python3 IEDriver抓取时报数据
最近做了测试抓取XX时报的数据,由于需要事先登录,并且有验证码,关于验证码解决有两个途径:一是利用打码平台,其原理是把验证码的图片上传发送给打码平台,
然后返回其验证码。二就是自己研究验证码技术问题。这个有时间再研究。
目前主要是测试从XX时报抓取数据,目前暂时用了笨方法,利用人工介入,输入验证码。
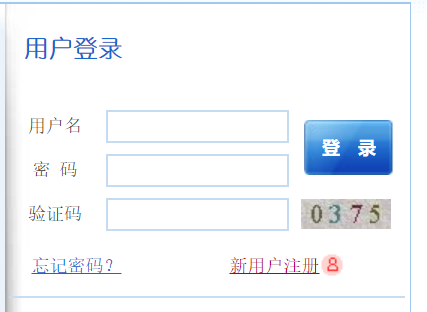
登录界面:
具体代码如下:
#coding=utf-8
import os
import re
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.common.action_chains import ActionChains
import collections
import mongoDbBase
import numpy
import imagehash
from PIL import Image,ImageFile
import datetime
class finalNews_IE:
def __init__(self,strdate,logonUrl,firstUrl,keyword_list,exportPath,codedir):
self.iniDriver()
self.db = mongoDbBase.mongoDbBase()
self.date = strdate
self.firstUrl = firstUrl
self.logonUrl = logonUrl
self.keyword_list = keyword_list
self.exportPath = exportPath
self.codedir = codedir
self.hash_code_dict ={} def iniDriver(self):
# 通过配置文件获取IEDriverServer.exe路径
IEDriverServer = "C:\Program Files\Internet Explorer\IEDriverServer.exe"
os.environ["webdriver.ie.driver"] = IEDriverServer
self.driver = webdriver.Ie(IEDriverServer) def WriteData(self, message, fileName):
fileName = os.path.join(os.getcwd(), self.exportPath + '/' + fileName)
with open(fileName, 'a') as f:
f.write(message) # 获取图片文件的hash值
def get_ImageHash(self,imagefile):
hash = None
if os.path.exists(imagefile):
with open(imagefile, 'rb') as fp:
hash = imagehash.average_hash(Image.open(fp))
return hash # 点降噪
def clearNoise(self, imageFile, x=0, y=0):
if os.path.exists(imageFile):
image = Image.open(imageFile)
image = image.convert('L')
image = numpy.asarray(image)
image = (image > 135) * 255
image = Image.fromarray(image).convert('RGB')
# save_name = "D:\work\python36_crawl\Veriycode\mode_5590.png"
# image.save(save_name)
image.save(imageFile)
return image #切割验证码
# rownum:切割行数;colnum:切割列数;dstpath:图片文件路径;img_name:要切割的图片文件
def splitimage(self, imagePath,imageFile,rownum=1, colnum=4):
img = Image.open(imageFile)
w, h = img.size
if rownum <= h and colnum <= w:
print('Original image info: %sx%s, %s, %s' % (w, h, img.format, img.mode))
print('开始处理图片切割, 请稍候...') s = os.path.split(imageFile)
if imagePath == '':
dstpath = s[0]
fn = s[1].split('.')
