = new TestBean(); TestMain.list.add(b); } %> SIZE:<%=TestMain.list.size()%><br/> counter:<%=TestMain.counter++%> </body> </html>
我们可以看到 body 里面,调用了 1W 次,TestBean b = new TsetBean(); 就是把方法实例化,也就是循环实例化了 1W 个TestBean b 对象,并且把它放进了 一个 叫做 TestMain 的 list 里面,扔进了一个数组里面
然后循环体外面,看到SIZE:和 counter : 就是我们在网页上看到的 。list在 java 里面很特殊,GC 是GC不掉的,要认为 的将其置 为 null :TestMain.list = null; 正常来讲, java 里面的方法,不再调度用它,引用会自动-1 ,但是数组不会这样,引用一直存在。所以每调用一次,对象多1W 次引用。。。内存里面放的全部是 TestBean b 对象不释放,老年代被占的越来越多。。。所以就内存溢出了
。list在 java 里面很特殊,GC 是GC不掉的,要认为 的将其置 为 null :TestMain.list = null; 正常来讲, java 里面的方法,不再调度用它,引用会自动-1 ,但是数组不会这样,引用一直存在。所以每调用一次,对象多1W 次引用。。。内存里面放的全部是 TestBean b 对象不释放,老年代被占的越来越多。。。所以就内存溢出了
那我们不懂 java 怎么知道,哪些类是开发写的???看包名,我们这里是 cn.test 里面,非java自带的,肯定就是开发写的,而且一般来讲是有命名的规则的,比如会加 公司名.部门.项目名 等
面试吹:
那么以后出去吹,我定位了一个内存溢出的问题:
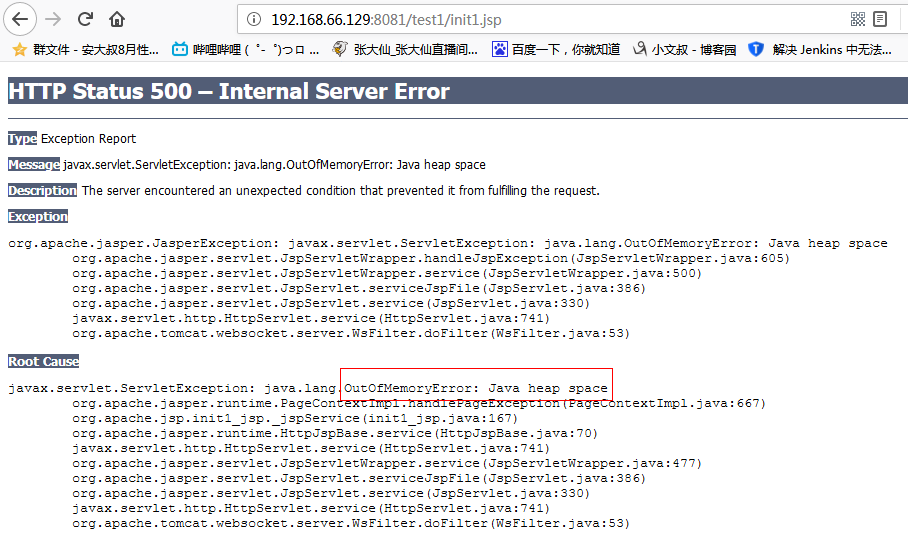
怎么发现的?压测过程中发现了一个问题:out of memory : heap space 。说明内存溢出了,查看代码日志,出现了 out of memory :heap space 。
那怎么分析的?怎么找具体原因的? jmap -histo pid 看占内存代大小前20内,有没有开发写的类,看是不是引用完成之后,没有及时释放。就这么分析的呀
那怎么解决的呀?引用完成之后,我把它置为空了
那为啥那个类引用完成之后没有自动置为空呢?因为开发把它写进了一个 list 里面去了
java 里面的方法不是会把引用给自动回收掉么?因为开发把这个对象放进了一个 list 内,list 内的引用不会自动给清空,所以引用一直在的话,一直存活不会被垃圾回收给回收掉
jmap -dump 文件名 pid号,可以输入 jmap ,里面有例子可以查看
# jmap …… -dump:<dump-options> to dump java heap in hprof binary format dump-options: live dump only live objects; if not specified, all objects in the heap are dumped. format=b binary format file=<file> dump heap to <file>Example: jmap -dump:live,format=b,file=heap.bin <pid> ##live是存活,formate=b是二进制文件,file 的名字为 heap.bin ,后面跟pid号(tomcat的)
接下来我们试试:
