Python 爬虫实例(8)—— 爬取 动态页面
今天使用python 和selenium爬取动态数据,主要是通过不停的更新页面,实现数据的爬取,要爬取的数据如下图
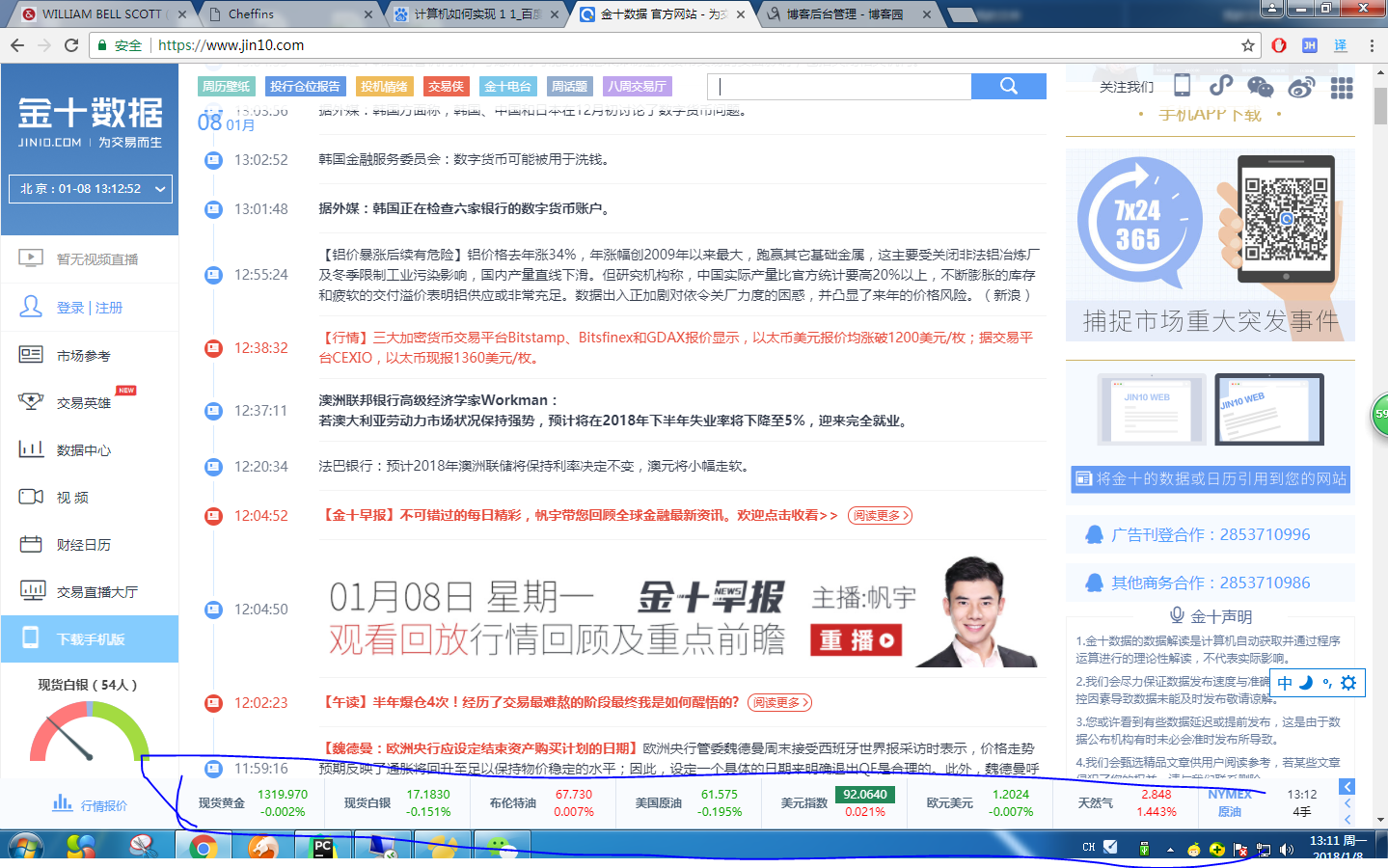
源代码:
#-*-coding:utf-8-*-
import time
from selenium import webdriver
import os
import re
#引入chromedriver.exe
chromedriver = "C:/Users/xuchunlin/AppData/Local/Google/Chrome/Application/chromedriver.exe"
os.environ["webdriver.chrome.driver"] = chromedriver
browser = webdriver.Chrome(chromedriver) #设置浏览器需要打开的url
url = "https://www.jin10.com/"
# 使用for循环不停的刷新页面,也可以每隔一段时间刷新页面
for i in range(1,100000):
browser.get(url)
result= browser.page_source
gold_price = ""
gold_price_change = ""
try:
gold_price = re.findall('<div id="XAUUSD_B" class="jin-price_value" style=".*?">(.*?)</div>',result)[0]
gold_price_change = re.findall('<div id="XAUUSD_P" class="jin-price_value" style=".*?">(.*?)</div>',result)[0]
except:
gold_pric = "------"
gold_price_change = "------" print gold_price
print gold_price_change
time.sleep(1)
Python 爬虫实例(8)—— 爬取 动态页面的更多相关文章
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
随机推荐
- 学生成绩管理系统C++
