OpenACC 梯度下降法求解线性方程的优化
▶ 书上第二章,用一系列步骤优化梯度下降法解线性方程组。才发现 PGI community 编译器不支持 Windows 下的 C++ 编译(有 pgCC 命令但是不支持 .cpp 文件,要专业版才支持),以后 OpenACC - C++ 全盘转向 Ubuntu 中。
● 代码
// matrix.h
#pragma once
#include <cstdlib> struct matrix
{
unsigned int num_rows;
unsigned int nnz;
unsigned int *row_offsets;
unsigned int *cols;
double *coefs;
}; void allocate_3d_poission_matrix(matrix &A, int N)
{
const int num_rows = (N + ) * (N + ) * (N + );
A.num_rows = num_rows;
A.row_offsets = (unsigned int*)malloc((num_rows + ) * sizeof(unsigned int));
A.cols = (unsigned int*)malloc( * num_rows * sizeof(unsigned int));
A.coefs = (double*)malloc( * num_rows * sizeof(double)); const int ystride = N, zstride = N * N;
int i, j, n, nnz, offsets[];
double coefs[]; i = ;
for (int z = -; z <= ; z++)
{
for (int y = -; y <= ; y++)
{
for (int x = -; x <= ; x++)
{
offsets[i] = zstride * z + ystride * y + x;
if (x == && y == && z == )
coefs[i] = ;
else
coefs[i] = -;
i++;
}
}
}
nnz = ;
for (i = ; i < num_rows; i++)
{
A.row_offsets[i] = nnz;
for (j = ; j < ; j++)
{
n = i + offsets[j];
if (n >= && n<num_rows)
{
A.cols[nnz] = n;
A.coefs[nnz] = coefs[j];
nnz++;
}
}
}
A.row_offsets[num_rows] = nnz;
A.nnz = nnz;
} void free_matrix(matrix &A)
{
unsigned int *row_offsets = A.row_offsets, *cols = A.cols;
double *coefs = A.coefs;
free(row_offsets);
free(cols);
free(coefs);
}
// matrix_function.h
#pragma once
#include "vector.h"
#include "matrix.h" void matvec(const matrix& A, const vector& x, const vector &y)
{ const unsigned int num_rows = A.num_rows;
unsigned int *row_offsets = A.row_offsets, *cols = A.cols;
double *Acoefs = A.coefs, *xcoefs = x.coefs, *ycoefs = y.coefs; for (int i = ; i < num_rows; i++)
{
const int row_start = row_offsets[i], row_end = row_offsets[i + ];
double sum = ;
for (int j = row_start; j < row_end; j++)
sum += Acoefs[j] * xcoefs[cols[j]];
ycoefs[i] = sum;
}
}
// vector.h
#pragma once
#include<cstdlib>
#include<cmath> struct vector
{
unsigned int n;
double *coefs;
}; void allocate_vector(vector &v, const unsigned int n)
{
v.n = n;
v.coefs = (double*)malloc(n * sizeof(double));
} void free_vector(vector &v)
{
v.n = ;
free(v.coefs);
} void initialize_vector(vector &v, const double val)
{
for (int i = ; i < v.n; i++)
v.coefs[i] = val;
}
// vector_function.h
#pragma once
#include<cstdlib>
#include "vector.h" double dot(const vector& x, const vector& y)
{
const unsigned int n = x.n;
double sum = , *xcoefs = x.coefs, *ycoefs = y.coefs; for (int i = ; i < n; i++)
sum += xcoefs[i] * ycoefs[i];
return sum;
} void waxpby(double alpha, const vector &x, double beta, const vector &y, const vector& w)
{
const unsigned int n = x.n;
double *xcoefs = x.coefs, *ycoefs = y.coefs, *wcoefs = w.coefs; for (int i = ; i < n; i++)
wcoefs[i] = alpha * xcoefs[i] + beta * ycoefs[i];
}
// main.cpp
#include <cstdlib>
#include <cstdio>
#include <chrono> #include "vector.h"
#include "vector_functions.h"
#include "matrix.h"
#include "matrix_functions.h" using namespace std::chrono; #define N 200
#define MAX_ITERS 100
#define TOL 1e-12 int main()
{
int iter;
double normr, rtrans, oldtrans, alpha;
vector x, p, Ap, b, r;
matrix A;
high_resolution_clock::time_point t1, t2; allocate_3d_poission_matrix(A, N);
allocate_vector(x, A.num_rows);
allocate_vector(p, A.num_rows);
allocate_vector(Ap, A.num_rows);
allocate_vector(b, A.num_rows);
allocate_vector(r, A.num_rows);
printf("Rows: %d, nnz: %d\n", A.num_rows, A.row_offsets[A.num_rows]); initialize_vector(x, );
initialize_vector(b, ); // 计算一个初始 r
waxpby(1.0, x, 0.0, x, p);
matvec(A, p, Ap);
waxpby(1.0, b, -1.0, Ap, r);
rtrans = dot(r, r);
normr = sqrt(rtrans); t1 = high_resolution_clock::now();
for(iter = ; iter < MAX_ITERS && normr > TOL; iter++)
{
// 更新 p 和 rtrans
if (iter == )
waxpby(1.0, r, 0.0, r, p);
else
{
oldtrans = rtrans;
rtrans = dot(r, r);
waxpby(1.0, r, rtrans / oldtrans, p, p);
