【Spark-core学习之六】 Spark资源调度和任务调度
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
一、Spark资源调度和任务调度
1、Spark资源调度和任务调度的流程
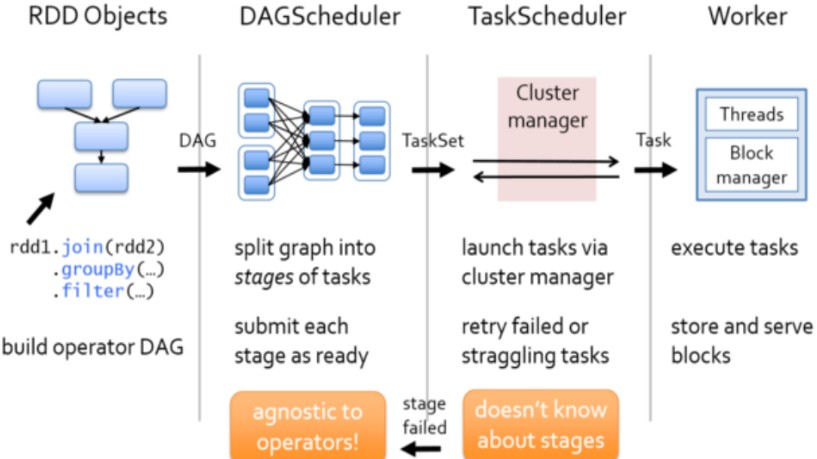
启动集群后,Worker节点会向Master节点汇报资源情况,Master掌握了集群资源情况。当Spark提交一个Application后,根据RDD之间的依赖关系将Application形成一个DAG有向无环图。任务提交后,Spark会在Driver端创建两个对象:DAGScheduler和TaskScheduler,DAGScheduler是任务调度的高层调度器,是一个对象。DAGScheduler的主要作用就是将DAG根据RDD之间的宽窄依赖关系划分为一个个的Stage,然后将这些Stage以TaskSet的形式提交给TaskScheduler(TaskScheduler是任务调度的低层调度器,这里TaskSet其实就是一个集合,里面封装的就是一个个的task任务,也就是stage中的并行度task任务),TaskSchedule会遍历TaskSet集合,拿到每个task后会将task发送到计算节点Executor中去执行(其实就是发送到Executor中的线程池ThreadPool去执行)。task在Executor线程池中的运行情况会向TaskScheduler反馈,当task执行失败时,则由TaskScheduler负责重试,将task重新发送给Executor去执行,默认重试3次。如果重试3次依然失败,那么这个task所在的stage就失败了。stage失败了则由DAGScheduler来负责重试,重新发送TaskSet到TaskSchdeuler,Stage默认重试4次。如果重试4次以后依然失败,那么这个job就失败了。job失败了,Application就失败了。
