关系型数据库之Mysql
简介
- 主要知识点包括:能够与mysql建立连接,创建数据库、表,分别从图形界面与脚本界面两个方面讲解
- 相关的知识点包括:E-R关系模型,数据库的3范式,mysql中数据字段的类型,字段约束
- 数据库的操作主要包括:
- 数据库的操作,包括创建、删除
- 表的操作,包括创建、修改、删除
- 数据的操作,包括增加、修改、删除、查询,简称crud
- 学生表结构:
- id
- 名称
- 性别
- 地址
- 生日
- 科目表结构:
- id
- 名称
数据库简介
- 人类在进化的过程中,创造了数字、文字、符号等来进行数据的记录,但是承受着认知能力和创造能力的提升,数据量越来越大,对于数据的记录和准确查找,成为了一个重大难题
- 计算机诞生后,数据开始在计算机中存储并计算,并设计出了数据库系统
- 数据库系统解决的问题:持久化存储,优化读写,保证数据的有效性
- 当前使用的数据库,主要分为两类
- 文档型,如sqlite,就是一个文件,通过对文件的复制完成数据库的复制
- 服务型,如mysql、postgre,数据存储在一个物理文件中,但是需要使用终端以tcp/ip协议连接,进行数据库的读写操作
E-R模型
- 当前物理的数据库都是按照E-R模型进行设计的
- E表示entry,实体
- R表示relationship,关系
- 一个实体转换为数据库中的一个表
- 关系描述两个实体之间的对应规则,包括
- 一对一
- 一对多
- 多对多
- 关系转换为数据库表中的一个列 *在关系型数据库中一行就是一个对象
三范式
- 经过研究和对使用中问题的总结,对于设计数据库提出了一些规范,这些规范被称为范式
- 第一范式(1NF):列不可拆分
- 第二范式(2NF):唯一标识
- 第三范式(3NF):引用主键
- 说明:后一个范式,都是在前一个范式的基础上建立的
安装
- 安装
sudo apt-get install mysql-server mysql-client
然后按照提示输入
管理服务
- 启动
service mysql start
- 停止
service mysql stop
- 重启
service mysql restart
允许远程连接
- 找到mysql配置文件并修改
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
将bind-address=127.0.0.1注释 - 登录mysql,运行命令
grant all privileges on *.* to 'root'@'%' identified by 'mysql' with grant option;
flush privileges; - 重启mysql
数据完整性
- 一个数据库就是一个完整的业务单元,可以包含多张表,数据被存储在表中
- 在表中为了更加准确的存储数据,保证数据的正确有效,可以在创建表的时候,为表添加一些强制性的验证,包括数据字段的类型、约束
字段类型
- 在mysql中包含的数据类型很多,这里主要列出来常用的几种
- 数字:int,decimal
- 字符串:varchar,text
- 日期:datetime
- 布尔:bit
约束
- 主键primary key
- 非空not null
- 惟一unique
- 默认default
- 外键foreign key
使用图形窗口连接
- 下发windows的navicat
- 点击“连接”弹出窗口,按照提示填写连接信息,如下图
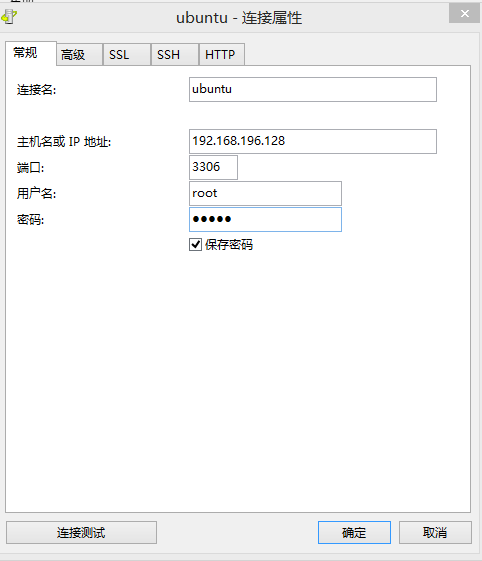
- 连接成功后,会在连接名称下面显示出当前的数据库