# jmap -dump:live,format=b,file=heap.bin Dumping heap to /opt/heap.bin ...
Heap dump file create
这里,dump 的时间可能会比较长,稍微等等就行
dump 完成之后,可以用jhat进行解析,也可以用我们的工具进行解析,这里先介绍 jhat 解析的方式
jhat
先把刚刚dump下的文件,heap.bin ,用 jhat进行解析:
# jhat heap.bin Reading from heap.bin... Dump file created Sat Dec :: CST Exception in thread "main" java.lang.OutOfMemoryError: Java heap space at java.util.Hashtable.rehash(Hashtable.java:) at java.util.Hashtable.addEntry(Hashtable.java:) at java.util.Hashtable.put(Hashtable.java:) at com.sun.tools.hat.internal.model.Snapshot.addHeapObject(Snapshot.java:) at com.sun.tools.hat.internal.parser.HprofReader.readInstance(HprofReader.java:) at com.sun.tools.hat.internal.parser.HprofReader.readHeapDump(HprofReader.java:) at com.sun.tools.hat.internal.parser.HprofReader.read(HprofReader.java:) at com.sun.tools.hat.internal.parser.Reader.readFile(Reader.java:) at com.sun.tools.hat.Main.main(Main.java:)
这里是因为有一个错误产生,因为我们的堆内存不够用了,jhat 解析不成功。解决方案:
jhat -J-mx512m heap.bin (512改成更大的,这是给jhat指定更大的内存),例如:
jhat -J-mx800m heap.bin Reading from heap.bin... Dump file created Sat Dec :: CST Snapshot read, resolving... Resolving objects... Chasing references, expect dots........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................ Eliminating duplicate references........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................ Snapshot resolved. Started HTTP server on port
根据提示,我们可以在浏览器内,用7000 端口查看

这里我们拉到最下面:点击进去

可以看到,我们的创建实例数:跟我们在 jmap -hist pid号 里面看到的类似