TaskScheduler不仅能重试失败的task,还会重试straggling(落后,缓慢)task(也就是执行速度比其他task慢太多的task)。如果有运行缓慢的task那么TaskScheduler会启动一个新的task来与这个运行缓慢的task执行相同的处理逻辑。两个task哪个先执行完,就以哪个task的执行结果为准。这就是Spark的推测执行机制。在Spark中推测执行默认是关闭的。推测执行可以通过spark.speculation属性来配置。
注意:
(1) 对于ETL类型要入数据库的业务要关闭推测执行机制,这样就不会有重复的数据入库。
(2)如果遇到数据倾斜的情况,开启推测执行则有可能导致一直会有task重新启动处理相同的逻辑,任务可能一直处于处理不完的状态。
2、图解Spark资源调度和任务调度的流程
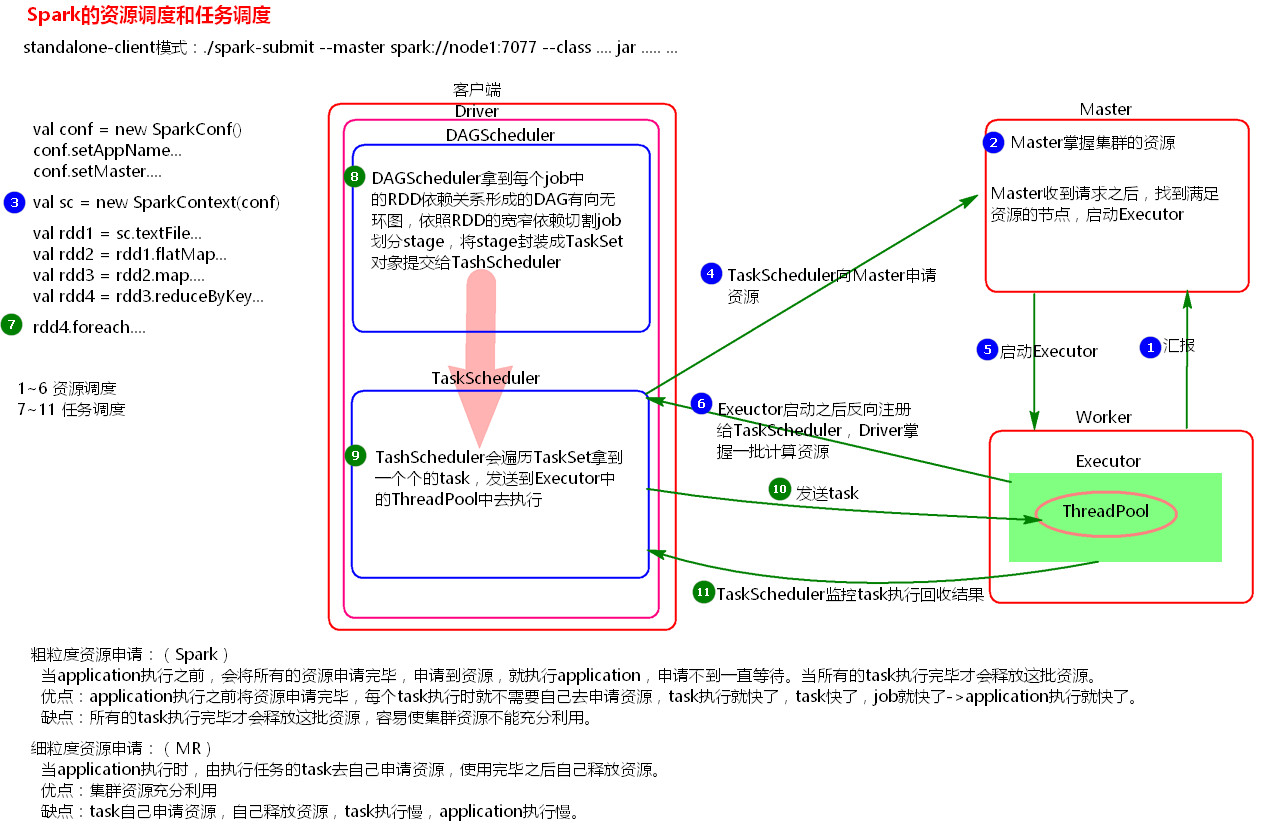
3、粗粒度资源申请和细粒度资源申请
(3.1)粗粒度资源申请(Spark)
在Application执行之前,将所有的资源申请完毕,当资源申请成功后,才会进行任务的调度,当所有的task执行完成后,才会释放这部分资源。
优点:在Application执行之前,所有的资源都申请完毕,每一个task直接使用资源就可以了,不需要task在执行前自己去申请资源,task启动就快了,task执行快了,stage执行就快了,job就快了,application执行就快了。
缺点:直到最后一个task执行完成才会释放资源,集群的资源无法充分利用。
(3.2)细粒度资源申请(MapReduce)
Application执行之前不需要先去申请资源,而是直接执行,让job中的每一个task在执行前自己去申请资源,task执行完成就释放资源。
优点:集群的资源可以充分利用。
缺点:task自己去申请资源,task启动变慢,Application的运行就相应的变慢了。
二、资源调度和任务调度源码
1、资源调度
(1)资源请求简单图
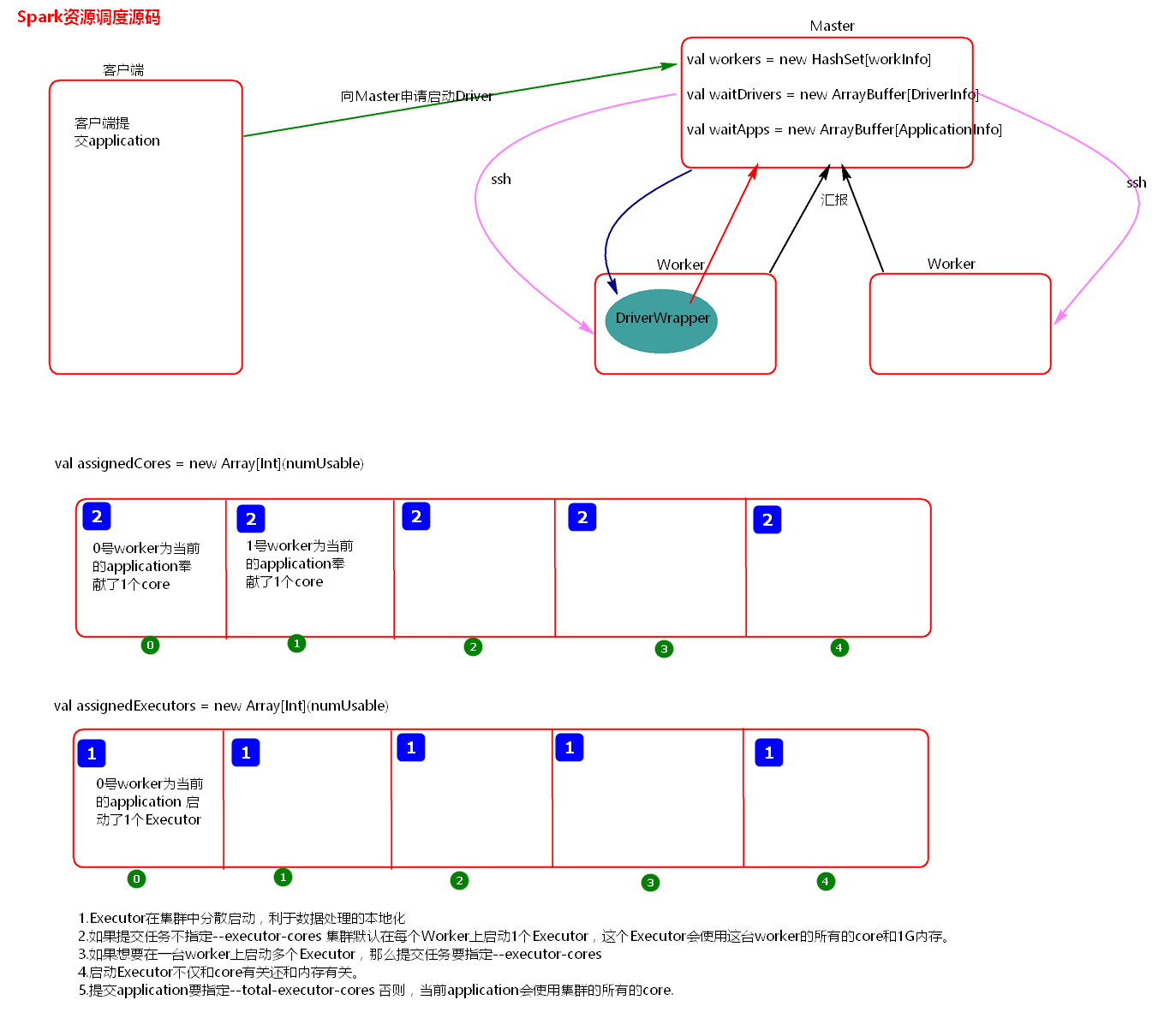
(2)资源调度Master路径:
org.apache.spark.deploy.SparkSubmit
