python之模块2
1.logging模块
等级
debug--->info--->warning(默认)--->error--->critical
配置两种方式:
#1.congfig函数
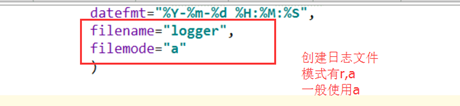
logging.basicConfig(level=logging.DEBUG,#设置等级
format="%(asctime)s---%(message)s",#文件格式
filename="logger",#设置文件名
filemode="a"#文件模式)
logging.debug("message")
num=1000
logging.info("cost %s"%num) logging.info("message") logging.warning("message") logging.error("message") logging.critical("message") import logging
注意:流向只能有一个,屏幕或者文件
#2.logger 是一个对象
logger=logging.getLogger()
# print(logger)在模块中产生一个对象 fh=logging.FileHandler("logger2")#产生一个文件对象
sh=logging.StreamHandler()#产生一个屏幕输出对象
logger.setLevel("DEBUG")#logger对象设定等级
fm=logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
#产生一个格式
fh.setFormatter(fm)
#文件对象引用格式
sh.setFormatter(fm)
#屏幕对象引用格式
logger.addHandler(fh)
logger.addHandler(sh)
logging.debug("message") logging.info("message") logging.warning("message") logging.error("message") logging.critical("message")
2.JSON模块
把对象(变量)从内存中变成可存储或传输的过程称之为序列化;反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,并返回表达式的值。
JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,而且可以直接在web页面中读取,非常方便。
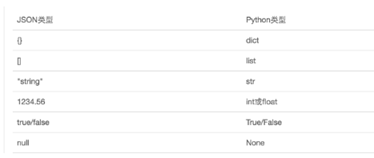
JSON和Python内置的数据类型对应如下:
import json
d={"name":"egon"}
s=json.dumps(d)#将字典d转为json字符串--->序列化过程
print(s)
print(type(s))
f=open("new","w")#产生一个文件
f.write(s)#写入内容
f.close()
# ------------------------>
# dump用法
f=open("new2","w")
json.dump(d,f)#--->转成josn字符串,将json字符串写入f里
# ------------------------>
f=open("new")#读取内容
data=f.read()
data2=json.loads(data)#反序列化过程
print(data2["name"]) import json
f=open("new3")
data=f.read()
res=json.loads(data)#只要是满足json格式的字符串
# 就可以使用loads反序列
print(res["name"]) 数据类型表示
import json
i=10
s='hello'
t=(1,4,6)
l=[3,5,7]
d={'name':"yuan"} json_str1=json.dumps(i)
json_str2=json.dumps(s)
json_str3=json.dumps(t)
json_str4=json.dumps(l)
json_str5=json.dumps(d) print(json_str1) #'10'
print(json_str2) #'"hello"'
print(json_str3) #'[1, 4, 6]'
print(json_str4) #'[3, 5, 7]'
print(json_str5) #'{"name": "yuan"}'
3.RE模块(正则表达式)
正则表达式是一种小型的、高度专业化的编程语言,它内嵌在python中,并通过re模块实现。
对字符串的模糊匹配
Re.findall()找到所有的匹配元素,返回一个列表

- 普通字符:大多数字符和字母都会和自身匹配(精准匹配)
import re
print(re.findall("alex","dfuhualalex"))
>>
['alex'] - Findall(“规则匹配的字符串”,“需要匹配的字符串”) 匹配的字符串中有几个成功的都会显示
import re
print(re.findall("a..x","assxdfuhualalex"))
>>
['assx', 'alex'] - 元字符:(1.). 通配符:什么都可以代表。除了\n匹配不上,其他都可以匹配
import re
print(re.findall("a....x","dfuhualalmmex"))
>>
['almmex'] import re
res=re.findall("p\n....h","hello python p\nnsdfh")#规则匹配加\n属于普通匹配
print(res)
>>
['p\nnsdfh'](2)^ 必须在字符串的开头匹配,否则匹配不成功
import re
print(re.findall("^a..x","assxdfuhualalex"))
>>
['assx'](3)$ 在字符串结尾匹配
import re
print(re.findall("a..x$","assxdfuhualalex"))
>>
['alex'](4)*重复符号(贪婪匹配) 匹配零到无穷次{0,}
import re
print(re.findall("alex*","asalexgnnkfnale"))
>>
['alex', 'ale'](5) +重复符号(贪婪匹配) 匹配一到无穷次{1,}
import re
print(re.findall("alex+","asalexgnnkfnale"))
>>
['alex'](6)? 重复符号(贪婪匹配) 匹配零到一次{0,1}
import re
print(re.findall("alex?","asalexxxgnnkfnale"))
>>
['alex', 'ale'](7) {} 万能的,想取几次取几次 可以表示* + ?