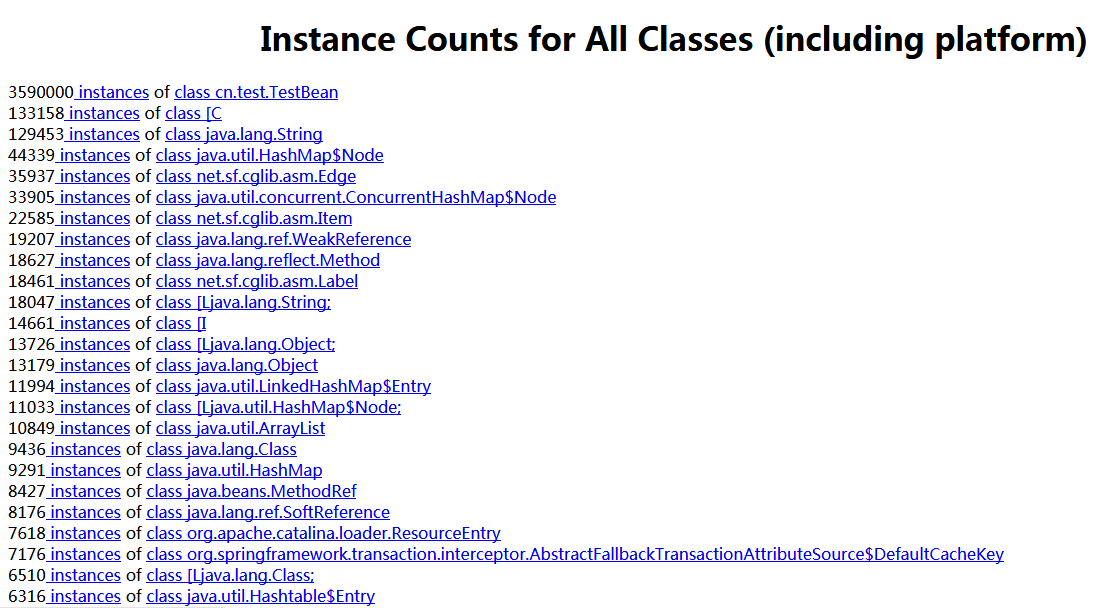
点击进去,可以看调用改类的父类,实在太多,难以分析,已经摒弃,注意:在xshell 内,ctrl+c,这个端口就会被关闭,也就访问不了了
但是这种方式分析起来太过于麻烦,我们可以借用另一个工具:mat,首先要把,heap.bin 下载到本地,用mat打开
mat
1、先用 mat 把heap.bin文件打开

2、打开后进行分析,提示要不要生成报告,点 finish 就好了,打开后如图:

对大对象进行分析,点击 detail :

结果:父类是 java.lang.Object,下一层的 elementData 是一个数组 ArrayList 数组引用,里面是 java.lang.TestMain 里面的方法
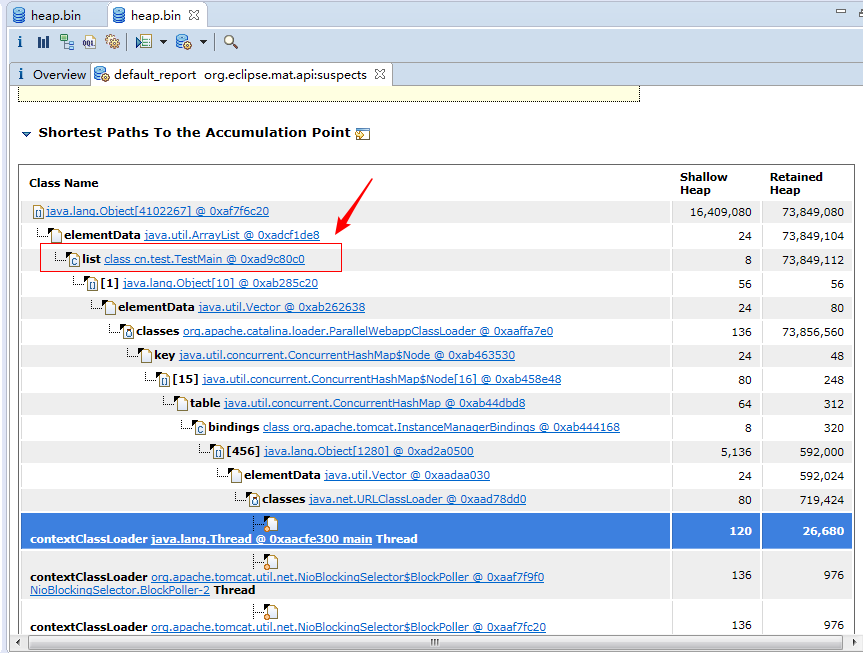
小结:看 default 报告即可,找到开发写的类以及方法
jstat——看堆内存的使用比例以及gc的次数&&时间
jstat -gcutil pid号
##每 ms 打印一次,打印10次,如果后面不跟打印次数则一直打印
# jstat -gcutil
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 45.67 65.73 98.02 - 2.286 0.883 3.170
0.00 0.00 45.67 65.73 98.02 - 2.286 0.883 3.170
0.00 0.00 45.67 65.73 98.02 - 2.286 0.883 3.170
0.00 0.00 45.67 65.73 98.02 - 2.286 0.883 3.170
0.00 0.00 45.67 65.73 98.02 - 2.286 0.883 3.170
0.00 0.00 45.90 65.73 98.02 - 2.286 0.883 3.170
0.00 0.00 45.90 65.73 98.02 - 2.286 0.883 3.170
0.00 0.00 45.90 65.73 98.02 - 2.286 0.883 3.170
0.00 0.00 45.90 65.73 98.02 - 2.286 0.883 3.170
0.00 0.00 45.90 65.73 98.02 - 2.286 0.883 3.170
存活区1 存活区2 Eden 老年代 持久代 young GC次数 younggc的耗时时间 full gc 的总次数 fullgc的总时间 younggc和fullgc的总时间
以上都是比例,并不是大小
E:eden
O:老年代
YGC:young gc 的次数
YGCT:young gc 的总的耗时时间
FGC:full gc 的次数
FGCT:full gc 的总耗时
GCT:full gc加 young gc的时间
这里没有改变是因为,我们并没有在压测,压测后,没有young GC了,但是 Full GC一直在涨:

所以页面一定崩溃了:
此时,我们看一下,CPU的使用率,可以看到,排在第一位的是我们的 2417 ,也就是tomcat1的那个进程
root 385m 92m S 73.6 9.2 :43.84 java root R 1.6 0.1 :00.26 top mysql 132m S 0.3 0.1 :01.53 mysqld