今天晚上终于做完了学生成绩管理系统!激动!开心!!!哈哈哈~~~~ 总共298行代码,第一次写这么多. 其中遇到了好多困难,也烦恼了好久,不过最终都解决了! 做了之后果然,满满的成就感!抑制不住的兴奋 ...
- linux命令基础三
使用cat命令进行文件的纵向合并使用cat命令实现文件的纵向合并: 例如:使用cat命令将baby.age.baby.kg和baby.sex这三个文件纵向合并为baby文件的方法:cat baby.a ...
- 使用Nginx部署静态网站
这篇文章将介绍如何利用Nginx部署静态网站. 之前写过2篇有关Nginx的文章,一篇是<利用nginx,腾讯云免费证书制作https>,另外一篇是<linux安装nginx> ...
- 最详细的Vuex教程
什么是Vuex? vuex是一个专门为vue.js设计的集中式状态管理架构.状态?我把它理解为在data中的属性需要共享给其他vue组件使用的部分,就叫做状态.简单的说就是data中需要共用的属性. ...
- sql 多行转多列,多行转一列合并数据,列转行
下面又是一种详解:
- docker -v挂载
docker run -d -p 3306:3306 -v /var/lib/mydata:/var/lib/mysql my_sql docker exec -it mys_sql /bin/ba ...
- Expedition [POJ2431] [贪心]
题目大意: 有n个加油站,每个加油站的加油的油量有限,距离终点都有一个距离. 一个卡车的油箱无限,每走一个单元要消耗一单元的油,问卡车到达终点的最少加多少次油. 分析: 我们希望的是走到没油的时候就尽 ...
- BZOJ4012[HNOI2015]开店——树链剖分+可持久化线段树/动态点分治+vector
题目描述 风见幽香有一个好朋友叫八云紫,她们经常一起看星星看月亮从诗词歌赋谈到 人生哲学.最近她们灵机一动,打算在幻想乡开一家小店来做生意赚点钱.这样的 想法当然非常好啦,但是她们也发现她们面临着一个 ...
- 深入理解JVM(2)——揭开HotSpot对象创建的奥秘
一.对象创建的过程:当虚拟机遇到一条含有New的指令时,会进行一系列对象创建的操作. 检查常量池中是否含有带创建对象所属类的符号引用 a) 如果含有的话,直接进行下一步 b) 如果常量池中没有这个符号 ...
- Java泛型之Type体系
Type是java类型信息体系中的顶级接口,其中Class就是Type的一个直接实现类.此外,Type还有有四个直接子接口:ParameterizedType,TypeVariable,Wildcar ...