} // 计算步长 alpha,用的是上一次的 rtran
matvec(A, p, Ap);
alpha = rtrans / dot(Ap, p);
normr = sqrt(rtrans); // 更新 x 和 r
waxpby(1.0, x, alpha, p, x);
waxpby(1.0, r, -alpha, Ap, r); if (iter % == )
printf("Iteration: %d, Tolerance: %.4e\n", iter, normr);
}
t2 = high_resolution_clock::now();
duration<double> time = duration_cast<duration<double>>(t2 - t1);
printf("Iterarion: %d, error: %e, time: %f s\n", iter, normr, time.count()); free_matrix(A);
free_vector(x);
free_vector(p);
free_vector(Ap);
free_vector(b);
free_vector(r);
//getchar();
return ;
}
● 输出结果,WSL
// WSL:
cuan@CUAN:/mnt/d/Code/ParallelProgrammingWithOpenACC-master/Chapter02/cpp$ pgc++ -std=c++ -acc -fast main.cpp -o acc.exe
cuan@CUAN:/mnt/d/Code/ParallelProgrammingWithOpenACC-master/Chapter02/cpp$ ./acc.exe
Rows: , nnz:
Iteration: , Tolerance: 4.0067e+08
Iteration: , Tolerance: 1.8772e+07
Iteration: , Tolerance: 6.4359e+05
Iteration: , Tolerance: 2.3202e+04
Iteration: , Tolerance: 8.3565e+02
Iteration: , Tolerance: 3.0039e+01
Iteration: , Tolerance: 1.0764e+00
Iteration: , Tolerance: 3.8360e-02
Iteration: , Tolerance: 1.3515e-03
Iteration: , Tolerance: 4.6209e-05
Iterarion: , error: 1.993399e-06, time: 17.065934 s // Ubuntu:
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/cpp$ pgc++ -std=c++ -acc -fast -Minfo -ta=tesla main.cpp -o no_acc.exe
initialize_vector(vector &, double):
, include "vector.h"
, Memory set idiom, loop replaced by call to __c_mset8
dot(const vector &, const vector &):
, include "vector_functions.h"
, Generated an alternate version of the loop
Generated vector simd code for the loop containing reductions
Generated prefetch instructions for the loop
Generated vector simd code for the loop containing reductions
Generated prefetch instructions for the loop
FMA (fused multiply-add) instruction(s) generated
waxpby(double, const vector &, double, const vector &, const vector &):
, include "vector_functions.h"
, Generated alternate versions of the loop
Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed
Generated prefetch instructions for the loop
Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed
Generated prefetch instructions for the loop
Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed
Generated prefetch instructions for the loop
Loop unrolled times
FMA (fused multiply-add) instruction(s) generated
allocate_3d_poission_matrix(matrix &, int):
, include "matrix.h"
, Loop not fused: different loop trip count
, Loop not vectorized/parallelized: loop count too small
, Loop unrolled times (completely unrolled)
, Loop not vectorized: data dependency
matvec(const matrix &, const vector &, const vector &):
, include "matrix_functions.h"
, Generated an alternate version of the loop
Generated vector simd code for the loop containing reductions
Generated a prefetch instruction for the loop
Generated vector simd code for the loop containing reductions
Generated a prefetch instruction for the loop
FMA (fused multiply-add) instruction(s) generated
main:
, allocate_3d_poission_matrix(matrix &, int) inlined, size= (inline) file main.cpp ()
, Loop not fused: different loop trip count
, Loop not vectorized/parallelized: loop count too small
, Loop unrolled times (completely unrolled)
, Loop not fused: function call before adjacent loop
, Loop not vectorized: data dependency
, allocate_vector(vector &, unsigned int) inlined, size= (inline) file main.cpp ()
, allocate_vector(vector &, unsigned int) inlined, size= (inline) file main.cpp ()
, allocate_vector(vector &, unsigned int) inlined, size= (inline) file main.cpp ()
, allocate_vector(vector &, unsigned int) inlined, size= (inline) file main.cpp ()
, allocate_vector(vector &, unsigned int) inlined, size= (inline) file main.cpp ()
, initialize_vector(vector &, double) inlined, size= (inline) file main.cpp ()
