吴裕雄 python 数据处理(2)
import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(data.head())
a = data.stack()
print(a)
b = a.unstack()
print(b)

import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(data.head())
df = data.set_index("日期")
print(df.head())

import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
print(a.info())

import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
print(data.head())

import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = data["价格"].groupby([data["出发地"],data["目的地"]]).mean()
print(a)

import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_route_cnt.csv")
print(data.head())

import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
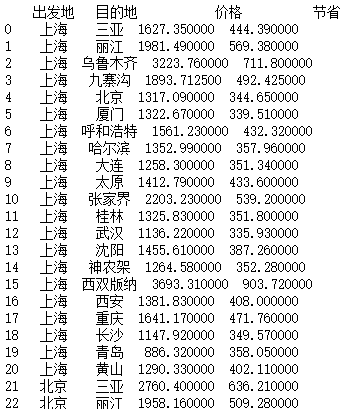
a = data.groupby([data["出发地"],data["目的地"]],as_index=False).mean()
print(a)
import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_route_cnt.csv")
print(data.head())
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
print(data_1.head())
a = data_1.groupby([data_1["出发地"],data_1["目的地"]],as_index=False).mean()
print(a.head())
b = pd.merge(a,data)
print(b.head())

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = pd.pivot_table(data_1,values=["价格"],index=["出发地"],columns=["目的地"])
print(a.head())

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = pd.pivot_table(data_1[data_1["出发地"]=="杭州"],values=["价格"],index=["出发地","目的地"],columns=["去程方式"])
print(a)

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(data_1.head())
print(data_1.isnull().head())
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
print(a.isnull())

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.dropna(axis=0)
print(b)

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.dropna(axis=1)
print(b)

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.fillna("missing")
print(b)
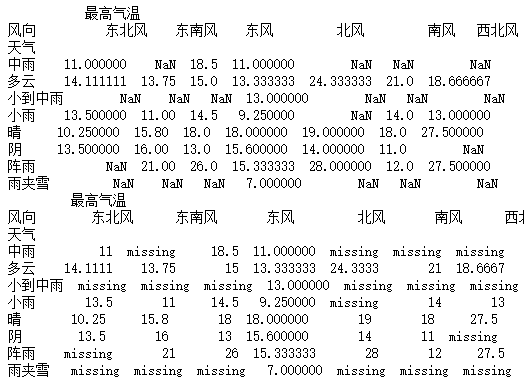
import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.fillna(method="pad")
print(b)

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.fillna(method="bfill",limit=1)
print(b)

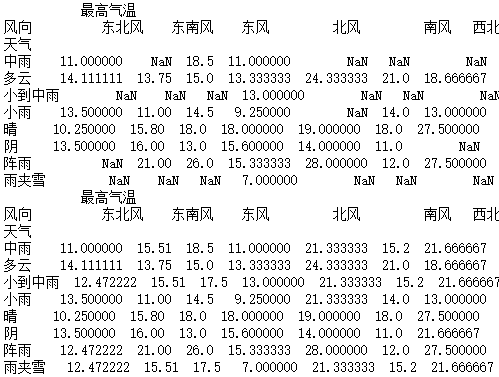
import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.fillna(a.mean())
print(b)
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(np.shape(df))
print(df.head())
fig,ax = plt.subplots(1,1,figsize=(8,5))
ax.hist(df["最低气温"],bins=20)
plt.show()
d = df["最低气温"]
zscore = (d-d.mean())/d.std()
df["isOutlier"]=zscore.abs()>3
print(df.head())
a = df["isOutlier"].value_counts()
print(a)


%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\sale_data.csv")
print(np.shape(df))
print(df.head())
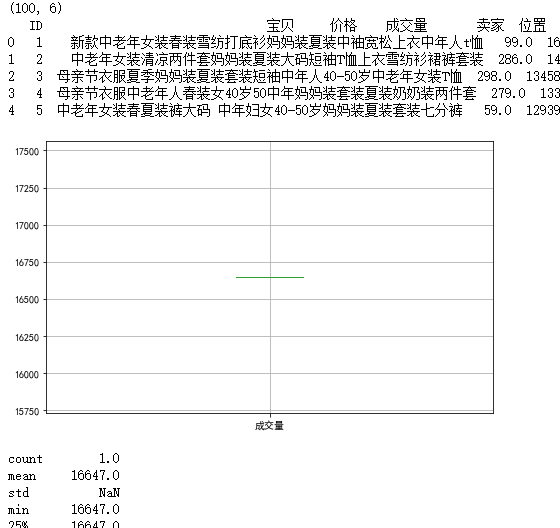
a = df[df["卖家"]=="夏奈凤凰旗舰店"]
fig,ax = plt.subplots(1,1,figsize=(8,5))
a.boxplot(column="成交量",ax=ax)
plt.show()
b = a["成交量"]
print(b.describe())
a["isOutlier"]=d>d.quantile(0.75)
c = a[a["isOutlier"]==True]
print(c)
import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(np.shape(df))
print(df.head())
a = df.duplicated()
print(np.shape(a))
print(a[:5])

