图像分类(一)GoogLenet Inception_V1:Going deeper with convolutions
在该论文中作者提出了一种被称为Inception Network的深度卷积神经网络,它由若干个Inception modules堆叠而成。Inception的主要特点是它能提高网络中计算资源的利用率,这得益于网络结构的精心设计(基于 Hebbian principle 和 the intuition of multi-scale processing ),使得网络在增加宽度和深度的同时又能保持计算开销不变。作者在论文中还介绍了 Inception 的一个应用例子——GoogLenet,该网络凭借在分类和检测任务下的出色表现在2014年的 ILSVRC竞赛上夺得冠军。
1. Motivation and High Level Considerations
从LeNet-5开始,不断出现的卷积神经网络CNNs有一个标准的结构——堆叠的卷积层(可能跟着contrast normalization和max pooling)后面接一个或多个全连接层。尽管max-pooling layers会使精确的空间信息丢失,但是类似于AlexNet的卷积网络已经被成功地应用到了localization、object detection和human pose estimation中。在 ImageNet上进行分类的CNNs也不断增加网络层数和 layer size,同时使用 dropout 避免加深加宽网络后出现严重的overfitting。这是因为提升深度网络性能最直接的方式就是增加网络的尺寸,包括加深和加宽两方面。但是这样做有两个drawbacks:
- 更大尺寸的网络意味着更多的参数,这使得增大后的网络更容易overfitting,尤其在训练集数据有限的情况下。按道理说这可以通过增大训练集解决,但是创建高质量的训练集非常棘手且昂贵
- 网络尺寸均匀增加会导致计算消耗的资源急剧增加
解决上述两个问题最基本的方法是将全连接变成稀疏连接结构(sparsely connected architectures),甚至在卷积层内部也这样。这样做除了模拟生物系统以外,还有坚实的理论基础,Arora 在论文中开创性的工作就证明了这一点。Arora等人的主要研究结果表明,如果数据集的概率分布可以用一个大型且非常稀疏的深度神经网络表示的话(该深度神经网络类似于分类器,可以将数据集内的所有样本正确分类),那么可以通过分析最后一层的激活值的相关性和对输出高度相关的神经元进行聚类来逐层构建理想的网络拓扑。虽然严格的数学证明需要很强的条件,但是事实上该研究结果与著名的Hebbian principle(neurons that fire together, wire together)是一致的,这说明在实践中,即使不完全满足严格的条件,这种潜在的思想也是可以应用的。
不过,使用上述解决方法的话在实现上会有些难度:
- 目前,计算设备在非均匀稀疏数据结构的数值计算非常低效。即使稀疏网络结构需要的计算量被减少100倍,查找和缓存失败的开销也会使理论上运算量减少带来的优势不复存在
- 此外,非均匀稀疏模型(网络结构的稀疏形式不统一)需要更复杂的设计和计算设备。当前大多数基于视觉的机器学习系统是利用卷积的特点在空间域实现稀疏的,但是卷积仅是在浅层作为对patches稠密连接(dense connection)的集合。早些的时候,为了打破网络对称性和提高学习能力,传统的网络都使用了稀疏连接。可是,后来为了更好地优化并行运算在AlexNet中又重新启用了全连接