, Memory set idiom, loop replaced by call to __c_mset8
, initialize_vector(vector &, double) inlined, size= (inline) file main.cpp ()
, Memory set idiom, loop replaced by call to __c_mset8
, waxpby(double, const vector &, double, const vector &, const vector &) inlined, size= (inline) file main.cpp ()
, Memory copy idiom, loop replaced by call to __c_mcopy8
, matvec(const matrix &, const vector &, const vector &) inlined, size= (inline) file main.cpp ()
, Loop not fused: dependence chain to sibling loop
, Generated an alternate version of the loop
Generated vector simd code for the loop containing reductions
Generated a prefetch instruction for the loop
Generated vector simd code for the loop containing reductions
Generated a prefetch instruction for the loop
FMA (fused multiply-add) instruction(s) generated
, waxpby(double, const vector &, double, const vector &, const vector &) inlined, size= (inline) file main.cpp ()
, Loop not fused: dependence chain to sibling loop
Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed
Generated prefetch instructions for the loop
Loop unrolled times
Generated prefetches in scalar loop
FMA (fused multiply-add) instruction(s) generated
, dot(const vector &, const vector &) inlined, size= (inline) file main.cpp ()
, Loop not fused: function call before adjacent loop
Generated vector simd code for the loop containing reductions
Generated prefetch instructions for the loop
FMA (fused multiply-add) instruction(s) generated
, Loop not vectorized/parallelized: potential early exits
, waxpby(double, const vector &, double, const vector &, const vector &) inlined, size= (inline) file main.cpp ()
, Memory copy idiom, loop replaced by call to __c_mcopy8
, dot(const vector &, const vector &) inlined, size= (inline) file main.cpp ()
, Loop not fused: dependence chain to sibling loop
Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed
Generated vector simd code for the loop containing reductions
Generated prefetch instructions for the loop
FMA (fused multiply-add) instruction(s) generated
, waxpby(double, const vector &, double, const vector &, const vector &) inlined, size= (inline) file main.cpp ()
, Loop not fused: different controlling conditions
Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed
Generated prefetch instructions for the loop
Loop unrolled times
Generated prefetches in scalar loop
FMA (fused multiply-add) instruction(s) generated
, matvec(const matrix &, const vector &, const vector &) inlined, size= (inline) file main.cpp ()
, Loop not fused: dependence chain to sibling loop
, Generated an alternate version of the loop
Generated vector simd code for the loop containing reductions
Generated a prefetch instruction for the loop
Generated vector simd code for the loop containing reductions
Generated a prefetch instruction for the loop
FMA (fused multiply-add) instruction(s) generated
, dot(const vector &, const vector &) inlined, size= (inline) file main.cpp ()
, Loop not fused: dependence chain to sibling loop
Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed
Generated vector simd code for the loop containing reductions
Generated prefetch instructions for the loop
FMA (fused multiply-add) instruction(s) generated
, waxpby(double, const vector &, double, const vector &, const vector &) inlined, size= (inline) file main.cpp ()
, Loop not fused: dependence chain to sibling loop
Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed
Loop not vectorized: data dependency
Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed
Generated prefetch instructions for the loop
Loop unrolled times
Generated prefetches in scalar loop
FMA (fused multiply-add) instruction(s) generated
, waxpby(double, const vector &, double, const vector &, const vector &) inlined, size= (inline) file main.cpp ()
, Loop not fused: function call before adjacent loop
Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed
Generated prefetch instructions for the loop
Loop unrolled times
Generated prefetches in scalar loop
FMA (fused multiply-add) instruction(s) generated
, free_matrix(matrix &) inlined, size= (inline) file main.cpp ()
, free_vector(vector &) inlined, size= (inline) file main.cpp ()
, free_vector(vector &) inlined, size= (inline) file main.cpp ()
, free_vector(vector &) inlined, size= (inline) file main.cpp ()
, free_vector(vector &) inlined, size= (inline) file main.cpp ()
, free_vector(vector &) inlined, size= (inline) file main.cpp ()
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/cpp$ ./no_acc.exe
Rows: , nnz:
Iteration: , Tolerance: 4.0067e+08
Iteration: , Tolerance: 1.8772e+07
Iteration: , Tolerance: 6.4359e+05
Iteration: , Tolerance: 2.3202e+04
Iteration: , Tolerance: 8.3565e+02
Iteration: , Tolerance: 3.0039e+01
Iteration: , Tolerance: 1.0764e+00
Iteration: , Tolerance: 3.8360e-02
Iteration: , Tolerance: 1.3515e-03
Iteration: , Tolerance: 4.6209e-05
Iterarion: , error: 1.993399e-06, time: 17182.560547 ms
● 优化后
// matrix.h
#pragma once
#include <cstdlib> struct matrix
{
unsigned int num_rows;
unsigned int nnz;
unsigned int *row_offsets;
unsigned int *cols;
double *coefs;
}; void allocate_3d_poission_matrix(matrix &A, int N)
{
const int num_rows = (N + ) * (N + ) * (N + );
A.num_rows = num_rows;
A.row_offsets = (unsigned int*)malloc((num_rows + ) * sizeof(unsigned int));
A.cols = (unsigned int*)malloc( * num_rows * sizeof(unsigned int));
A.coefs = (double*)malloc( * num_rows * sizeof(double)); const int ystride = N, zstride = N * N;
int i, j, n, nnz, offsets[];
double coefs[]; i = ;
for (int z = -; z <= ; z++)
{
for (int y = -; y <= ; y++)
{
for (int x = -; x <= ; x++)
{
offsets[i] = zstride * z + ystride * y + x;
if (x == && y == && z == )
coefs[i] = ;
else
coefs[i] = -;
i++;
}
}
}
nnz = ;
for (i = ; i < num_rows; i++)
{
A.row_offsets[i] = nnz;
for (j = ; j < ; j++)
{
n = i + offsets[j];
if (n >= && n<num_rows)
{
A.cols[nnz] = n;
A.coefs[nnz] = coefs[j];
nnz++;
}
}
}
A.row_offsets[num_rows] = nnz;
A.nnz = nnz;
#pragma acc enter data copyin(A)
#pragma acc enter data copyin(A.row_offsets[0:num_rows+1],A.cols[0:nnz],A.coefs[0:nnz])
} void free_matrix(matrix &A)
{
unsigned int *row_offsets = A.row_offsets, *cols = A.cols;
double *coefs = A.coefs;
#pragma acc exit data delete(A.row_offsets,A.cols,A.coefs)
#pragma acc exit data delete(A)
free(row_offsets);
free(cols);
free(coefs);
}
// matrix_function.h
#pragma once
#include "vector.h"
#include "matrix.h" void matvec(const matrix& A, const vector& x, const vector &y)
{
const unsigned int num_rows=A.num_rows;
unsigned int *restrict row_offsets=A.row_offsets, *restrict cols=A.cols;
double *restrict Acoefs=A.coefs, *restrict xcoefs=x.coefs, *restrict ycoefs=y.coefs; #pragma acc kernels copyin(cols[0:A.nnz],Acoefs[0:A.nnz],xcoefs[0:x.n])
#pragma acc loop device_type(nvidia) gang worker(8)
for(int i = ; i < num_rows; i++)
{
double sum = ;
const int row_start=row_offsets[i], row_end=row_offsets[i+];
#pragma acc loop device_type(nvidia) vector(32)
for(int j = row_start; j < row_end; j++)
sum += Acoefs[j] * xcoefs[cols[j]];
ycoefs[i] = sum;
}
}
// vector.h
#pragma once
#include<cstdlib>
#include<cmath> struct vector
{
unsigned int n;
double *coefs;
}; void allocate_vector(vector &v, const unsigned int n)
{
v.n=n;
v.coefs=(double*)malloc(n*sizeof(double));
#pragma acc enter data create(v)
#pragma acc enter data create(v.coefs[0:n])
} void free_vector(vector &v)
{
#pragma acc exit data delete(v.coefs)
#pragma acc exit data delete(v)
v.n = ;
free(v.coefs);
} void initialize_vector(vector &v, const double val)
{
for (int i = ; i < v.n; i++)
v.coefs[i] = val;
#pragma acc update device(v.coefs[0:v.n])
}
// vector_functions.h
#pragma once
#include<cstdlib>