- 双击选中数据库,就可以编辑此数据库
- 下次再进入此软件时,通过双击完成连接、编辑操作
数据库操作
- 在连接的名称上右击,选择“新建数据库”,弹出窗口,并按提示填写
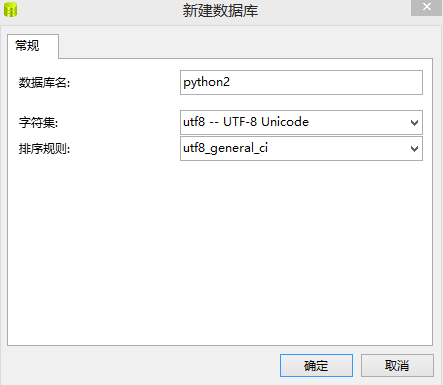
- 在数据库上右击,选择“删除数据库”可以完成删除操作
表操作
- 当数据库显示为高亮时,表示当前操作此数据库,可以在数据中创建表
- 一个实体对应一张表,用于存储特定结构的数据
- 点击“新建表”,弹出窗口,按提示填写信息
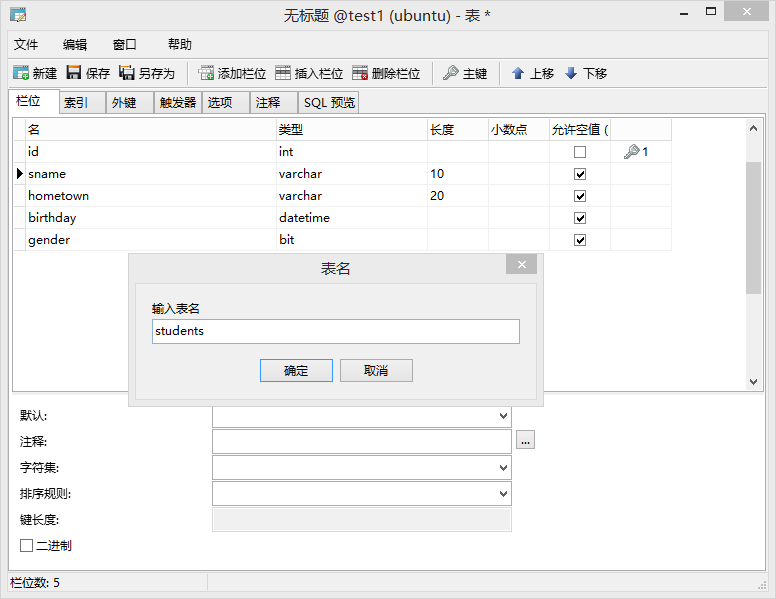
- 主键的名称一般为id,设置为int型,无符号数,自动增长,非空
- 自动增长表示由mysql系统负责维护这个字段的值,不需要手动维护,所以不用关心这个字段的具体值
- 字符串varchar类型需要设置长度,即最多包含多少个字符
- 点击“添加栏位”,可以添加一个新的字段
- 点击“保存”,为表定义名称
数据操作
- 表创建成功后,可以在右侧看到,双击表打开新窗口,如下图
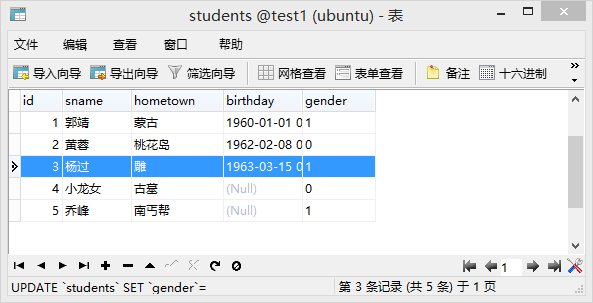
- 在此窗口中可以增加、修改、删除数据
逻辑删除
- 对于重要数据,并不希望物理删除,一旦删除,数据无法找回
- 一般对于重要数据,会设置一个isDelete的列,类型为bit,表示逻辑删除
- 大于大量增长的非重要数据,可以进行物理删除
- 数据的重要性,要根据实际开发决定
使用命令连接
- 命令操作方式,在工作中使用的更多一些,所以要达到熟练的程度
- 打开终端,运行命令
mysql -uroot -p
回车后输入密码,当前设置的密码为mysql
- 连接成功后如下图
- 退出登录
quit或exit
- 退出成功后如下图

- 登录成功后,输入如下命令查看效果
查看版本:select version();
显示当前时间:select now(); - 注意:在语句结尾要使用分号;
远程连接
- 一般在公司开发中,可能会将数据库统一搭建在一台服务器上,所有开发人员共用一个数据库,而不是在自己的电脑中配置一个数据库
- 运行命令
mysql -hip地址 -uroot -p
- -h后面写要连接的主机ip地址
- -u后面写连接的用户名
- -p回车后写密码
数据库操作
- 创建数据库
create database 数据库名 charset=utf8;v
- 删除数据库
drop database 数据库名;
- 切换数据库
use 数据库名;
- 查看当前选择的数据库
select database();
表操作
- 查看当前数据库中所有表
show tables;
- 创建表
auto_increment表示自动增长
create table 表名(列及类型);
如:
create table students(
id int auto_increment primary key,
sname varchar(10) not null
);
- 修改表
alter table 表名 add|change|drop 列名 类型;
如:
alter table students add birthday datetime; - 删除表
drop table 表名;
- 查看表结构
desc 表名;
- 更改表名称
rename table 原表名 to 新表名;
- 查看表的创建语句
show create table '表名';
数据操作
- 查询
select * from 表名
- 增加
全列插入:insert into 表名 values(...)