相反,均匀的结构(或者统一的结构)、大量的filters和更大的batch size允许网络使用高效的密集计算(dense computation)。既然如此,那是否可以在网络中既使用稀疏结构,又能利用密集矩阵(dense matrices)在当前硬件上的高计算性能对稀疏结构进行数值计算?大量关于稀疏矩阵( sparse matrix)计算的文献表明,将稀疏矩阵聚类成相对密集的子矩阵,往往能使稀疏矩阵乘法达到最先进的实用性能。但是在该论文中作者没有利用这一思路,只是说,在不远的将来类似的方法或许会被用于非均匀深度学习结构的自动构建。
作者的思路是,是否可以通过简单易得的dense components(dense network中常见的组件,比如卷积、全连接等)逼近和覆盖卷积网络中理想的局部稀疏结构?事实证明,这是可以的!!作者设计的 Inception module就可以做到这一点。
2. Inception module
Serre 在论文中使用一系列参数固定、尺寸不同的 Gabor filters 来解决多尺度(multiple scales)问题(如下图)。受此启发,作者在 Inception module 中也使用了相同的2层深度模型,不过所有filters参数不是固定的,需要通过学习得到。(补充:之所以引入尺度这个概念,其实是为了更贴近人类的视觉系统。多尺度模拟了不同远近的物体在视网膜上的形成,而尺度不变性保证不同远近物体可以对视觉神经有相同的刺激。类似的,引入尺度这个概念可以保证在图像或特征不同大小时,算法都能有效地提出相同的关键点)
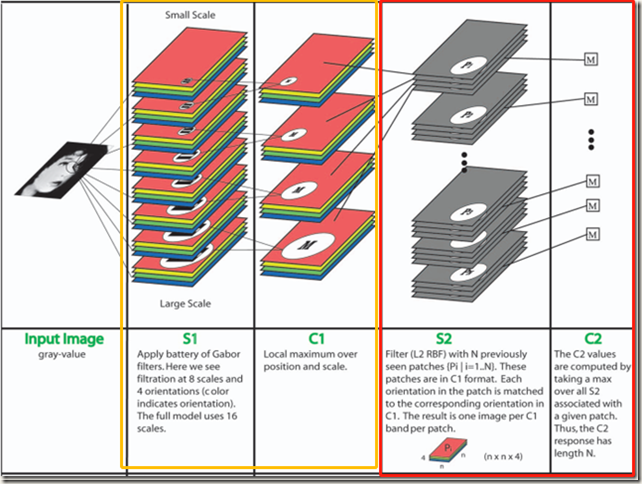
此外,作者还借鉴了Lin在论文中提出的Network-in-Network方法来增强网络的表示能力( representation power)。在应用时,NIN方法可以被视为1层1*1卷积层+rectified linear activation,这样就使得该方法可以很容易地被集成到当前的 CNN pipelines 中。在设计 Inception module 时,NIN方法被大量使用。作者这样做的主要目的并非是想提高网络的表示能力,而是在 Inception module 中将NIN方法当做降维模块(dimension reduction modules,这里的升维降维指的是改变 channels 数,即通道方向上的升维降维)用来克服计算瓶颈,不然computaitional bottlenecks 会限制网络的size。这样设计使得网络不仅能够增加深度,还能增加网络的宽度,同时还不会带来显著的性能损失。
Inception architecture的核心思想是找到如何通过简单易得的稠密组件(dense components指的是卷机层、池化层等卷积网络的组件)逼近和覆盖卷积网络中理想的局部稀疏结构的方法。Arora在论文中提供了一种逐层构建的方法,具体是:先分析某层输出的相关性并根据相关性对输出聚类得到clusters;然后这些clusters会构成下一层的神经元,同时与前一层中的神经元相连。假设来自earlier layer的每个unit都对应于input image中的一些区域,并且这些units被分成 filter banks(对feature map进行卷积时每个卷积核filter的计算结果被称为filter bank)。