#include "vector.h" double dot(const vector& x, const vector& y)
{
const unsigned int n = x.n;
double sum = , *xcoefs = x.coefs, *ycoefs = y.coefs; #pragma acc kernels
for (int i = ; i < n; i++)
sum += xcoefs[i] * ycoefs[i];
return sum;
} void waxpby(double alpha, const vector &x, double beta, const vector &y, const vector& w) const unsigned int n = x.n;
double *restrict xcoefs = x.coefs, *ycoefs = y.coefs, *wcoefs = w.coefs; #pragma acc kernels copy(wcoefs[:w.n],ycoefs[0:y.n]) copyin(xcoefs[0:x.n])
{
#pragma acc loop independent
for (int i = ; i<n; i++)
wcoefs[i] = alpha * xcoefs[i] + beta * ycoefs[i];
}
}
● 输出结果
// Ubuntu:
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/cpp$ pgc++ -fast -acc -Minfo main.cpp -ta=tesla
allocate_vector(vector &, unsigned int):
, include "vector.h"
, Accelerator clause: upper bound for dimension of array 'v' is unknown
Generating enter data create(v[:],v->coefs[:n])
free_vector(vector &):
, include "vector.h"
, Generating exit data delete(v[:],v->coefs[:])
initialize_vector(vector &, double):
, include "vector.h"
, Memory set idiom, loop replaced by call to __c_mset8
, Generating update device(v->coefs[:v->n])
dot(const vector &, const vector &):
, include "vector_functions.h"
, Generating implicit copyin(ycoefs[:n],xcoefs[:n])
, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
, Generating implicit reduction(+:sum)
waxpby(double, const vector &, double, const vector &, const vector &):
, include "vector_functions.h"
, Generating copyin(xcoefs[:x->n])
Generating copy(ycoefs[:y->n],wcoefs[:w->n])
, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
allocate_3d_poission_matrix(matrix &, int):
, include "matrix.h"
, Loop not fused: different loop trip count
, Loop not vectorized/parallelized: loop count too small
, Loop not fused: function call before adjacent loop
, Loop not vectorized: data dependency
, Accelerator clause: upper bound for dimension of array 'A' is unknown
Generating enter data copyin(A[:],A->row_offsets[:num_rows+],A->coefs[:nnz],A->cols[:nnz])
free_matrix(matrix &):
, include "matrix.h"
, Generating exit data delete(A->coefs[:],A->cols[:],A[:],A->row_offsets[:])
matvec(const matrix &, const vector &, const vector &):
, include "matrix_functions.h"
, Generating copyin(Acoefs[:A->nnz])
Generating implicit copyin(row_offsets[:num_rows+])
Generating copyin(xcoefs[:x->n])
Generating implicit copyout(ycoefs[:num_rows])
Generating copyin(cols[:A->nnz])
, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
, #pragma acc loop gang, worker(8) /* blockIdx.x threadIdx.y */
, #pragma acc loop vector(32) /* threadIdx.x */
, Generating implicit reduction(+:sum)
, Loop is parallelizable
main:
, Loop not vectorized/parallelized: potential early exits
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/cpp$ ./a.out
Rows: , nnz:
Iteration: , Tolerance: 4.0067e+08
Iteration: , Tolerance: 1.8772e+07
Iteration: , Tolerance: 6.4359e+05
Iteration: , Tolerance: 2.3202e+04
Iteration: , Tolerance: 8.3565e+02
Iteration: , Tolerance: 3.0039e+01
Iteration: , Tolerance: 1.0764e+00
Iteration: , Tolerance: 3.8360e-02
Iteration: , Tolerance: 1.3515e-03
Iteration: , Tolerance: 4.6209e-05
Iterarion: , error: 1.993399e-06, time: 3249.523926 ms
● 对应的 fortran 代码优化前后的结果
// Ubuntu 优化前:
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90/-multicore$ pgf90 -c matrix.F90 vector.F90
matrix.F90:
vector.F90:
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90/-multicore$ pgf90 main.F90 matrix.o vector.o -fast -mp -Minfo -o no_acc.exe
main.F90:
main:
, Loop not vectorized/parallelized: potential early exits
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90/-multicore$ ./no_acc.exe
Rows: nnz:
Iteration: Tolerance: 4.006700E+08
Iteration: Tolerance: 1.877230E+07
^C
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90/-multicore$ cd ..