user cpu使用高,定位到进程,进程再去定位线程,找到线程再去看线程里面调用的方法
接下来定位到消耗 CPU 高线程:
# top -H -p top - :: up :, users, load average: 0.95, 0.55, 0.22 Tasks: total, running, sleeping, stopped, zombie Cpu(s): 3.5%us, 0.4%sy, 0.0%ni, 93.7%id, 2.3%wa, 0.0%hi, 0.1%si, 0.0%st Mem: 1030684k total, 593832k used, 436852k free, 6004k buffers Swap: 2064376k total, 136844k used, 1927532k free, 173532k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND root 385m 306m R 81.6 30.4 :26.70 java root 385m 306m S 0.0 30.4 :00.00 java root 385m 306m S 0.0 30.4 :09.83 java root 385m 306m S 0.0 30.4 :00.02 java
我们定位到了这个 ,超高 cpu 的ppid
接下来,我们要根据这个pid 号以及 ppid 号,去看栈的信息
栈
jstack
这里看的是整个进程下,所有线程的方法栈信息
#jstack pid号 重定向到 .log查看 # jstack > .log
可以看到类似的线程信息:
"http-nio-8081-Acceptor-0" # daemon prio= os_prio= tid=0xa3d6f000 nid=0x9f2 runnable [0xa18fe000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.ServerSocketChannelImpl.accept0(Native Method)
at sun.nio.ch.ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:)
at sun.nio.ch.ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:)
- locked <0xaaf53600> (a java.lang.Object)
at org.apache.tomcat.util.net.NioEndpoint.serverSocketAccept(NioEndpoint.java:)
at org.apache.tomcat.util.net.NioEndpoint.serverSocketAccept(NioEndpoint.java:)
at org.apache.tomcat.util.net.Acceptor.run(Acceptor.java:)
at java.lang.Thread.run(Thread.java:)
说明没有出错,如果执行不出来,一般是,压测没有停止,停了等一会儿应该就ok
线程堆栈的信息都包含:
1、线程名字,id,线程的数量等。如上边线程信息内的:“http-nio-8081-Acceptor-0”
2、线程的运行状态,锁的状态(锁被哪个线程持有,哪个线程在等待锁等)