在较低的层(接近input image)中,相关的units会集中在局部区域,也就是说,聚类的得到的clusters会集中在单个区域(单个位置)。因此,这些units可以被下一层的1*1卷积覆盖,得到下一层的clusters。但是,units聚类时也会得到少量对应较大 patches 的 clusters 和更少量的对应更大patches的clusters。所以,为了避免Inception module中的所有 patches尺寸相同,作者在module中同时使用了 1*1、3*3 和 5*5 三种尺寸的 filters,这么做更多的是基于便利性(方便对齐,如果设定stride=1,那么只要分别设定padding=0,1,2就能得到维度相同的特征,而后可以直接拼接)而非必要性。这也意味着 Inception module 是所有这些层的组合,其输出的 filter banks 拼接成单个输出向量(不同尺度特征的融合)成为下一阶段的输入。除了三种卷积之外,作者在Inception module中还添加了一条并行的池化路径,因为池化操作在目前先进的卷积网络中至关重要,添加池化路径后应该会给module带来额外的好处。至此,朴素形式的Inception module已经设计完成,如Figure 2(a)所示:
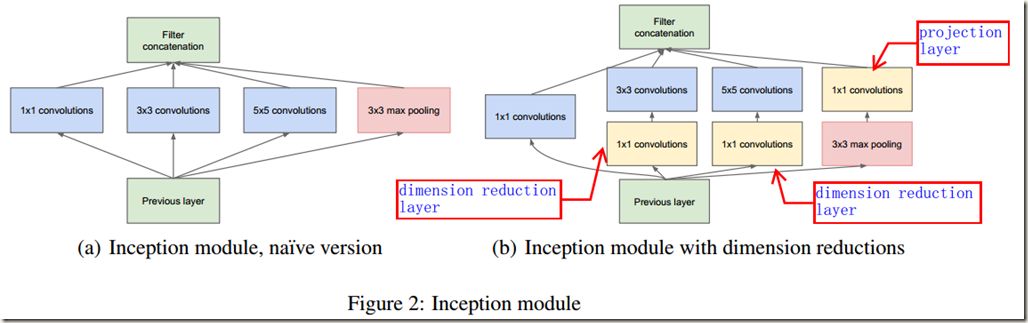
随着 Inception modules 逐层堆叠,网络的输出相关性肯定会变化:当更高的抽象特征被更高的层捕获时,抽象特征的空间集中程度预计会减小(像在低层时聚类出现的单个区域会减少),因此随着网络层数的加深,3*3和5*5卷积的比例应该增加。
朴素形式的 Inception modules 的设计存在一个大问题,那就是具有大量 filters 的卷积层会使得计算非常昂贵(输出channel较多)。当池化单元添加到 module 中后,这个问题会变得更明显。这是因为卷积层的输出通道数还可以通过减少filters降低,但是池化单元的输出通道数等于前一阶段(即Figure 2(a)中的 previous layer)输入的通道数,无法减少。随后池化层输出和卷积层输出的合并会导致这一阶段到下一阶段的输出通道数不可避免的增加。显然,经过几个 modules 后,网络的计算量会爆炸。
为了解决这个问题,作者提出在 naive Inception modules中计算量会大幅增加的地方应用dimension reductions 和 projections,即 dimension reduction layer 和 projection layer。这是基于embeddings的成功:即使低维嵌入可能包含大量关于 large image patch 的信息。然而 embeddings 以密集、压缩形式表示信息并且压缩后的信息更难处理。作者希望在需要的地方保持表示的稀疏性,在必要的地方对信号进行压缩。也就是如 Figure 2(b)所示,在原本计算昂贵的 3*3和5*5卷积之前使用1*1卷积降维(dimension reduction layer),同时,1*1卷积还带有 rectified linear activation;在池化单元之后,作者同样使用了1*1卷积(projection layer),作用是减少通道数,避免计算爆炸。至此,得到 Inception V1的结构,即 Inception module with dimension reductions