basename = fn[0]
ext = fn[-1] num = 1
rowheight = h // rownum
colwidth = w // colnum
file_list =[]
for r in range(rownum):
index = 0
for c in range(colnum):
# (left, upper, right, lower)
# box = (c * colwidth, r * rowheight, (c + 1) * colwidth, (r + 1) * rowheight)
if index < 1:
colwid = colwidth + 6
elif index < 2:
colwid = colwidth + 1
elif index < 3:
colwid = colwidth box = (c * colwid, r * rowheight, (c + 1) * colwid, (r + 1) * rowheight)
newfile = os.path.join(imagePath, basename + '_' + str(num) + '.' + ext)
file_list.append(newfile)
img.crop(box).save(newfile, ext)
num = num + 1
index += 1
return file_list def compare_image_with_hash(self, image_hash1,image_hash2, max_dif=5):
"""
max_dif: 允许最大hash差值, 越小越精确,最小为0
推荐使用
"""
dif = image_hash1 - image_hash2
# print(dif)
if dif < 0:
dif = -dif
if dif <= max_dif:
return True
else:
return False # 截取验证码图片
def savePicture(self):
# self.driver.get(self.logonUrl)
# self.driver.maximize_window()
# time.sleep(2) self.driver.save_screenshot(self.codedir +"\Temp.png")
checkcode = self.driver.find_element_by_id("checkcode")
location = checkcode.location # 获取验证码x,y轴坐标
size = checkcode.size # 获取验证码的长宽
rangle = (int(location['x']), int(location['y']), int(location['x'] + size['width']),
int(location['y'] + size['height'])) # 写成我们需要截取的位置坐标
i = Image.open(self.codedir +"\Temp.png") # 打开截图
result = i.crop(rangle) # 使用Image的crop函数,从截图中再次截取我们需要的区域
filename = datetime.datetime.now().strftime("%M%S")
filename =self.codedir +"\Temp_code.png"
result.save(filename)
self.clearNoise(filename)
file_list = self.splitimage(self.codedir,filename)
time.sleep(3)
verycode =''
for f in file_list:
imageHash = self.get_ImageHash(f)
if imageHash:
for h, code in self.hash_code_dict.items():
flag = self.compare_image_with_hash(imageHash, h, 0)
if flag:
# print(code)
verycode += code
break print(verycode)
return verycode
# print(verycode)
# self.driver.close() def getVerycode(self, txtFile="verycode.txt"):
f = open(txtFile, 'r')
result = f.read()
return result def longon(self):
for f in range(0,10):
for l in range(1,5):
file = os.path.join(self.codedir, "codeLibrary\code" + str(f) + '_'+str(l) + ".png")
# print(file)
hash = self.get_ImageHash(file)
self.hash_code_dict[hash]= str(f) flag = True
try:
self.driver.get(self.logonUrl)
self.driver.maximize_window()
time.sleep(2)
verycode = self.savePicture()
if len(verycode)==4:
accname = self.driver.find_element_by_id("username")
# accname = self.driver.find_element_by_id("//input[@id='username']")
accname.send_keys('ctrchina') accpwd = self.driver.find_element_by_id("password")
# accpwd.send_keys('123456')
# code = self.getVerycode()
checkcode = self.driver.find_element_by_name("checkcode")
checkcode.send_keys(verycode)
submit = self.driver.find_element_by_name("button")
submit.click()
else:
flag = False
except Exception as e1:
message = str(e1.args)
flag = False
return flag # 获取版面链接及关键字
def saveUrls(self):
error = ''
while True:
flag = self.longon()
time.sleep(2)
if flag:
try:
codefault = self.driver.find_element_by_xpath("//table[@class='table_login']/tbody/tr/td/font")
if codefault:
continue
except Exception as e1:
pass
break
try:
time.sleep(2)