3、调用堆栈(即函数的调用层次关系)调用堆栈包含完整的类名,所执行的方法,源代码的行数。
线程栈解读
从main线程看,线程堆栈里面的最直观的信息是当前线程的调用上下文,即从哪个函数调用到哪个函数(从下往上看),正执行到哪一类的哪一行,借助这些信息,我们就对当前系统正在做什么一目了然。

"http-nio-8081-Acceptor-0" #33 daemon prio=5 os_prio=0 tid=0xa3d6f000 nid=0x9f2 runnable [0xa18fe000]
main就是线程名称:http-nio-8081-Acceptor-0
后面的daemon是指哪个用户起的
prio :线程优先级:prio=5
tid :线程id:tid=0xa3d6f000
nid:本地方法栈id:nid=0x9f2
runnable:线程状态
后面是线程的内存地址:[0xa18fe000]
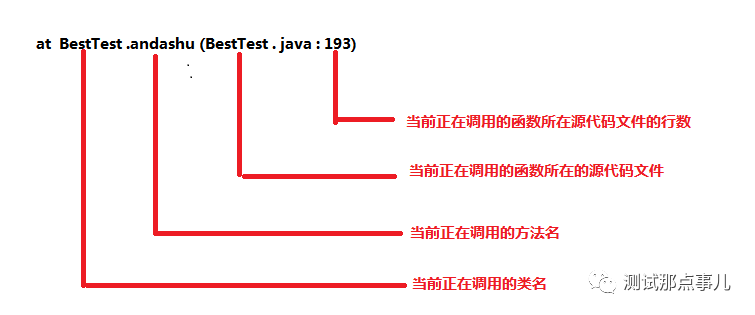
at sun.nio.ch.ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:422)
at XXX.XXX.XXX.xxx(xxxx.java:123)
在包.方法(源代码文件.行数)
线程死锁:一个线程要求去 lock 一个地址,但是这个地址正被另一个线程 locked 了
下面,去定位线程使用的方法,就是导致CPU高的问题:
我们上边看 CPU 高的线程是 2478 ,是10进制的,要换成 16 进制 ,才能知道 ,高CPU线程对应的方法是什么
# printf %x 9ae
用 9ae 去线程栈内查找: 或者,我们进行: jstack pid | grep ppid(ppid 是 十六进制的)
"VM Thread" os_prio= tid=0xb765d800 nid=0x9ae runnable
这里是虚拟机线程 "VM Thread" 导致的,java 有什么虚拟机线程?也就是 gc 线程。其实就是 gc 起的虚拟机线程
说明就是 VM Thread 导致的问题,其实是 GC 导致的,这里不知道为什么是显示这个,可以去调查下
这里,我们打比方,打比方耗CPU较高的线程的id 是下面这个导致的:0x9f2 导致的
"http-nio-8081-Acceptor-0" # daemon prio= os_prio= tid=0xa3d6f000 nid=0x9f2 runnable [0xa18fe000] java.lang.Thread.State: RUNNABLE at sun.nio.ch.ServerSocketChannelImpl.accept0(Native Method) at sun.nio.ch.ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:) at sun.nio.ch.ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:) - locked <0xaaf53600> (a java.lang.Object) at org.apache.tomcat.util.net.NioEndpoint.serverSocketAccept(NioEndpoint.java:) at org.apache.tomcat.util.net.NioEndpoint.serverSocketAccept(NioEndpoint.java:) at org.apache.tomcat.util.net.Acceptor.run(Acceptor.java:) at java.lang.Thread.run(Thread.java:)
