记我的第一个python爬虫
捣鼓了两天,终于完成了一个小小的爬虫代码。现在才发现,曾经以为那么厉害的爬虫,在自己手里实现的时候,也不过如此。但是心里还是很高兴的。
其实一开始我是看的慕课上面的爬虫教学视屏,对着视屏的代码一行行的敲,两天的学习之后,终于看完了,代码也敲完了。视频中老师说,让我们来运行一下 看看效果,然后就看到爬取的结果一点点的出来了。我也对着自己的程序运行了一下,一堆看不懂的错误,上网查了之后一点点都改掉了。终于没有错误了。一运行,what???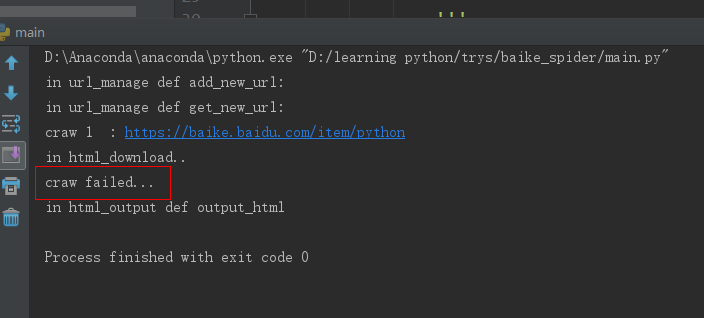
合着就爬取了一个?还是我给的根网址。这种情况最让人难受,语法错误有没有,也能运行,就是不安你说的做。不听话。
我发现他只执行到 download()函数就停止了,于是进入这个函数查看,是不是有错误,先看一下主函数,部分程序如下:
html_cont = self.downloader.download(new_url) #下载这个页面
new_urls,new_data = self.parser.parse(new_url,html_cont) #解析得到新的url和数据
self.urls.add_new_urls(new_urls)
self.output.collect_data(new_data) if count == 100: #只允许爬取1000个链接网页
break;
count = count+1 except:
print "craw failed..." self.output.output_html() #输出爬取信息
在download()函数里面是这个:
import urllib2
class HTML_download(object):
def download(self, url):
print 'in html_download..'
if url is None:
return None
response = urllib2.urlopen(url)
if response.getcode(url) != 200: #说明访问失败,一般返回200说明访问成功
return None
else:
return response.read()
他打印完 print 函数就停止了,跳到了异常处理里面,所以我认为是这个里面的问题。但是代码又都是按照视屏中敲的,能有什么问题呢?
好吧,既然问题找不到,那咱们就咱把这部分单独拿出来实现一下,看看行不行,于是有了下面的代码:
#!Anaconda/anaconda/python
#coding: utf-8 from bs4 import BeautifulSoup
import re
import urllib2
import urlparse URL = "https://baike.baidu.com/item/Python/407313?fr=aladdin"
count = 1 #计算共有多少爬取结果 response = urllib2.urlopen(URL) #打开一个网页 soup = BeautifulSoup(response,'html.parser',from_encoding='utf-8') #创建 beautifulsoup 对象 #<a target="_blank" href="/item/%E6%BA%90%E4%BB%A3%E7%A0%81/3969" data-lemmaid="3969">源代码</a> print "get all the URL...."
links = soup.find_all('a',href=re.compile(r"/item/")) for link in links:
count+= 1
new_url = link['href']
new_full_url = urlparse.urljoin(URL, new_url) #与完整网页链接结合,构成完整网页,不然输出的是不完整的网页链接
print link.name,new_full_url,link.get_text() print '共 %d 个爬取结果'%(count)
虽然很短,但是能爬取相关网页。
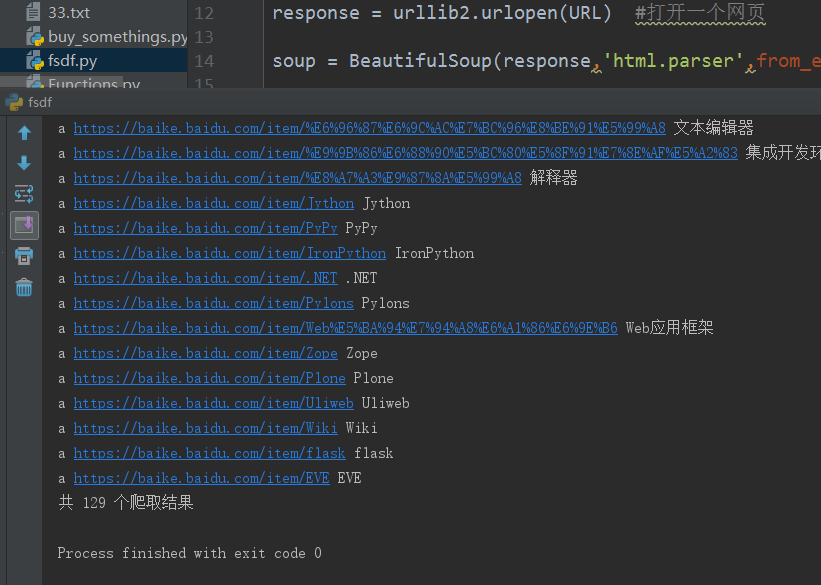
看来还是能爬取的,说明download()函数没有问题 ,那么问题就只能出现在下面几个函数里面了,还有可能就是可能是函数间的参数传递不对。导致程序异常停止。
后来发现,原来问题出在这里:
if response.getcode() != :
在getcode()函数里面并不需要参数,上面一个程序里面传入了参数url
自此,我的原爬虫程序就能执行了,虽然途中也遇到 了一些其他的问题,但是也都一一解决了。
记我的第一个python爬虫的更多相关文章
- 一个python爬虫小程序
起因 深夜忽然想下载一点电子书来扩充一下kindle,就想起来python学得太浅,什么“装饰器”啊.“多线程”啊都没有学到. 想到廖雪峰大神的python教程很经典.很著名.就想找找有木有pdf版的 ...