self.driver.get(self.firstUrl)
self.driver.maximize_window()
# urllb = "//div[@id='pageLink']/ul/div/div/a"
urllb = "//a[@id='pageLink']"
time.sleep(2)
elements = self.driver.find_elements_by_xpath(urllb)
url_layout_dict = collections.OrderedDict()
for element in elements:
layout = element.text
# print(layout)
if len(layout) == 0:
continue
# layout = txt[txt.find(":") + 1:]
link = element.get_attribute("href")
print(link)
if link not in url_layout_dict:
url_layout_dict[link] = layout
index = 0
for sub_url,layout in url_layout_dict.items():
if index==0:
sub_url=""
print(index)
self.getArticleLink(sub_url,layout)
index+=1
except Exception as e1:
print("saveUrlsException")
print("saveUrlsException:Exception" + str(e1.args)) def getArticleLink(self, url,layout):
error = ''
try:
if url:
self.driver.get(url)
self.driver.maximize_window()
time.sleep(2)
dt = datetime.datetime.now().strftime("%Y.%m.%d")
urllb = "//div[@id='titleList']/ul/li/a"
elements = self.driver.find_elements_by_xpath(urllb)
url_layout_dict = {}
for element in elements:
txt = element.text
txt = txt[txt.rfind(")") + 1:len(txt)]
if txt.find("无标题") > -1 or txt.find("公 告") > -1 or txt.find("FINANCIAL NEWS") > -1 or txt.find(dt) > -1:
continue
link = element.get_attribute("href")
print(link)
url_layout_dict[link] = layout
self.db.SavefinalUrl(url_layout_dict,self.date)
except Exception as e1:
print("getArticleLink:Exception")
print("getArticleLink:Exception" + str(e1.args))
error = e1.args def catchdata(self): rows = self.db.GetfinalUrl(self.date)
lst = []
for row in rows:
lst.append(row)
print("rowcount:"+str(len(lst)))
count =1
for row in lst:
url = row['url']
layout = row['layout']
try:
self.driver.get(url)
self.driver.maximize_window()
time.sleep(1)
title = "" # t1 = doc("div[class='text_c']")
element = self.driver.find_element_by_class_name("text_c")
title = element.find_element_by_css_selector("h3").text
st = element.find_element_by_css_selector("h1").text
if st:
title += "\n" + st
st = element.find_element_by_css_selector("h2").text
if st:
title += "\n" + st st = element.find_element_by_css_selector("h4").text
if st:
if st.find("记者") == -1:
title += "\n" + st
# else:
# author = st.replace("记者","").replace("本报","").strip()
elements = self.driver.find_elements_by_xpath("//div[@id='ozoom']/p") content = "" key = ""
index = 0
author = ''
for element in elements:
txt = element.text.strip().replace("\n", "")
content += txt
if index == 0:
if txt.find("记者") > 0 and txt.find("报道") > 0:
author = txt[txt.find("记者") + 2:txt.find("报道")]
elif txt.find("记者") > 0 and txt.find("报道") == -1:
author = txt[txt.find("记者") + 2:len(txt)]
elif txt.find("记者") == -1 and txt.find("报道") == -1:
author = txt.strip()
index += 1 for k in self.keyword_list:
if content.find(k)>-1 or title.find(k)>-1:
key+=k+","
if key:
key = key[0:len(key)-1]
author = author.replace("记者", "").strip()
if len(author)>6:
author = ""
print(count)
print(layout)
print(url)
print(title)
print(author)
count+=1
# print(content)
self.db.updatefinalUrl(url)
self.db.SavefinalData(self.date,layout,url,title,author,key,content)
except Exception as e1:
error = e1.args
self.driver.close() def export(self):
rows = self.db.GetfinalData(self.date)