3. Inception network
一般,Inception nework(或Inception architecture)是通过 Inception modules相互堆叠得到的,中间可能还会添加 stride 为2的 max-pooling layers 来将网格的分辨率减半。
Inception network主要有两方面的好处:
- 该网络增加stage的数量和每个stage(module)中的单元数量时不用担心计算复杂度爆炸(即加深加宽)。这主要得益于无处不在的dimension reduction
- 网络的设计符合直觉,即视觉信息应该在不同scales上处理,然后进行聚合以便下一阶段能够同时从不同scales提取特征(the intuition of multi-scale processing )
4. GoogLeNet
GoogLeNet是Inception nework最成功的一个应用,该网络在2014年举办的ILSVRC竞赛上夺得冠军。之所以被称为GoogLeNet而不是GoogleNet是为了向 Yann LeCuns 提出的 LeNet-5致敬。具体结构如 Table 1 所示:
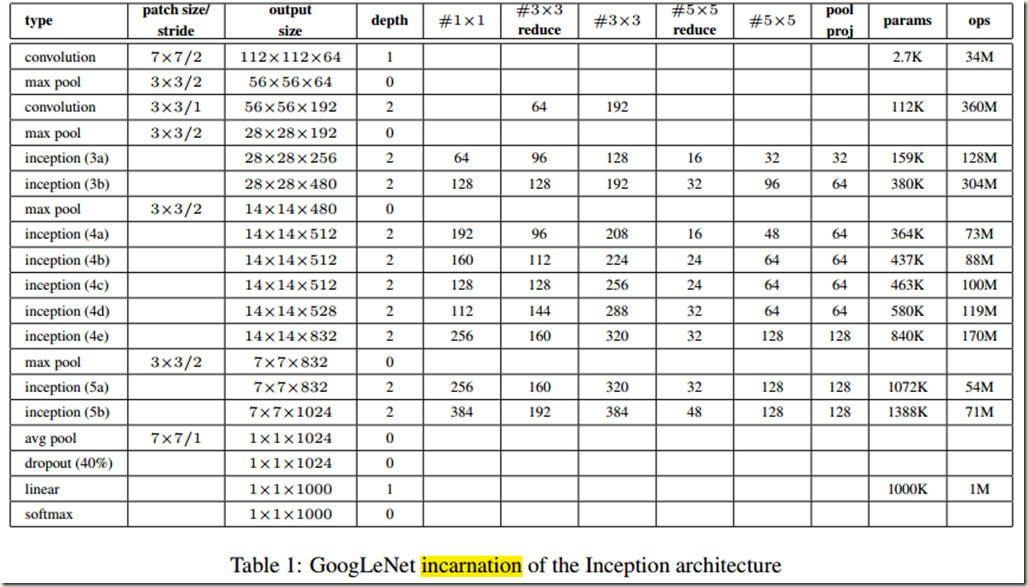
需要说明的是:网络中的所有卷积,包括 Inception modules 的卷积层,都使用了 rectified linear activation;该网络的感受野(receptive filed)尺寸为224*224,输入是减去均值的RGB图像;Table 1中的”#3x3 reduce“和”#5x5 reduce“分别代表3*3卷积和5*5卷积层前面的1*1卷积所使用的 filters数目; max-pooling layer后面的 projection layer使用的filters数目可以在 pool proj 那一列看到;所有的 reduction layer 和 projection layer 同样都使用 rectified linear activation
GoogLeNet网络的设计考虑到了计算效率和实用性,所以inference过程可以在单个设备上运行,甚至于那些内存资源有限的设备。如果只计算含参层的话该网络一共有22层,如果再加上池化层就有27层。需要特别说明的是,在每个classifier(该网络有3个softmax分类器)之前还使用了average pooling和FC。FC的添加使得网络很容易适应和微调其它数据集,作者这么做其实主要是为了方便(不使用全连接层而像NIN那样使用avearge pooling的话,更换训练集时就需要对网络结构进行大量修改,反之,使用全连接层的话仅需简单地修改下输出神经元个数),并没有期望它会产生很大的影响。实验证明确实如此,将全连接层除去(使用average pooling代替全连接层)反而能将 top-1 accuracy 提高0.6%(除去全连接层后dropout层依然保留)。