路径:spark-1.6.0/core/src/main/scala/org.apache.spark/deploy/Master/Master.scala
(3)提交应用程序,submit的路径:
org.apache.spark.deploy.master.Master
路径:spark-1.6.0/core/src/main/scala/org.apache.spark/deploy/SparkSubmit.scala
(4)总结:
(4.1)Executor在集群中分散启动,有利于task计算的数据本地化。
(4.2)默认情况下(提交任务的时候没有设置--executor-cores选项),每一个Worker为当前的Application启动一个Executor,这个Executor会使用这个Worker的所有的cores和1G内存。
(4.3)如果想在Worker上启动多个Executor,提交Application的时候要加--executor-cores这个选项。
(4.4)默认情况下没有设置--total-executor-cores,一个Application会使用Spark集群中所有的cores。
(5)结论演示
使用Spark-submit提交任务演示。也可以使用spark-shell
(5.1)默认情况每个worker为当前的Application启动一个Executor,这个Executor使用集群中所有的cores和1G内存。
./spark-submit
--master spark://node1:7077
--class org.apache.spark.examples.SparkPi
../lib/spark-examples-1.6.0-hadoop2.6.0.jar
10000
(5.2)在workr上启动多个Executor,设置--executor-cores参数指定每个executor使用的core数量。
./spark-submit
--master spark://node1:7077
--executor-cores 1
--class org.apache.spark.examples.SparkPi