lst = []
for dataRow1 in rows:
lst.append(dataRow1)
count =1
# dt = datetime.datetime.now().strftime("%Y-%m-%d")
fileName = '金融时报_' + self.date + '.csv'
header = "发表日期,关键字,作者,全文字数,标题,版面,链接,正文"
if len(lst)>0:
self.WriteData(header, fileName) for dataRow in lst:
date = str(dataRow['date'])
layout = str(dataRow['layout'])
url = str(dataRow['url'])
title = str(dataRow['title']).replace(",",",").replace("\n"," ")
author = str(dataRow['author']).replace(",",",")
key = str(dataRow['key']).replace(",",",")
wordcount = str(dataRow['wordcount'])
content = str(dataRow['content']).replace(",",",").replace("\n"," ") # txt = "\n%s,%s,%s,%s,%s,%s" % (
# date, key, title, author, wordcount, url)
txt = "\n%s,%s,%s,%s,%s,%s,%s,%s" % (
date, key, author, wordcount, title,layout, url, content)
try:
self.WriteData(txt, fileName)
except Exception as e1:
print(str(e1))
print(count)
count += 1 #
# dt = datetime.datetime.now().strftime("%Y-%m-%d")
# ym = datetime.datetime.now().strftime("%Y-%m")
# day = datetime.datetime.now().strftime("%d")
#
# codepath='E:/python36_crawl/mediaInfo/verycode.txt'
#
# logonUrl="http://epaper.financialnews.com.cn/dnis/client/jrsb/index.jsp"
# # firsturl="http://epaper.financialnews.com.cn/jrsb/html/2018-09/18/node_2.htm"
# firsturl="http://epaper.financialnews.com.cn/jrsb/html/"+ym+"/"+day+"/node_2.htm"
# # print(firsturl)
# keyword_list ="银保监会,央行,中国银行,中行,中银".split(",")
# exportPath="E:/News"
# codedir='E:\python36_crawl\Veriycode'
# obj = finalNews_IE(dt,logonUrl,firsturl,keyword_list,exportPath,codedir)
# # obj.saveUrls()
# obj.catchdata()
# obj.export()
# # obj.savePicture()
采集时报2

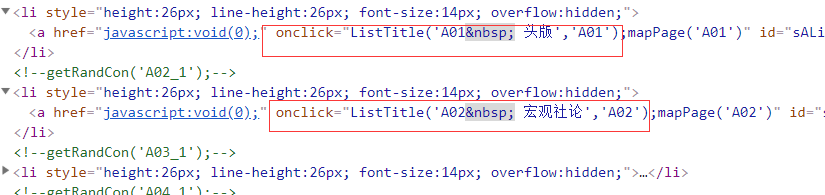
layoutElement.get_attribute("onclick")
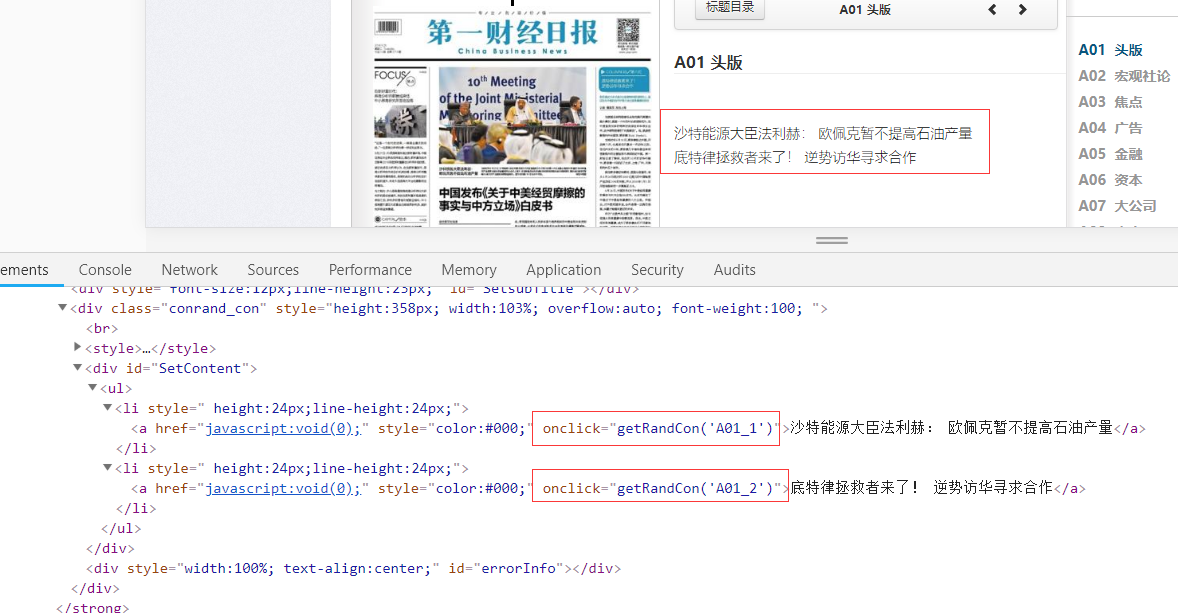
layoutLink = layoutElement.get_attribute("onclick")
#coding=utf-8
import os
import re
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.common.action_chains import ActionChains
import collections
import mongoDbBase
import datetime
import numpy
from PIL import Image
import RClient
class firstfinal:
def __init__(self, strdate, firstUrl, keyword_list, exportPath,dirpath): self.db = mongoDbBase.mongoDbBase()
self.date = strdate
self.firstUrl = firstUrl
self.keyword_list = keyword_list
self.exportPath = exportPath
self.dirpath = dirpath
self.rclient = RClient.RClient() def iniDriver(self):
# 通过配置文件获取IEDriverServer.exe路径
IEDriverServer = "C:\Program Files\internet explorer\IEDriverServer.exe"
os.environ["webdriver.ie.driver"] = IEDriverServer
self.driver = webdriver.Ie(IEDriverServer) def WriteData(self, message, fileName):
fileName = os.path.join(os.getcwd(), self.exportPath + '/' + fileName)
with open(fileName, 'a') as f:
f.write(message) def getVerycode(self, txtFile="verycode.txt"):
f = open(txtFile, 'r')
result = f.read()
return result
# 点降噪 def clearNoise(self, imageFile, x=0, y=0):
if os.path.exists(imageFile):
image = Image.open(imageFile)
image = image.convert('L')
image = numpy.asarray(image)
image = (image > 135) * 255
image = Image.fromarray(image).convert('RGB')
# save_name = "D:\work\python36_crawl\Veriycode\mode_5590.png"
# image.save(save_name)
image.save(imageFile)
return image