缺省插入:insert into 表名(列1,...) values(值1,...)
同时插入多条数据:insert into 表名 values(...),(...)...;
或insert into 表名(列1,...) values(值1,...),(值1,...)...;
- 主键列是自动增长,但是在全列插入时需要占位,通常使用0,插入成功后以实际数据为准
- 修改
update 表名 set 列1=值1,... where 条
- 删除
delete from 表名 where 条件
- 逻辑删除,本质就是修改操作update
alter table students add isdelete bit default 0;
如果需要删除则
update students isdelete=1 where ...;备份与恢复
数据备份
- 进入超级管理员
sudo -s
- 进入mysql库目录
cd /var/lib/mysql
- 运行mysqldump命令
ysqldump –uroot –p 数据库名 > ~/Desktop/备份文件.sql;
按提示输入mysql的密码数据恢复
- 连接mysqk,创建数据库
- 退出连接,执行如下命令
mysql -uroot –p 数据库名 < ~/Desktop/备份文件.sql
根据提示输入mysql密码
总结
- 数据库解决的问题,E-R模型,三范式
- 图形界面操作数据库、表、数据
- 命令行操作数据库、表、数据
表查询简介
- 查询的基本语法
select * from 表名;
- from关键字后面写表名,表示数据来源于是这张表
- select后面写表中的列名,如果是*表示在结果中显示表中所有列
- 在select后面的列名部分,可以使用as为列起别名,这个别名出现在结果集中
- 如果要查询多个列,之间使用逗号分隔
消除重复行
- 在select后面列前使用distinct可以消除重复的行
select distinct gender from students;
条件
- 使用where子句对表中的数据筛选,结果为true的行会出现在结果集中
- 语法如下:
select * from 表名 where 条件;
比较运算符
- 等于=
- 大于>
- 大于等于>=
- 小于<
- 小于等于<=
- 不等于!=或<>
- 查询编号大于3的学生
select * from students where id>3;
- 查询编号不大于4的科目
select * from subjects where id<=4;
- 查询姓名不是“黄蓉”的学生
select * from students where sname!='黄蓉';
- 查询没被删除的学生
select * from students where isdelete=0;
逻辑运算符
- and
- or
- not
- 查询编号大于3的女同学
select * from students where id>3 and gender=0;
- 查询编号小于4或没被删除的学生
select * from students where id<4 or isdelete=0;
模糊查询
- like
- %表示任意多个任意字符
- _表示一个任意字符
- 查询姓黄的学生
select * from students where sname like '黄%';
- 查询姓黄并且名字是一个字的学生
select * from students where sname like '黄_';
- 查询姓黄或叫靖的学生
select * from students where sname like '黄%' or sname like '%靖%';
范围查询
- in表示在一个非连续的范围内
- 查询编号是1或3或8的学生
select * from students where id in(1,3,8);
- between ... and ...表示在一个连续的范围内
- 查询学生是3至8的学生
select * from students where id between 3 and 8;
- 查询学生是3至8的男生
select * from students where id between 3 and 8 and gender=1;
空判断
- 注意:null与''是不同的
- 判空is null
- 查询没有填写地址的学生
select * from students where hometown is null;
- 判非空is not null
- 查询填写了地址的学生
select * from students where hometown is not null;
- 查询填写了地址的女生
select * from students where hometown is not null and gender=0;
优先级
- 小括号,not,比较运算符,逻辑运算符
- and比or先运算,如果同时出现并希望先算or,需要结合()使用
聚合
- 为了快速得到统计数据,提供了5个聚合函数