{加想要的次数}
import re
print(re.findall("alex{2}","asalexxxgnnkfnale"))
>>
['alexx']注意:贪婪匹配就是尽可能匹配,后面写?就变成惰性匹配
import re
print(re.findall("alex*?","asalexxxgnnkfnale"))
>>
['ale', 'ale'] import re
print(re.findall("alex+?","asalexxxgnnkfnale"))
>>
['alex'] import re
print(re.findall("alex??","asalexxxgnnkfnale"))
>>
['ale', 'ale'] - 字符集[] 表示或者 在字符集中有特殊意义的只有
(1)\
(2)-
import re
res=re.findall("a[1-9]","a423bx56")#字符集显示1到9的一个
print(res)
>>
['a4'] import re
res=re.findall("a[1-9]*","a423bx56")#[]后面+* 表示a,一个数字,0-无穷次
print(res)
>>
['a423'](3)^ 非以它开头的
import re
print(re.findall("q[^a-z]","qa"))
>>
[] import re
res=re.findall("[^\d]","a423bx56a")#取不是数字的
print(res)
>>
['a', 'b', 'x', 'a'] import re
res=re.findall("[^\d]+","a423bx56a")#取不是数字,1到无穷
print(res)
>>
['a', 'bx', 'a']注意:字符集中把部分符号变成了普通符号
\字符 转译反斜杠后面跟元字符去除特殊功能\. \*
反斜杠后面跟普通字符时限内特殊功能 \d \w
\d 匹配任何十进制数;它相当于类 [0-9]
练习:求小数
import re
res=re.findall("\d+\.?\d*\*\d+\.?\d*","2*6+7*45+1.4*3-8/4")
print(res)
>>
['2*6', '7*45', '1.4*3'] 求负数
print(re.findall("-{0,1}\d+\.?\d*\*\d+\.?\d*","2*6.000+7*45-1.4567*3-8/4"))
print(re.findall("-?\d+\.?\d*\*\d+\.?\d*","2*6.000+7*45-1.4567*3-8/4"))
>>
['2*6.000', '7*45', '-1.4567*3'] import re
print(re.findall("\d","12+24*8-(3+5*7)"))
>>
['1', '2', '2', '4', '8', '3', '5', '7'] import re
print(re.findall("\d*","12+24*8-(3+5*7)"))
>>
['12', '', '24', '', '8', '', '', '3', '', '5', '', '7', '', '']\D 匹配任何非数字字符;它相当于类 [^0-9]
import re
print(re.findall("\D","12+24*8-(3+5*7)"))
>>
['+', '*', '-', '(', '+', '*', ')']\s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]
import re
print(re.findall("\s","hello world"))
>>
[' ']\S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]
import re
print(re.findall("\S","hello world")) >>
['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd'] import re
print(re.findall("\S+","hello world"))
>>
['hello', 'world']\w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]
import re
print(re.findall("\w","heLlo worlD"))
>>
['h', 'e', 'L', 'l', 'o', 'w', 'o', 'r', 'l', 'D']\W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]
import re
print(re.findall("\W","heLlo worlD"))
>>
[' ']\b 匹配一个特殊字符边界,比如空格 ,&,#等
import re
print(re.findall("i","i an list"))
>>
['i', 'i'] import re
print(re.findall("i\\b","hello i an list"))
>>
['i']import re
print(re.findall(r"i\b","hello i an list"))#原生字符串,r后面的字符串不做任何转译
>>
['i']\ 转译普通字符
import re
print(re.findall("www*baidu","www*baidu"))
>>
[''] import re
print(re.findall("www\*baidu","www*baidu"))
['www*baidu']反斜杠转译过程
解释器-------> re模块
() 元字符 无命名分组
括号前面加\代表普通字符
import re
res=re.findall("(ad)+","addd")
print(res)
>>
['ad']import re
res=re.findall("(ad)+yuan","addyuangf") #匹配到ad,第二个d时不成功
print(res)
>>
['ad']注意:?:取消优先级
import re
res=re.findall("(\d)+yuan","adad7842yuan46gf")
print(res)
>>
['2'] import re
res=re.findall("(?:\d)+yuan","adad7842yuan46gf")
print(res)
>>
['7842yuan']命名分组

|或
import re
res=re.findall("www.(oldboy)|(baidu).com","www.oldboy.com")
print(res)
>>
[('oldboy', '')] #优先找括号里的规则,匹配成功返回相对应的值,匹配不成功返回空 import re
res=re.findall("www.(oldboy|baidu).com","www.oldboy.com")
print(res)
>>
['oldboy']
python之模块2的更多相关文章
- Python标准模块--threading
1 模块简介 threading模块在Python1.5.2中首次引入,是低级thread模块的一个增强版.threading模块让线程使用起来更加容易,允许程序同一时间运行多个操作. 不过请注意,P ...