def savePicture(self):
# self.iniDriver()
# self.driver.get(self.firstUrl)
# self.driver.maximize_window() logon = self.driver.find_element_by_xpath("//div[@class='topMenu']/div[2]/a") # 索引从1开始
# href = logon.get_attribute("href")
# self.driver.execute_script(href)
logon.click()
# self.driver.maximize_window()
time.sleep(2)
checkcode = self.driver.find_element_by_id("Verify")
temppng = "E:\python36_crawl\Veriycode\Temp.png" self.driver.save_screenshot("E:\python36_crawl\Veriycode\Temp.png")
location = checkcode.location # 获取验证码x,y轴坐标
size = checkcode.size # 获取验证码的长宽
rangle = (int(location['x']), int(location['y']), int(location['x'] + size['width']),
int(location['y'] + size['height'])) # 写成我们需要截取的位置坐标
# i = Image.open("D:\work\python36_crawl\Veriycode\code\Temp.png") # 打开截图
i = Image.open(temppng)
result = i.crop(rangle) # 使用Image的crop函数,从截图中再次截取我们需要的区域
# imagefile = datetime.datetime.now().strftime("%Y%m%d%H%M%S")+".png"
# imagefile = os.path.join("D:\work\python36_crawl\Veriycode\code",imagefile)
result.save(temppng)
# self.driver.close()
# time.sleep(2)
return temppng def longon(self): self.iniDriver()
self.driver.get(self.firstUrl)
self.driver.maximize_window() logon = self.driver.find_element_by_xpath("//div[@class='topMenu']/div[2]/a")#索引从1开始
# href = logon.get_attribute("href")
# self.driver.execute_script(href)
logon.click()
self.driver.maximize_window()
time.sleep(2)
# if os.path.exists(self.codepath):
# os.system(self.codepath) # code = self.getVerycode()
accname = self.driver.find_element_by_name("username")
# accname = self.driver.find_element_by_id("//input[@id='username']")
accname.send_keys('ctrchina') # time.sleep(15)
accpwd = self.driver.find_element_by_name("password")
# 在服务器上浏览器记录密码了,就不需要设置了
accpwd.send_keys('') checkcode = self.driver.find_element_by_name("code")
temppng = self.savePicture()
code = self.rclient.test(temppng)
checkcode.send_keys(code) submit = self.driver.find_element_by_xpath("//div[@class='UserFrom']/div[8]/button")
submit.click() time.sleep(4)
# self.driver.refresh() # 获取版面链接及关键字 def catchData(self):
flag = True
try: layoutlb = "//ul[@class='BNameList']/li/a"
artclelb = "//div[@id='SetContent']/ul/li/a"
contentlb = "//div[@id='SetContent']/ul/li/a"
layoutElements = self.driver.find_elements_by_xpath(layoutlb)
layoutCount = len(layoutElements)
layoutIndex = 0
layout = ''
# 版面循环
print("layoutCount="+str(layoutCount))
while layoutIndex<layoutCount:
if layoutIndex >0:
self.driver.get(self.firstUrl)
self.driver.maximize_window()
layoutElements = self.driver.find_elements_by_xpath(layoutlb)
layoutElement = layoutElements[layoutIndex]
layoutLink = layoutElement.get_attribute("onclick")
self.driver.execute_script(layoutLink)
else:
layoutElement = layoutElements[layoutIndex]
layout = layoutElement.text
print(layout)
articleElements = self.driver.find_elements_by_xpath(artclelb)
articleCount = len(articleElements)
print("articleCount=" + str(articleCount))
articleIndex = 0
# 每个版面中文章列表循环
while articleIndex < articleCount:
if articleIndex > 0 :
self.driver.get(self.firstUrl)
self.driver.maximize_window()
layoutElements = self.driver.find_elements_by_xpath(layoutlb)