由于比较深,网络训练时反向传播梯度的能力就成了应该关注的重点。作者为了鼓励低层的区分性、增强反向传播的梯度信号(避免梯度消失)并提供额外的regularization,在网络的中间层添加了 2个辅助分类器(auxiliary classifiers)用于向前传导梯度。这是基于这样一种认识:相对较浅的网络已经具有强大的性能,那么网络中间层产生的特征应该更有区分性。这些分类器以一种 smaller convolutional networks的形式出现在网络中。值得注意的是,在训练时,这些分类器的损失会被以加权(权重为0.3)的形式计算网络的总损失当中,但是在 inference 时,这些辅助网络会被废弃不用。
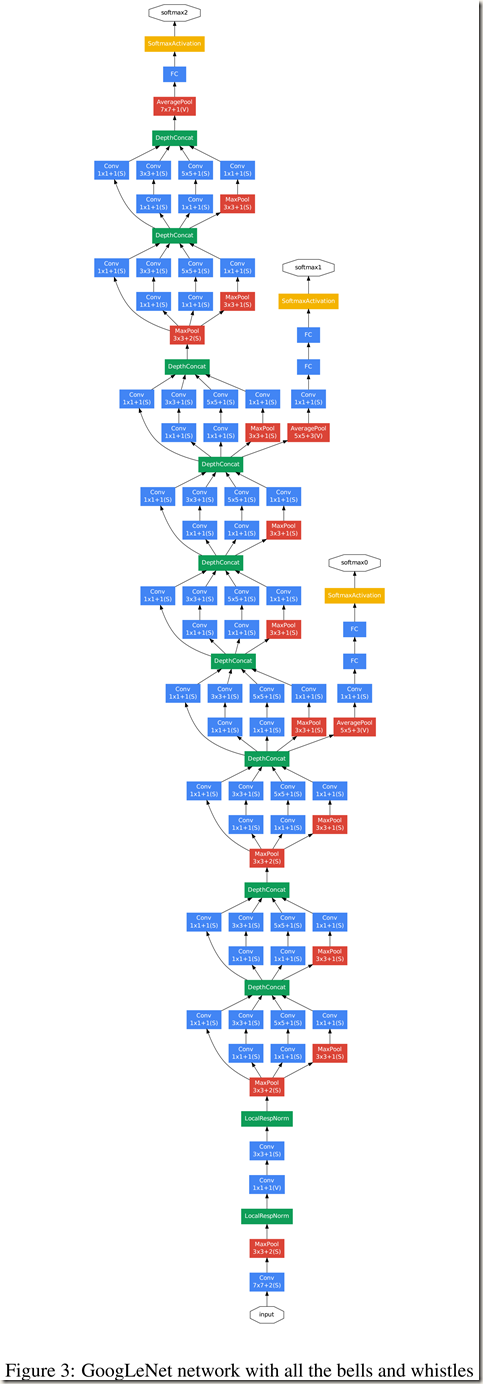
GoogLeNet 除了 Table 1 中列出的 layers,还有一些包括辅助分类器在内的附加网络,更详细的结构如 Figure 3 所示:
5. Training Methodology
GoogLeNet网络使用 DistBelief 分布式机器学习系统进行训练,该系统使用适量的模型和数据并行。作者训练时使用异步随机梯度下降法,动量为0.9,固定的学习率计划(每8个epochs学习速率下降4%)。在 inference 时,使用 Polyak averaging 创建最终的model 。因为各种变化,导致作者也无法明确给出最有效的训练方法。
此外,GoogLeNet 在分类和检测任务上的应用细节等可以参见原论文,这里不再记录。
6. Inception v1 总结
- Inception module的设计目的是使用常见的 dense components 逼近理想的局部稀疏结构,以避免网络加深加宽带来的计算爆炸
- Serre使用了一系列参数固定尺寸不同的Gabor filters解决图像当中的多尺度问题。之所以使用一组滤波器就是为了保证对不同尺度的图像都能检测出相同的特征。Inception module借鉴这一点,同时使用了1*1、3*3、5*5卷积提取特征以提升对不同尺度图像的检测能力
- Inception module借鉴了NIN的特性,在原先的卷积过程中附加了1*1的卷积核加上ReLU激活,这不仅提升了网络的深度,提高了representation power,还在通道方向进行了降维,减少了更新参数量
- GoogLeNet 中存在一些包括辅助分类器在内的附加网络,详细见 Figure 3 及论文
参考资料
- 1*1的卷积核与Inception
- 论文导读:GoogLeNet模型,Inception结构网络简化(Going deeper with convolutions)
- GoogLeNet系列解读InceptionV1/V2
- GoogLeNet
- Deep Learning-TensorFlow (13) CNN卷积神经网络_ GoogLeNet 之 Inception(V1-V4)
- 从Inception v1,v2,v3,v4,RexNeXt到Xception再到MobileNets,ShuffleNet,MobileNetV2
- 翻译论文汇总
图像分类(一)GoogLenet Inception_V1:Going deeper with convolutions的更多相关文章
- 解读(GoogLeNet)Going deeper with convolutions
(GoogLeNet)Going deeper with convolutions Inception结构 目前最直接提升DNN效果的方法是increasing their size,这里的size包 ...