- count(*)表示计算总行数,括号中写星与列名,结果是相同的
- 查询学生总数
select count(*) from students;
- max(列)表示求此列的最大值
- 查询女生的编号最大值
select max(id) from students where gender=0;
- min(列)表示求此列的最小值
- 查询未删除的学生最小编号
select min(id) from students where isdelete=0;
- sum(列)表示求此列的和
- 查询男生的编号之后
select sum(id) from students where gender=1;
- avg(列)表示求此列的平均值
- 查询未删除女生的编号平均值
select avg(id) from students where isdelete=0 and gender=0;
分组
- 按照字段分组,表示此字段相同的数据会被放到一个组中
- 分组后,只能查询出相同的数据列,对于有差异的数据列无法出现在结果集中
- 可以对分组后的数据进行统计,做聚合运算
- 语法:
select 列1,列2,聚合... from 表名 group by 列1,列2,列3...
- 查询男女生总数
select gender as 性别,count(*)
from students
group by gender;
- 查询各城市人数
select hometown as 家乡,count(*)
from students
group by hometown;分组后的数据筛选
- 语法:
select 列1,列2,聚合... from 表名
group by 列1,列2,列3...
having 列1,...聚合... - 查询男生总人数
having后面的条件运算符与where的相同
方案一
select count(*)
from students
where gender=1;
-----------------------------------
方案二:
select gender as 性别,count(*)
from students
group by gender
having gender=1;
对比where与having
- where是对from后面指定的表进行数据筛选,属于对原始数据的筛选
- having是对group by的结果进行筛选
排序
- 为了方便查看数据,可以对数据进行排序
- 语法:
select * from 表名
order by 列1 asc|desc,列2 asc|desc,...
- 将行数据按照列1进行排序,如果某些行列1的值相同时,则按照列2排序,以此类推
- 默认按照列值从小到大排列
- asc从小到大排列,即升序
- desc从大到小排序,即降序
- 查询未删除男生学生信息,按学号降序
select * from students
where gender=1 and isdelete=0
order by id desc;
- 查询未删除科目信息,按名称升序
select * from subject
where isdelete=0
order by stitle;获取部分行
- 当数据量过大时,在一页中查看数据是一件非常麻烦的事情
- 语法
select * from 表名
limit start,count
- 从start开始,获取count条数据
- start索引从0开始
示例:分页
- 已知:每页显示m条数据,当前显示第n页
- 求总页数:此段逻辑后面会在python中实现
- 查询总条数p1
- 使用p1除以m得到p2
- 如果整除则p2为总数页
- 如果不整除则p2+1为总页数
- 求第n页的数据
select * from students
where isdelete=0
limit (n-1)*m,m
总结
- 完整的select语句
select distinct *
from 表名
where ....
group by ... having ...
order by ...
limit star,count
- 执行顺序为:
- from 表名
- where ....
- group by ...
- select distinct *
- having ...
- order by ...
- limit star,count
- 实际使用中,只是语句中某些部分的组合,而不是全部
关系型数据库之Mysql的更多相关文章
- Cobar是提供关系型数据库(MySQL)分布式服务的中间件
简介 Cobar是提供关系型数据库(MySQL)分布式服务的中间件,它可以让传统的数据库得到良好的线性扩展,并看上去还是一个数据库,对应用保持透明. 产品在阿里巴巴稳定运行3年以上. 接管了3000+ ...
- 关系型数据库之MySQL基础总结_part1
一:数据库的操作语言的种类 MySQL 是我们最常使用的关系型数据库,对于MySQL的操作的语言种类又可以分为:DDL,DML,DCL,DQL DDL:是数据库的定义语言:主要对于数据库信息的一些定义 ...