- 一个Python爬虫工程师学习养成记
大数据的时代,网络爬虫已经成为了获取数据的一个重要手段. 但要学习好爬虫并没有那么简单.首先知识点和方向实在是太多了,它关系到了计算机网络.编程基础.前端开发.后端开发.App 开发与逆向.网络安全. ...
- 我的第一个Python爬虫——谈心得
2019年3月27日,继开学到现在以来,开了软件工程和信息系统设计,想来想去也没什么好的题目,干脆就想弄一个实用点的,于是产生了做“学生服务系统”想法.相信各大高校应该都有本校APP或超级课程表之类的 ...
- 我的第一个 python 爬虫脚本
#!/usr/bin/env python# coding=utf-8import urllib2from bs4 import BeautifulSoup #res = urllib.urlopen ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- 第一个python爬虫程序
1.安装Python环境 官网https://www.python.org/下载与操作系统匹配的安装程序,安装并配置环境变量 2.IntelliJ Idea安装Python插件 我用的idea,在工具 ...
- 我的第一个python爬虫
我的第一个爬虫,哈哈,纯面向过程 实现目标: 1.抓取本地conf文件,其中的URL地址,然后抓取视频名称以及对应的下载URL 2.抓取URL会单独写在本地路径下,以便复制粘贴下载 废话补多少,代码实 ...
- 一个python爬虫工具类
写了一个爬虫工具类. # -*- coding: utf-8 -*- # @Time : 2018/8/7 16:29 # @Author : cxa # @File : utils.py # @So ...
- 我的第一个python爬虫程序
程序用来爬取糗事百科上的图片的,程序设有超时功能,具有异常处理能力 下面直接上源码: #-*-coding:utf-8-*- ''' Created on 2016年10月20日 @author: a ...
随机推荐
- 消息中间件的意义和应用场景 (activeMq)
消息中间件一般两个功能,解耦和异步处理,分别举个例子吧 解耦合:比如我们做一个微博产品中的好友系统,就很需要使用消息中间件当我们添加一个关注的时候, 涉及以下几个子系统 推荐系统,需要根据你关注的人给 ...
- linux sed在某些字符串的下一行插入内容?sed在下一行插入?
需求描述: 今天在配置nrpe的时候,使用到了在搜索到某些字符串之后,然后在字符串的下一行进行插入字符串 在此记录下如何实现. 即通过sed的a命令实现内容的追加. 操作过程: 1.查看原文件中的内容 ...
- linux环境中,如何使用tar来创建压缩包?解压缩?
需求说明: 今天需要将一个tomcat目录打成压缩包,使用zip感觉有点慢,所以就想用tar来试试,之前一直使用tar的解压缩命令, 今天试试tar的压缩命令 操作过程: 1.通过tar的zcf选项进 ...
- HTTPS原理,以及加密、解密的原理。
https://blog.csdn.net/Yang_yangyang/article/details/79702583 摘要:本文用图文的形式一步步还原HTTPS的设计过程,进而深入了解原理. A在 ...
- 01-虚拟软件vmware安装
什么是虚拟软件: 虚拟原件是一个可以使你在一台机器上同时运行二个或更多Windows.LINUX等系统.它可以模拟一个标准PC环境.这个环境和真实的计算机一样,都有芯片组.CPU.内存.显卡.声卡.网 ...
- ios开发之--使用AFN上传3.1.0上传视频,不走成功回调原因及解决方法
在测试接口的时候,发现接口称走走了,但是success的回调不走,检查了下代码,发现没有初始化下面两个方法: manage.responseSerializer = [AFHTTPResponseSe ...
- ios开发之--新手引导页图片适配方案
1,图片适配,最早以前是自己命名规范,例如@1x,@2x,@3x等,3套图基本上就够用了 2,在iPhone X之后,需要适配的图就多了,因为分辨率增多了,屏幕尺寸也增多了 3,尺寸 :640*960 ...
- springJdbc in 查询,Spring namedParameterJdbcTemplate in查询
springJdbc in 查询,Spring namedParameterJdbcTemplate in查询, SpringJdbc命名参数in查询,namedParameterJdbcTempla ...
- 【ArcGIS】ArcGIS Enterprise部署
单机部署 多层部署 高可用性部署
- springboot 集成elasticsearch5.4.3
官网上对elasticsearch 的集成用的是spring-data,而且,暂时不支持5.x的版本, 要是想集成5.x的版本,我们只能在pom.xml文件中进行修改,如图: <project ...