- 【网络结构】GoogLeNet inception-v1:Going deeper with convolutions论文笔记
目录 0. 论文链接 1. 概述 2. inception 3. GoogleNet 参考链接 @ 0. 论文链接 1. 概述 GoogLeNet是谷歌团队提出的一种大体保持计算资源不变的前提下, ...
- Going Deeper with Convolutions (GoogLeNet)
目录 代码 Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]. computer vision and pattern ...
- Going Deeper with Convolutions阅读摘要
论文链接:Going deeper with convolutions 代码下载: Abstract We propose a deep convolutional neural network ...
- Going deeper with convolutions 这篇论文
致网友:如果你不小心检索到了这篇文章,请不要看,因为很烂.写下来用于作为我的笔记. 2014年,在LSVRC14(large-Scale Visual Recognition Challenge)中, ...
- [论文阅读]Going deeper with convolutions(GoogLeNet)
本文采用的GoogLenet网络(代号Inception)在2014年ImageNet大规模视觉识别挑战赛取得了最好的结果,该网络总共22层. Motivation and High Level Co ...
- 【CV论文阅读】Going deeper with convolutions(GoogLeNet)
目的: 提升深度神经网络的性能. 一般方法带来的问题: 增加网络的深度与宽度. 带来两个问题: (1)参数增加,数据不足的情况容易导致过拟合 (2)计算资源要求高,而且在训练过程中会使得很多参数趋向于 ...
- Going deeper with convolutions(GoogLeNet、Inception)
从LeNet-5开始,cnn就有了标准的结构:stacked convolutional layers are followed by one or more fully-connected laye ...
- 论文阅读笔记四十二:Going deeper with convolutions (Inception V1 CVPR2014 )
论文原址:https://arxiv.org/pdf/1409.4842.pdf 代码连接:https://github.com/titu1994/Inception-v4(包含v1,v2,v4) ...
随机推荐
- 什么是rpc
远程过程调用协议RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议.RPC协议假定某些传输协议的存在,如TC ...
- C# Cache缓存读取设置
先创建一个CacheHelper.cs类,代码如下: using System; using System.Web; using System.Collections; using System.We ...
- [转]调试利器-SSH隧道
在开发微信公众号或小程序的时候,由于微信平台规则的限制,部分接口需要通过线上域名才能正常访问.但我们一般都会在本地开发,因为这能快速的看到源码修改后的运行结果.但当涉及到需要调用微信接口时,由于不和你 ...
- npm 发布包和删除包(2019最新攻略)
- Linux基础知识之用户和用户组以及 Linux 权限管理
已经开始接触Linux用户管理,用户组管理,以及权限管理这几个逼格满满的关键字.这几个关键字对于前端程序猿的我来说真的是很高大上有木有,以前尝试学 Linux 的时候看到这些名词总是下意识的跳过不敢看 ...
- 搭建hbase1.2.5完全分布式集群
简介 有一段时间,没写博客了,因为公司开发分布式调用链追踪系统,用到hbase,在这里记录一下搭建过程 1.集群如下: ip 主机名 角色 192.168.6.130 node1.jacky.com ...
- windows下JDK环境配置与Android SDK环境配置
一.JDK环境配置1.配置变量名:JAVA_HOME变量值:jdk安装的绝对路径. 变量名:Path(在系统变量中找到并选中Path点击下面的编辑按钮,不要删除原本变量值中的任何一个字母,在这个变量值 ...
- jsp中相对路劲
.代表当前目录 ..代表上一层目录 例如:如下文件,aliCashier.html要引入images下的图片,应该写成../../static/images/logo.png,此处会找到本地静态路径. ...
- 误删除libc.so.6的解决
最近安装一个软件需要glibc-2.17. 使用ldd --version 发现系统的glibc版本为 glibc-2.12,当时没有想到更好的方法,就尝试将系统的glibc版本修改为glibc-2. ...
- 使用PHP几种写99乘法表的方式
首先按照规矩,还是先废话一番,对于刚学PHP的新手来讲,用php写九九乘法表无疑是非常经典的一道练习题. 但不要小看这道练习题,它对于逻辑的考验还是相当到位的. 也许有人会觉得,九九乘法表有什么难的, ...