- 关于关系型数据库(MySQL)的一些概念
主键:关系型数据库中的一条记录中有若干个属性,若其中某一个属性组(注意是组)能唯一标识一条记录, 该属性组就可以成为一个主键,主键不允许为空,主键只能有同一个 外键:如果一个表的某个属性是另一个表的主 ...
- 数据存储之关系型数据库存储---MySQL存储
MySQL的存储 利用PyMySQL连接MySQL 连接数据库 import pymysql # 连接MySQL MySQL在本地运行 用户名为root 密码为123456 默认端口3306 db = ...
- 应用开发实践之关系型数据库(以MySql为例)小结
本文主要是对目前工作中使用到的DB相关知识点的总结,应用开发了解到以下深度基本足以应对日常需求,再深入下去更偏向于DB本身的理论.调优和运维实践. 不在本文重点关注讨论的内容(可能会提到一些): 具体 ...
- Oracle,SQL Server 数据库较MySql数据库,Sql语句差异
原文:Oracle,SQL Server 数据库较MySql数据库,Sql语句差异 Oracle,SQL Server 数据库较MySql数据库,Sql语句差异 1.关系型数据库 百度百科 关系数据库 ...
- redis事务与关系型数据库事务比较
redis 是一个高性能的key-value 数据库.作为no sql 数据库redis 与传统关系型数据库相比有简单灵活.数据结构丰富.高速读写等优点. 本文主要针对redis 在事物方面的处理与传 ...
- 【Redis】(1)-- 关系型数据库与非关系型数据库
关系型数据库与非关系型数据库 2019-07-02 16:34:48 by冲冲 1. 关系型数据库 1.1 概念 关系型数据库,是指采用了关系模型来组织数据的数据库.关系模型指的就是二维表格模型, ...
- SQLite vs MySQL vs PostgreSQL:关系型数据库比较
自1970年埃德加·科德提出关系模型之后,关系型数据库便开始出现,经过了40多年的演化,如今的关系型数据库种类繁多,功能强大,使用广泛.面对如此之多的关系型数据库,我们应该如何权衡找出适合自己应用场景 ...
随机推荐
- POJ 3617:Best Cow Line(贪心,字典序)
Best Cow Line Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 30684 Accepted: 8185 De ...
- CSI-MIPI学习笔记
一.mipi LCD 的CLK时钟频率与显示分辨率及帧率的关系 公式: Mipiclock = [ (width+hsync+hfp+hbp) x (height+vsync+vfp+vbp) ] x ...
- 使用VBS发邮件
NameSpace = "http://schemas.microsoft.com/cdo/configuration/"set Email = CreateObject(&quo ...
- Centos下LNMP安装
安装nginx [root@xuegod64 ~]# yum install -y gcc gcc-c++ autoconf automake zlib zlib-devel openssl open ...
- linux的性能优化
转一位大神的笔记. linux的性能优化: 1.CPU,MEM 2.DISK--RAID 3.网络相关的外设,网卡 linux系统性能分析: top:linux系统的负载,CPU,MEM,SWAP,占 ...
- 使用Oracle PROFILE控制会话空闲时间
客户想实现对会话空闲时间的控制,下面是做的一个例子.Microsoft Windows [版本 6.1.7601] 版权所有 (c) 2009 Microsoft Corporation.保留所有权利 ...
- PHP安全相关的配置(1)
PHP作为一门强大的脚本语言被越来越多的web应用程序采用,不规范的php安全配置可能会带来敏感信息泄漏.SQL注射.远程包含等问题,规范的安全配置可保障最基本的安全环境.下面我们分析几个会引发安全问 ...
- linux ping报错Name or service not known
ubuntu设置静态ip以后忘记设置dns,ping的时候报错:Name or service not known 添加dns即可 vi /etc/resolv.conf nameserver 8.8 ...
- thinkphp mysql和mongodb 完美使用
thinkphp mysql和mongodb 完美使用.第一步:在你的应用的Model文件下建立一个MonModel如下图第二步:MonModel的内容如下 <?php /** * Create ...
- C# 爬取网页上的数据
最近工作中需求定时爬取不同城市每天的温度.其实就是通过编程的方法去抓取不同网站网页进行分析筛选的过程..NET提供了很多类去访问并获得远程网页的数据,比如WebClient类和HttpWebReque ...