我们分析那个?看我们能看懂的那几个,这里例子举得不好,init.jsp 和 jprofile 在其他的 at 里面是有的,基本就是这几个,实际上找到这个 线程,把它的全部方法给开发就得了
大概率是第一个 at 和 第一个 - 后面的at,就是上面的俩行黄色的
线程作用
因为线程栈是瞬时快照包含线程状态以及调用关系,所以借助堆栈信息可以帮助分析很多问题,比如线程死锁,锁争用,死循环,识别耗时操作等等。线程栈是瞬时记录,所以没有历史消息的回溯,一般我们都需要结合程序的日志进行跟踪,一般线程栈能分析如下性能问题:
1、系统无缘无故的cpu过高
2、系统挂起,无响应
3、系统运行越来越慢
4、性能瓶颈(如无法充分利用cpu等)
5、线程死锁,死循环等
6、由于线程数量太多导致的内存溢出(如无法创建线程等)
状态:
1、NEW
2、RUNNABLE
3、RUNNING
4、BLOCKED
5、WAITING
6、TIMED_WAITING
7、TERMINATED
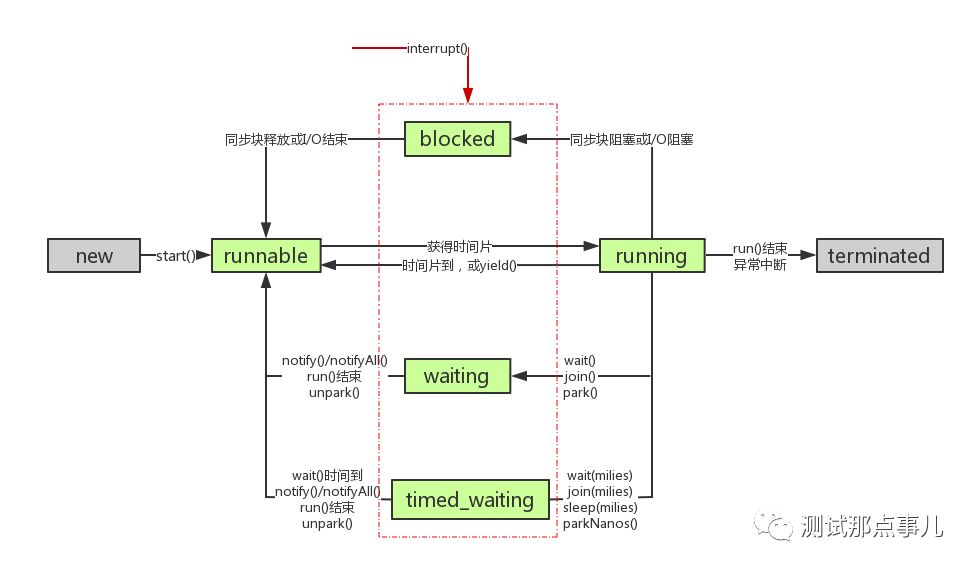
new,初始化之后,是 runnable 的状态,当拿到 CPU 时间片之后,就变成 running 的状态,CPU时间片完了之后,没有执行完,就变成 runnable 状态;
当在 running 后,还可以退出变成 terminated ,发生同步阻塞或者 I/O 异步阻塞,就会变成 blocked 状态,running 变成 waiting 是一直等待某个资源无时间限制,变成 timed_waiting 是有时间限制的超过时间限制是不会等待的;
blocked 同步块释放或者io结束就会变成 runnable 状态
waitting 和 timed_waiting 和 blocked 都只会切换成 runnable ,waiting 要得到资源才能到 runnable ,timed_waiting 等待到资源或者超时会变成 runnable
线程大量 runable 和 runnable 是没多大问题的;大量的 blocked ,是不行的 ,tomcat 开的线程有限制,都锁了其他的还玩个舌头;大量的 waiting 和 time_waiting 是有问题的
JVM(上)的更多相关文章
- 转 PHP在JVM上的实现JPHP
前两天还在想,像Quercus只封装了PHP在Java上的Web接口,有没有实现了完整的JVM语言特性的东东,这不,来了. JPHP是一个面向Java虚拟机的PHP实现,支持PHP(5.3+)的很多特 ...
- 为什么很多语言选择在JVM上实现
非常经济地实现跨平台.你的语言编译器后端只需要输出 JVM 字节码就可以.跨平台需要极大的工作量,举个例子,只是独立开发生成本地代码,就需要花费大量精力去针对不同平台和处理器进行优化(比如 Firef ...
- JVM上的响应式流 — Reactor简介
强烈建议先阅读下JVM平台上的响应式流(Reactive Streams)规范,如果没读过的话. 官方文档:https://projectreactor.io/. 响应式编程 作为响应式编程方向上的第 ...