layoutElement = layoutElements[layoutIndex]
layoutLink = layoutElement.get_attribute("onclick")
self.driver.execute_script(layoutLink) elements = self.driver.find_elements_by_xpath(contentlb)
sublink = elements[articleIndex].get_attribute("onclick") #
title = elements[articleIndex].text
print(title)
self.driver.execute_script(sublink)
author = self.driver.find_element_by_id("Setauthor").text
subE = self.driver.find_elements_by_xpath("//div[@id='SetContent']/p")
content = ''
for se in subE:
content += se.text
key = ''
for k in self.keyword_list:
if content.find(k) > -1 or title.find(k) > -1:
key += k + ","
if key:
key = key[0:len(key) - 1]
print(author)
# print(content)
print(key)
print('\n')
articleIndex += 1
self.db.SaveFirsFinalData(self.date, layout, self.firstUrl, title, author, key, content)
layoutIndex+=1 except Exception as e1:
error = e1.args
flag = True def export(self):
try:
rows = self.db.GetFirsFinalData(self.date)
lst = []
for dataRow1 in rows:
lst.append(dataRow1)
count = 1
dt = datetime.datetime.now().strftime("%Y-%m-%d")
fileName = '第一财经日报_' + self.date + '.csv'
header = "发表日期,关键字,作者,全文字数,标题,版面,链接,正文"
if len(lst)>0:
self.WriteData(header, fileName)
# 所有的文章链接都是一样的
url = 'http://buy.yicai.com/read/index/id/5.html'
for dataRow in lst:
date = str(dataRow['date'])
layout = str(dataRow['layout'])
# url = str(dataRow['url']) title = str(dataRow['title']).replace(",", ",").replace("\n", " ")
author = str(dataRow['author']).replace(",", ",")
key = str(dataRow['key']).replace(",", ",")
wordcount = str(dataRow['wordcount'])
content = str(dataRow['content']).replace(",", ",").replace("\n", " ") # txt = "\n%s,%s,%s,%s,%s,%s" % (
# date, key, title, author, wordcount, url)
txt = "\n%s,%s,%s,%s,%s,%s,%s,%s" % (
date, key, author, wordcount, title, layout, url, content)
try:
self.WriteData(txt, fileName)
except Exception as e1:
print(str(e1))
print(count)
count += 1
except Exception as e1:
error = e1.args def test(self):
dt = datetime.datetime.now().strftime("%Y-%m-%d")
# dt="2018-10-08"
dirpath = "E:\python36_crawl"
# codepath= os.path.join(dirpath,"mediaInfo\Verycode.txt")
# codepath='E:/python36_crawl/mediaInfo/verycode.txt'
# file_list = os.listdir("D:\work\python36_crawl\Veriycode\code")
# firsturl="http://buy.yicai.com/read/index/id/5.html"
firsturl = 'http://buy.yicai.com/read/index/id/5.html'
keyword_list = "银保监会,央行,中国银行,中行,中银".split(",")
exportPath = "E:/News"
obj = firstfinal(dt, firsturl, keyword_list, exportPath, dirpath)
obj.longon()
obj.catchData()
obj.export() # dt = datetime.datetime.now().strftime("%Y-%m-%d")
# # dt="2018-10-08"
# dirpath ="E:\python36_crawl"
# # codepath= os.path.join(dirpath,"mediaInfo\Verycode.txt")
# # codepath='E:/python36_crawl/mediaInfo/verycode.txt'
# # file_list = os.listdir("D:\work\python36_crawl\Veriycode\code")
# # firsturl="http://buy.yicai.com/read/index/id/5.html"
# firsturl='http://buy.yicai.com/read/index/id/5.html'
# keyword_list = "银保监会,央行,中国银行,中行,中银".split(",")
# exportPath = "E:/News"
# obj = firstfinal(dt, firsturl, keyword_list, exportPath,dirpath)
# obj.longon()
# obj.catchData()
# # while True:
# # obj.savePicture()
# obj.export()
# coding=utf-8
import datetime