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90$ pgf90 -c matrix.F90 vector.F90 -fast -Minfo
matrix.F90:
allocate_3d_poisson_matrix:
, Loop not fused: different loop trip count
, Loop not vectorized/parallelized: loop count too small
, Loop unrolled times (completely unrolled)
, Loop not vectorized: data dependency
matvec:
, Loop unrolled times
FMA (fused multiply-add) instruction(s) generated
vector.F90:
initialize_vector:
, Memory set idiom, loop replaced by call to __c_mset8
dot:
, Generated an alternate version of the loop
Generated vector simd code for the loop containing reductions
Generated prefetch instructions for the loop
Generated vector simd code for the loop containing reductions
Generated prefetch instructions for the loop
FMA (fused multiply-add) instruction(s) generated
waxpby:
, Generated alternate versions of the loop
Generated vector simd code for the loop
Generated prefetch instructions for the loop
Generated vector simd code for the loop
Generated prefetch instructions for the loop
Generated vector simd code for the loop
Generated prefetch instructions for the loop
FMA (fused multiply-add) instruction(s) generated
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90$ pgf90 main.F90 matrix.o vector.o -fast -Minfo -mp -o no_acc.exe
main.F90:
main:
, Loop not vectorized/parallelized: potential early exits
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90$ ./no_acc.exe
Rows: nnz:
Iteration: Tolerance: 4.006700E+08
Iteration: Tolerance: 1.877230E+07
Iteration: Tolerance: 6.435887E+05
Iteration: Tolerance: 2.320219E+04
Iteration: Tolerance: 8.356487E+02
Iteration: Tolerance: 3.003893E+01
Iteration: Tolerance: 1.076441E+00
Iteration: Tolerance: 3.836034E-02
Iteration: Tolerance: 1.351503E-03
Iteration: Tolerance: 4.620883E-05
Total Iterations: Time (s): 23.30484 s // Ubuntu 优化后:
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90/-multicore$ pgf90 -c matrix.F90 vector.F90 -acc -fast -Minfo
matrix.F90:
allocate_3d_poisson_matrix:
, Loop not fused: different loop trip count
, Loop not vectorized/parallelized: loop count too small
, Loop unrolled times (completely unrolled)
, Loop not fused: function call before adjacent loop
, Loop not vectorized: data dependency
, Generating enter data copyin(a)
, Generating enter data copyin(a%coefs(:),a%row_offsets(:),a%cols(:))
free_matrix:
, Generating exit data delete(a%coefs(:),a%cols(:),a%row_offsets(:))
, Generating exit data delete(a)
matvec:
, Generating implicit copyin(arow_offsets(:a%num_rows+),acols(:),acoefs(:))
Generating implicit copyout(y(:a%num_rows))
Generating implicit copyin(x(:))
, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