- CentOS7 Tomcat 启动过程很慢,JVM上的随机数与熵池策略
1. CentOS7 Tomcat 启动过程很慢 在centos启动官方的tomcat时,启动过程很慢,需要几分钟,经过查看日志,发现耗时在这里:是session引起的随机数问题导致的: <co ...
- ZooKeeper服务器是用Java创建的,它在JVM上运行。
ZooKeeper服务器是用Java创建的,它在JVM上运行. 创建配置文件 使用命令 vi conf/zoo.cfg 和所有以下参数设置为起点,打开名为 conf/zoo.cfg 的配置文件. $ ...
- 牛逼了,教你用九种语言在JVM上输出HelloWorld
我们在<深入分析Java的编译原理>中提到过,为了让Java语言具有良好的跨平台能力,Java独具匠心的提供了一种可以在所有平台上都能使用的一种中间代码——字节码(ByteCode). 有 ...
- JVM上的随机数与熵池策略
在apache-tomcat官方文档:如何让tomcat启动更快里面提到了一些启动时的优化项,其中一项是关于随机数生成时,采用的“熵源”(entropy source)的策略. 他提到tomcat7的 ...
- 深入理解 JVM(上)
菜鸟拙见,望请纠正(首先:推荐一本书[链接:https://pan.baidu.com/s/15I062n5LPYtRmueAAUFuFA 密码:kyo1]) 一:JVM体系概述 1:JVM是运行在操 ...
- JVM上的下一个Java——Scala
Scala是一种针对 JVM 将函数和面向对象技术组合在一起的编程语言.Scala编程语言近来抓住了很多开发者的眼球.它看起来像是一种纯粹的面向对象编程语言,而又无缝地结合了命令式和函数式的编程风格. ...
- Springboot程序启动慢及JVM上的随机数与熵池策略
问题描述 线上环境中很容易出现一个java应用启动非常耗时的情况,在日志中可以发现是session引起的随机数问题导致的 o.a.c.util.SessionIdGeneratorBase : Cre ...
随机推荐
- python-day67--MTV之Template
一.什么是模板? html+模板语法 二.模版包括在使用时会被值替换掉的 变量,和控制模版逻辑的 标签. 三.嵌入变量的三种方式: def current_time(req): # ========= ...
- 170301、使用Spring AOP实现MySQL数据库读写分离案例分析
使用Spring AOP实现MySQL数据库读写分离案例分析 原创 2016-12-29 徐刘根 Java后端技术 一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案 ...
- UVA-10127 Ones (数论)
题目大意:给一个数n,找出一个各位全是1的最小的十进制数,使得n能整除这个数.只输出最小位数. 题目分析:纯粹是数论,暴力. 代码如下: # include<iostream> # inc ...
- ASP.NET简介
1.什么是ASP.NET? ASP.NET是一套免费的网络架构,是为了构建一个伟大的或者说非常不错的网站或网络应用,并同时使用了一些前端技术,比如说HTML,CSS和JavaScript ASP.NE ...
- 有名管道mkfifo
int mkfifo(const char *pathname, mode_t mode); int mknod(const char *pathname, mode_t mode, dev_t de ...
- memory prefix vice ,with out 1
1● vice 副的 2● with 向后,相反
- 给构造函数(constructor)创建对象(object)
(来源http://www.cnblogs.com/dongjc/p/5179561.html) javascript是一种“基于prototype的面向对象语言“,与java有非常大的区别,无法通过 ...
- Android如何打印std::cout/printf(重定向stdout)
Android应用调试时没有stdout和stderr的输出,网上看到的解释都是下面这个样子: ################################################# An ...
- sgu101 欧拉路径 难度:1
101. Domino time limit per test: 0.25 sec. memory limit per test: 4096 KB Dominoes – game played wit ...
- 返回书签 GotoBookmark
property Bookmark: TBookmark read GetBookmark write GotoBookmark; 直接给Bookmark属性赋值,还是 调用数据集GotoBookma ...