import finalNews_IE
import firstfinal
import Mail
import time
import os # def WriteData(message, fileName):
# fileName = os.path.join(os.getcwd(), 'mailflag.txt')
# with open(fileName) as f:
# f.write(message)
def run():
attachmentFileDir ="E:\\News"
mailflagfile = os.path.join(os.getcwd(), 'mailflag.txt')
while True:
date = datetime.datetime.now()
strtime = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(strtime + " 正常循环")
dt = datetime.datetime.now().strftime("%Y-%m-%d")
ym = datetime.datetime.now().strftime("%Y-%m")
day = datetime.datetime.now().strftime("%d") fileName = '金融时报_' + dt + '.csv'
fileName = os.path.join(attachmentFileDir, fileName) firstfileName = '第一财经日报_' + dt + '.csv'
firstfileName = os.path.join(attachmentFileDir, firstfileName) if not os.path.exists(fileName):
# 采集金融时报数据
logonUrl = "http://epaper.financialnews.com.cn/dnis/client/jrsb/index.jsp"
# firsturl="http://epaper.financialnews.com.cn/jrsb/html/2018-09/18/node_2.htm"
firsturl = "http://epaper.financialnews.com.cn/jrsb/html/" + ym + "/" + day + "/node_2.htm"
# print(firsturl)
keyword_list = "银保监会,央行,中国银行,中行,中银".split(",")
exportPath = "E:/News"
codedir = 'E:\python36_crawl\Veriycode'
obj = finalNews_IE.finalNews_IE(dt, logonUrl, firsturl, keyword_list, exportPath, codedir)
obj.saveUrls()
obj.catchdata()
obj.export()
if not os.path.exists(firstfileName):
# 采集第一采集日报数据
dirpath = "E:\python36_crawl"
firsturl = 'http://buy.yicai.com/read/index/id/5.html'
keyword_list = "银保监会,央行,中国银行,中行,中银".split(",")
exportPath = "E:/News"
obj = firstfinal.firstfinal(dt, firsturl, keyword_list, exportPath, dirpath)
obj.longon()
obj.catchData()
obj.export()
if date.strftime('%H:%M')=="08:50":
# 发送邮件
obj = Mail.Mail()
obj.test()
# WriteData(dt,mailflagfile)
time.sleep(100)
else:
time.sleep(10) run() # try: # dt = datetime.datetime.now().strftime("%Y-%m-%d")
# ym = datetime.datetime.now().strftime("%Y-%m")
# day = datetime.datetime.now().strftime("%d")
# # 采集金融时报数据
# logonUrl = "http://epaper.financialnews.com.cn/dnis/client/jrsb/index.jsp"
# # firsturl="http://epaper.financialnews.com.cn/jrsb/html/2018-09/18/node_2.htm"
# firsturl = "http://epaper.financialnews.com.cn/jrsb/html/" + ym + "/" + day + "/node_2.htm"
# # print(firsturl)
# keyword_list = "银保监会,央行,中国银行,中行,中银".split(",")
# exportPath = "E:/News"
# codedir = 'E:\python36_crawl\Veriycode'
# obj = finalNews_IE.finalNews_IE(dt, logonUrl, firsturl, keyword_list, exportPath, codedir)
# obj.saveUrls()
# obj.catchdata()
# obj.export()
#
# # 采集第一采集日报数据
# dirpath = "E:\python36_crawl"
# firsturl = 'http://buy.yicai.com/read/index/id/5.html'
# keyword_list = "银保监会,央行,中国银行,中行,中银".split(",")
# exportPath = "E:/News"
# obj = firstfinal.firstfinal(dt, firsturl, keyword_list, exportPath, dirpath)
# obj.longon()
# obj.catchData()
# obj.export() # 发送邮件
# obj = Mail.Mail()
# obj.test()
# except Exception as e1:
# print(str(e1))
python3 IEDriver抓取时报数据的更多相关文章
- Charles 如何抓取https数据包
Charles可以正常抓取http数据包,但是如果没有经过进一步设置的话,无法正常抓取https的数据包,通常会出现乱码.举个例子,如果没有做更多设置,Charles抓取https://www.bai ...
- 手把手教你用python打造网易公开课视频下载软件3-对抓取的数据进行处理
上篇讲到抓取的数据保存到rawhtml变量中,然后通过编码最终保存到html变量当中,那么html变量还会有什么问题吗?当然会有了,例如可能html变量中的保存的抓取的页面源代码可能有些标签没有关闭标 ...