import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(np.shape(df))
a = df.set_index("日期")
print(a.head())
b = a.duplicated()
print(b[:5])
import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(np.shape(df))
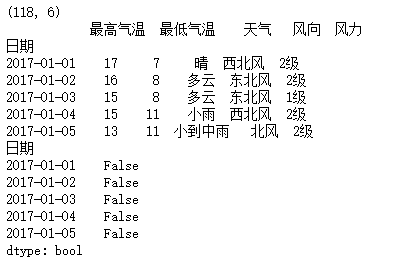
a = df.set_index("日期")
print(a.head())
b = a.duplicated("最高气温")
print(b[:5])

import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(type(df))
print(np.shape(df))
a = df.set_index("日期")
print(a.head())
b = a.drop_duplicates("最高气温")
print(np.shape(b))
print(b.head())

import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
print(df.head())
print(df.info())

import numpy as np
import pandas as pd
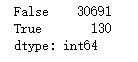
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = df.duplicated().value_counts()
print(a)
import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = df.drop_duplicates()
b = a.duplicated().value_counts()
print(b)

import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = df.drop_duplicates()
print(a.describe())

%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
print(np.shape(df))
fig,axes = plt.subplots(1,2,figsize=(12,5))
axes[0].hist(df["价格"],bins=20)
df.boxplot(column="价格",ax=axes[1])
plt.show()

%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
d = df["价格"]
zscore = (d-d.mean())/d.std()
print(zscore[0:3])
df["isOutlier"]=zscore.abs()>3.5
print(df["isOutlier"].value_counts())
a = df[df["isOutlier"]==True]
print(a.head())

吴裕雄 python 数据处理(2)的更多相关文章
- 吴裕雄 python 数据处理(3)
import time a = time.time()print(a)b = time.localtime()print(b)c = time.strftime("%Y-%m-%d %X&q ...
- 吴裕雄 python 数据处理(1)
import time print(time.time())print(time.localtime())print(time.strftime('%Y-%m-%d %X',time.localtim ...
- 吴裕雄 python 神经网络——TensorFlow 输入数据处理框架
import tensorflow as tf files = tf.train.match_filenames_once("E:\\MNIST_data\\output.tfrecords ...
- 吴裕雄 python神经网络 花朵图片识别(10)
import osimport numpy as npimport matplotlib.pyplot as pltfrom PIL import Image, ImageChopsfrom skim ...
- 吴裕雄 python神经网络 花朵图片识别(9)
import osimport numpy as npimport matplotlib.pyplot as pltfrom PIL import Image, ImageChopsfrom skim ...
- 吴裕雄 python 神经网络——TensorFlow pb文件保存方法
import tensorflow as tf from tensorflow.python.framework import graph_util v1 = tf.Variable(tf.const ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(4)
# -*- coding: utf-8 -*- import glob import os.path import numpy as np import tensorflow as tf from t ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(3)
import glob import os.path import numpy as np import tensorflow as tf from tensorflow.python.platfor ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(2)
import glob import os.path import numpy as np import tensorflow as tf from tensorflow.python.platfor ...
随机推荐
- 大快hadoop安装包下载与平台监控参数说明
前阶段用了差不多两周的时间把DKhadoop的运行环境搭建以及安装的各个操作都介绍了一遍.关于DKhadoop安装包下载也只是顺带说了一下,但好像大快搜索的服务器在更新,新的下载页面还不好用!有好些朋 ...
- Openfiler使用说明
Openfiler使用说明 http://www.cnblogs.com/zb9222/p/6118074.html 一. Openfiler简介 Openfiler 能把标准x86/64架构的系统变 ...
- 小峰mybatis(5)mybatis使用注解配置sql映射器--动态sql
一.使用注解配置映射器 动态sql: 用的并不是很多,了解下: Student.java 实体bean: package com.cy.model; public class Student{ pri ...
- Java-Runoob-高级教程-实例-数组:04. Java 实例 – 数组反转
ylbtech-Java-Runoob-高级教程-实例-数组:04. Java 实例 – 数组反转 1.返回顶部 1. Java 实例 - 数组反转 Java 实例 以下实例中我们使用 Collec ...
- (转)USB中CDC-ECM的了解和配置
USB中典型类及子类: 类别 解释 子类 典型应用 IC芯片 备注 UVC 视频类 免驱USB摄像头 CDC 通讯类 RNDIS ECM(p24) 免驱USB网卡 RTL8152B EEM ..... ...
- [datatable]借助DataTable的Compute方法
借助DataTable的Compute方法,DataTable中数据不用事先排好序. 下面代码中的dt是跟前面的是一样的 DataTable dtName = dt.DefaultView.ToTab ...
- 让MySql支持Emoji表情(MySQL中4字节utf8字符保存方法)
手机端插入Emoji表情,保存到数据库时报错: Caused by: java.sql.SQLException: Incorrect string value: '\xF0\x9F\x98\x84' ...
- 在docker中运行kong和kong dashboard
一.制作alpine版的kong镜像 https://github.com/Kong/docker-kong/tree/d4cec3dc46c780a916a40963309554ca81da2b46 ...
- MySQL 安装方法
所有平台的Mysql下载地址为: MySQL 下载. 挑选你需要的 MySQL Community Server 版本及对应的平台. Linux/UNIX上安装Mysql Linux平台上推荐使用RP ...
- Solr SchemaXml 一些解读
The schema.xml file contains all of the details about which fields your documents can contain, and h ...