, !$acc loop gang, worker() ! blockidx%x threadidx%y
, !$acc loop vector() ! threadidx%x
, Generating implicit reduction(+:tmpsum)
, Loop not fused: no successor loop
, Loop is parallelizable
Loop unrolled times
FMA (fused multiply-add) instruction(s) generated
vector.F90:
initialize_vector:
, Generating present(vector(:))
, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
, !$acc loop gang, vector() ! blockidx%x threadidx%x
, Memory set idiom, loop replaced by call to __c_mset8
allocate_vector:
, Generating enter data create(vector(:))
free_vector:
, Generating exit data delete(vector(:))
dot:
, Generating implicit copyin(y(:length),x(:length))
, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
, !$acc loop gang, vector() ! blockidx%x threadidx%x
, Generating implicit reduction(+:tmpsum)
, Loop not fused: no successor loop
Generated an alternate version of the loop
Generated vector simd code for the loop containing reductions
Generated prefetch instructions for the loop
Generated vector simd code for the loop containing reductions
Generated prefetch instructions for the loop
FMA (fused multiply-add) instruction(s) generated
waxpby:
, Generating implicit copyin(x(:length),y(:length))
Generating implicit copyout(w(:length))
, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
, !$acc loop gang, vector() ! blockidx%x threadidx%x
, Loop not fused: no successor loop
Generated alternate versions of the loop
Generated vector simd code for the loop
Generated prefetch instructions for the loop
Generated vector simd code for the loop
Generated prefetch instructions for the loop
Generated vector simd code for the loop
Generated prefetch instructions for the loop
FMA (fused multiply-add) instruction(s) generated
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90/-multicore$ pgf90 main.F90 matrix.o vector.o -acc -fast -Minfo -mp -o acc.exe
main.F90:
main:
, Loop not vectorized/parallelized: potential early exits
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90/-multicore$ ./acc.exe
Rows: nnz:
Iteration: Tolerance: 4.006700E+08
Iteration: Tolerance: 1.877230E+07
Iteration: Tolerance: 6.435887E+05
Iteration: Tolerance: 2.320219E+04
Iteration: Tolerance: 8.356487E+02
Iteration: Tolerance: 3.003893E+01
Iteration: Tolerance: 1.076441E+00
Iteration: Tolerance: 3.836034E-02
Iteration: Tolerance: 1.351503E-03
Iteration: Tolerance: 4.620883E-05
Total Iterations: Time (s): 3.533652 s
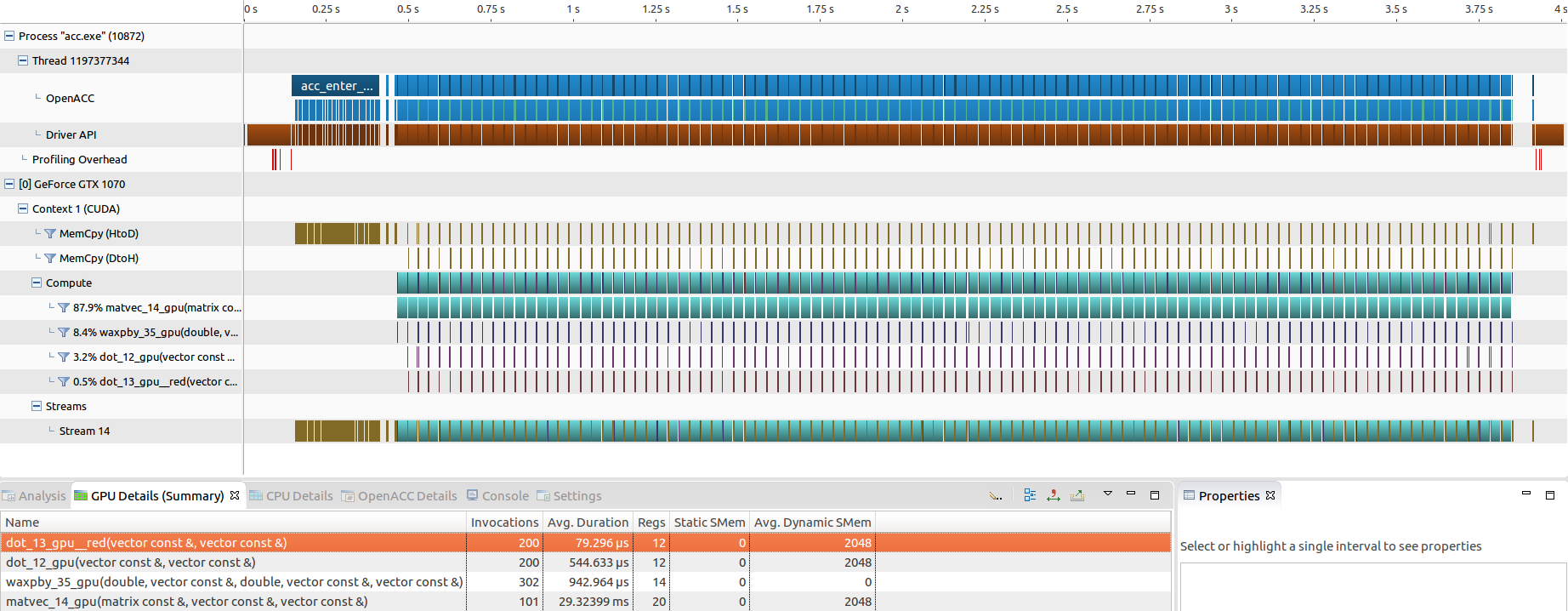
● C++ 优化结果在 nvprof 中的表现
OpenACC 梯度下降法求解线性方程的优化的更多相关文章
- 使用matlab用优化后的梯度下降法求解达最小值时参数
matlab可以用 -Conjugate gradient -BFGS -L-BFGS 等优化后的梯度方法来求解优化问题.当feature过多时,最小二乘计算复杂度过高(O(n**3)),此时 这一些 ...