- iOS开发——网络实用技术OC篇&网络爬虫-使用青花瓷抓取网络数据
网络爬虫-使用青花瓷抓取网络数据 由于最近在研究网络爬虫相关技术,刚好看到一篇的的搬了过来! 望谅解..... 写本文的契机主要是前段时间有次用青花瓷抓包有一步忘了,在网上查了半天也没找到写的完整的教 ...
- iOS开发——网络使用技术OC篇&网络爬虫-使用正则表达式抓取网络数据
网络爬虫-使用正则表达式抓取网络数据 关于网络数据抓取不仅仅在iOS开发中有,其他开发中也有,也叫网络爬虫,大致分为两种方式实现 1:正则表达 2:利用其他语言的工具包:java/Python 先来看 ...
- iOS—网络实用技术OC篇&网络爬虫-使用java语言抓取网络数据
网络爬虫-使用java语言抓取网络数据 前提:熟悉java语法(能看懂就行) 准备阶段:从网页中获取html代码 实战阶段:将对应的html代码使用java语言解析出来,最后保存到plist文件 上一 ...
- Node.js的学习--使用cheerio抓取网页数据
打算要写一个公开课网站,缺少数据,就决定去网易公开课去抓取一些数据. 前一阵子看过一段时间的Node.js,而且Node.js也比较适合做这个事情,就打算用Node.js去抓取数据. 关键是抓取到网页 ...
- C#抓取天气数据
使用C#写的一个抓取天气数据的小工具,使用正则匹配的方式实现,代码水平有限,供有需要的同学参考.压缩包中的两个sql语句是建表用的. http://files.cnblogs.com/files/yu ...
- 抓取网站数据不再是难事了,Fizzler(So Easy)全能搞定
首先从标题说起,为啥说抓取网站数据不再难(其实抓取网站数据有一定难度),SO EASY!!!使用Fizzler全搞定,我相信大多数人或公司应该都有抓取别人网站数据的经历,比如说我们博客园每次发表完文章 ...
- java抓取网页数据,登录之后抓取数据。
最近做了一个从网络上抓取数据的一个小程序.主要关于信贷方面,收集的一些黑名单网站,从该网站上抓取到自己系统中. 也找了一些资料,觉得没有一个很好的,全面的例子.因此在这里做个笔记提醒自己. 首先需要一 ...
随机推荐
- NOI经验谈
对于NOI来说,甚至比硬实力更加重要.我觉得一场考试这么几件事要做:看题,选题,分析,编码,调试,测试,骗分. 1.看题 拿到试卷以后的第一件事就是看题.看题不是看小说,要仔细阅读.当然,阅读也不宜过 ...
- 使用 IntraWeb (13) - 基本控件之 TIWLabel、TIWLink、TIWURL、TIWURLWindow
TIWLabel // TIWLink //内部链接 TIWURL //外部链接 TIWURLWindow //页内框架, 就是 <iframe></iframe> TIWLa ...
- HDU 4737 A Bit Fun (2013成都网络赛)
A Bit Fun Time Limit: 5000/2500 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total S ...
- hdoj-2066-一个人的旅行(迪杰斯特拉)
一个人的旅行 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Sub ...
- LPC-Link-II Rev C JTAG
- STM32F1XX devices vector table for EWARM toolchain.
;******************** (C) COPYRIGHT 2014 STMicroelectronics ******************* ;* File Name : start ...
- VC设置代理方法
参考文章: VC 设置代理 Setting and Retrieving Internet Options Change Internet Proxy settings http://suppor ...
- 解决SVN CONNOT VERIFY LOCK ON PATH NO MATCHING LOCK-TOKEN AVAILABLE
最近使用SVN,开发项目的时候,璞玉遇到一个问题.就是: connot verify lock on path no matching lock-token available connot v ...
- delphiredisclient开源GIT
delphiredisclient - Redis client for Delphi Delphi Redis Client版本2(此分支)与Delphi 10.1 Berlin兼容,更好.警告!如 ...
- 一键GHOST优盘版安装XP/win7系统
系统的安装方法有各种各样,一键GHOST优盘版也是其中的一种系统安装方法,也是俗称的U盘系统安装.下面豆豆来详细介绍下使用一键GHOST优盘版系统安装方法. 一.安装: 所谓"优盘" ...