- Python的模块引用和查找路径
模块间相互独立相互引用是任何一种编程语言的基础能力.对于“模块”这个词在各种编程语言中或许是不同的,但我们可以简单认为一个程序文件是一个模块,文件里包含了类或者方法的定义.对于编译型的语言,比如C#中 ...
- Python Logging模块的简单使用
前言 日志是非常重要的,最近有接触到这个,所以系统的看一下Python这个模块的用法.本文即为Logging模块的用法简介,主要参考文章为Python官方文档,链接见参考列表. 另外,Python的H ...
- Python标准模块--logging
1 logging模块简介 logging模块是Python内置的标准模块,主要用于输出运行日志,可以设置输出日志的等级.日志保存路径.日志文件回滚等:相比print,具备如下优点: 可以通过设置不同 ...
- python基础-模块
一.模块介绍 ...
- python 安装模块
python安装模块的方法很多,在此仅介绍一种,不需要安装其他附带的pip等,python安装完之后,配置环境变量,我由于中英文分号原因,环境变量始终没能配置成功汗. 1:下载模块的压缩文件解压到任意 ...
- python Queue模块
先看一个很简单的例子 #coding:utf8 import Queue #queue是队列的意思 q=Queue.Queue(maxsize=10) #创建一个queue对象 for i in ra ...
- python logging模块可能会令人困惑的地方
python logging模块主要是python提供的通用日志系统,使用的方法其实挺简单的,这块就不多介绍.下面主要会讲到在使用python logging模块的时候,涉及到多个python文件的调 ...
- Python引用模块和查找模块路径
模块间相互独立相互引用是任何一种编程语言的基础能力.对于"模块"这个词在各种编程语言中或许是不同的,但我们可以简单认为一个程序文件是一个模块,文件里包含了类或者方法的定义.对于编译 ...
- Python Paramiko模块与MySQL数据库操作
Paramiko模块批量管理:通过调用ssh协议进行远程机器的批量命令执行. 要使用paramiko模块那就必须先安装这个第三方模块,仅需要在本地上安装相应的软件(python以及PyCrypto), ...
随机推荐
- CCF-CSP 第三题字符串整理(模拟大法好)
URL映射 规则的相邻两项之间用‘/’分开,所以我们先把所有项分开,然后依次把两个字符串的对应项匹配即可. 分离字符串这里用字符串流(stringstream)处理,先把所有的‘/’变为空格,然后一个 ...
- CDOJ 1962 天才钱vs学霸周2【最大流】
以s=0,t=n+m+1分别为超级源点和超级汇点.网络流中的流量以0为开始,题目要求从1到20,我们先把每个点都减去1,即ai - m,bi - n.然后源点s与n个顶点连容量为ai的路,汇点t与m个 ...
- 替罪羊树&&非旋treap
题解: 替罪羊树的模板和splay差距还是比较大的.. 按照我的splay的写法 真是都是问题.. 替罪羊树就是暴力的搞 当某颗子树大小大于这棵树的alpha时 就退出 另外删除的时候打懒标记删除 当 ...
- 前端接口自动化测试工具-DOClever使用介绍(转载)
DOClever 不仅集成了文档编写,团队协作,接口运行,mock 数据等功能,还有两个功能是让我们团队大大的提高工作效率的.一个是接口的自动化生成,可以根据接口数据自动生成文档信息,还有一个便是本文 ...
- python--模拟蜂窝网(https)登陆总结
#用户名密码登陆 1.寻找登陆请求(此处可以故意输错用户名密码,目的是为了能够看清楚重定向的地址) 发现: 点击登陆时,请求了 ①.post302:https://passport.mafengwo. ...
- git 错误解决
1.今天 当我 执行 git add somefile 的时候,出现 如下 错误: If no other git process is currently running, this prob ...
- TCP/UDP 协议,和 HTTP、FTP、SMTP,区别及应用场景
一.OSI 模型 OSI 模型主要作为一个通用模型来做理论分析,而TCP/IP 协议模型是互联网的实际通讯协议,两者一般做映射分析,以下不做严格区分和声明(好吧,比较懒): OSI 整个模型层次大致可 ...
- Centos7使用yum命令安装Mysql5.6.X
首先:具体的安装步骤在mysql官方文档上都有详细的描述. 文档虽然是英文,不过很容易理解,我就不一一翻译了. 官方文档地址:https://dev.mysql.com/doc/refman/5.6/ ...
- html-form
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- POJ 2912 Rochambeau(暴力)+【带权并查集】
<题目链接> 题目大意: n个人进行m轮剪刀石头布游戏(0<n<=500,0<=m<=2000),接下来m行形如x, y, ch的输入,ch='='表示x, y平局 ...