../lib/spark-examples-1.6.0-hadoop2.6.0.jar
10000
(5.3)内存不足的情况下启动core的情况。Spark启动是不仅看core配置参数,也要看配置的core的内存是否够用。
./spark-submit
--master spark://node1:7077
--executor-cores 1
--executor-memory 3g
--class org.apache.spark.examples.SparkPi
../lib/spark-examples-1.6.0-hadoop2.6.0.jar
10000
(5.4)--total-executor-cores集群中共使用多少cores
注意:一个进程不能让集群多个节点共同启动。
./spark-submit
--master spark://node1:7077
--executor-cores 1
--executor-memory 2g
--total-executor-cores 3
--class org.apache.spark.examples.SparkPi
../lib/spark-examples-1.6.0-hadoop2.6.0.jar
10000
2、任务调度源码分析
(1)Action算子开始分析
任务调度可以从一个Action类算子开始。因为Action类算子会触发一个job的执行。
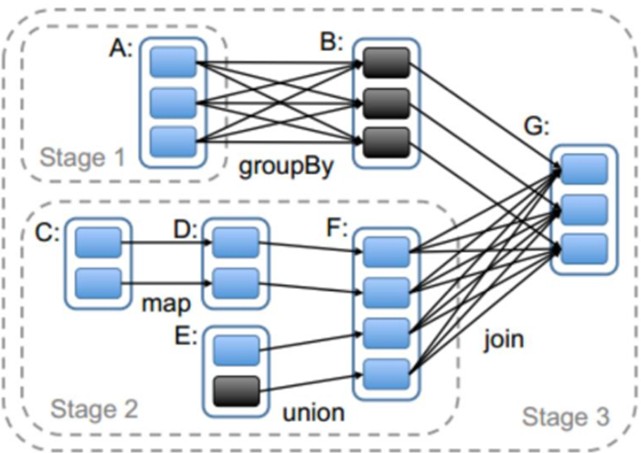
(2)划分stage,以taskSet形式提交任务
DAGScheduler 类中getMessingParentStages()方法是切割job划分stage。可以结合以下这张图来分析:
参考:
Spark
【Spark-core学习之六】 Spark资源调度和任务调度的更多相关文章
- spark SQL学习(spark连接 mysql)
spark连接mysql(打jar包方式) package wujiadong_sparkSQL import java.util.Properties import org.apache.spark ...