- 梯度下降法求解函数极大值-Matlab
目录 目录题目作答1. 建立函数文件ceshi.m2. 这是调用的命令,也可以写在.m文件里3. 输出结果题外话 题目 作答 本文使用MATLAB作答 1. 建立函数文件ceshi.m functio ...
- 机器学习---用python实现最小二乘线性回归算法并用随机梯度下降法求解 (Machine Learning Least Squares Linear Regression Application SGD)
在<机器学习---线性回归(Machine Learning Linear Regression)>一文中,我们主要介绍了最小二乘线性回归算法以及简单地介绍了梯度下降法.现在,让我们来实践 ...
- tensorflow实现svm多分类 iris 3分类——本质上在使用梯度下降法求解线性回归(loss是定制的而已)
# Multi-class (Nonlinear) SVM Example # # This function wll illustrate how to # implement the gaussi ...
- tensorflow实现svm iris二分类——本质上在使用梯度下降法求解线性回归(loss是定制的而已)
iris二分类 # Linear Support Vector Machine: Soft Margin # ---------------------------------- # # This f ...
- 梯度下降法原理与python实现
梯度下降法(Gradient descent)是一个一阶最优化算法,通常也称为最速下降法. 要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离 ...
- 梯度下降法(BGD、SGD)、牛顿法、拟牛顿法(DFP、BFGS)、共轭梯度法
一.梯度下降法 梯度:如果函数是一维的变量,则梯度就是导数的方向: 如果是大于一维的,梯度就是在这个点的法向量,并指向数值更高的等值线,这就是为什么求最小值的时候要用负梯度 梯度下降法(Gr ...
- 理解梯度下降法(Gradient Decent)
1. 什么是梯度下降法? 梯度下降法(Gradient Decent)是一种常用的最优化方法,是求解无约束问题最古老也是最常用的方法之一.也被称之为最速下降法.梯度下降法在机器学习中十分常见,多用 ...
- matlib实现梯度下降法
样本文件下载:ex2Data.zip ex2x.dat文件中是一些2-8岁孩子的年龄. ex2y.dat文件中是这些孩子相对应的体重. 我们尝试用批量梯度下降法,随机梯度下降法和小批量梯度下降法来对这 ...
随机推荐
- Navicat Premium连接PostgreSQL
连接PostgreSQL时,报错 大致意思:你当前的IP没有连接权限,在文件pg_hba中缺少当前IP的配置 解决:找你的PostgreSQL安装路径,这是我的:C:\Program Files\Po ...
- spring boot sso 学习资源
diy: 关键字: springboot sso:public boolean preHandle(HttpServletRequest request, HttpServletResponse re ...
- IP相关的方法
1.验证是否为IP地址 def isIP(ip, with_netmask=True): """ 判断IP的格式是否正确 :param ip: IP字符串 :param ...
- day7 python学习
今日内容# 枚举 此代码可以用于对有一定值的列表进行按带序列号的方式打印出来 lis=['手机','电脑','潜艇','手表'] for index,i in enumerate(lis,1): pr ...
- apache spark kubernets 部署试用
spark 是一个不错的平台,支持rdd 分析stream 机器学习... 以下为使用kubernetes 部署的说明,以及注意的地方 具体的容器镜像使用别人已经构建好的 deploy yaml 文件 ...
- web开发的一些总结
现在我们是在互联网的时代,到处可以使用internet 这些年的发展,让we 成为了当前开发的主流,包括现在好多的移动端开发, 很多也是使用web 页面进行呈现,因为web 拉近了你我之间的距离.对于 ...
- poj 2449 Remmarguts' Date(K短路,A*算法)
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/u013081425/article/details/26729375 http://poj.org/ ...
- 通过手动安装来启动ZStack
当您使用手动安装手册完成ZStack的安装之后,您可以继续进行一些必要的配置 以便用它来自动云环境.ZStack的管控工具zstack-ctl会安装到每一个ZStack管理节点,您可以使用它来控制本地 ...
- 如何在MFC DLL中向C#类发送消息
如何在MFC DLL中向C#类发送消息 一. 引言 由于Windows Message才是Windows平台的通用数据流通格式,故在跨语言传输数据时,Message是一个不错的选择,本文档将描述如何在 ...
- SQL Server-- 存储过程中错误处理
一.存储过程中使用事务的简单语法 在存储过程中使用事务时非常重要的,使用数据可以保持数据的关联完整性,在Sql server存储过程中使用事务也很简单,用一个例子来说明它的语法格式: Create P ...