- 【spark core学习---算子总结(java版本) (第1部分)】
map算子 flatMap算子 mapParitions算子 filter算子 mapParttionsWithIndex算子 sample算子 distinct算子 groupByKey算子 red ...
- Spark Core源代码分析: Spark任务运行模型
DAGScheduler 面向stage的调度层,为job生成以stage组成的DAG,提交TaskSet给TaskScheduler运行. 每个Stage内,都是独立的tasks,他们共同运行同一个 ...
- Spark Core源代码分析: Spark任务模型
概述 一个Spark的Job分为多个stage,最后一个stage会包含一个或多个ResultTask,前面的stages会包含一个或多个ShuffleMapTasks. ResultTask运行并将 ...
- spark SQL学习(spark连接hive)
spark 读取hive中的数据 scala> import org.apache.spark.sql.hive.HiveContext import org.apache.spark.sql. ...
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
- 【Spark Core】任务运行机制和Task源代码浅析1
引言 上一小节<TaskScheduler源代码与任务提交原理浅析2>介绍了Driver側将Stage进行划分.依据Executor闲置情况分发任务,终于通过DriverActor向exe ...
- 大数据笔记(二十七)——Spark Core简介及安装配置
1.Spark Core: 类似MapReduce 核心:RDD 2.Spark SQL: 类似Hive,支持SQL 3.Spark Streaming:类似Storm =============== ...
- Spark Core 资源调度与任务调度(standalone client 流程描述)
Spark Core 资源调度与任务调度(standalone client 流程描述) Spark集群启动: 集群启动后,Worker会向Master汇报资源情况(实际上将Worker的资 ...
随机推荐
- myeclipse中的classpath .
博客分类: java基础 myeclipse中的classpath是一个很重要的问题 myeclipse的在查找的时候都是按照其查找,而且myeclipse有一个专门的文件来保存classpath ...
- winscp的root连接ubuntu“拒绝访问”的解决方法
转载:https://www.cnblogs.com/weizhxa/p/10098640.html 解决: 1.修改ssh配置文件:sudo vim etc/ssh/sshd_config 在#Pe ...
- 通过java递归思想实现以树形方式展现出该目录中的所有子目录和文件
当初在开始接触Java时 学习File部分的一个小练习 挺有意思 一开始是通过看 北京圣思园 张龙老师的视频开始学校java的,必须强烈推荐,真很棒. 功能实现:主要实现以树形方式展现出该目录中的 ...
- 深度学习中交叉熵和KL散度和最大似然估计之间的关系
机器学习的面试题中经常会被问到交叉熵(cross entropy)和最大似然估计(MLE)或者KL散度有什么关系,查了一些资料发现优化这3个东西其实是等价的. 熵和交叉熵 提到交叉熵就需要了解下信息论 ...
- mysql的某个数据库拒绝访问的问题
场景: mysql自带的mysql和test库都可以正常连接. 新建一个数据库demo,配置java访问时报错:Access denied for user 'root'@'localhost' (u ...
- 【Zookeeper系列】ZooKeeper机制架构(转)
原文链接:https://www.cnblogs.com/sunddenly/p/4133784.html 一.ZooKeeper权限管理机制 1.1 权限管理ACL(Access Control L ...
- 在VS中为C/C++源代码文件生成对应的汇编代码文件(.asm)
以VS2017为例 然后重新生成工程,在工程目录中就会有对应的汇编代码文件.
- git使用——推送本地文件到远程仓库
捣鼓了一下午之后总结如下: 1.首先可以照着这个链接里面博主给出的详细方法进行操作和配置: http://www.open-open.com/lib/view/open1454507333214. ...
- hibernate10--命名查询
<?xml version="1.0"?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hiber ...
- apache开启重写模式
现在的好多的框架都使用有路由机制,但是如果在apache下,没有开启重写模式,服务器不会读取路由 所以今天要分享一下apache开启重写模式 ubuntu下: 1.在命令行下 sudo a2enmod ...